Neexistuje žádný relevantní pevně zakódovaný limit (65 536 * Velikost síťového paketu 4 kB je 268 MB a délka vašeho skriptu se tomu ani zdaleka neblíží), i když se nedoporučuje používat tuto metodu pro velké množství řádků.
Chyba, kterou vidíte, je vyvolána klientskými nástroji, nikoli SQL Serverem. Pokud vytvoříte řetězec SQL v dynamické kompilaci SQL, může se alespoň úspěšně spustit
DECLARE @SQL NVARCHAR(MAX) = '(100,200,300),
';
SELECT @SQL = 'SELECT * FROM (VALUES ' + REPLICATE(@SQL, 1000000) + '
(100,200,300)) tc (proj_d, period_sid, val)';
SELECT @SQL AS [processing-instruction(x)]
FOR XML PATH('')
SELECT DATALENGTH(@SQL) / 1048576.0 AS [Length in MB] --30.517705917
EXEC(@SQL);
I když jsem výše uvedené zabil po ~30 minutách kompilace a stále to nevyvolalo řadu. Doslovné hodnoty musí být uloženy uvnitř samotného plánu jako tabulka konstant a SQL Server utratí spousta času snaží se o nich také odvodit vlastnosti.
SSMS je 32bitová aplikace a vyvolá std::bad_alloc výjimka při analýze dávky
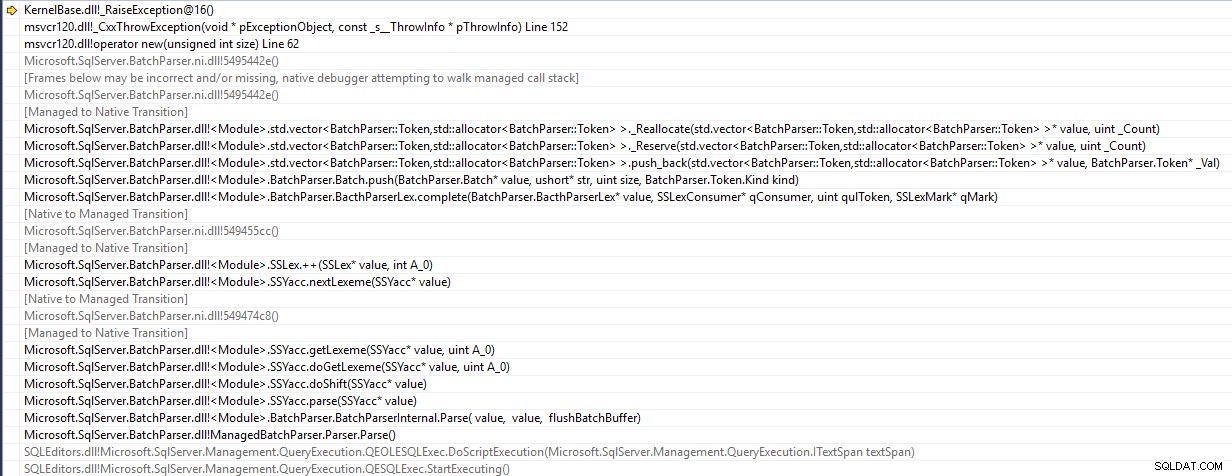
Snaží se vložit prvek do vektoru tokenu, který dosáhl kapacity, a jeho pokus o změnu velikosti selže kvůli nedostupnosti dostatečně velké souvislé oblasti paměti. Takže prohlášení se nikdy nedostane až na server.
Kapacita vektoru pokaždé vzroste o 50 % (tj. podle sekvence zde ). Kapacita, na kterou vektor potřebuje růst, závisí na tom, jak je kód rozvržen.
Následující potřebuje zvýšit kapacitu z 19 na 28.
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
a následující potřebuje pouze velikost 2
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
Následující vyžaduje kapacitu> 63 a <=94.
SELECT *
FROM (VALUES
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300)
) tc (proj_d, period_sid, val)
Pro milion řádků rozložených jako v případě 1 musí vektorová kapacita vzrůst na 3 543 306.
Možná zjistíte, že některá z následujících možností umožní úspěšné analýze na straně klienta.
- Snižte počet zalomení řádků.
- Restartování SSMS v naději, že požadavek na velkou souvislou paměť bude úspěšný, když dojde k menší fragmentaci adresního prostoru.
I když jej však úspěšně odešlete na server, stejně to skončí pouze zabitím serveru během generování plánu provádění, jak je uvedeno výše.
K načtení tabulky budete mnohem lépe používat průvodce importem a exportem. Pokud to musíte udělat v TSQL, zjistíte, že rozdělení na menší dávky a/nebo použití jiné metody, jako je skartování XML, bude fungovat lépe než tabulkové konstruktory. Následující se například na mém počítači spustí za 13 sekund (i když při použití SSMS byste se pravděpodobně museli rozdělit do několika dávek, místo abyste vkládali masivní řetězcový literál XML).
DECLARE @S NVARCHAR(MAX) = '<x proj_d="100" period_sid="200" val="300" />
' ;
DECLARE @Xml XML = REPLICATE(@S,1000000);
SELECT
x.value('@proj_d','int'),
x.value('@period_sid','int'),
x.value('@val','int')
FROM @Xml.nodes('/x') c(x)