Python a SQL jsou dva nejdůležitější jazyky pro datové analytiky.
V tomto článku vás provedu vším, co potřebujete vědět k propojení Pythonu a SQL.
Dozvíte se, jak stahovat data z relačních databází přímo do vašich kanálů strojového učení, ukládat data z vaší Python aplikace do vlastní databáze nebo jakkoli jiného případu použití, se kterým můžete přijít.
Společně pokryjeme:
- Proč se učit, jak používat Python a SQL společně?
- Jak nastavit prostředí Python a server MySQL
- Připojení k serveru MySQL v Pythonu
- Vytvoření nové databáze
- Vytváření tabulek a vztahů mezi tabulkami
- Naplňování tabulek daty
- Čtení dat
- Aktualizace záznamů
- Mazání záznamů
- Vytváření záznamů ze seznamů Python
- Vytváření znovu použitelných funkcí, které to vše za nás v budoucnu udělá
To je spousta velmi užitečných a velmi cool věcí. Pojďme do toho!
Rychlá poznámka, než začneme:v tomto úložišti GitHub je k dispozici notebook Jupyter obsahující veškerý kód použitý v tomto tutoriálu. Důrazně doporučujeme kódování!
Zde použitá databáze a kód SQL jsou všechny z mé předchozí série Úvod do SQL zveřejněné na Towards Data Science (kontaktujte mě, pokud máte nějaké problémy se zobrazením článků, a já vám mohu zdarma poslat odkaz na jejich zobrazení).
Pokud nejste obeznámeni s SQL a koncepty za relačními databázemi, rád bych vás nasměroval na tuto sérii (a samozřejmě je zde na freeCodeCamp k dispozici obrovské množství skvělých věcí!)
Proč Python s SQL?
Pro datové analytiky a datové vědce má Python mnoho výhod. Obrovská škála open-source knihoven z něj dělá neuvěřitelně užitečný nástroj pro každého datového analytika.
Máme pandy, NumPy a Vaex pro analýzu dat, Matplotlib, seaborn a Bokeh pro vizualizaci a TensorFlow, scikit-learn a PyTorch pro aplikace strojového učení (plus mnoho, mnoho dalších).
Díky své (relativně) snadné křivce učení a všestrannosti není divu, že Python je jedním z nejrychleji rostoucích programovacích jazyků.
Pokud tedy pro analýzu dat používáme Python, stojí za to se zeptat – odkud všechna tato data pocházejí?
I když existuje obrovské množství zdrojů pro datové sady, v mnoha případech – zejména v podnikových podnicích – budou data uložena v relační databázi. Relační databáze jsou extrémně efektivní, výkonný a široce používaný způsob vytváření, čtení, aktualizace a mazání dat všeho druhu.
Nejrozšířenější systémy pro správu relačních databází (RDBMS) - Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 - všechny používají Structured Query Language (SQL) pro přístup k datům a provádění změn v nich.
Všimněte si, že každý RDBMS používá mírně odlišnou variantu SQL, takže kód SQL napsaný pro jednoho obvykle nebude fungovat v jiném bez (obvykle poměrně malých) úprav. Ale koncepty, struktury a operace jsou do značné míry totožné.
To znamená, že pro pracujícího datového analytika je silné porozumění SQL nesmírně důležité. Znalost toho, jak používat Python a SQL společně, vám poskytne ještě větší výhodu, pokud jde o práci s vašimi daty.
Zbytek tohoto článku bude věnován tomu, abychom vám přesně ukázali, jak to můžeme udělat.
Začínáme
Požadavky a instalace
Abyste mohli kódovat spolu s tímto tutoriálem, budete potřebovat nastavení vlastního prostředí Pythonu.
Používám Anacondu, ale existuje mnoho způsobů, jak to udělat. Pokud potřebujete další pomoc, stačí vygooglovat „jak nainstalovat Python“. Můžete také použít Binder ke kódování spolu s přidruženým Jupyter Notebookem.
Budeme používat MySQL Community Server, protože je zdarma a široce používaný v oboru. Pokud používáte Windows, tato příručka vám pomůže s nastavením. Zde jsou příručky také pro uživatele Mac a Linux (ačkoli se mohou lišit podle distribuce Linuxu).
Jakmile je nastavíte, budeme je muset přimět, aby spolu komunikovaly.
K tomu potřebujeme nainstalovat knihovnu MySQL Connector Python. Chcete-li to provést, postupujte podle pokynů nebo použijte pip:
pip install mysql-connector-pythonBudeme také používat pandy, takže se ujistěte, že je máte nainstalované také.
pip install pandasImport knihoven
Jako u každého projektu v Pythonu, úplně první věc, kterou chceme udělat, je importovat naše knihovny.
