Přesunutí vašich dat do veřejné cloudové služby je velké rozhodnutí. Všichni hlavní cloudoví dodavatelé nabízejí cloudové databázové služby, přičemž Amazon RDS pro MySQL je pravděpodobně nejoblíbenější.
V tomto blogu se podrobně podíváme na to, co to je, jak to funguje a porovnáme jeho klady a zápory.
RDS (Relational Database Service) je nabídka webových služeb Amazon. Stručně řečeno, je to Databáze jako služba, kde Amazon nasazuje a provozuje vaši databázi. Stará se o úkoly, jako je zálohování a oprava databázového softwaru, stejně jako o vysokou dostupnost. Několik databází je podporováno RDS, zde nás však zajímá hlavně MySQL - Amazon podporuje MySQL a MariaDB. K dispozici je také Aurora, což je klon MySQL od Amazonu, vylepšený, zejména v oblasti replikace a vysoké dostupnosti.
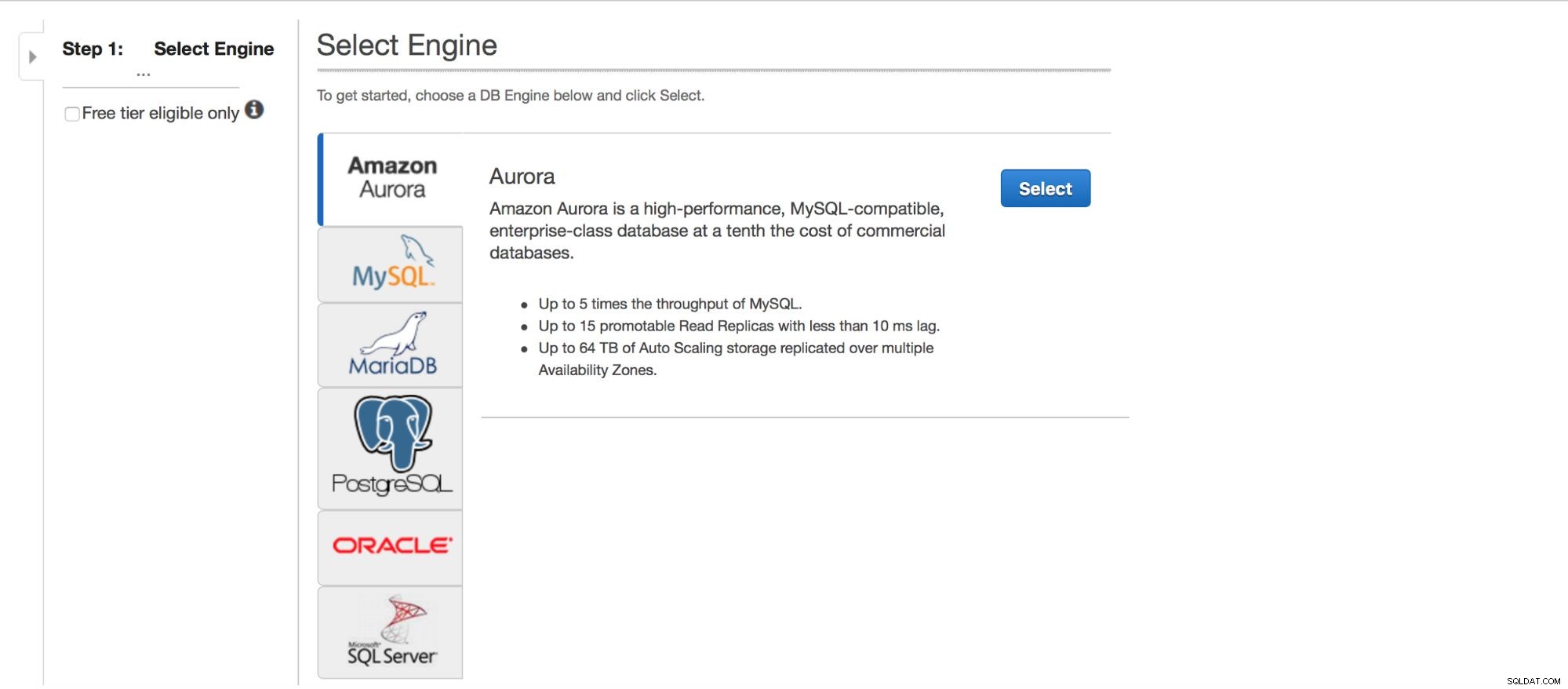
Nasazení MySQL přes RDS
Pojďme se podívat na nasazení MySQL přes RDS. Vybrali jsme MySQL a poté se nám zobrazí několik vzorů nasazení, ze kterých si můžeme vybrat.
