Důvod problému :
TOKEN metoda v SSIS používá implementaci strtok funkce v C++ . Tyto informace jsem získal při čtení knihy Microsoft® SQL Server® 2012 Integration Services
. Je to zmíněno jako poznámka na stránce 113 (Tato kniha se mi líbí! Spousta pěkných informací. ).
Hledal jsem implementaci strtok a našel jsem následující odkazy.
INFO:strtok():Funkce C -- Dodatek k dokumentaci - Ukázka kódu v tomto odkazu ukazuje, že funkce ignoruje po sobě jdoucí oddělovací znaky.
Odpovědi na následující otázky SO poukazují na to, že strtok funkce je navržena tak, aby ignorovala po sobě jdoucí oddělovače.
Potřebujete vědět, když se mezi dvěma oddělovači tokenů neobjeví žádná data pomocí strtok()
chování strtok_s s po sobě jdoucími oddělovači
Myslím, že TOKEN a TOKENCOUNT funkce fungují podle návrhu, ale zda se takto má chovat SSIS, může být otázkou pro tým Microsoft SSIS.
Původní příspěvek – výše uvedená sekce je aktualizace:
Vytvořil jsem jednoduchý balíček v SSIS 2012 na základě vašich datových vstupů. Jak jste popsali ve své otázce, TOKEN funkce se nechová tak, jak bylo zamýšleno. Souhlasím s vámi, že funkce zřejmě nefunguje. Tento příspěvek není odpověď na váš původní problém.
Zde je alternativní způsob, jak napsat výraz relativně jednodušším způsobem. To bude fungovat pouze v případě, že poslední segment ve vašem vstupním záznamu bude mít vždy hodnotu (řekněme A1 , B2 , C3 atd.).
Výraz lze přepsat jako :
Tento příkaz bude mít vstupní záznam jako parametr, oddělovací stříšku (^) jako druhý parametr. Třetí parametr vypočítá celkový počet segmentů v záznamech při rozdělení oddělovačem. Pokud máte data v posledním segmentu, máte zaručeno, že budete mít dva segmenty. Poté můžete odečíst 1 a získat předposlední segment.
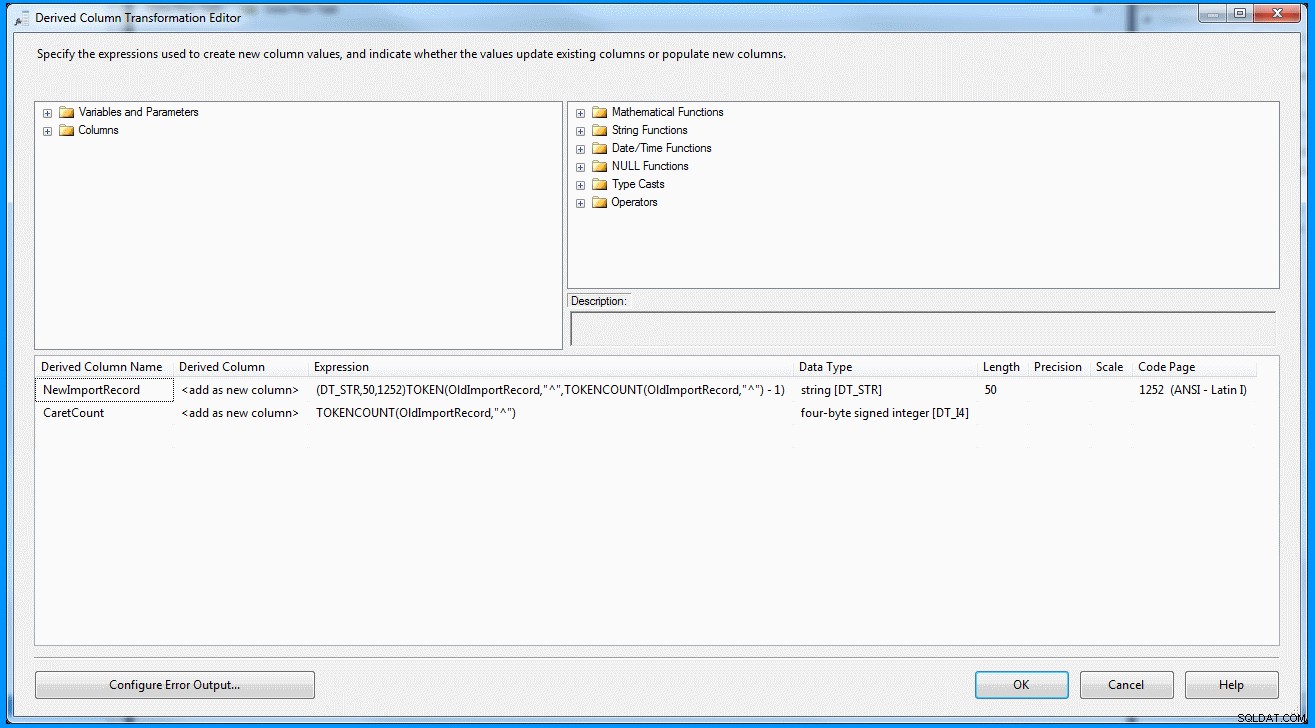
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
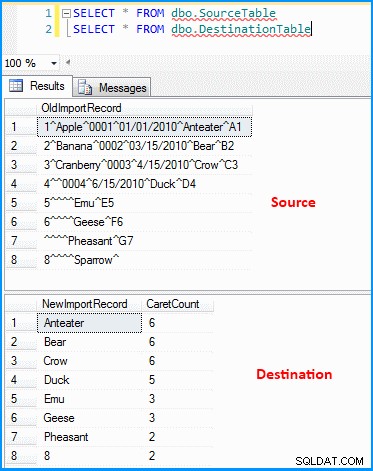
Vytvořil jsem jednoduchý balíček s úlohou datového toku. Zdroj OLE DB načte data a odvozená transformace analyzuje a rozdělí data podle níže uvedeného snímku obrazovky. Výstup je poté vložen do cílové tabulky. Zdrojové a cílové tabulky můžete vidět na posledním snímku obrazovky. Tabulka cílů má dva sloupce. První sloupec obsahuje data předposledního segmentu a počet segmentů na základě oddělovače (což opět není správné). Můžete si všimnout, že poslední záznam nepřinesl správné výsledky. Pokud poslední záznam neměl hodnotu 8 , pak výše uvedený výraz selže, protože výraz bude vyhodnocen jako nulový index.
Doufám, že to pomůže zjednodušit váš výraz.
Pokud se vám nikdo jiný neozve, doporučil bych zaznamenat tento problém na webu Microsoft Connect .
Vytvořte tabulku a naplňte skripty :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
Odvozená transformace sloupců v rámci úlohy toku dat :
Data ve zdrojových a cílových tabulkách :