Když potřebujete pracovat s databází, kterou neznáte na 100 %, můžete být zahlceni stovkami dostupných metrik. Které jsou ty nejdůležitější? Co bych měl sledovat a proč? Jaké vzory v metrikách by měly zvonit na poplach? V tomto příspěvku na blogu se vám pokusíme představit některé z nejdůležitějších metrik, na které byste měli dávat pozor při spuštění MySQL nebo MariaDB v produkci.
Počítadla stavu Com_*
Začneme čítači Com_* – ty definují počet a typy dotazů, které MySQL provádí. Hovoříme zde o typech dotazů jako SELECT, INSERT, UPDATE a mnoha dalších. Je docela důležité je sledovat, protože náhlé skoky nebo neočekávané poklesy mohou naznačovat, že se v systému něco pokazilo.
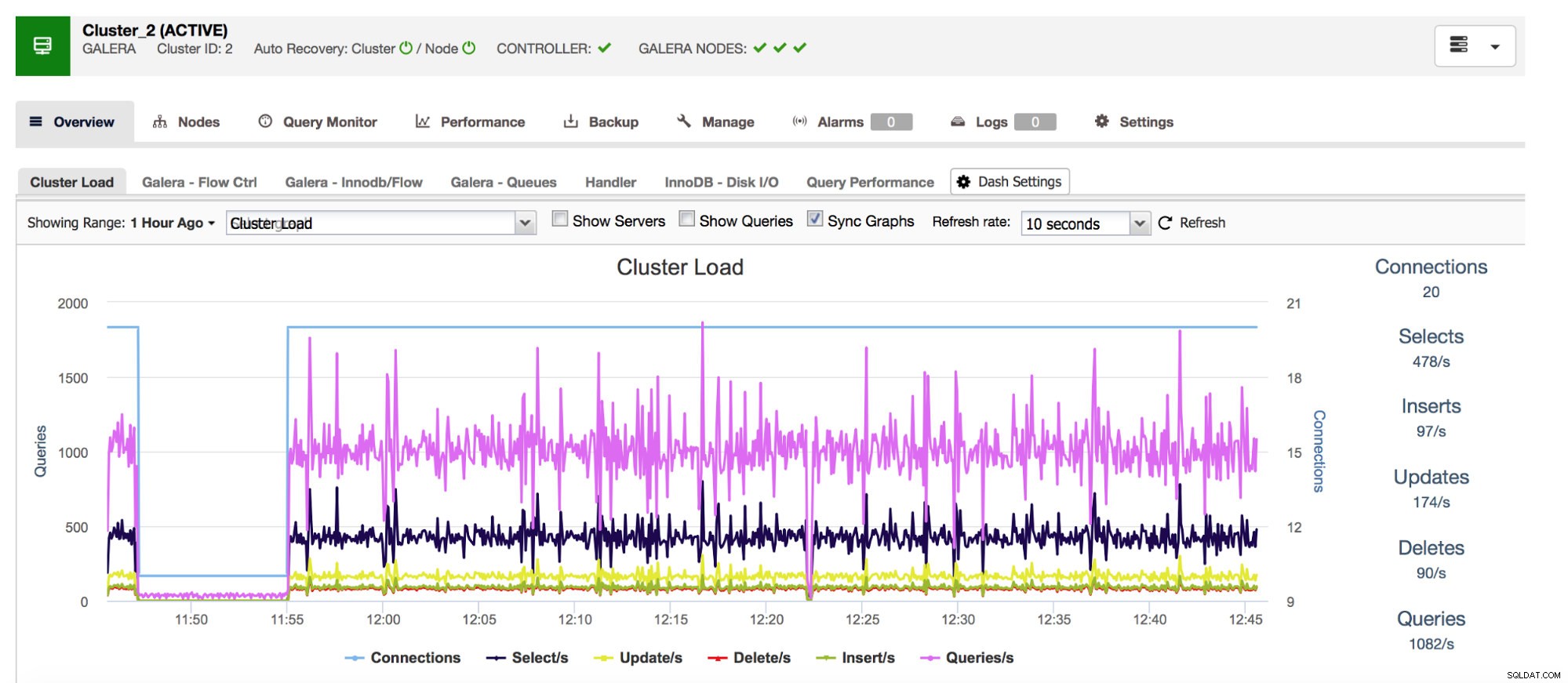
Náš komplexní systém pro správu databází ClusterControl vám zobrazuje tato data související s nejběžnějšími typy dotazů v sekci „Přehled“.