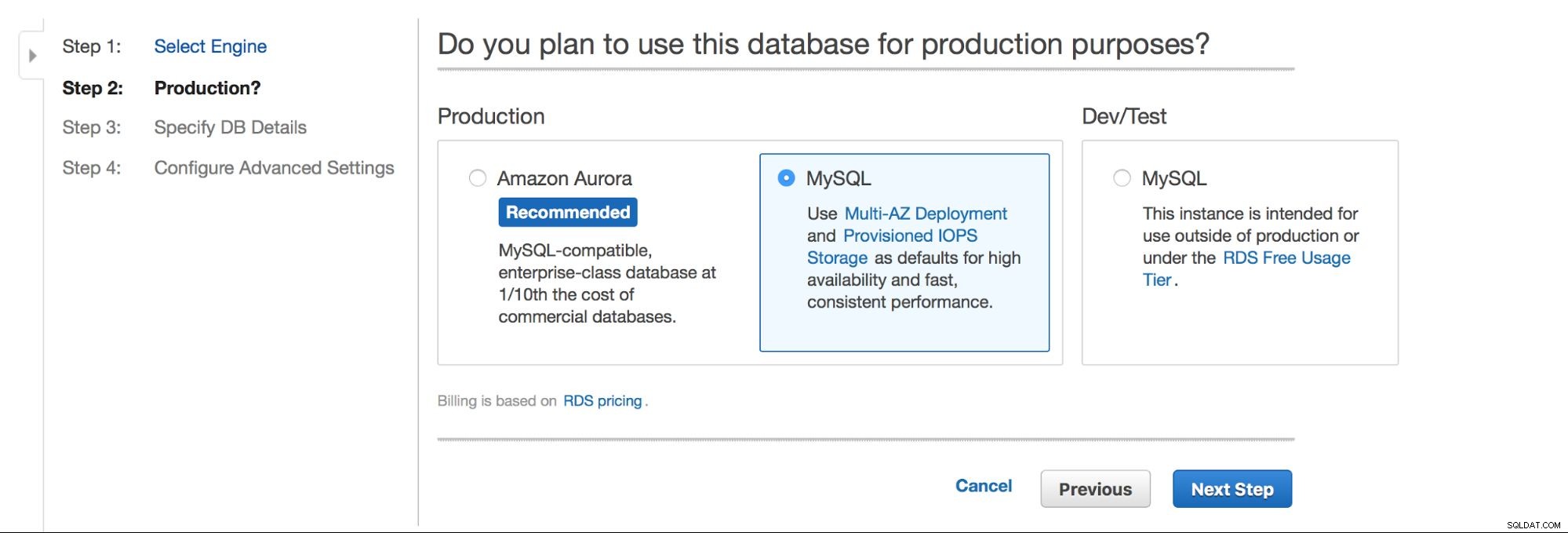
Hlavní volba je - chceme mít vysokou dostupnost nebo ne? Aurora je také podporována.
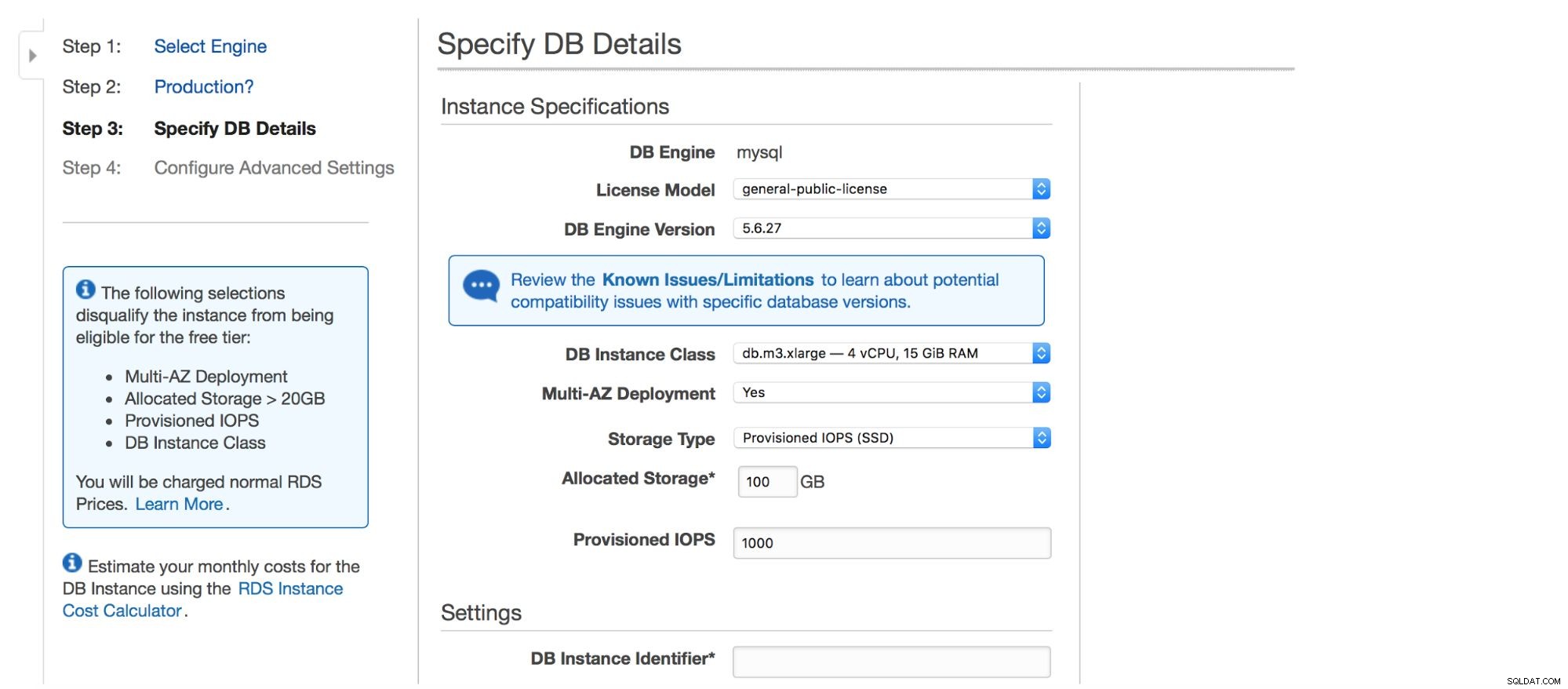
Další dialogové okno nám poskytuje některé možnosti přizpůsobení. Můžete si vybrat jednu z mnoha verzí MySQL – k dispozici je několik verzí 5.5, 5.6 a 5.7. Instance databáze – můžete si vybrat z typických velikostí instance dostupných v daném regionu.
