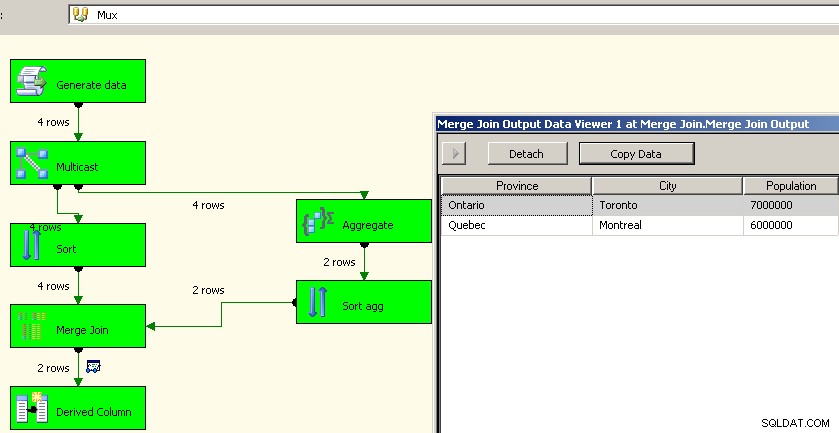
Naprostý souhlas s @PaulStock, že agregáty je nejlepší ponechat zdrojovým systémům. Agregát v SSIS je plně blokující komponenta podobně jako řazení a já mám v tomto bodě již argumentoval .
Ale jsou chvíle, kdy tyto operace ve zdrojovém systému prostě nebudou fungovat. To nejlepší, co se mi podařilo vymyslet, je v podstatě zdvojnásobit data. Ano, dobře, ale nikdy jsem nenašel způsob, jak projet kolonu bez ovlivnění. U scénářů Min/Max bych to chtěl jako možnost, ale něco jako Součet by samozřejmě znesnadnilo komponentě zjistit, ke kterému "zdrojovému" řádku by se připojila.
2005
Implementace z roku 2005 by vypadala takto. Váš výkon nebude dobrý, ve skutečnosti několik řádů od dobrého, protože tam budete mít všechny tyto blokující transformace a navíc budete muset znovu zpracovávat vaše zdrojová data.
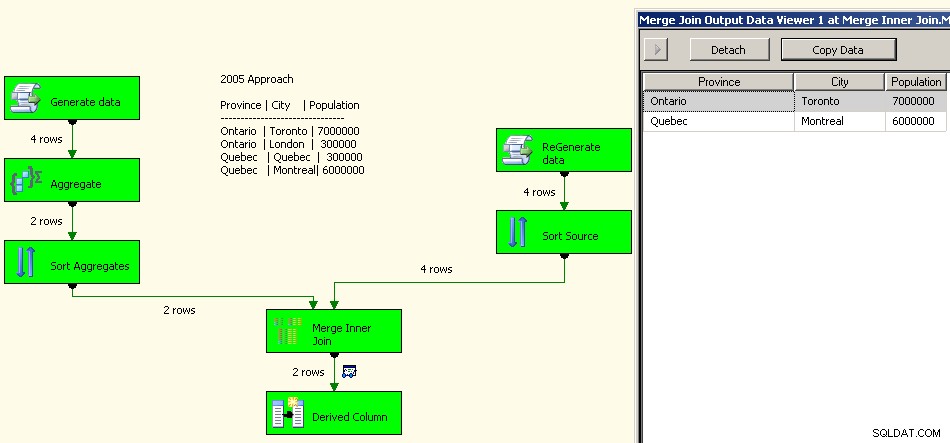
Sloučit se připojit 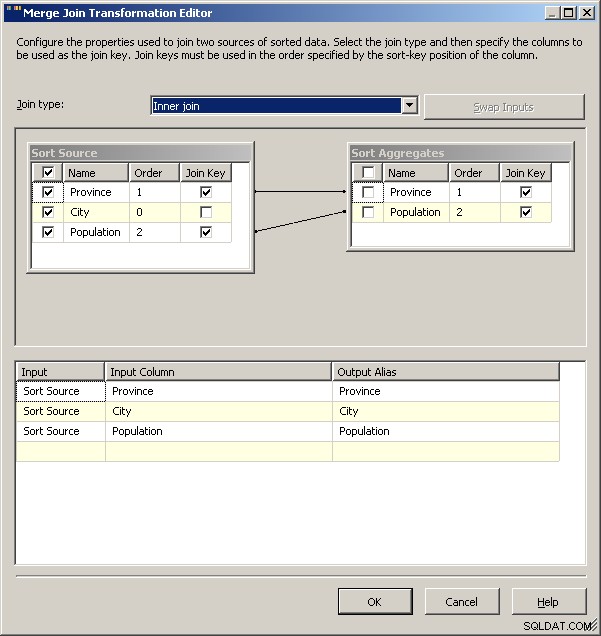
2008
V roce 2008 máte možnost použít Správce připojení mezipaměti což by pomohlo odstranit blokující transformace, alespoň tam, kde je to důležité, ale stále budete muset zaplatit náklady na dvojí zpracování vašich zdrojových dat.