Nejlepší praxí je naimportovat všechny knihovny, které budeme používat na začátku projektu, aby lidé, kteří čtou nebo kontrolují náš kód, zhruba věděli, co se chystá, aby nedošlo k žádnému překvapení.
Pro tento tutoriál použijeme pouze dvě knihovny – MySQL Connector a pandy.
import mysql.connector
from mysql.connector import Error
import pandas as pdFunkci Error importujeme samostatně, abychom k ní měli snadný přístup pro naše funkce.
Připojování k serveru MySQL
V tomto okamžiku bychom měli mít v našem systému nastaven server MySQL Community Server. Nyní musíme napsat nějaký kód v Pythonu, který nám umožní navázat spojení s tímto serverem.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionVytváření opakovaně použitelné funkce pro kód, jako je tento, je osvědčeným postupem, abychom jej mohli používat znovu a znovu s minimálním úsilím. Jakmile to bude napsáno, budete to moci znovu použít ve všech svých projektech v budoucnu, takže v budoucnu – budete vděční!
Pojďme si projít tento řádek po řádku, abychom pochopili, co se zde děje:
První řádek je, že pojmenujeme funkci (create_server_connection) a pojmenujeme argumenty, které tato funkce bude mít (host_name, user_name a user_password).
Další řádek uzavře všechna existující připojení, aby nedošlo k záměně serveru s více otevřenými připojeními.
Dále použijeme blok try-except v Pythonu ke zpracování případných chyb. První část se pokouší vytvořit připojení k serveru pomocí metody mysql.connector.connect() s použitím podrobností zadaných uživatelem v argumentech. Pokud to funguje, funkce vytiskne radostnou zprávu o malém úspěchu.
Mimo část bloku vypíše chybu, kterou MySQL Server vrátí, za nešťastných okolností, že došlo k chybě.
Nakonec, pokud je připojení úspěšné, funkce vrátí objekt připojení.
Toho využíváme v praxi tak, že výstup funkce přiřadíme proměnné, která se pak stane naším spojovacím objektem. Pak na něj můžeme aplikovat další metody (např. kurzor) a vytvářet další užitečné objekty.
connection = create_server_connection("localhost", "root", pw)To by mělo vytvořit zprávu o úspěchu:

Vytvoření nové databáze
Nyní, když jsme navázali spojení, je naším dalším krokem vytvoření nové databáze na našem serveru.
V tomto tutoriálu to uděláme pouze jednou, ale znovu to napíšeme jako znovu použitelnou funkci, takže máme hezkou užitečnou funkci, kterou můžeme znovu použít pro budoucí projekty.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Tato funkce má dva argumenty, připojení (náš objekt připojení) a dotaz (SQL dotaz, který napíšeme v dalším kroku). Provede dotaz na serveru prostřednictvím připojení.
K vytvoření objektu kurzoru používáme metodu kurzoru na našem objektu připojení (MySQL Connector používá objektově orientované programovací paradigma, takže existuje spousta objektů, které dědí vlastnosti z nadřazených objektů).
Tento objekt kurzoru má metody, jako je spustit, vykonat mnoho (které použijeme v tomto tutoriálu) spolu s několika dalšími užitečnými metodami.
Pokud to pomůže, můžeme si objekt kurzoru představit tak, že nám poskytuje přístup k blikajícímu kurzoru v okně terminálu serveru MySQL.
Dále definujeme dotaz pro vytvoření databáze a zavoláme funkci:

Všechny dotazy SQL použité v tomto tutoriálu jsou vysvětleny v mé sérii výukových programů Úvod do SQL a úplný kód lze nalézt v souvisejícím notebooku Jupyter v tomto úložišti GitHub, takže nebudu poskytovat vysvětlení toho, co kód SQL v tomto dělá. tutoriál.
Toto je však možná nejjednodušší SQL dotaz. Pokud umíte číst anglicky, pravděpodobně zjistíte, co to dělá!
Spuštění funkce create_database s výše uvedenými argumenty vede k vytvoření databáze nazvané 'school' na našem serveru.
Proč se naše databáze jmenuje „škola“? Možná by teď byl vhodný čas podívat se podrobněji na to, co přesně implementujeme v tomto tutoriálu.