Další možnost je docela důležitá volba - chcete použít multi-AZ nasazení nebo ne? To vše je o vysoké dostupnosti. Pokud nechcete používat nasazení multi-AZ, nainstaluje se jedna instance. V případě poruchy se roztočí nový a jeho datový objem se k němu znovu připojí. Tento proces nějakou dobu trvá, během které nebude vaše databáze dostupná. Tento dopad můžete samozřejmě minimalizovat používáním otroků a propagací jednoho z nich, ale nejde o automatizovaný proces. Pokud chcete mít automatizovanou vysokou dostupnost, měli byste použít nasazení multi-AZ. Stane se, že se vytvoří dvě instance databáze. Jeden je pro vás viditelný. Druhá instance v samostatné zóně dostupnosti není pro uživatele viditelná. Bude fungovat jako stínová kopie, připravená převzít provoz, jakmile aktivní uzel selže. Stále to není dokonalé řešení, protože provoz musí být převeden z neúspěšné instance do stínové instance. V našich testech trvalo převzetí služeb při selhání ~45 s, ale samozřejmě to může záviset na velikosti instance, výkonu I/O atd. Je to však mnohem lepší než neautomatizované převzetí služeb při selhání, kde jsou zapojeny pouze podřízené jednotky.
Nakonec tu máme nastavení úložiště – typ, velikost, PIOPS (pokud je to možné) a nastavení databáze – identifikátor, uživatel a heslo.
V dalším kroku čeká na vstup uživatele několik dalších možností.
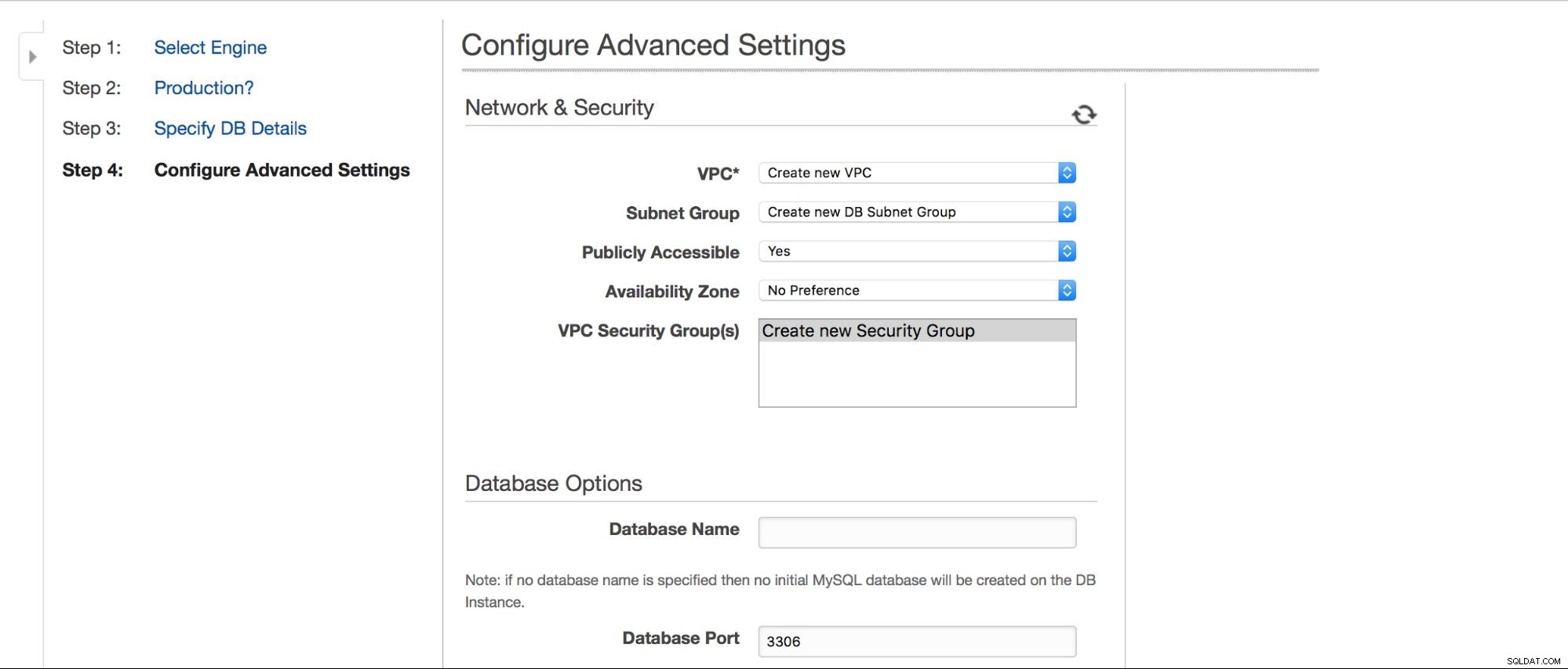
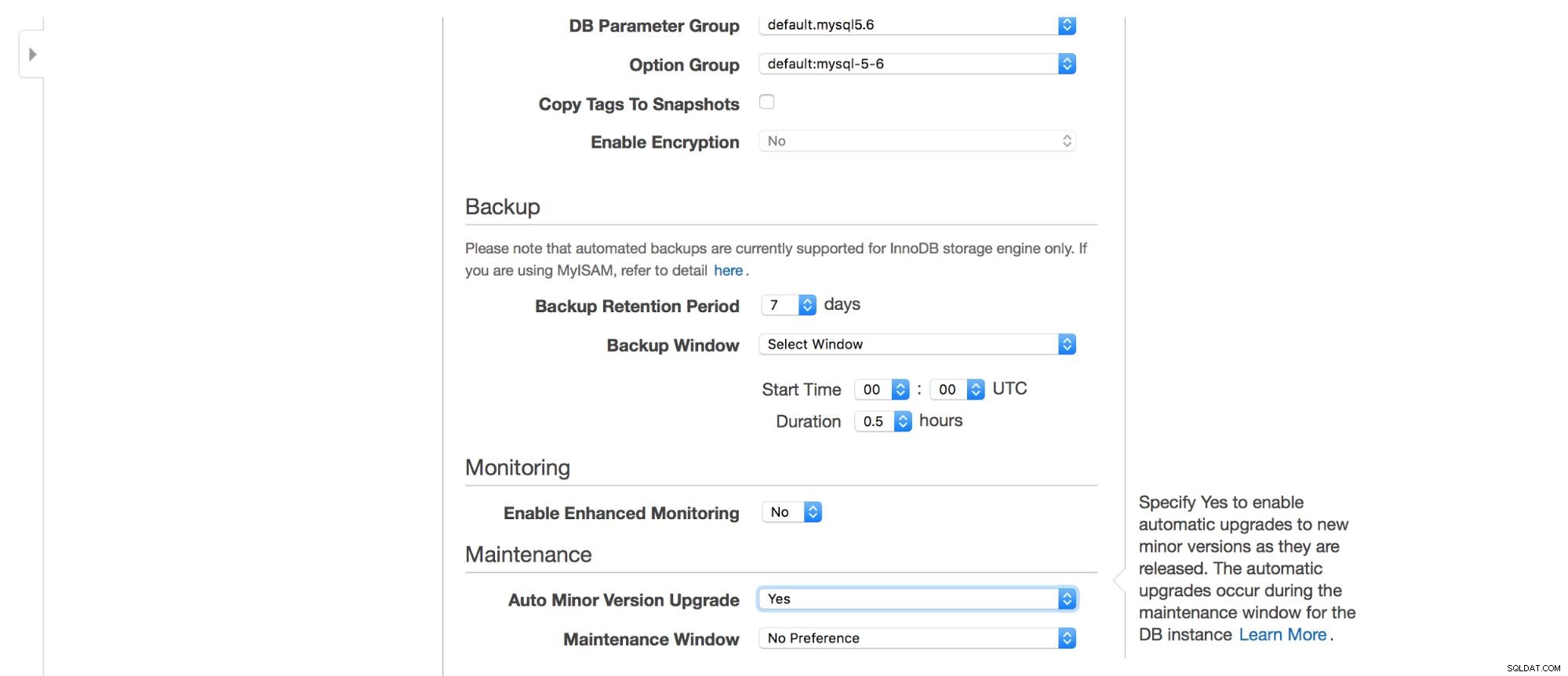
Můžeme si vybrat, kde má být instance vytvořena:VPC, podsíť, má být veřejně dostupná nebo ne (jako v případě - má být instanci RDS přiřazena veřejná IP), zóna dostupnosti a skupina zabezpečení VPC. Pak máme možnosti databáze:první schéma, které má být vytvořeno, port, skupiny parametrů a možností, zda mají být tagy metadat zahrnuty do snímků nebo ne, nastavení šifrování.
