Před dlouhou dobou jsem odpověděl na otázku o NULL na Stack Exchange s názvem „Proč bychom neměli povolit NULL?“ Mám svůj podíl na peteees a vášně, a strach z NULL je docela vysoko na mém seznamu. Kolega mi nedávno řekl, poté, co vyjádřil preferenci vynutit prázdný řetězec namísto povolení NULL:
"Nerad se zabývám nulami v kódu."
Omlouvám se, ale to není dobrý důvod. Způsob, jakým prezentační vrstva zachází s prázdnými řetězci nebo hodnotami NULL, by neměl být hnacím motorem pro návrh tabulky a datový model. A pokud povolujete „nedostatek hodnoty“ v některém sloupci, záleží vám z logického hlediska na tom, zda je „nedostatek hodnoty“ reprezentován řetězcem nulové délky nebo NULL? Nebo ještě hůř, hodnota tokenu jako 0 nebo -1 pro celá čísla nebo 1900-01-01 pro data?
Itzik Ben-Gan nedávno napsal celou sérii o NULL a vřele doporučuji projít si ji celou:
- Složitost NULL – část 1
- Složitost NULL – část 2
- Složitost NULL – Část 3, Chybějící standardní funkce a alternativy T-SQL
- Složitost NULL – Část 4, Chybějící standardní jedinečné omezení
Ale můj cíl je zde o něco méně komplikovaný, když se téma objevilo v jiné otázce Stack Exchange:„Přidat pole auto now do existující tabulky.“ Zde uživatel přidával nový sloupec do existující tabulky se záměrem automaticky jej vyplnit aktuálním datem/časem. Přemýšleli, zda by měli v tomto sloupci ponechat hodnoty NULL pro všechny existující řádky, nebo nastavit výchozí hodnotu (pravděpodobně jako 1900-01-01, i když nebyly explicitní).
Pro někoho znalého může být snadné odfiltrovat staré řádky na základě hodnoty tokenu – koneckonců, jak by někdo mohl věřit, že nějaký druh Bluetooth doodad byl vyroben nebo zakoupen 1900-01-01? Viděl jsem to v současných systémech, kde v zobrazeních používají nějaké libovolně znějící datum, které funguje jako magický filtr, zobrazující pouze řádky, kterým lze důvěřovat. Ve skutečnosti ve všech případech, které jsem dosud viděl, je datum v klauzuli WHERE datum/čas, kdy byl sloupec (nebo jeho výchozí omezení) přidán. Což je všechno v pořádku; možná to není nejlepší způsob, jak problém vyřešit, ale je to a způsobem.
Pokud však k tabulce nevstupujete prostřednictvím zobrazení, tento důsledek je známý hodnota může stále způsobovat logické problémy i problémy související s výsledky. Logický problém je jednoduše v tom, že někdo, kdo pracuje s tabulkou, musí vědět, že 1900-01-01 je falešná, tokenová hodnota představující „neznámé“ nebo „nepodstatné“. Pro příklad ze skutečného světa, jaká byla průměrná rychlost uvolňování v sekundách pro quarterbacka, který hrál v 70. letech, než jsme něco takového změřili nebo sledovali? Je 0 dobrá hodnota tokenu pro „unknown“? Co takhle -1? Nebo 100? Vraťme se k datům, pokud je pacient bez průkazu totožnosti přijat do nemocnice a je v bezvědomí, co by měl zadat jako datum narození? Nemyslím si, že 1900-01-01 je dobrý nápad a rozhodně to nebyl dobrý nápad v době, kdy to bylo s větší pravděpodobností skutečné datum narození.
Vliv hodnot tokenu na výkon
Z hlediska výkonu mohou falešné nebo „tokenové“ hodnoty jako 1900-01-01 nebo 9999-21-31 způsobit problémy. Podívejme se na několik z nich s příkladem volně založeným na nedávné otázce uvedené výše. Máme tabulku widgetů a po některých vráceních záruky jsme se rozhodli přidat sloupec EnteredService, kam zadáme aktuální datum/čas pro nové řádky. V jednom případě ponecháme všechny existující řádky jako NULL a ve druhém aktualizujeme hodnotu na naše magické datum 1900-01-01. (Jakoukoli kompresi z konverzace prozatím vynecháme.)
