Replikace MySQL je nejběžnějším a nejrozšířenějším řešením pro vysokou dostupnost obrovskými organizacemi, jako jsou Github, Twitter a Facebook. Přestože je nastavení snadné, při používání tohoto řešení se potýkají s problémy z oblasti údržby, včetně upgradů softwaru, posunu dat nebo nekonzistence dat napříč uzly replik, změn topologie, převzetí služeb při selhání a obnovy. Když MySQL vydala verzi 5.6, přinesla řadu významných vylepšení, zejména replikaci, která zahrnuje globální transakční ID (GTID), kontrolní součty událostí, vícevláknové slave a slave/mastery bezpečné při havárii. Replikace se ještě zlepšila s MySQL 5.7 a MySQL 8.0.
Replikace umožňuje replikaci dat z jednoho serveru MySQL (primárního/hlavního) na jeden nebo více serverů MySQL (replika/podřízené). Replikace MySQL se velmi snadno nastavuje a používá se ke škálování zátěže čtení, poskytování vysoké dostupnosti a geografické redundance a snižování zátěže záloh a analytických úloh.
Replikace MySQL v přírodě
Udělejme si rychlý přehled o tom, jak replikace MySQL přirozeně funguje. Replikace MySQL je široká a existuje několik způsobů, jak ji nakonfigurovat a jak ji lze použít. Ve výchozím nastavení používá asynchronní replikaci, která funguje po dokončení transakce v místním prostředí. Neexistuje žádná záruka, že se nějaká událost někdy dostane k nějakému otrokovi. Je to volně propojený vztah mezi pánem a otrokem, kde:
-
Primární nečeká na repliku.
-
Replika určuje, kolik se má číst a od kterého bodu v binárním protokolu.
-
Replika může libovolně zaostávat za mistrem při čtení nebo aplikaci změn.
Pokud primární selže, transakce, které provedl, nemusí být přeneseny do žádné repliky. V důsledku toho může převzetí služeb při selhání z primárního na nejpokročilejší repliku v tomto případě vést k převzetí služeb při selhání na požadovaný primární server, ve kterém ve skutečnosti chybí transakce vzhledem k předchozímu serveru.
Asynchronní replikace poskytuje nižší latenci zápisu, protože zápis je potvrzen lokálně masterem, než je zapsán na podřízené jednotky. Je to skvělé pro škálování čtení, protože přidání dalších replik neovlivní latenci replikace. Mezi dobré příklady použití asynchronní replikace patří nasazení replik čtení pro škálování čtení, živá záložní kopie pro obnovu po havárii a analýzy/přehledy.
Semisynchronní replikace MySQL
MySQL také podporuje semisynchronní replikaci, kdy master nepotvrdí transakce klientovi, dokud alespoň jeden slave nezkopíruje změnu do svého protokolu přenosu a nevyprázdní ji na disk. Chcete-li povolit semisynchronní replikaci, jsou vyžadovány další kroky pro instalaci pluginu, které musí být povoleny na určených hlavních a podřízených uzlech MySQL.
Semisynchronní se zdá být dobrým a praktickým řešením pro mnoho případů, kdy je důležitá vysoká dostupnost a žádná ztráta dat. Měli byste však vzít v úvahu, že semisynchronní má dopad na výkon v důsledku dodatečné zpáteční cesty a neposkytuje silné záruky proti ztrátě dat. Když se odevzdání úspěšně vrátí, je známo, že data existují alespoň na dvou místech (na hlavním a alespoň na jednom podřízeném). Pokud se master potvrdí, ale dojde k havárii, zatímco master čeká na potvrzení od slave, je možné, že transakce nedosáhla žádného slave. To není tak velký problém, protože potvrzení se v tomto případě nevrátí do aplikace. Úkolem aplikace je v budoucnu transakci opakovat. Je důležité mít na paměti, že když hlavní server selže a podřízený byl povýšen, starý hlavní server se nemůže zapojit do replikačního řetězce. Za určitých okolností to může vést ke konfliktům s daty na podřízených zařízeních, tj. když se master zhroutil poté, co slave přijal událost binárního protokolu, ale předtím, než master obdržel potvrzení od slave). Jediným bezpečným způsobem je tedy zlikvidovat data na starém masteru a poskytnout je od začátku pomocí dat z nově povýšeného masteru.