Dále možnosti zálohování – jak dlouho chcete zálohy uchovávat? Kdy je chcete vzít? Podobné nastavení souvisí s údržbou – někdy musí správci Amazonu provádět údržbu na vaší instanci RDS – stane se tak v předdefinovaném okně, které zde můžete nastavit. Vezměte prosím na vědomí, že neexistuje žádná možnost nevybrat si alespoň 30 minut pro okno údržby, proto je skutečně důležité mít vícenásobnou instanci AZ na produkci. Údržba může mít za následek restart uzlu nebo nedostatek dostupnosti po určitou dobu. Bez multi-AZ se musíte s tím prostojem smířit. Při nasazení multi-AZ dojde k převzetí služeb při selhání.
Nakonec tu máme nastavení související s dalším sledováním – chceme ho mít povolený nebo ne?
Správa RDS
V této kapitole se blíže podíváme na to, jak spravovat MySQL RDS. Nebudeme procházet všechny dostupné možnosti, ale rádi bychom zdůraznili některé funkce, které Amazon zpřístupnil.
Snímky
MySQL RDS používá svazky EBS jako úložiště, takže může snímky EBS používat pro různé účely. Zálohy, otroci – vše na základě snímků. Snímky můžete vytvářet ručně nebo je lze pořizovat automaticky, když taková potřeba nastane. Je důležité mít na paměti, že snímky EBS obecně (nejen v instancích RDS) zvyšují I/O operace. Pokud chcete pořídit snímek, počítejte s poklesem vašeho I/O výkonu. Pokud nepoužíváte multi-AZ nasazení, tzn. V takovém případě bude „stínová“ instance použita jako zdroj snímků a na produkční instanci nebude viditelný žádný dopad.