Počítadla stavu Handler_*
Kategorie metrik, které byste měli sledovat, jsou čítače Handler_* v MySQL. Čítače Com_* vám říkají, jaké druhy dotazů vaše instance MySQL provádí, ale jeden SELECT může být zcela odlišný od druhého – SELECT může být vyhledávání primárního klíče, může to být také skenování tabulky, pokud nelze použít index. Obslužné rutiny vám řeknou, jak MySQL přistupuje k uloženým datům – to je velmi užitečné pro zkoumání problémů s výkonem a posouzení, zda je možné získat zisk z kontroly dotazů a dodatečného indexování.
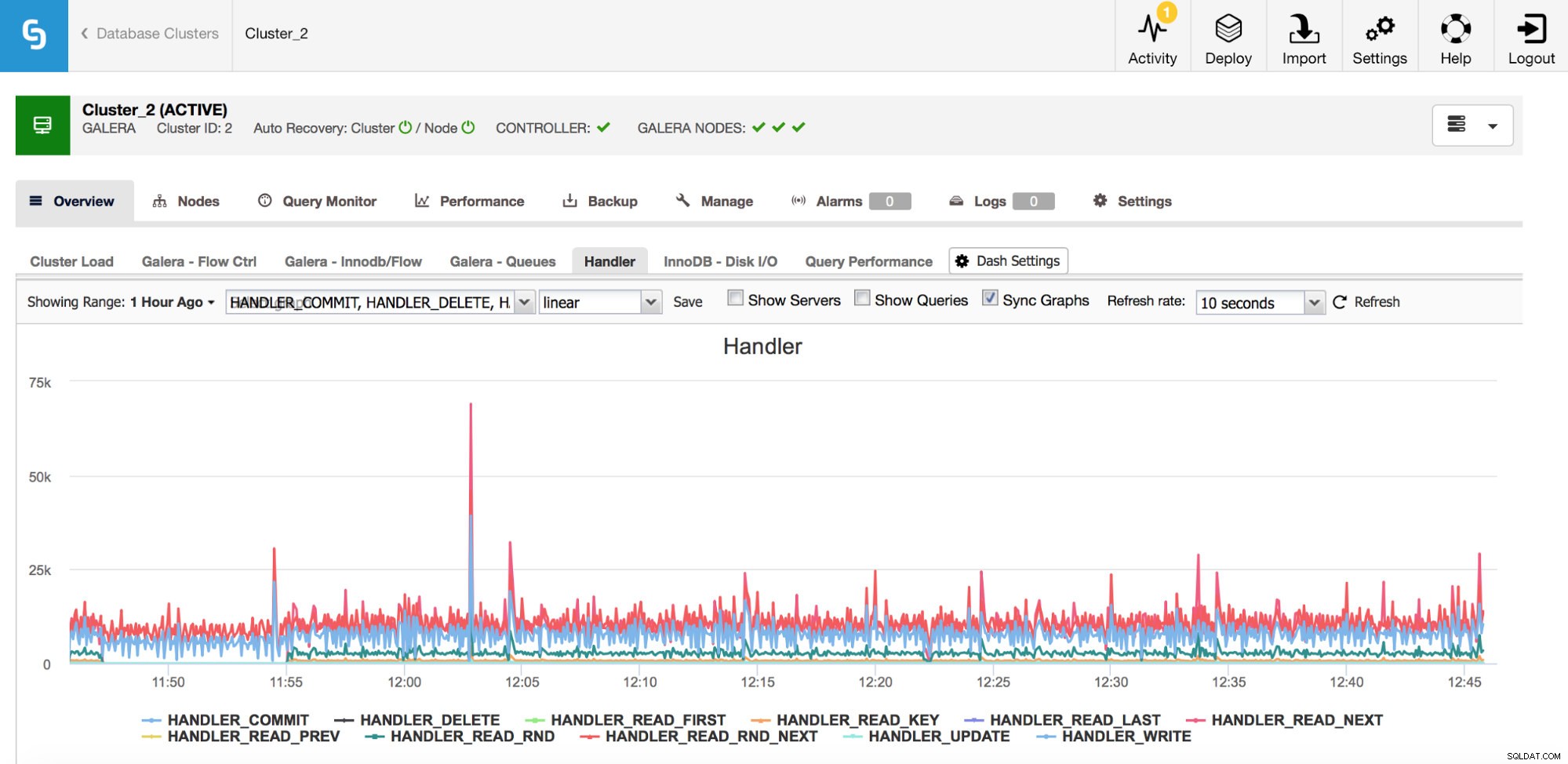
Jak můžete vidět z výše uvedeného grafu, existuje mnoho metrik ke sledování (a grafy ClusterControl ty nejdůležitější) – nebudeme je zde všechny pokrývat (popisy naleznete v dokumentaci MySQL), ale rádi bychom zdůraznili ty nejdůležitější.