Nesprávné použití formátu replikace
Od MySQL 5.7.7 používá výchozí binární formát protokolu nebo proměnná binlog_format ROW, což bylo STATEMENT před verzí 5.7.7. Různé formáty replikace odpovídají metodě použité k záznamu událostí binárního protokolu zdroje. Replikace funguje, protože události zapsané do binárního protokolu jsou čteny ze zdroje a následně zpracovávány v replice. Události jsou zaznamenávány do binárního protokolu v různých formátech replikace podle typu události. Problémem může být, když nevíte, co přesně použít. MySQL má tři formáty replikačních metod:STATEMENT, ROW a MIXED.
-
Formát replikace STATEMENT (SBR) je přesně tím, čím je – replikační proud každého spuštěného příkazu na hlavním uzlu, který bude přehrán na podřízeném uzlu. Tradiční (asynchronní) replikace MySQL standardně neprovádí replikované transakce na podřízené jednotky paralelně. Znamená to, že pořadí příkazů v replikačním proudu nemusí být 100% stejné. Přehrání příkazu může také poskytnout jiné výsledky, pokud není provedeno ve stejnou dobu, jako když je provedeno ze zdroje. To vede k nekonzistentnímu stavu vůči primárnímu a jeho replikám (replikám). To nebyl problém po mnoho let, protože málokdo provozoval MySQL s mnoha simultánními vlákny. U moderních architektur s více CPU se to však při běžné každodenní zátěži stalo vysoce pravděpodobné.
-
Formát replikace ROW poskytuje řešení, která SBR postrádají. Při použití formátu protokolování replikace založené na řádcích (RBR) zapisuje zdroj do binárního protokolu události, které označují, jak se mění jednotlivé řádky tabulky. Replikace ze zdroje do repliky funguje tak, že se události představující změny v řádcích tabulky zkopírují do repliky. To znamená, že lze generovat více dat, což ovlivní místo na disku v replice a ovlivní síťový provoz a diskové I/O. Zvažte, že pokud příkaz změní mnoho řádků, řekněme pomocí příkazu UPDATE, RBR zapíše více dat do binárního protokolu i pro příkazy, které jsou vráceny zpět. Spouštění momentálních snímků může také trvat déle. Problémy se souběžností mohou vstoupit do hry vzhledem k časům uzamčení potřebným k zápisu velkých kusů dat do binárního protokolu.
-
Pak mezi těmito dvěma existuje metoda; replikace ve smíšeném režimu. Tento typ replikace bude vždy replikovat příkazy, kromě případů, kdy dotaz obsahuje funkci UUID(), spouštěče, uložené procedury, UDF a několik dalších výjimek. Smíšený režim nevyřeší problém posunu dat a spolu s replikací založenou na příkazech by se mu mělo zabránit.
Plánujete nastavení Multi-Master?
Kruhová replikace (také známá jako kruhová topologie) je známé a běžné nastavení replikace MySQL. Používá se ke spuštění nastavení s více hlavními servery (viz obrázek níže) a je často nezbytný, pokud máte prostředí s více datovými centry. Vzhledem k tomu, že aplikace nemůže čekat, až master v druhém datovém centru potvrdí zápisy, je preferován lokální master. Normálně se offset automatického přírůstku používá, aby se zabránilo kolizím dat mezi mastery. To, že dva mastery provádějí zápisy do sebe tímto způsobem, je široce přijímané řešení.
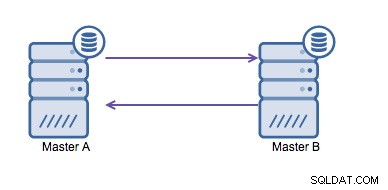
Pokud však potřebujete zapsat více datových center do stejné databáze , skončíte s několika mastery, kteří si potřebují zapsat svá data do sebe. Před MySQL 5.7.6 neexistovala žádná metoda pro provedení replikace typu mesh, takže alternativou by bylo použít místo toho kruhovou replikaci.