Několik nines DevOps Průvodce správou databázíZjistěte, co potřebujete vědět k automatizaci a správě vašich databází s otevřeným zdrojovým kódemStáhněte si zdarmaZálohy
Zálohy jsou založeny na snímcích. Jak bylo uvedeno výše, můžete definovat plán zálohování a uchování při vytváření nové instance. Tato nastavení můžete samozřejmě upravit později pomocí možnosti „upravit instanci“.
Snímek můžete kdykoli obnovit – musíte přejít do sekce snímek, vybrat snímek, který chcete obnovit, a zobrazí se vám dialogové okno podobné tomu, které jste viděli při vytváření nové instance. Není to překvapením, protože snímek můžete obnovit pouze do nové instance – neexistuje způsob, jak jej obnovit na jedné ze stávajících instancí RDS. Může to být překvapením, ale i v cloudovém prostředí může mít smysl znovu použít hardware (a instance, které již máte). Ve sdíleném prostředí se může výkon jedné virtuální instance lišit – můžete se raději držet výkonnostního profilu, který již znáte. Bohužel to není možné v RDS.
Další možností v RDS je point-in-time recovery – velmi důležitá funkce, požadavek pro každého, kdo se potřebuje dobře starat o svá data. Zde jsou věci složitější a méně jasné. Pro začátek je důležité mít na paměti, že MySQL RDS před uživatelem skrývá binární protokoly. Můžete změnit několik nastavení a vytvořit seznam vytvořených binlogů, ale nemáte k nim přímý přístup – k provedení jakékoli operace, včetně použití pro obnovu, můžete použít pouze uživatelské rozhraní nebo CLI. To omezuje vaše možnosti na to, co vám Amazon umožňuje, a umožňuje vám to obnovit zálohu až do poslední „obnovitelné doby“, která se počítá v intervalu 5 minut. Pokud tedy byla vaše data odstraněna v 9:33, můžete je obnovit pouze do stavu v 9:30. Obnova v určitém okamžiku funguje stejným způsobem jako obnova snímků – vytvoří se nová instance.
Škálování, replikace
MySQL RDS umožňuje škálování prostřednictvím přidávání nových podřízených jednotek. Když je vytvořen slave, je pořízen snímek hlavního zařízení a je použit k vytvoření nového hostitele. Tato část funguje docela dobře. Bohužel nemůžete vytvořit žádnou složitější replikační topologii, jako je topologie zahrnující středně pokročilé mastery. Nejste schopni vytvořit hlavní – hlavní nastavení, které ponechá jakékoli HA v rukou Amazonu (a multi-AZ nasazení). Z toho, co můžeme říci, neexistuje způsob, jak povolit GTID (ne že byste z toho mohli mít prospěch, protože nemáte žádnou kontrolu nad replikací, žádný CHANGE MASTER v RDS), pouze běžné, staromódní pozice binlogu.
Nedostatek GTID znemožňuje použití vícevláknové replikace - počet pracovníků je sice možné nastavit pomocí skupin parametrů RDS, ale bez GTID je to nepoužitelné. Hlavním problémem je, že neexistuje způsob, jak v případě havárie najít jedinou pozici binárního protokolu – někteří pracovníci mohli být pozadu, někteří mohli být pokročilejší. Pokud použijete poslední použitou událost, ztratíte data, která tito „zpoždění“ pracovníci ještě nepoužili. Pokud použijete nejstarší událost, s největší pravděpodobností skončíte s chybami „duplicitního klíče“ způsobenými událostmi aplikovanými těmi pokročilejšími pracovníky. Samozřejmě existuje způsob, jak tento problém vyřešit, ale není to triviální a je to časově náročné - rozhodně to není něco, co byste mohli snadno automatizovat.
Uživatelé vytvoření na MySQL RDS nemají SUPER oprávnění, takže operace, které jsou jednoduché v samostatném MySQL, nejsou v RDS triviální. Amazon se rozhodl použít uložené procedury, aby umožnil uživateli provádět některé z těchto operací. Z toho, co můžeme říci, je pokryta řada potenciálních problémů, i když tomu tak nebylo vždy – pamatujeme si, když jste nemohli otočit na další binární protokol na hlavním serveru. Hlavní havárie + poškození binlogu by mohly způsobit rozbití všech slave – nyní na to existuje postup:rds_next_master_log .
Slave lze ručně povýšit na master. To by vám umožnilo vytvořit nějaký druh HA nad mechanismem multi-AZ (nebo jej obejít), ale bylo to zbytečné, protože žádného ze stávajících otroků nemůžete znovu podřídit novému masteru. Pamatujte, že nad replikací nemáte žádnou kontrolu. Díky tomu je celé cvičení marné – pokud váš mistr nepojme veškerý váš provoz. Poté, co povýšíte nového hlavního serveru, nemůžete na něj přejít při selhání, protože nemá žádné otroky, kteří by zvládli váš náklad. Vytváření nových podřízených jednotek bude nějakou dobu trvat, protože je třeba nejprve vytvořit snímky EBS, což může trvat hodiny. Poté musíte infrastrukturu zahřát, než ji budete moci zatížit.