Naše databáze
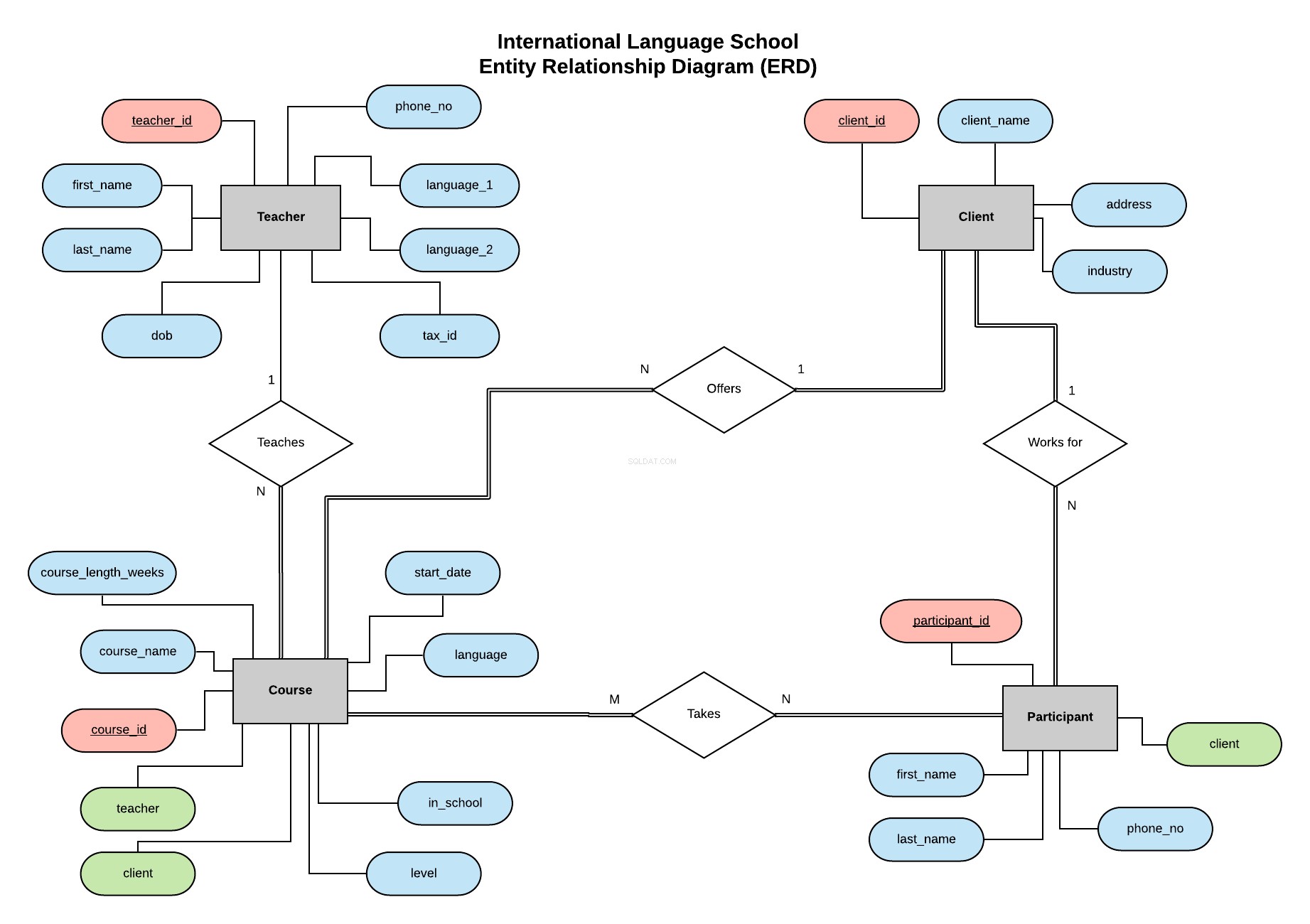
Po vzoru mého předchozího seriálu budeme implementovat databázi pro International Language School - fiktivní jazykovou školu, která poskytuje profesionální jazykové lekce firemním klientům.
Tento diagram vztahů entit (ERD) popisuje naše entity (učitel, klient, kurz a účastník) a definuje vztahy mezi nimi.
Všechny informace o tom, co je ERD a co je třeba vzít v úvahu při jeho vytváření a návrhu databáze, naleznete v tomto článku.
Nezpracovaný kód SQL, požadavky na databázi a data pro vstup do databáze, to vše je obsaženo v tomto úložišti GitHub, ale vše uvidíte, až si projdeme tento tutoriál.
Připojování k databázi
Nyní, když jsme vytvořili databázi na serveru MySQL, můžeme upravit naši funkci create_server_connection tak, aby se k této databázi připojovala přímo.
Všimněte si, že je možné – ve skutečnosti běžné – mít více databází na jednom serveru MySQL, takže se chceme vždy a automaticky připojit k databázi, která nás zajímá.