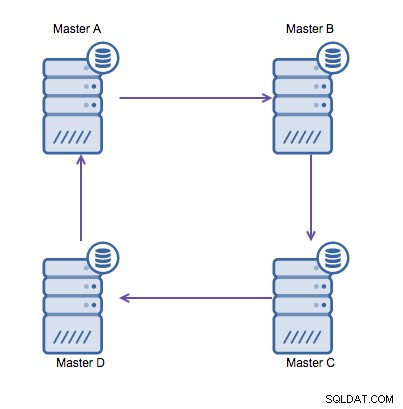
Replikace ringu v MySQL je problematická z následujících důvodů:latence, vysoká dostupnost a datový drift. Zapsání některých dat na server A by trvalo tři skoky, než by skončilo na serveru D (přes server B a C). Protože (tradiční) replikace MySQL je jednovláknová, jakýkoli dlouhotrvající dotaz v replikaci může zastavit celý kruh. Pokud by některý ze serverů selhal, kruh by se porouchal a v současnosti žádný software pro přepnutí při selhání nemůže opravit kruhové struktury. Pak může dojít k posunu dat, když jsou data zapsána na server A a jsou současně změněna na serveru C nebo D.
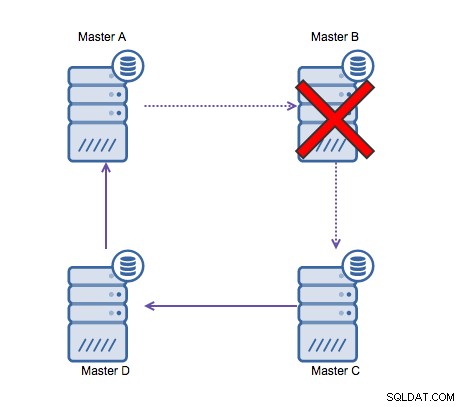
Obecně se kruhová replikace nehodí k MySQL a měla by být vyhnout za každou cenu. Jelikož byl Galera Cluster navržen s ohledem na to, byla by dobrou alternativou pro zápisy ve více datacentrech.
Zastavení replikace pomocí velkých aktualizací
Různé dávkové úlohy úklidu často provádějí různé úkoly, od čištění starých dat až po výpočet průměrů „lajků“ získaných z jiného zdroje. To znamená, že úloha vytvoří mnoho databázové aktivity v nastavených intervalech a pravděpodobně zapíše mnoho dat zpět do databáze. Přirozeně to znamená, že aktivita v rámci replikačního proudu se stejně zvýší.
Replikace založená na příkazech bude replikovat přesné dotazy používané v dávkových úlohách, takže pokud by zpracování dotazu na hlavním serveru trvalo půl hodiny, podřízené vlákno by se zastavilo alespoň na stejnou dobu čas. To znamená, že žádná jiná data se nemohou replikovat a podřízené uzly začnou zaostávat za masterem. Pokud to překročí práh vašeho nástroje pro převzetí služeb při selhání nebo proxy, může tyto podřízené uzly vypustit z dostupných serverů v clusteru. Používáte-li replikaci založenou na příkazech, můžete tomu zabránit tím, že budete data pro vaši úlohu zpracovávat v menších dávkách.
Nyní si možná myslíte, že replikace založená na řádcích není tímto ovlivněna, protože replikuje informace o řádcích namísto dotazu. To je částečně pravda, protože pro změny DDL se replikace vrátí zpět do formátu založeného na příkazech. Také velký počet operací CRUD (vytvoření, čtení, aktualizace, odstranění) ovlivní tok replikace. Ve většině případů se stále jedná o jednovláknovou operaci, a proto každá transakce bude čekat na přehrání předchozí prostřednictvím replikace. To znamená, že pokud máte vysokou souběžnost na masteru, slave se může zastavit kvůli přetížení transakcí během replikace.