Nedostatek SUPER privilegií
Jak jsme uvedli dříve, RDS neuděluje uživatelům SUPER privilegia a to začíná být nepříjemné pro někoho, kdo je zvyklý mít to na MySQL. Berte jako samozřejmost, že v prvních týdnech se dozvíte, jak často je potřeba dělat věci, které děláte poměrně často – jako je zabíjení dotazů nebo obsluha schématu výkonu. V RDS se budete muset držet předdefinovaného seznamu uložených procedur a používat je místo toho, abyste věci dělali přímo. Všechny je můžete vypsat pomocí následujícího dotazu:
SELECT specific_name FROM information_schema.routines;Stejně jako u replikace je pokryta řada úkolů, ale pokud jste se dostali do situace, která ještě pokryta není, máte smůlu.
Interoperabilita a nastavení hybridního cloudu
Toto je další oblast, kde RDS postrádá flexibilitu. Řekněme, že chcete vytvořit smíšené nastavení cloud/on-premises – máte infrastrukturu RDS a rádi byste vytvořili několik podřízených zařízení v areálu. Hlavním problémem, kterému budete čelit, je, že neexistuje žádný způsob, jak přesunout data z RDS, kromě logického výpisu. Můžete pořizovat snímky dat RDS, ale nemáte k nim přístup a nemůžete je přesunout pryč od AWS. Také nemáte fyzický přístup k instanci pro použití xtrabackup, rsync nebo dokonce cp. Jedinou možností pro vás je použít mysqldump, mydump nebo podobné nástroje. To zvyšuje složitost (nastavení znakové sady a řazení mohou způsobit problémy) a je to časově náročné (vypisování a načítání dat pomocí nástrojů logického zálohování trvá dlouho).
Je možné nastavit replikaci mezi RDS a externí instancí (obouma způsoby, takže migrace dat do RDS je také možná), ale může to být velmi časově náročný proces.
Na druhou stranu, pokud chcete zůstat v prostředí RDS a rozšířit svou infrastrukturu napříč Atlantikem nebo z východního na západní pobřeží USA, RDS vám to umožňuje – při vytváření nového otroka si můžete snadno vybrat region.
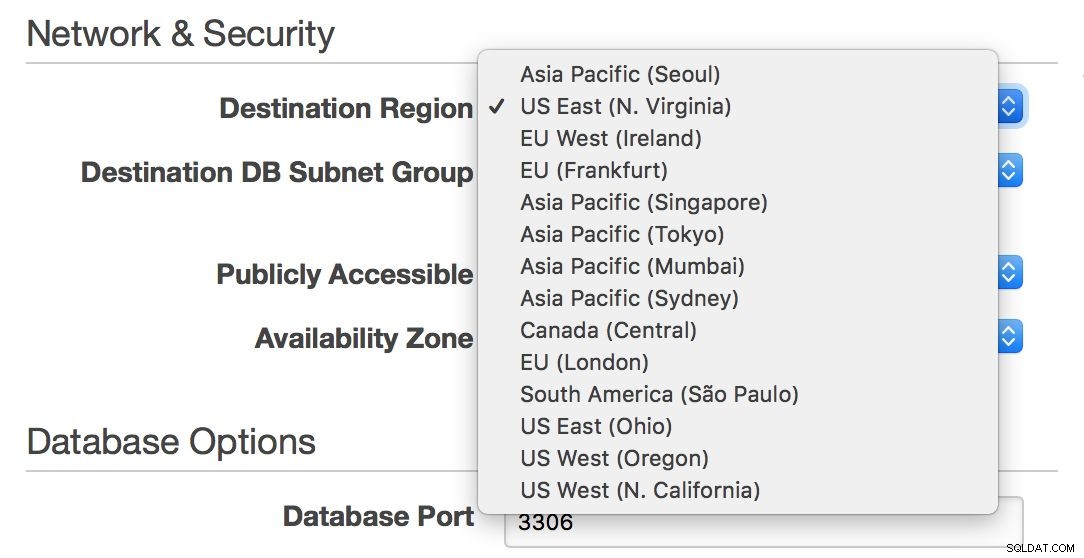
Bohužel, pokud byste chtěli přesunout svého mastera z jednoho regionu do druhého, bez prostojů to prakticky není možné – pokud váš jediný uzel nezvládne veškerý váš provoz.