Můžeme to udělat takto:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionToto je přesně stejná funkce, ale nyní vezmeme ještě jeden argument – název databáze – a předáme jej jako argument metodě connect().
Vytvoření funkce spuštění dotazu
Poslední funkce, kterou (prozatím) vytvoříme, je extrémně důležitá – funkce pro provádění dotazu. Toto vezme naše SQL dotazy uložené v Pythonu jako řetězce a předá je metodě kurzor.execute(), aby je provedla na serveru.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Tato funkce je přesně stejná jako naše dřívější funkce create_database, kromě toho, že používá metodu connection.commit() k zajištění implementace příkazů podrobně popsaných v našich dotazech SQL.
Toto bude naše funkce tahouna, kterou budeme používat (vedle create_db_connection) k vytváření tabulek, navazování vztahů mezi těmito tabulkami, naplňování tabulek daty a aktualizaci a mazání záznamů v naší databázi.
Pokud jste odborník na SQL, tato funkce vám umožní provádět všechny složité příkazy a dotazy, které se vám mohou povalovat, přímo ze skriptu Python. To může být velmi mocný nástroj pro správu vašich dat.
Vytváření tabulek
Nyní jsme všichni připraveni začít spouštět SQL příkazy na náš server a začít budovat naši databázi. První věc, kterou chceme udělat, je vytvořit potřebné tabulky.
Začněme naší tabulkou učitelů:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryNejprve přiřadíme náš SQL příkaz (podrobně vysvětlený zde) do proměnné s příslušným názvem.
V tomto případě používáme Pythonův zápis s trojitými uvozovkami pro víceřádkové řetězce k uložení našeho SQL dotazu a poté jej zavedeme do naší funkce execute_query, abychom jej implementovali.
Všimněte si, že toto víceřádkové formátování je čistě ve prospěch lidí, kteří čtou náš kód. SQL ani Python se „nestarají“ o to, zda je příkaz SQL takto rozložen. Pokud je syntaxe správná, oba jazyky ji přijmou.
Ve prospěch lidí, kteří budou číst váš kód, (i když to bude pouze budoucnost – vy!) je však velmi užitečné to udělat, aby byl kód čitelnější a srozumitelnější.
Totéž platí pro KAPITALIZACI operátorů v SQL. Toto je široce používaná konvence, která se důrazně doporučuje, ale skutečný software, který spouští kód, nerozlišuje velká a malá písmena a bude s příkazy „CREATE TABLE teacher“ a „create table teacher“ zacházet jako s identickými příkazy.

Spuštění tohoto kódu nám dává zprávy o úspěchu. Můžeme to také ověřit v klientovi příkazového řádku serveru MySQL:
Skvělý! Nyní vytvoříme zbývající tabulky.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Tím se vytvoří čtyři tabulky potřebné pro naše čtyři entity.
Nyní chceme definovat vztahy mezi nimi a vytvořit jednu další tabulku pro zpracování vztahu many-to-many mezi tabulkami účastníků a kurzů (další podrobnosti viz zde).
Děláme to úplně stejným způsobem:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Nyní jsou vytvořeny naše tabulky spolu s příslušnými omezeními, primárním klíčem a vztahy cizích klíčů.
Vyplnění tabulek
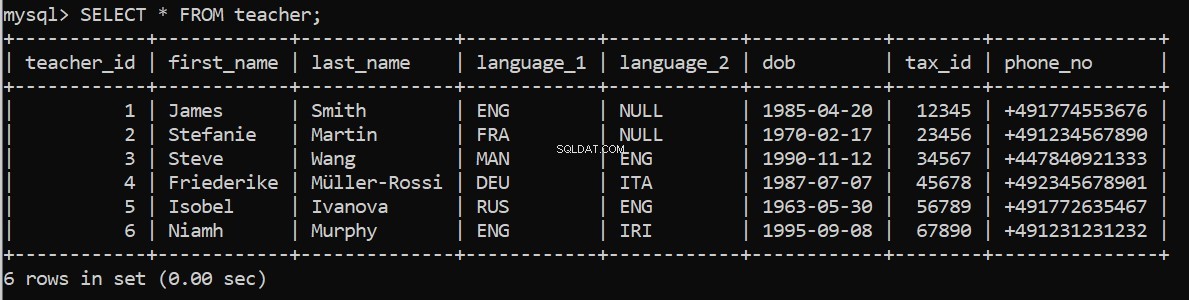
Dalším krokem je přidání některých záznamů do tabulek. Opět používáme execute_query k vložení našich existujících SQL příkazů na server. Začněme znovu tabulkou Učitel.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)Funguje to? Můžeme to znovu zkontrolovat v našem klientovi příkazového řádku MySQL:
Nyní k naplnění zbývajících tabulek.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Úžasný! Nyní jsme vytvořili databázi kompletní se vztahy, omezeními a záznamy v MySQL, s použitím pouze příkazů Pythonu.
