
Dostupnost, přístupnost a výkon dat jsou zásadní pro obchodní úspěch. Ladění výkonu a optimalizace dotazů SQL jsou složité, ale pro databázové profesionály nezbytné postupy. Vyžadují prohlížení různých sbírek dat pomocí rozšířených událostí, perfmon, prováděcích plánů, statistik a indexů, abychom jmenovali alespoň některé. Někdy majitelé aplikací požadují zvýšení systémových prostředků (CPU a paměti), aby zlepšili výkon systému. Tyto dodatečné zdroje však možná nebudete potřebovat a mohou s nimi být spojeny náklady. Někdy stačí jen provést drobná vylepšení, aby se změnilo chování dotazu.
V tomto článku probereme několik doporučených postupů optimalizace dotazů SQL, které lze použít při psaní dotazů SQL.
SELECT * vs SELECT seznam sloupců
Vývojáři obvykle používají ke čtení dat z tabulky příkaz SELECT *. Přečte všechna dostupná data sloupce v tabulce. Předpokládejme, že tabulka [AdventureWorks2019].[HumanResources].[Employee] ukládá data pro 290 zaměstnanců a vy máte požadavek na získání následujících informací:
- Národní identifikační číslo zaměstnance
- DOB
- Pohlaví
- Datum pronájmu
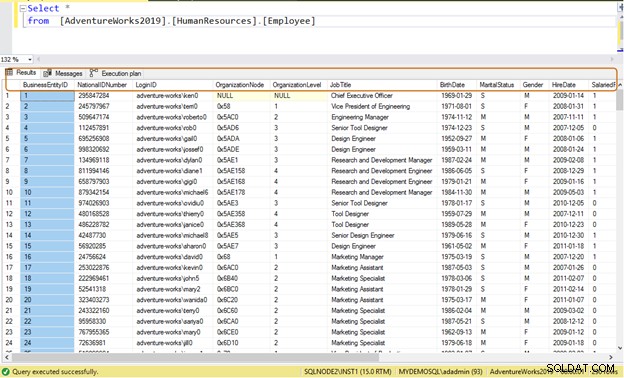
Neefektivní dotaz: Pokud použijete příkaz SELECT *, vrátí všechna data sloupce pro všech 290 zaměstnanců.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
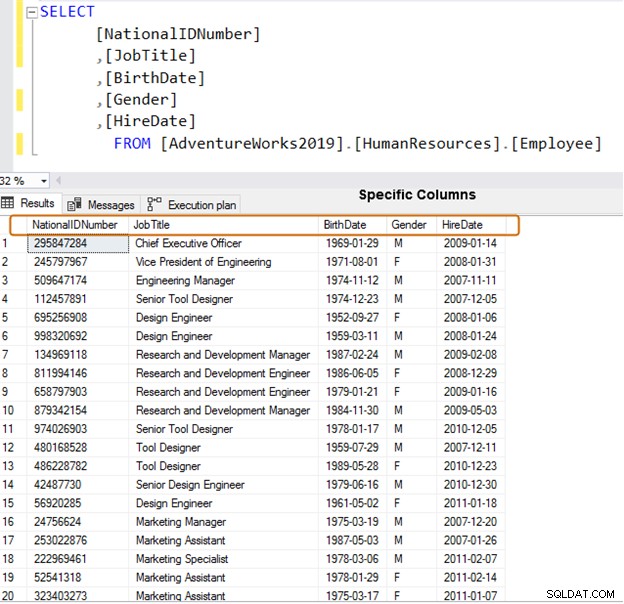
Místo toho použijte pro načítání dat konkrétní názvy sloupců.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
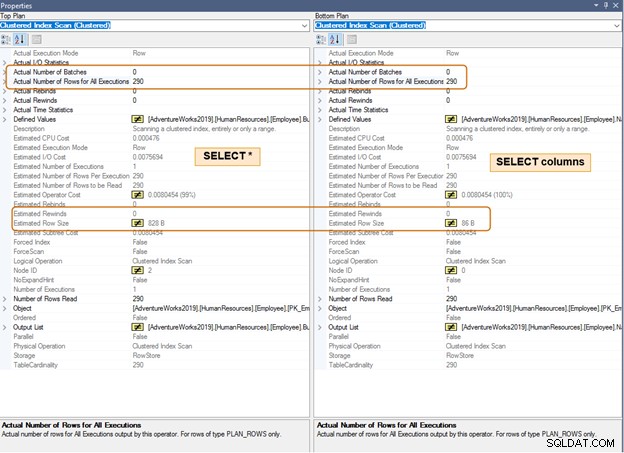
V níže uvedeném plánu provádění si poznamenejte rozdíl v odhadované velikosti řádku pro stejný počet řádků. U velkého počtu řádků si také všimnete rozdílu v CPU a IO.