Zabezpečení
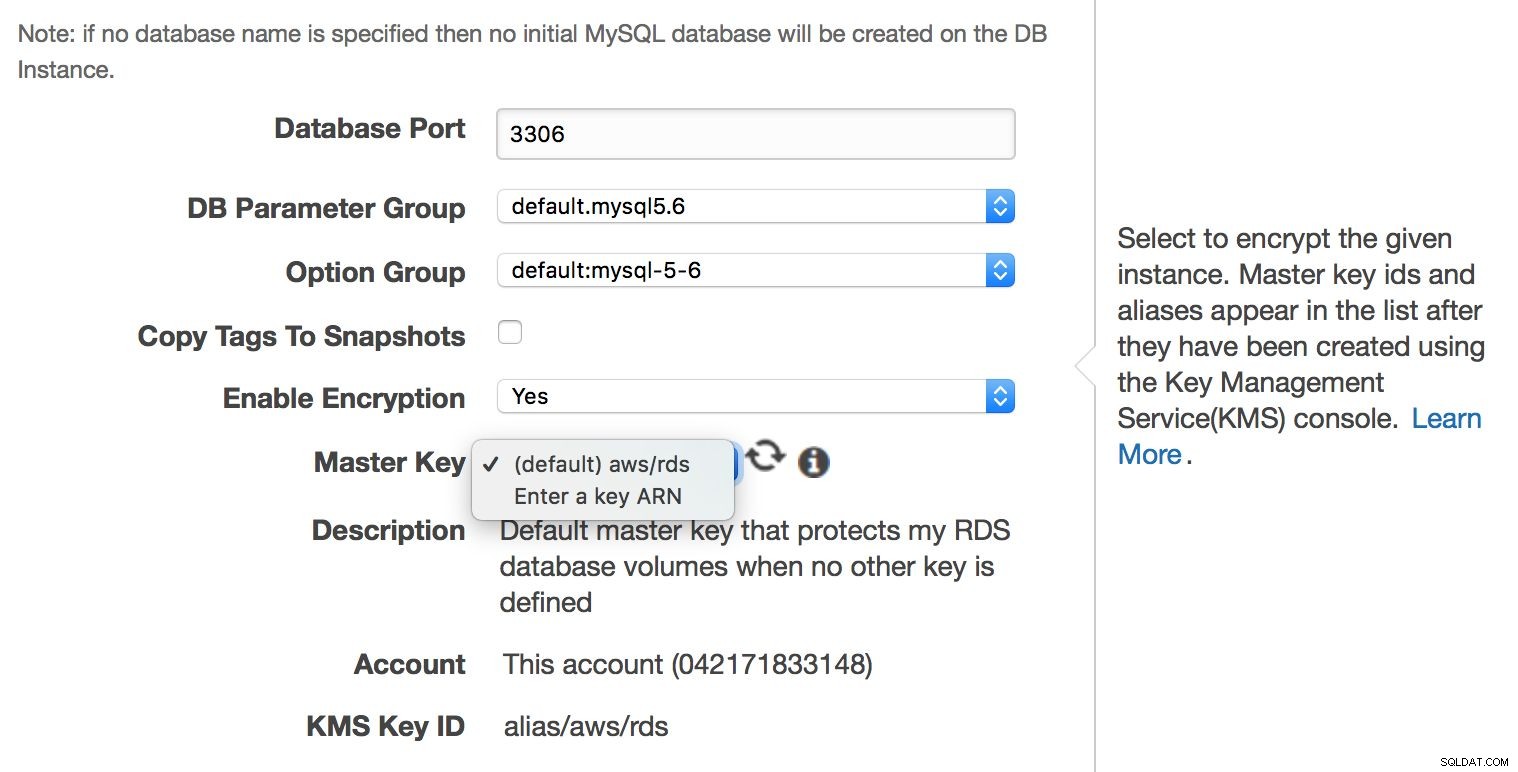
Zatímco MySQL RDS je spravovaná služba, ne o každý aspekt související s bezpečností se starají inženýři Amazonu. Amazon to nazývá „model sdílené odpovědnosti“. Amazon se zkrátka stará o bezpečnost síťové a úložné vrstvy (aby byla data přenášena bezpečným způsobem), operačního systému (záplaty, bezpečnostní opravy). Na druhou stranu se uživatel musí postarat o zbytek bezpečnostního modelu. Ujistěte se, že provoz do a z instance RDS je v rámci VPC omezen, zajistěte, aby autentizace na úrovni databáze byla provedena správně (žádné uživatelské účty MySQL bez hesla), ověřte, že je zajištěno zabezpečení API (AMI jsou nastaveny správně a s minimálními požadovanými oprávněními). Uživatel by se měl také postarat o nastavení firewallu (skupiny zabezpečení), aby se minimalizovalo vystavení RDS a VPC, ve kterém je, externím sítím. Je také odpovědností uživatele implementovat šifrování dat v klidu – buď na úrovni aplikace, nebo na úrovni databáze, a to vytvořením šifrované instance RDS.
Šifrování na úrovni databáze lze povolit pouze při vytváření instance, nelze šifrovat existující, již běžící databázi.
Omezení RDS
Pokud plánujete používat RDS nebo jej již používáte, musíte si být vědomi omezení, která s sebou přináší MySQL RDS.
Nedostatek oprávnění SUPER může být, jak jsme již zmínili, velmi nepříjemné. Zatímco uložené procedury se starají o řadu operací, je to křivka učení, protože se musíte naučit dělat věci jiným způsobem. Nedostatek oprávnění SUPER může také způsobit problémy při používání externích nástrojů pro monitorování a sledování trendů – stále existují nástroje, které mohou toto oprávnění vyžadovat pro určitou část své funkčnosti.
Nedostatek přímého přístupu k datovému adresáři a protokolům MySQL ztěžuje provádění akcí která se jich týká. Každou chvíli se stává, že správce databází potřebuje analyzovat binární protokoly nebo koncovou chybu, pomalý dotaz nebo obecný protokol. I když je možné přistupovat k těmto protokolům na RDS, je to těžkopádnější než dělat cokoli potřebujete přihlášením do shellu na hostiteli MySQL. Stahování místně také nějakou dobu trvá a přidává další latenci všemu, co děláte.
Nedostatek kontroly nad topologií replikace, vysoká dostupnost pouze v nasazeních v multi-AZ. Vzhledem k tomu, že nemáte kontrolu nad replikací, nemůžete do své databázové vrstvy implementovat žádný druh mechanismu vysoké dostupnosti. Nezáleží na tom, že máte několik otroků, některé z nich nemůžete použít jako kandidáty na pána, protože i když povýšíte otroka na pána, neexistuje způsob, jak od tohoto nového pána znovu zotročit zbývající otroky. To nutí uživatele používat multi-AZ nasazení a zvyšuje náklady ("stínová" instance není zdarma, uživatel za ni musí platit).