Prošli jsme to krok za krokem, aby to bylo srozumitelné. Ale v tomto okamžiku můžete vidět, že to vše lze velmi snadno zapsat do jednoho skriptu Python a spustit jedním příkazem v terminálu. Mocná věc.
Čtení dat
Nyní máme funkční databázi, se kterou můžeme pracovat. Jako datový analytik pravděpodobně přijdete do kontaktu se stávajícími databázemi v organizacích, kde pracujete. Bude velmi užitečné vědět, jak vytáhnout data z těchto databází, aby je pak bylo možné vložit do vašeho datového kanálu pythonu. To je to, na čem budeme dále pracovat.
K tomu budeme potřebovat ještě jednu funkci, tentokrát pomocí kurzoru.fetchall() místo kurzoru.commit(). Pomocí této funkce načítáme data z databáze a neprovádíme žádné změny.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Opět to budeme implementovat velmi podobným způsobem jako execute_query. Vyzkoušejte to jednoduchým dotazem, abyste viděli, jak to funguje.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)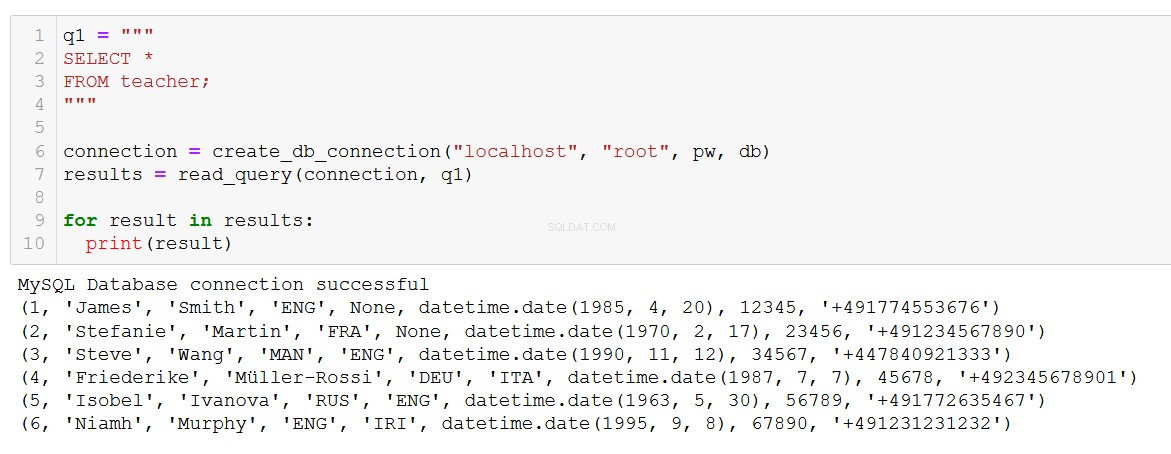
Přesně to, co očekáváme. Funkce také funguje se složitějšími dotazy, jako je tento zahrnující JOIN na kurz a klientské tabulky.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)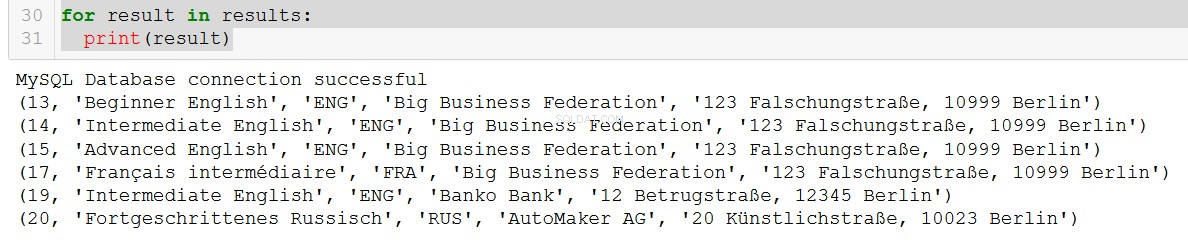
Velmi hezké.
Pro naše datové kanály a pracovní postupy v Pythonu možná budeme chtít získat tyto výsledky v různých formátech, aby byly užitečnější nebo připravenější k manipulaci.
Pojďme si projít několik příkladů, abychom viděli, jak to můžeme udělat.