Handler_read_rnd_next - kdykoli MySQL přistoupí k řádku bez vyhledávání indexu, v sekvenčním pořadí, bude tento čítač zvýšen. Pokud je ve vaší zátěži handler_read_rnd_next zodpovědný za vysoké procento veškerého provozu, znamená to, že vaše tabulky by s největší pravděpodobností mohly používat nějaké další indexy, protože MySQL provádí spoustu prohledávání tabulek.
Handler_read_next a handler_read_prev – tyto dva čítače se aktualizují vždy, když MySQL provádí skenování indexu – dopředu nebo dozadu. Handler_read_first a handler_read_last mohou vrhnout více světla na to, o jaký druh skenování indexu se jedná – pokud mluvíme o úplném skenování indexu (dopředu nebo vzad), tyto dva čítače budou aktualizovány.
Handler_read_key – tento čítač, na druhou stranu, pokud je jeho hodnota vysoká, vám říká, že vaše tabulky jsou dobře indexovány, protože mnoho řádků bylo zpřístupněno pomocí vyhledávání indexu.
Prodleva replikace
Pokud pracujete s replikací MySQL, je zpoždění replikace metrikou, kterou určitě chcete sledovat. Zpoždění replikace je nevyhnutelné a budete se s ním muset vypořádat, ale abyste se s ním vypořádali, musíte pochopit, proč k němu dochází. Prvním krokem proto bude vědět, _kdy_ se to objevilo.
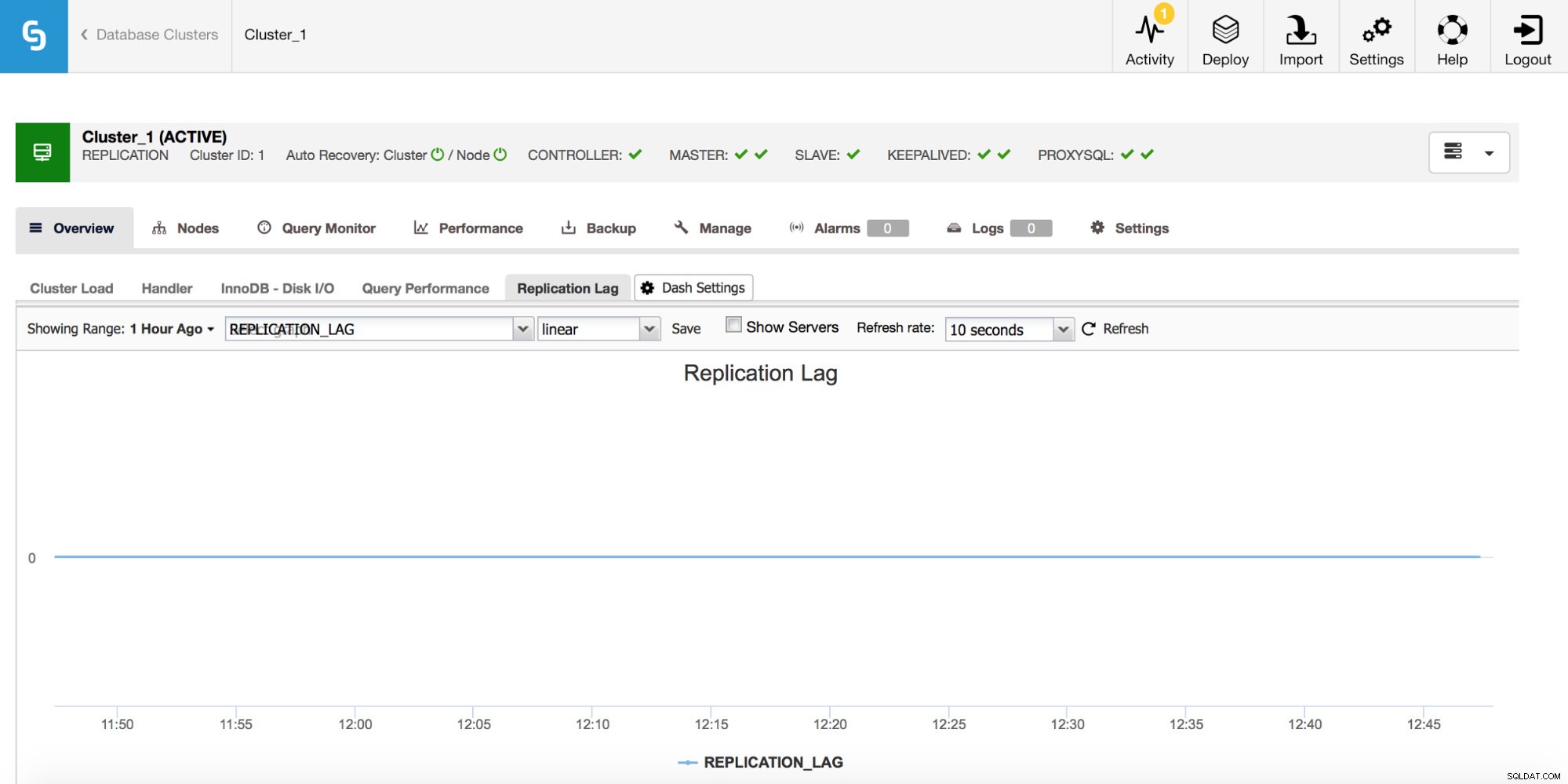
Kdykoli uvidíte špičku zpoždění replikace, budete chtít zkontrolovat další grafy, abyste získali další vodítka – proč se to stalo? Co to mohlo způsobit? Důvody mohou být různé – dlouhé a těžké DML, významný nárůst počtu DML provedených v krátkém časovém období, omezení CPU nebo I/O.
InnoDB I/O
Existuje řada důležitých metrik, které se týkají I/O, ke sledování.
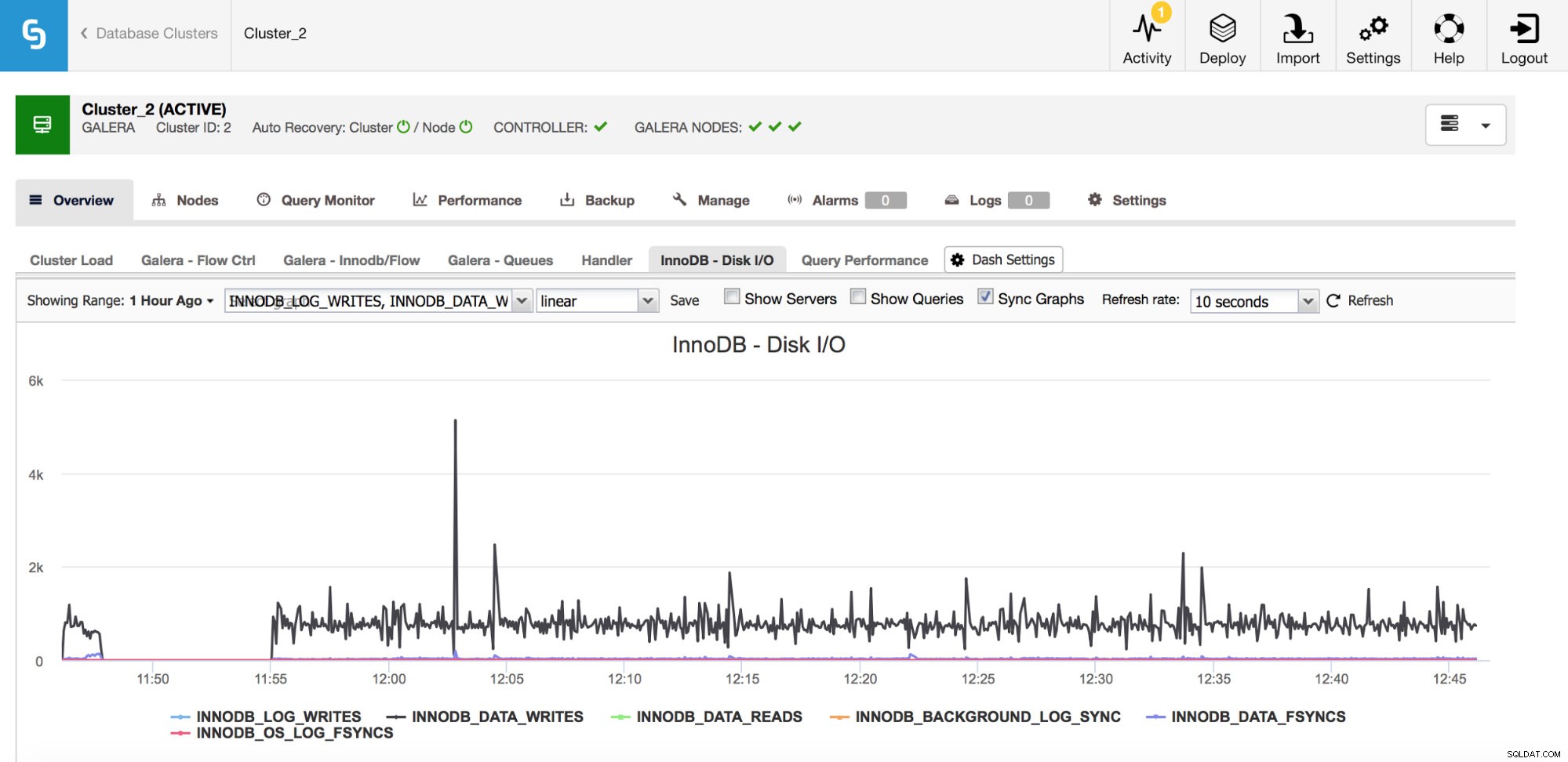
Ve výše uvedeném grafu můžete vidět několik metrik, které vám řeknou, jaký druh I/O InnoDB dělá – data zapisuje a čte, opakování zápisů do protokolu, fsyncs. Tyto metriky vám pomohou například rozhodnout, zda zpoždění replikace bylo způsobeno špičkou I/O nebo možná z nějakého jiného důvodu. Je také důležité sledovat tyto metriky a porovnávat je s vašimi hardwarovými omezeními – pokud se blížíte k hardwarovým limitům vašich disků, možná je čas se na to podívat, než to bude mít vážnější dopad na výkon vaší databáze.
Několik nines DevOps Průvodce správou databázíZjistěte, co potřebujete vědět k automatizaci a správě vašich databází s otevřeným zdrojovým kódemStáhněte si zdarmaMetriky Galera – řízení toku a fronty
Pokud náhodou používáte Galera Cluster (bez ohledu na to, jakou příchuť používáte), existuje několik dalších metrik, které byste chtěli pečlivě sledovat, jsou poněkud propojené. První z nich jsou metriky související s řízením toku.