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); Nyní do každé tabulky vložíme stejných 100 000 řádků:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; Pak můžeme přidat nový sloupec a aktualizovat 10 % stávajících hodnot s rozložením aktuálních dat a zbývajících 90 % k našemu datu tokenu pouze v jedné z tabulek:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; Nakonec můžeme přidat indexy:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
Využité místo
Vždy slyším „prostor na disku je levný“, když mluvíme o volbě datových typů, fragmentaci a hodnotách tokenů vs. NULL. Moje starost se tolik netýká místa na disku, které tyto další nesmyslné hodnoty zabírají. Jde spíše o to, že když je tabulka dotazována, plýtvá pamětí. Zde můžeme získat rychlou představu o tom, kolik místa spotřebují naše hodnoty tokenu před a po přidání sloupce a indexu:
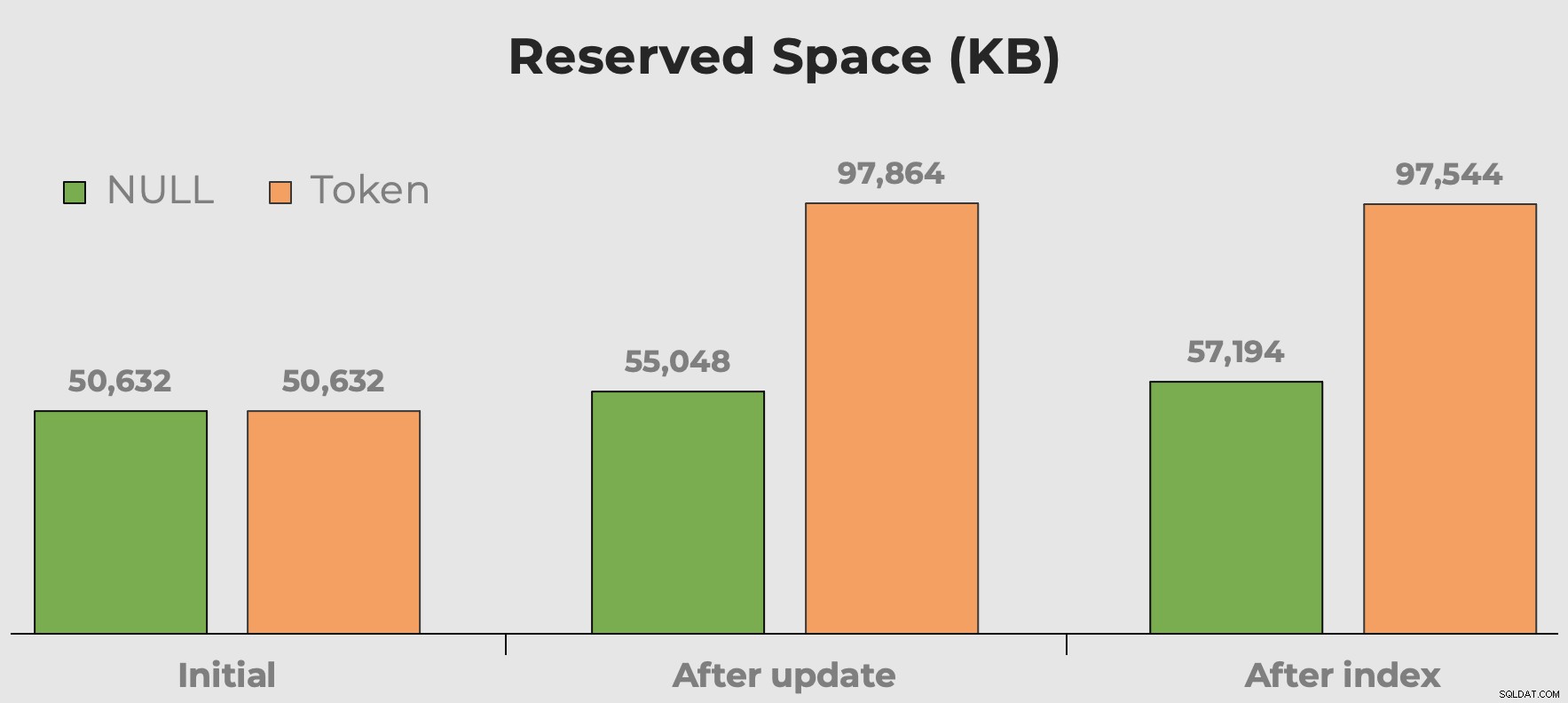 Vyhrazené místo v tabulce po přidání sloupce a přidání indexu. Prostor se s hodnotami tokenu téměř zdvojnásobí.