Formátování výstupu do seznamu
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Formátování výstupu na seznam seznamů
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Formátování výstupu do datového rámce pandas
Pro datové analytiky používající Python jsou pandy naším krásným a důvěryhodným starým přítelem. Je velmi jednoduché převést výstup z naší databáze do DataFrame a odtud jsou možnosti nekonečné!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)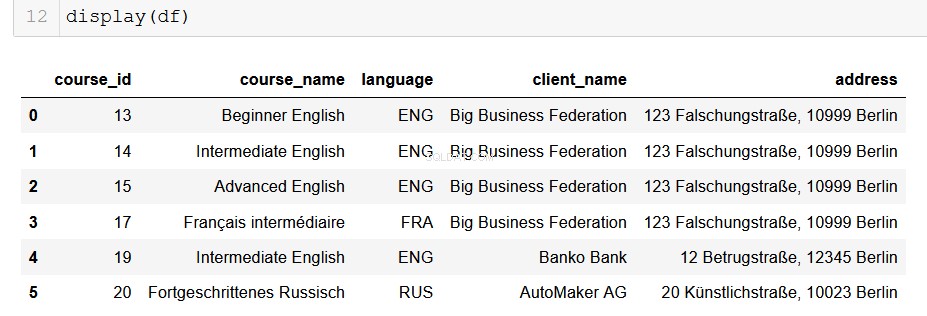
Doufejme, že zde vidíte možnosti, které se před vámi otevírají. Pomocí několika řádků kódu můžeme snadno extrahovat všechna data, se kterými můžeme pracovat, z relačních databází, kde žijí, a přenést je do našich nejmodernějších kanálů pro analýzu dat. To je opravdu užitečná věc.
Aktualizace záznamů
Když udržujeme databázi, někdy budeme muset provést změny ve stávajících záznamech. V této části se podíváme na to, jak to udělat.
Řekněme, že ILS je informováno, že jeden z jejích stávajících klientů, Big Business Federation, přesouvá kanceláře na 23 Fingiertweg, 14534 Berlín. V tomto případě bude muset správce databáze (to jsme my!) provést nějaké změny.
Naštěstí to můžeme udělat pomocí naší funkce execute_query spolu s příkazem SQL UPDATE.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Všimněte si, že klauzule WHERE je zde velmi důležitá. Pokud spustíme tento dotaz bez klauzule WHERE, pak by se všechny adresy pro všechny záznamy v naší tabulce Klient aktualizovaly na 23 Fingiertweg. To není to, co chceme udělat.
Všimněte si také, že jsme v dotazu UPDATE použili "WHERE client_id =101". Bylo by také možné použít "WHERE client_name ='Big Business Federation'" nebo "WHERE address ='123 Falschungstraße, 10999 Berlin'" nebo dokonce "WHERE address LIKE '%Falschung%'".
Důležité je, že klauzule WHERE nám umožňuje jednoznačně identifikovat záznam (nebo záznamy), který chceme aktualizovat.
Mazání záznamů
Je také možné použít naši funkci execute_query k odstranění záznamů pomocí DELETE.
Při použití SQL s relačními databázemi musíme být opatrní při používání operátoru DELETE. Toto není Windows, není zde žádné 'Opravdu to chcete smazat?' varovné vyskakovací okno a není zde žádný odpadkový koš. Jakmile něco smažeme, je to opravdu pryč.
S tím, co bylo řečeno, opravdu někdy potřebujeme věci mazat. Pojďme se na to tedy podívat odstraněním kurzu z naší tabulky kurzů.
Nejprve si připomeňme, jaké kurzy máme.