Snížená dostupnost díky plánovaným odstávkám. Při nasazování instance RDS jste nuceni zvolit týdenní časové okno 30 minut, během kterého mohou být na vaší instanci RDS prováděny operace údržby. Na jednu stranu je to pochopitelné, protože RDS je databáze jako služba, takže upgrady hardwaru a softwaru vašich instancí RDS spravují inženýři AWS. Na druhou stranu to snižuje vaši dostupnost, protože nemůžete zabránit výpadku hlavní databáze po dobu trvání období údržby. Opět platí, že v tomto případě použití vícenásobného nastavení AZ zvyšuje dostupnost, protože ke změnám dojde nejprve ve stínové instanci a poté se provede převzetí služeb při selhání. Samotné převzetí služeb při selhání však není transparentní, takže tak či onak ztratíte dobu provozuschopnosti. To vás nutí navrhovat aplikaci s ohledem na neočekávaná selhání hlavního serveru MySQL. Ne, že by se jednalo o špatný návrhový vzor – databáze mohou kdykoli spadnout a vaše aplikace by měla být sestavena tak, aby obstála i v těch nejhroznějších scénářích. Jde jen o to, že s RDS máte omezené možnosti vysoké dostupnosti.
Omezené možnosti implementace vysoké dostupnosti. Vzhledem k nedostatku flexibility ve správě topologie replikace je jedinou proveditelnou metodou vysoké dostupnosti nasazení ve více AZ. Tato metoda je dobrá, ale existují nástroje pro replikaci MySQL, které by prostoje ještě více minimalizovaly. Například MHA nebo ClusterControl při použití ve spojení s ProxySQL může zajistit (za určitých podmínek, jako je nedostatek dlouhotrvajících transakcí) transparentní proces převzetí služeb při selhání pro aplikaci. V RDS nebudete moci tuto metodu použít.
Snížený přehled o výkonu vaší databáze. I když můžete získat metriky ze samotného MySQL, někdy to prostě nestačí k tomu, abyste získali celkový pohled na situaci z 10 000 stop. V určitém okamžiku se většina uživatelů bude muset potýkat s opravdu podivnými problémy způsobenými vadným hardwarem nebo vadnou infrastrukturou – ztracenými síťovými pakety, náhle ukončenými připojeními nebo neočekávaně vysokým vytížením CPU. Když máte přístup ke svému hostiteli MySQL, můžete využít spoustu nástrojů, které vám pomohou diagnostikovat stav linuxového serveru. Při používání RDS jste omezeni tím, jaké metriky jsou dostupné v Cloudwatch, nástroji pro sledování a sledování trendů společnosti Amazon. Jakákoli podrobnější diagnóza vyžaduje kontaktovat podporu a požádat ji o kontrolu a vyřešení problému. Může to být rychlé, ale také to může být velmi dlouhý proces se spoustou e-mailové komunikace tam a zpět.
Zablokování dodavatele způsobené složitým a časově náročným procesem získávání dat z MySQL RDS. RDS neuděluje přístup k adresáři dat MySQL, takže neexistuje způsob, jak využít standardní nástroje, jako je xtrabackup, k přesunu dat binárním způsobem. Na druhou stranu, RDS pod kapotou je MySQL spravovaný Amazonem, těžko říct, jestli je 100% kompatibilní s upstreamem nebo ne. RDS je k dispozici pouze na AWS, takže byste nemohli provést hybridní nastavení.
Shrnutí
MySQL RDS má silné i slabé stránky. Jedná se o velmi dobrý nástroj pro ty, kteří se chtějí soustředit na aplikaci, aniž by se museli starat o obsluhu databáze. Nasadíte databázi a začnete zadávat dotazy. Není třeba vytvářet zálohovací skripty nebo nastavovat řešení pro monitorování, protože to již provedli inženýři AWS – vše, co musíte udělat, je použít to.
Existuje také temná stránka MySQL RDS. Nedostatek možností pro vytváření složitějších nastavení a škálování mimo pouhé přidávání dalších otroků. Nedostatek podpory pro lepší vysokou dostupnost, než jaká je navržena v rámci multi-AZ nasazení. Těžkopádný přístup k protokolům MySQL. Nedostatek přímého přístupu k adresáři dat MySQL a nedostatek podpory fyzických záloh, což ztěžuje přesun dat z instance RDS.
Abych to shrnul, RDS pro vás může fungovat dobře, pokud si ceníte snadného použití před detailním ovládáním databáze. Musíte mít na paměti, že někdy v budoucnu můžete MySQL RDS přerůst. Nemluvíme zde nutně pouze o výkonu. Jde spíše o potřeby vaší organizace pro složitější topologii replikace nebo o potřebu mít lepší přehled o databázových operacích, abyste mohli rychle řešit různé problémy, které čas od času vyvstanou. V takovém případě, pokud vaše datová sada již narostla, může být obtížné přesunout se z RDS. Před jakýmkoli rozhodnutím o přesunutí vašich dat do RDS musí informační manažeři zvážit požadavky a omezení své organizace v konkrétních oblastech.
V několika následujících příspěvcích na blogu vám ukážeme, jak přenést data z RDS na samostatné místo. Probereme jak migraci na EC2, tak na místní infrastrukturu.