Aby se to vyhnulo, nabízí MariaDB i MySQL paralelní replikaci. Implementace se může lišit podle dodavatele a verze. MySQL 5.6 nabízí paralelní replikaci, pokud jsou dotazy odděleny schématem. MariaDB 10.0 a MySQL 5.7 zvládnou paralelní replikaci napříč schématy, ale mají jiné hranice. Provádění dotazů prostřednictvím paralelních podřízených vláken může urychlit váš replikační proud, pokud píšete náročné. Jinak by bylo lepší držet se tradiční jednovláknové replikace.
Zpracování změn schématu nebo DDL
Od vydání 5.7 se správa změny schématu nebo DDL (Data Definition Language) v MySQL hodně zlepšila. Až do MySQL 8.0 jsou podporované algoritmy změn DDL COPY a INPLACE.
-
KOPÍROVAT:Tento algoritmus vytvoří novou dočasnou tabulku se změněným schématem. Jakmile kompletně migruje data do nové dočasné tabulky, vymění a zruší starou tabulku.
-
INPLACE:Tento algoritmus provádí operace na místě s původní tabulkou a vyhýbá se kopírování a opětovnému sestavení tabulky, kdykoli je to možné.
-
OKAMŽITĚ:Tento algoritmus byl zaveden od MySQL 8.0, ale stále má omezení.
V MySQL 8.0 byl představen algoritmus INSTANT, který umožňuje okamžité a na místě změny tabulky pro přidávání sloupců a umožňuje souběžné DML se zlepšenou odezvou a dostupností v rušných produkčních prostředích. To pomáhá vyhnout se velkým prodlevám a zasekáváním repliky, které byly obvykle velkými problémy v perspektivě aplikace, což způsobovalo načítání zastaralých dat, protože čtení v podřízeném zařízení ještě nebylo aktualizováno kvůli zpoždění.
I když je to slibné zlepšení, stále s nimi existují omezení a někdy není možné použít algoritmy INSTANT a INPLACE. Například pro algoritmy INSTANT a INPLACE je změna datového typu sloupce také obvyklou úlohou DBA, zejména v perspektivě vývoje aplikací kvůli změně dat. Tyto příležitosti jsou nevyhnutelné; proto nemůžete pokračovat s algoritmem COPY, protože to uzamkne stůl a způsobí zpoždění v podřízeném zařízení. Během tohoto provádění má také dopad na primární/hlavní server, protože hromadí příchozí transakce, které také odkazují na ovlivněnou tabulku. Na zaneprázdněném serveru nemůžete provést přímou změnu ALTER nebo schématu, protože to doprovází výpadky nebo případně poškodí vaši databázi, pokud ztratíte trpělivost, zvláště pokud je cílová tabulka obrovská.
Je pravda, že provádění změn schématu na běžícím produkčním nastavení je vždy náročný úkol. Často používaným řešením je nejprve použít změnu schématu na podřízené uzly. To funguje dobře pro replikaci založenou na příkazech, ale to může fungovat pouze do určité míry pro replikaci založenou na řádcích. Replikace založená na řádcích umožňuje, aby na konci tabulky existovaly další sloupce, takže pokud umí zapisovat první sloupce, bude to v pořádku. Nejprve aplikujte změnu na všechny podřízené jednotky, poté přepnutí při selhání na jednoho z podřízených a poté aplikujte změnu na nadřízenou jednotku a připojte ji jako podřízenou. Pokud vaše změna zahrnuje vložení sloupce doprostřed nebo odebrání sloupce, bude to fungovat s replikací založenou na řádcích.
K dispozici jsou nástroje, které dokážou spolehlivěji provádět změny online schématu. DBA běžně používají změny schématu Percona Online Schema Change (známé jako pt-osc) a gh-ost od Schlomi Noach. Tyto nástroje efektivně zpracovávají změny schématu seskupováním dotčených řádků do bloků a tyto bloky lze nakonfigurovat podle toho, kolik jich chcete seskupit.