Vyhrazené místo v tabulce po přidání sloupce a přidání indexu. Prostor se s hodnotami tokenu téměř zdvojnásobí.
Spuštění dotazu
Nevyhnutelně někdo udělá předpoklady o datech v tabulce a dotazuje se na sloupec EnteredService, jako by všechny hodnoty byly legitimní. Například:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; Hodnoty tokenů mohou v některých případech narušovat odhady, ale co je důležitější, vedou k nesprávným (nebo alespoň neočekávaným) výsledkům. Zde je plán provádění dotazu proti tabulce s hodnotami tokenu:
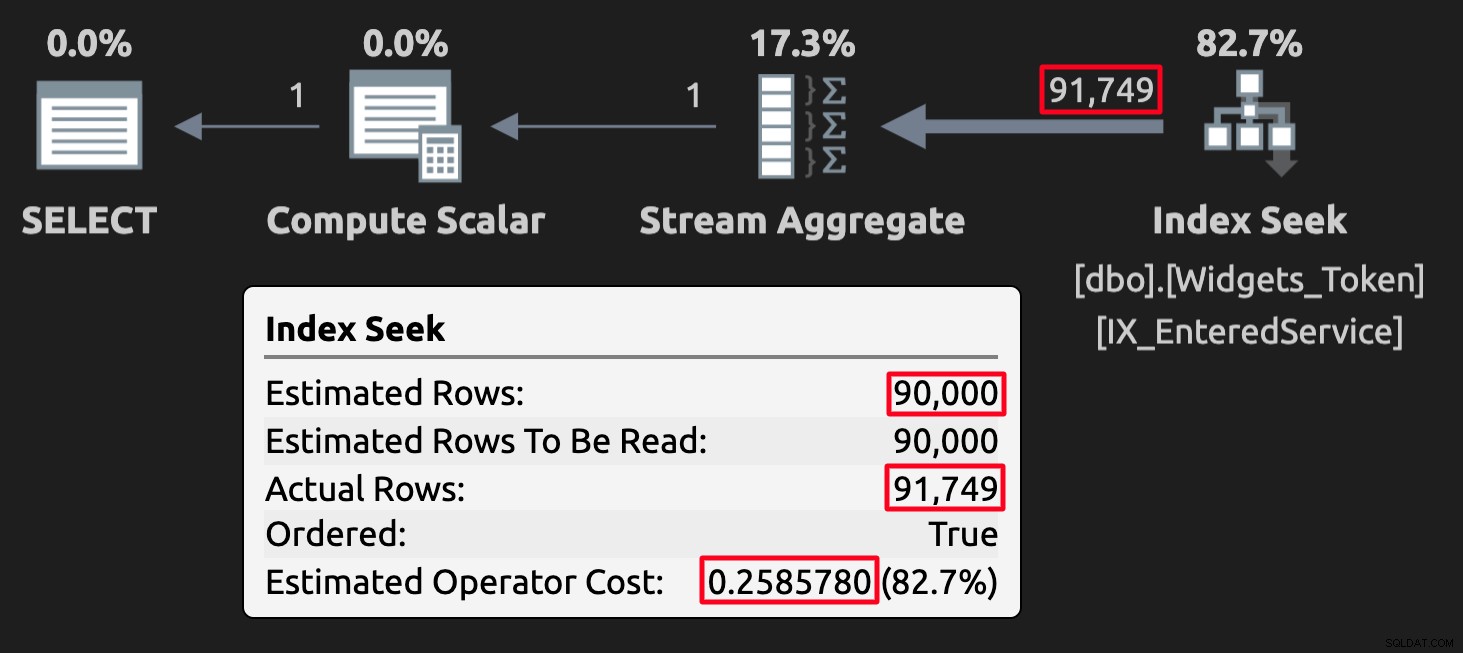 Plán provádění pro tabulku tokenů; všimněte si vysokých nákladů.
Plán provádění pro tabulku tokenů; všimněte si vysokých nákladů.