Použití COUNT() vs. EXISTS
Předpokládejme, že chcete zkontrolovat, zda v tabulce SQL existuje konkrétní záznam. Obvykle používáme COUNT (*) ke kontrole záznamu a vrací počet záznamů ve výstupu.
K tomuto účelu však můžeme použít funkci IF EXISTS(). Pro srovnání jsem povolil statistiky před provedením dotazů.
Dotaz pro COUNT()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
Dotaz pro IF EXISTS()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
K analýze statistických výsledků obou dotazů jsem použil statisticsparser. Podívejte se na výsledky níže. Dotaz s COUNT(*) má 276 logických čtení, zatímco IF EXISTS() má 83 logických čtení. Pomocí IF EXISTS() můžete dokonce dosáhnout výraznějšího snížení logických čtení. Proto byste jej měli používat k optimalizaci SQL dotazů pro lepší výkon.

Vyhněte se používání SQL DISTINCT
Kdykoli chceme z dotazu jedinečné záznamy, obvykle používáme klauzuli SQL DISTINCT. Předpokládejme, že jste spojili dvě tabulky dohromady a ve výstupu vrátí duplicitní řádky. Rychlou opravou je zadat operátor DISTINCT, který potlačí duplicitní řádek.
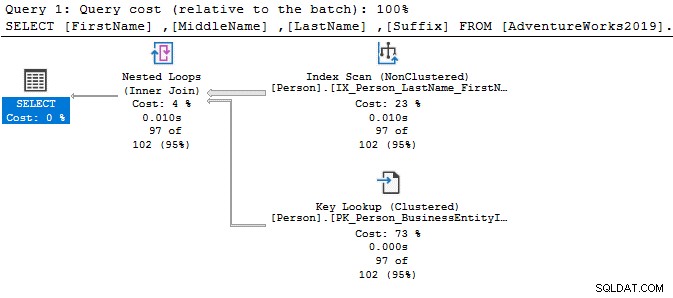
Podívejme se na jednoduché příkazy SELECT a porovnejme prováděcí plány. Jediný rozdíl mezi oběma dotazy je operátor DISTINCT.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
S operátorem DISTINCT je cena dotazu 77 %, zatímco dřívější dotaz (bez DISTINCT) má pouze 23 % dávkové náklady.
Můžete použít GROUP BY, CTE nebo poddotaz pro psaní efektivního kódu SQL namísto použití DISTINCT pro získání odlišných hodnot ze sady výsledků. Navíc můžete načíst další sloupce pro odlišnou sadu výsledků.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Použití zástupných znaků v dotazu SQL
Předpokládejme, že chcete vyhledat konkrétní záznamy obsahující jména začínající zadaným řetězcem. Vývojáři používají k vyhledání odpovídajících záznamů zástupný znak.
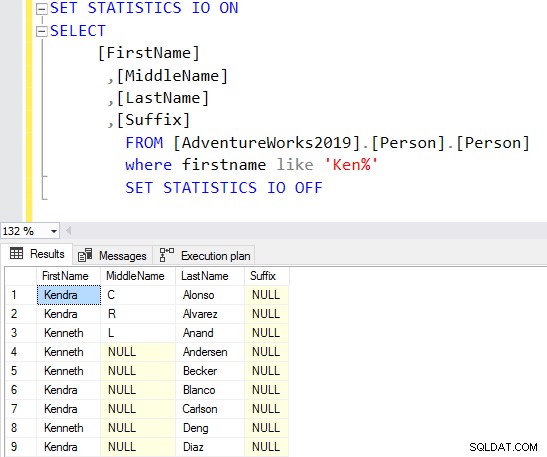
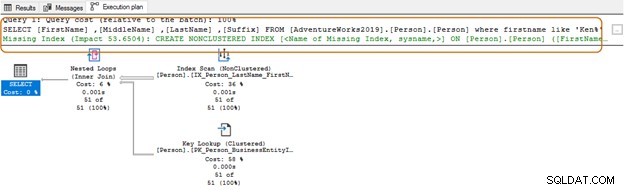
V níže uvedeném dotazu hledá řetězec Ken ve sloupci křestního jména. Tento dotaz načte očekávané výsledky Ken dra a Ken neth. Poskytuje však také neočekávané výsledky, například Macken zie a Nken ge.