Pokud se chystáte skočit s pt-osc, tento nástroj vytvoří stínovou tabulku s novou strukturou tabulky, vloží nová data pomocí spouštěčů a vyplní data na pozadí. Jakmile vytvoříte novou tabulku, jednoduše vymění starou tabulku za novou v rámci transakce. Toto nefunguje ve všech případech, zvláště pokud vaše stávající tabulka již spouštěcí prvky má.
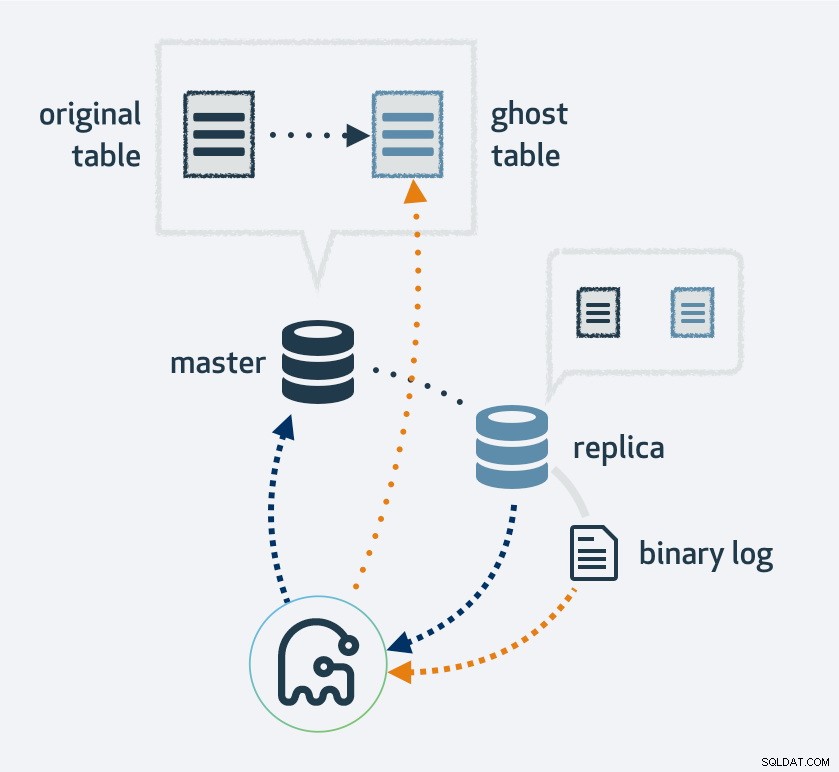
Pomocí gh-ost nejprve vytvoříte kopii vašeho stávajícího rozložení tabulky, změňte tabulku na nové rozvržení a poté připojte proces jako repliku MySQL. Použije replikační proud k vyhledání nových řádků, které byly vloženy do původní tabulky, a zároveň tabulku vyplní. Po dokončení zásypu se původní a nové tabulky prohodí. Všechny operace s novou tabulkou přirozeně skončí v replikačním proudu; takže u každé repliky probíhá migrace současně.
Tabulky paměti a replikace
Když už jsme u DDL, častým problémem je vytváření paměťových tabulek. Paměťové tabulky jsou neperzistentní tabulky, jejich struktura tabulek zůstává, ale po restartu MySQL ztrácejí svá data. Při vytváření nové paměťové tabulky na masteru i slave budou mít prázdnou tabulku, která bude fungovat naprosto v pořádku. Jakmile se jeden z nich restartuje, tabulka se vyprázdní a dojde k chybám replikace.
Replikace založená na řádcích se přeruší, jakmile data v podřízeném uzlu vrátí jiné výsledky, a replikace založená na příkazech se přeruší, jakmile se pokusí vložit data, která již existují. U paměťových tabulek je to častý nástroj pro přerušení replikace. Oprava je snadná:vytvořte novou kopii dat, změňte engine na InnoDB a nyní by měla být replikace bezpečná.