Přetáhněte dva datové toky na plátno. První vyplní správce připojení mezipaměti a měl by být místem, kde se shromažďuje.
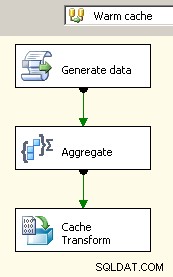
Nyní, když mezipaměť obsahuje agregovaná data, vypusťte vyhledávací úlohu do hlavního toku dat a proveďte vyhledávání v mezipaměti.
Karta Obecné vyhledávání
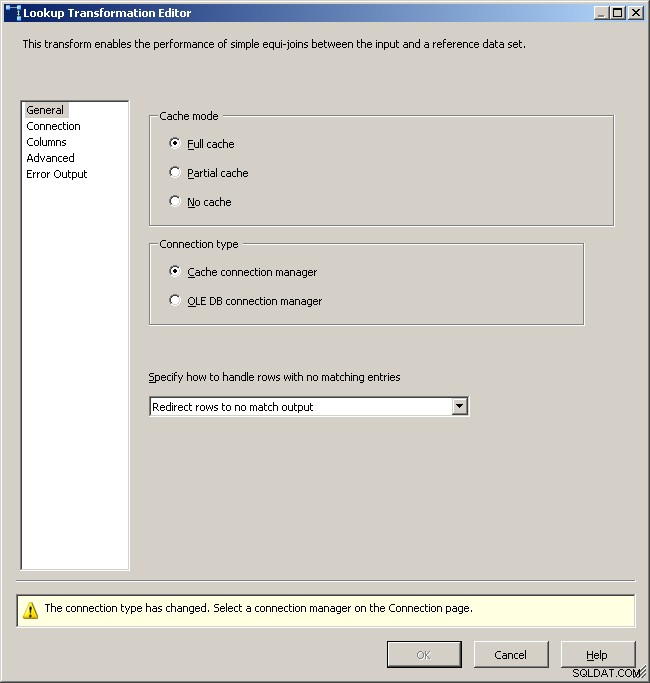
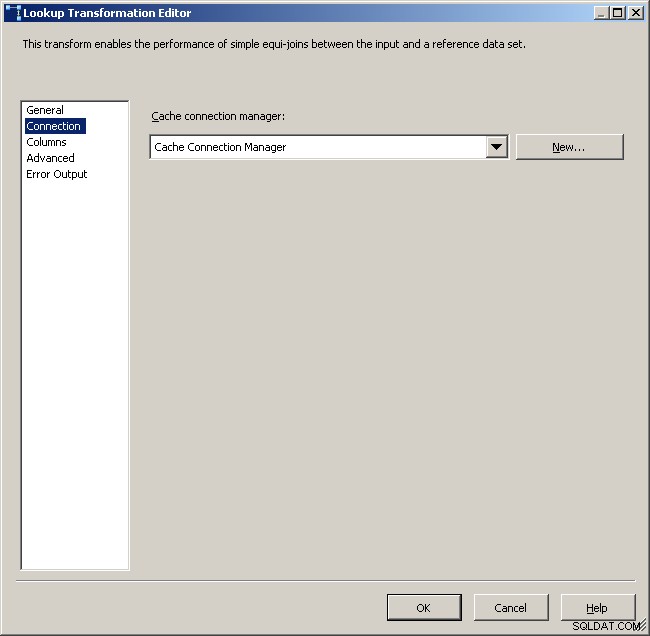
Vyberte správce připojení mezipaměti
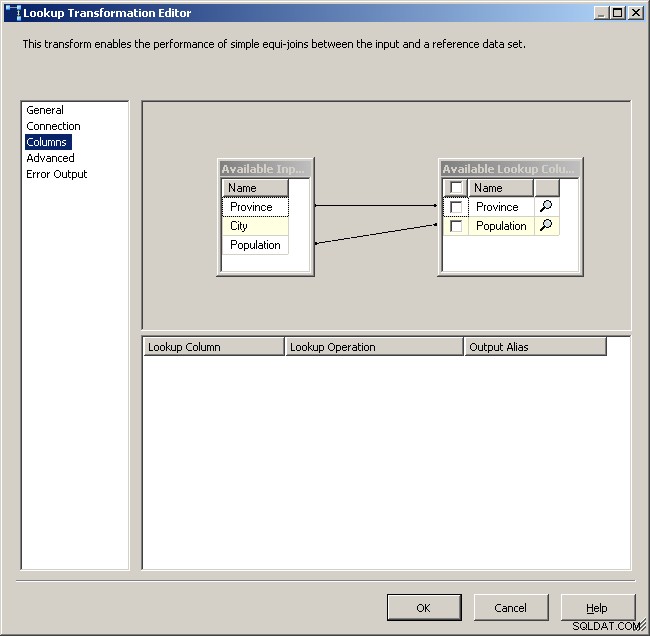
Mapujte příslušné sloupce
Velký úspěch 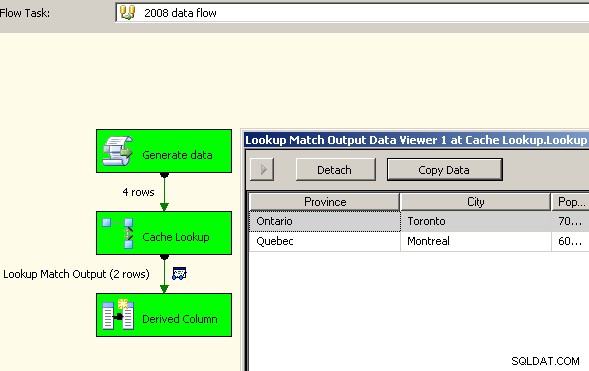
Úloha skriptu
Třetí přístup, který mě napadá, 2005 nebo 2008, je napsat si to sám. Obecným pravidlem je, že se snažím vyhýbat úlohám skriptu, ale toto je případ, kdy to pravděpodobně dává smysl. Budete z něj muset udělat asynchronní transformace skriptů ale jednoduše zpracujte své agregace tam. Více kódu k údržbě, ale můžete si ušetřit potíže s opětovným zpracováním zdrojových dat.
Nakonec, jako obecné upozornění, bych prozkoumal, co dopad vazeb udělá s vaším řešením. U tohoto souboru dat bych očekával, že něco jako Guelph náhle nabobtná a spojí Toronto, ale pokud ano, co by měl balíček dělat? Právě teď budou mít oba za následek 2 řádky pro Ontario, ale je to zamýšlené chování? Skript samozřejmě umožňuje definovat, co se stane v případě remíz. Pravděpodobně byste mohli postavit řešení z roku 2008 na hlavu tak, že uložíte „normální“ data do mezipaměti a použijete je jako podmínku vyhledávání a použijete agregáty k stažení pouze jedné z vazeb. 2005 pravděpodobně dokáže totéž, jen když uvede agregaci jako levý zdroj pro spojení sloučení
Úpravy
Jason Horner měl ve svém komentáři dobrý nápad. Jiným přístupem by bylo použití multicastové transformace a provedení agregace v jednom proudu a její opětovné spojení. Nemohl jsem přijít na to, jak to udělat, aby to fungovalo se sjednocením, ale mohli bychom použít řazení a sloučení spojení podobně jako výše. Toto je pravděpodobně lepší přístup, protože nám ušetří potíže s přepracováním zdrojových dat.