V plánu provádění vidíte skenování indexu a vyhledávání klíčů pro výše uvedený dotaz.
Neočekávanému výsledku se můžete vyhnout použitím zástupného znaku na konci řetězce.
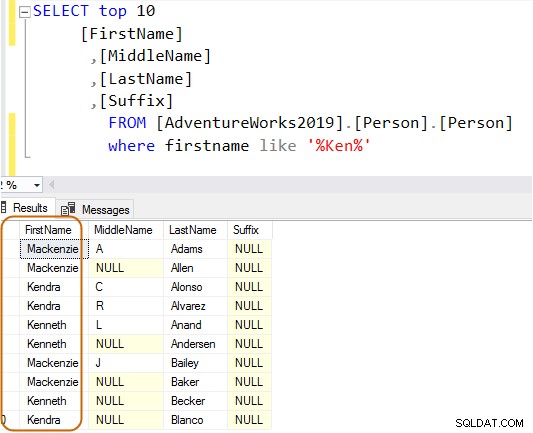
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Nyní získáte filtrovaný výsledek na základě vašich požadavků.
Při použití zástupného znaku na začátku nemusí být optimalizátor dotazu schopen použít vhodný index. Jak ukazuje níže uvedený snímek obrazovky, s koncovým zástupným znakem optimalizátor dotazů také navrhuje chybějící index.
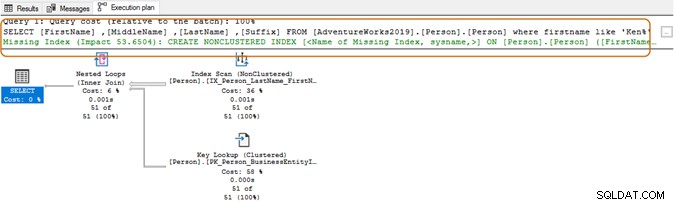
Zde budete chtít vyhodnotit požadavky vaší aplikace. Měli byste se pokusit vyhnout se použití zástupného znaku ve vyhledávacích řetězcích, protože by to mohlo přinutit optimalizátor dotazů použít skenování tabulky. Pokud je tabulka obrovská, vyžadovala by vyšší systémové prostředky pro IO, CPU a paměť a může způsobit problémy s výkonem vašeho SQL dotazu.
Použití klauzulí WHERE a HAVING
Klauzule WHERE a HAVING se používají jako filtry řádků dat. Klauzule WHERE filtruje data před použitím logiky seskupování, zatímco klauzule HAVING filtruje řádky po agregovaných výpočtech.
Například v níže uvedeném dotazu používáme datový filtr v klauzuli HAVING bez klauzule WHERE.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
Následující dotaz filtruje data nejprve v klauzuli WHERE a poté používá klauzuli HAVING pro filtr agregovaných dat.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
Doporučuji použít klauzuli WHERE pro filtrování dat a klauzuli HAVING pro filtr agregovaných dat jako osvědčený postup.
Použití klauzulí IN a EXISTS
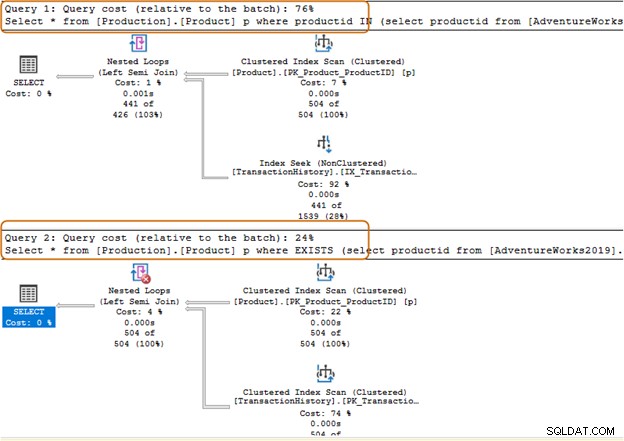
Měli byste se vyhnout použití klauzule IN-operátor pro vaše dotazy SQL. Například v níže uvedeném dotazu jsme nejprve našli id produktu z tabulky [Produkce].[Historie transakcí]) a poté jsme hledali odpovídající záznamy v tabulce [Produkce].[Produkt].