A zde je plán provádění dotazu proti tabulce s hodnotami NULL:
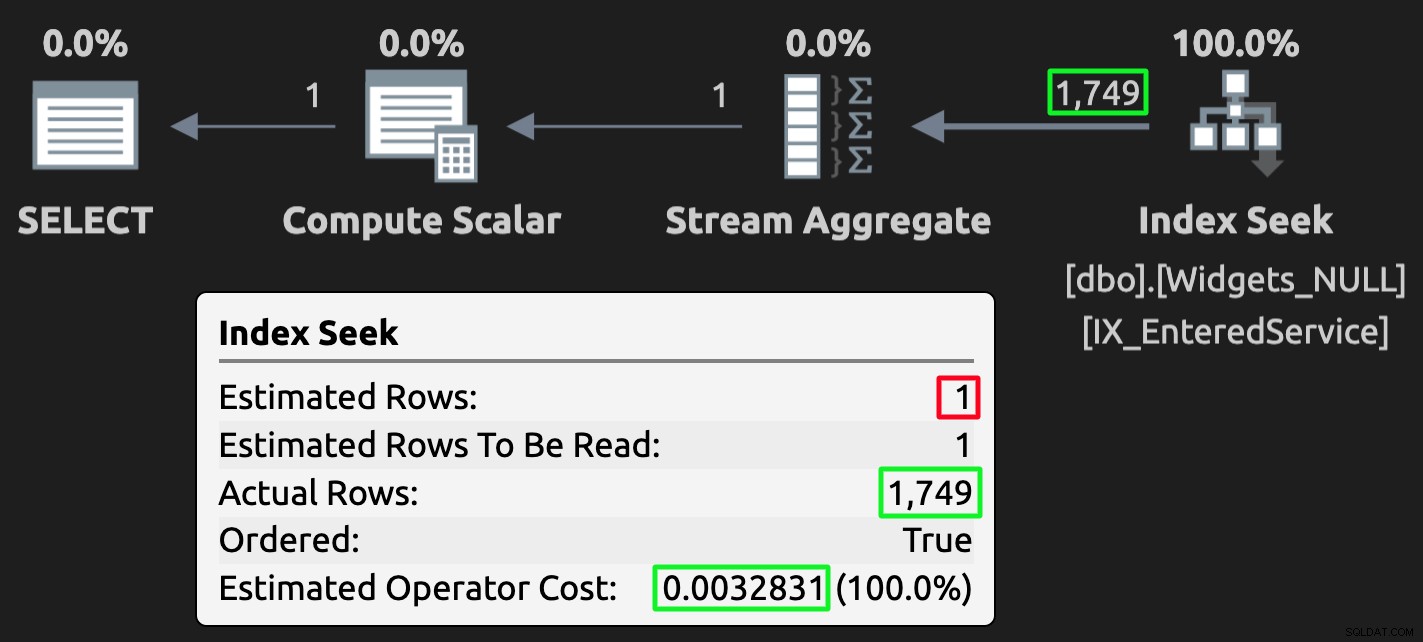 Plán spouštění pro tabulku NULL; špatný odhad, ale mnohem nižší náklady.
Plán spouštění pro tabulku NULL; špatný odhad, ale mnohem nižší náklady.
Totéž by se stalo opačně, pokud by se dotaz zeptal na>={nějaké datum} a 9999-12-31 bylo použito jako magická hodnota představující neznámo.
Opět platí, že pro lidi, kteří náhodou vědí, že výsledky jsou špatné, konkrétně proto, že jste použili tokenové hodnoty, to není problém. Ale všichni ostatní, kteří to nevědí – včetně budoucích kolegů, jiných dědiců a správců kódu, a dokonce i vás budoucích s problémy s pamětí – pravděpodobně narazí.
Závěr
Volba povolit NULL ve sloupci (nebo se NULL úplně vyhnout) by neměla být redukována na ideologické nebo na strachu založené rozhodnutí. Architektura datového modelu, aby se zajistilo, že žádná hodnota nemůže být NULL, nebo použití nesmyslných hodnot k reprezentaci něčeho, co by snadno nebylo možné vůbec uložit, má skutečné, hmatatelné nevýhody. Nenavrhuji, aby každý sloupec ve vašem modelu umožňoval hodnoty NULL; jen abyste nebyli proti myšlence z NULL.