Nastavení read_only={True|1}
Toto je samozřejmě možný případ, když používáte kruhovou topologii, a pokud je to možné, použití kruhové topologie nedoporučujeme. Již dříve jsme popsali, že nemít stejná data v podřízených uzlech může přerušit replikaci. Často je to způsobeno tím, že něco (nebo někdo) mění data na podřízeném uzlu, ale ne na hlavním uzlu. Jakmile se data hlavního uzlu změní, budou replikována do podřízeného, kde nemůže změnu použít, a to způsobí přerušení replikace. To může také vést k poškození dat na úrovni clusteru, zejména pokud byl podřízený počítač povýšen nebo selhal kvůli havárii. To může být katastrofa.
Snadnou prevencí je zajistit, aby read_only a super_read_only (pouze na> 5.6) byly nastaveny na ON nebo 1. Možná jste pochopili, jak se tyto dvě proměnné liší a jak to ovlivní, pokud zakážete nebo povolíte jim. Se zakázaným super_read_only (od MySQL 5.7.8) může uživatel root zabránit jakýmkoli změnám v cíli nebo replice. Takže když jsou oba zakázány, znemožní to komukoli provádět změny v datech, s výjimkou replikace. Většina správců převzetí služeb při selhání, jako je ClusterControl, nastavuje tento příznak automaticky, aby uživatelům zabránila v zápisu do použitého hlavního serveru během převzetí služeb při selhání. Některé z nich si to zachovají i po převzetí služeb při selhání.
Povolení GTID
Při replikaci MySQL je zásadní spouštění slave ze správné pozice v binárních protokolech. Získání této pozice lze provést při vytváření zálohy (podporuje to xtrabackup a mysqldump) nebo když jste přestali slavit na uzlu, ze kterého vytváříte kopii. Spuštění replikace pomocí příkazu CHANGE MASTER TO by vypadalo takto:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Spuštění replikace na nesprávném místě může mít katastrofální následky:data mohou být zapsána dvakrát nebo nebudou aktualizována. To způsobí posun dat mezi nadřízeným a podřízeným uzlem.
Také selhání z master na slave zahrnuje nalezení správné pozice a změnu master na vhodného hostitele. MySQL neuchovává binární protokoly a pozice ze svého hlavního serveru, ale místo toho vytváří své vlastní binární protokoly a pozice. To by se mohlo stát vážným problémem pro opětovné zarovnání podřízeného uzlu s novým masterem. Přesná poloha hlavního zařízení při převzetí služeb při selhání musí být nalezena na novém hlavním zařízení a poté mohou být všechny podřízené jednotky znovu zarovnány.
Oracle MySQL i MariaDB implementovaly Global Transaction Identifier (GTID) do vyřešit tento problém. GTID umožňují automatické zarovnání otroků a server sám zjistí, jaká je správná poloha. Oba však implementovali GTID odlišně, a proto jsou nekompatibilní. Pokud potřebujete nastavit replikaci z jednoho do druhého, měla by být replikace nastavena pomocí tradičního umístění binárního protokolu. Také váš software pro přepnutí při selhání by měl být upozorněn na to, že nepoužívá GTID.
Crash-Safe Slave
Crash safe znamená, že i když dojde k selhání slave MySQL/OS, můžete slave obnovit a pokračovat v replikaci, aniž byste obnovovali databáze MySQL na slave. Chcete-li, aby slave fungoval bez nebezpečí zhroucení, musíte použít pouze úložiště InnoDB a ve verzi 5.6 musíte nastavit relay_log_info_repository=TABLE a relay_log_recovery=1.
Závěr
Cvičení skutečně dělá mistra, ale bez řádného tréninku a znalostí těchto životně důležitých technik by to mohlo být problematické nebo vést ke katastrofě. Tyto postupy běžně dodržují odborníci na MySQL a přizpůsobují je velká průmyslová odvětví jako součást své každodenní rutinní práce při správě replikace MySQL na produkčních databázových serverech.
Pokud si chcete přečíst více o replikaci MySQL, podívejte se na tento výukový program o replikaci MySQL pro vysokou dostupnost.
Chcete-li získat další aktualizace o řešeních pro správu databází a osvědčených postupech pro vaše databáze s otevřeným zdrojovým kódem, sledujte nás na Twitteru a LinkedIn a přihlaste se k odběru našeho zpravodaje.