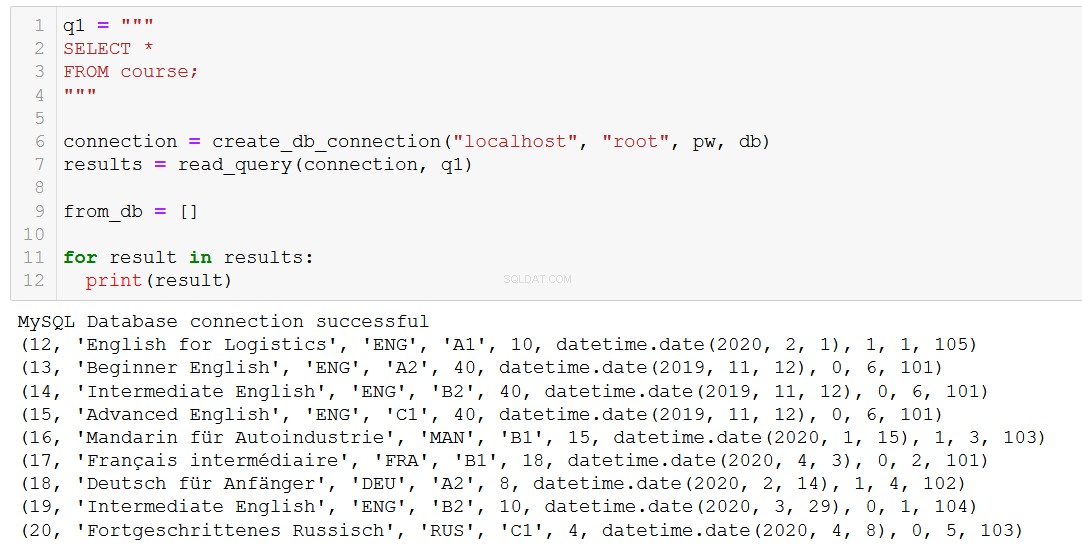
Řekněme, že kurz 20, 'Fortgeschrittenes Russisch' (to je 'Pokročilá ruština' pro vás a mě), se blíží ke konci, takže jej musíme odstranit z naší databáze.
V této fázi vás už vůbec nepřekvapí, jak to děláme - uložte příkaz SQL jako řetězec a poté jej vložte do naší funkce vykonat_dotaz.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Zkontrolujeme, zda to mělo zamýšlený účinek:
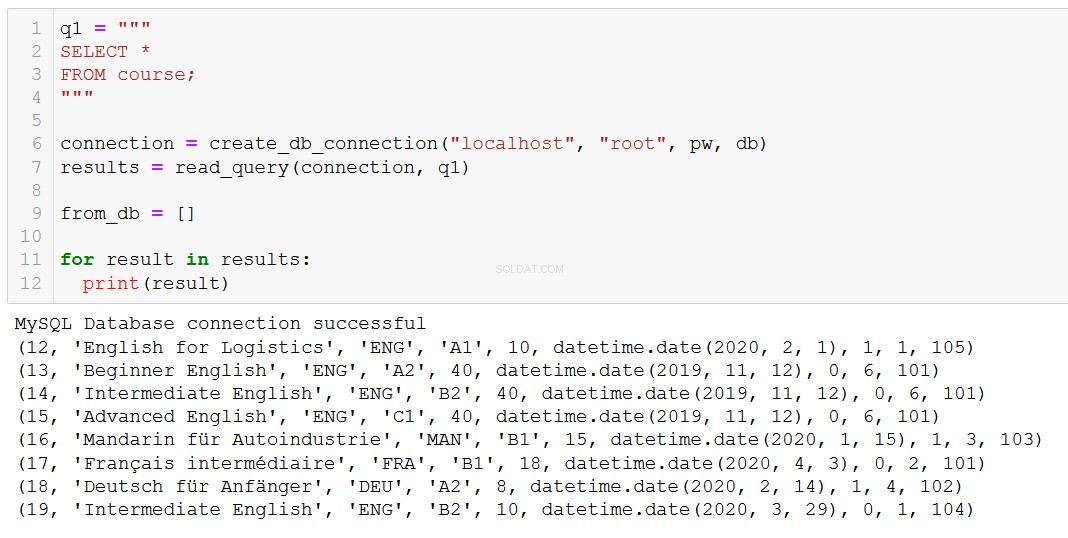
„Pokročilá ruština“ je pryč, jak jsme očekávali.
Funguje to také s mazáním celých sloupců pomocí DROP COLUMN a celých tabulek pomocí příkazů DROP TABLE, ale těmi se v tomto tutoriálu nebudeme zabývat.
Pokračujte a experimentujte s nimi – nezáleží na tom, zda smažete sloupec nebo tabulku z databáze pro fiktivní školu, a je dobré se s těmito příkazy seznámit, než se přesunete do produkčního prostředí.
Ach CRUD
V tomto okamžiku jsme nyní schopni dokončit čtyři hlavní operace pro trvalé ukládání dat.
Naučili jsme se, jak:
- Vytvářejte – zcela nové databáze, tabulky a záznamy
- Číst – extrahovat data z databáze a ukládat je v různých formátech
- Aktualizovat – provádět změny existujících záznamů v databázi
- Smazat – odstraní záznamy, které již nejsou potřeba
To jsou fantasticky užitečné věci, které můžete dělat.
Než to tady dokončíme, musíme se naučit ještě jednu velmi užitečnou dovednost.
Vytváření záznamů ze seznamů
Při naplňování našich tabulek jsme viděli, že k vložení záznamů do naší databáze můžeme použít příkaz SQL INSERT v naší funkci execute_query.