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
V níže uvedeném dotazu jsme nahradili klauzuli IN klauzulí EXISTS.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
Nyní porovnáme statistiky po provedení obou dotazů.
Klauzule IN používá 504 skenů, zatímco klauzule EXISTS používá 1 sken pro tabulku [Production].[TransactionHistory])].
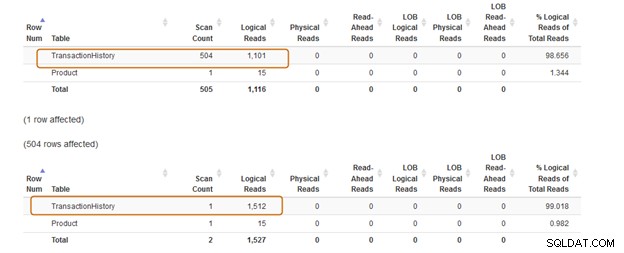
Dávka dotazu klauzule IN stojí 74 %, zatímco cena klauzule EXISTS je 24 %. Proto byste se měli vyhnout klauzuli IN, zejména pokud poddotaz vrací velkou datovou sadu.
Chybějící indexy
Někdy, když spustíme dotaz SQL a hledáme skutečný plán provádění v SSMS, dostanete návrh na index, který by mohl váš dotaz SQL zlepšit.
Případně můžete použít pohledy dynamické správy ke kontrole podrobností o chybějících indexech ve vašem prostředí.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Obvykle se DBA řídí radami SSMS a vytvářejí indexy. Momentálně by to mohlo zlepšit výkon dotazů. Neměli byste však vytvářet index přímo na základě těchto doporučení. Mohlo by to ovlivnit výkon jiných dotazů a zpomalit vaše příkazy INSERT a UPDATE.
- Nejprve zkontrolujte existující indexy pro vaši tabulku SQL.
- Všimněte si, že nadměrné i nedostatečné indexování je špatné pro výkon dotazů.
- Po zkontrolování stávajících indexů použijte chybějící doporučení indexu s nejvyšším dopadem a implementujte je do nižšího prostředí. Pokud vaše pracovní zatížení po implementaci nového chybějícího indexu funguje dobře, stojí za to přidat it.
Doporučuji vám nahlédnout do tohoto článku, kde najdete podrobné doporučené postupy indexování: 11 Doporučené postupy pro indexování SQL Serveru pro vylepšené ladění výkonu.
Nápovědy k dotazu
Vývojáři specifikují rady dotazů explicitně ve svých příkazech t-SQL. Tyto nápovědy k dotazu přepíší chování optimalizátoru dotazů a přinutí jej připravit plán provádění na základě nápovědy k dotazu. Často používané tipy pro dotazy jsou NOLOCK, Optimize For a Recompile Merge/Hash/Loop. Jsou to krátkodobé opravy vašich dotazů. Měli byste však pracovat na analýze svého dotazu, indexů, statistik a plánu provádění, abyste získali trvalé řešení.
Podle osvědčených postupů byste měli minimalizovat používání jakékoli nápovědy k dotazu. Chcete-li použít nápovědu k dotazu v dotazu SQL poté, co nejprve pochopíte jeho důsledky, a nepoužívejte je zbytečně.
Připomenutí optimalizace dotazů SQL
Jak jsme diskutovali, optimalizace dotazů SQL je cesta s otevřeným koncem. Můžete použít osvědčené postupy a malé opravy, které mohou výrazně zlepšit výkon. Zvažte následující tipy pro lepší vývoj dotazů:
- Vždy se podívejte na přidělení systémových prostředků (disky, CPU, paměť)
- Zkontrolujte příznaky trasování při spuštění, indexy a úlohy údržby databáze
- Analyzujte svou pracovní zátěž pomocí rozšířených událostí, profileru nebo nástrojů pro monitorování databáze třetích stran
- Vždy implementujte jakékoli řešení (i když jste si 100% jisti) nejprve v testovacím prostředí a analyzujte jeho dopad; jakmile budete spokojeni, naplánujte si produkční implementace