Vzhledem k tomu, že k manipulaci s naší SQL databází používáme Python, bylo by užitečné mít možnost vzít datovou strukturu Pythonu (například seznam) a vložit ji přímo do naší databáze.
To by mohlo být užitečné, když chceme ukládat záznamy o aktivitě uživatelů v aplikaci sociálních médií, kterou jsme napsali v Pythonu, nebo například vstupy od uživatelů do námi vytvořené Wiki. Existuje tolik možných využití, kolik vás napadne.
Tato metoda je také bezpečnější, pokud je naše databáze kdykoli otevřena našim uživatelům, protože pomáhá předcházet útokům SQL Injection, které mohou poškodit nebo dokonce zničit celou naši databázi.
Abychom toho dosáhli, napíšeme funkci pomocí metody executemany() namísto jednodušší metody execute(), kterou jsme dosud používali.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Nyní máme funkci, potřebujeme definovat SQL příkaz ('sql') a seznam obsahující hodnoty, které chceme vložit do databáze ('val'). Hodnoty musí být uloženy jako seznam n-tic, což je poměrně běžný způsob ukládání dat v Pythonu.
Chcete-li přidat dva nové učitele do databáze, můžeme napsat nějaký kód, jako je tento:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Všimněte si, že v kódu 'sql' používáme '%s' jako zástupný symbol pro naši hodnotu. Podobnost se zástupným symbolem '%s' pro řetězec v pythonu je pouze náhodná (a upřímně řečeno velmi matoucí), chceme použít '%s' pro všechny datové typy (řetězce, ints, data atd.) s MySQL Pythonem Konektor.
Na Stackoverflow můžete vidět řadu otázek, kde se někdo zmátl a pokusil se použít zástupné symboly '%d' pro celá čísla, protože je na to zvyklý v Pythonu. Tady to nebude fungovat – musíme použít '%s' pro každý sloupec, do kterého chceme přidat hodnotu.
Funkce executemany pak vezme každou n-tici v našem seznamu 'val' a vloží příslušnou hodnotu pro tento sloupec na místo zástupného symbolu a provede příkaz SQL pro každou n-tici obsaženou v seznamu.
To lze provést pro více řádků dat, pokud jsou správně naformátovány. V našem příkladu přidáme pouze dva nové učitele pro ilustraci, ale v zásadě jich můžeme přidat, kolik bychom chtěli.
Pokračujme a spusťte tento dotaz a přidejte učitele do naší databáze.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)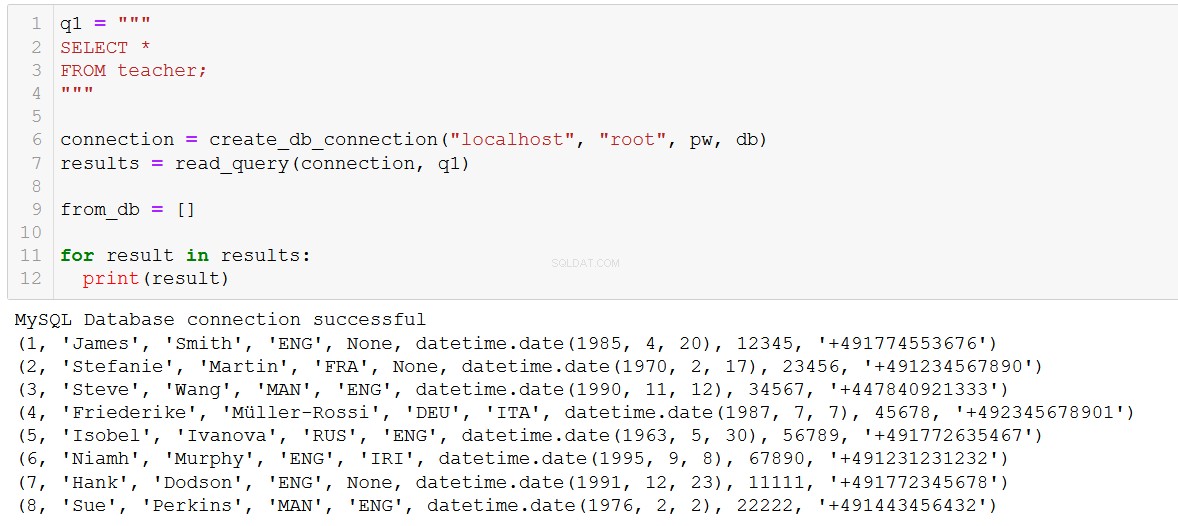
Vítejte v ILS, Hanku a Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Závěr
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!