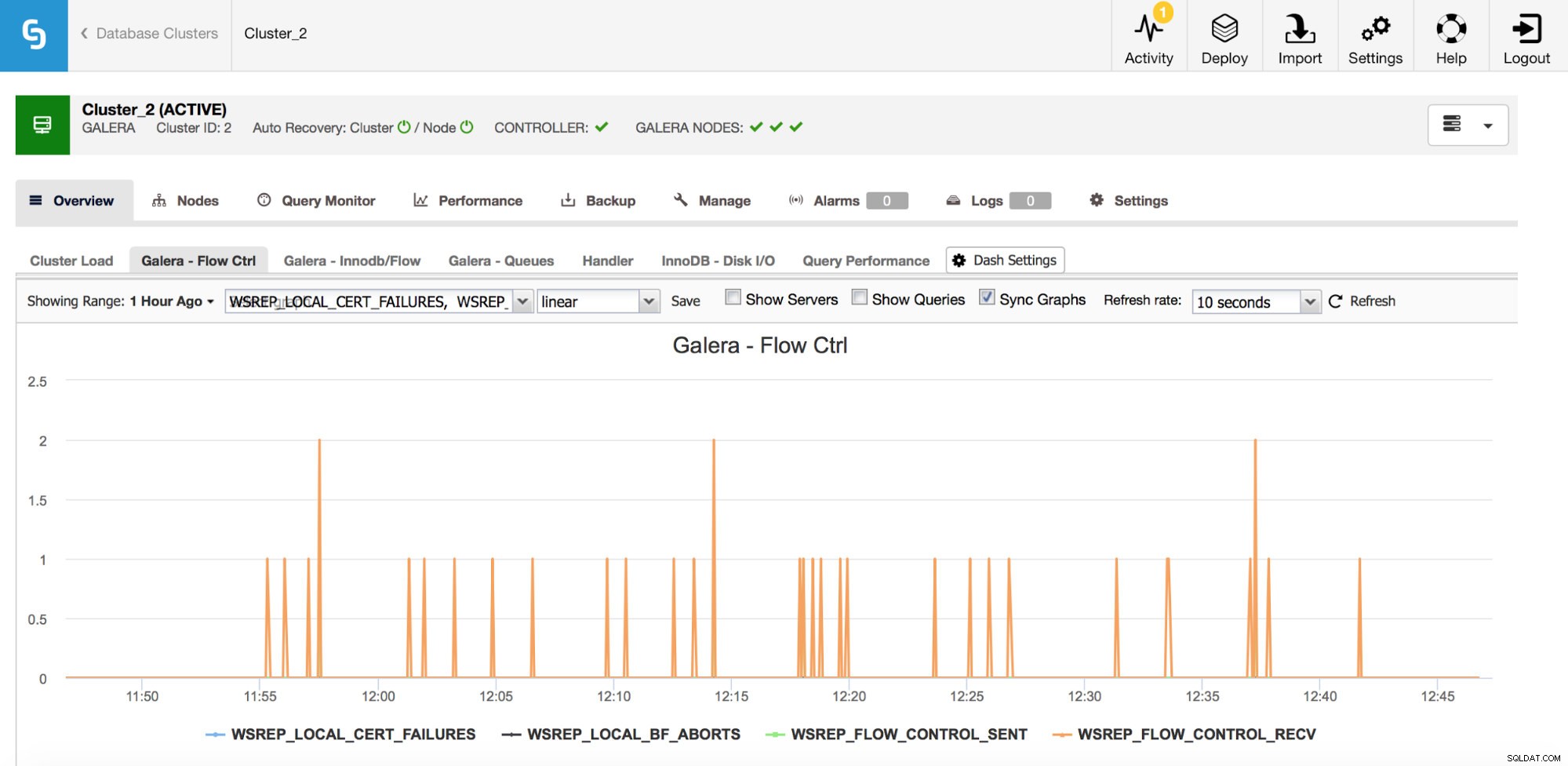
Řízení toku v Galeře je prostředek k udržení synchronizace clusteru. Kdykoli se uzel zablokuje a nemůže držet krok se zbytkem clusteru, začne odesílat zprávy řízení toku s žádostí o zpomalení zbývajících uzlů clusteru. To mu umožňuje dohnat. To snižuje výkon clusteru, takže je důležité vědět, který uzel a kdy začal odesílat zprávy řízení toku. To může vysvětlit některá zpomalení, se kterými se uživatelé setkávají, nebo omezit časové okno a hostitele pro další vyšetřování.
Druhá sada metrik ke sledování jsou ty, které souvisejí s odesíláním a přijímáním front v Galeře.
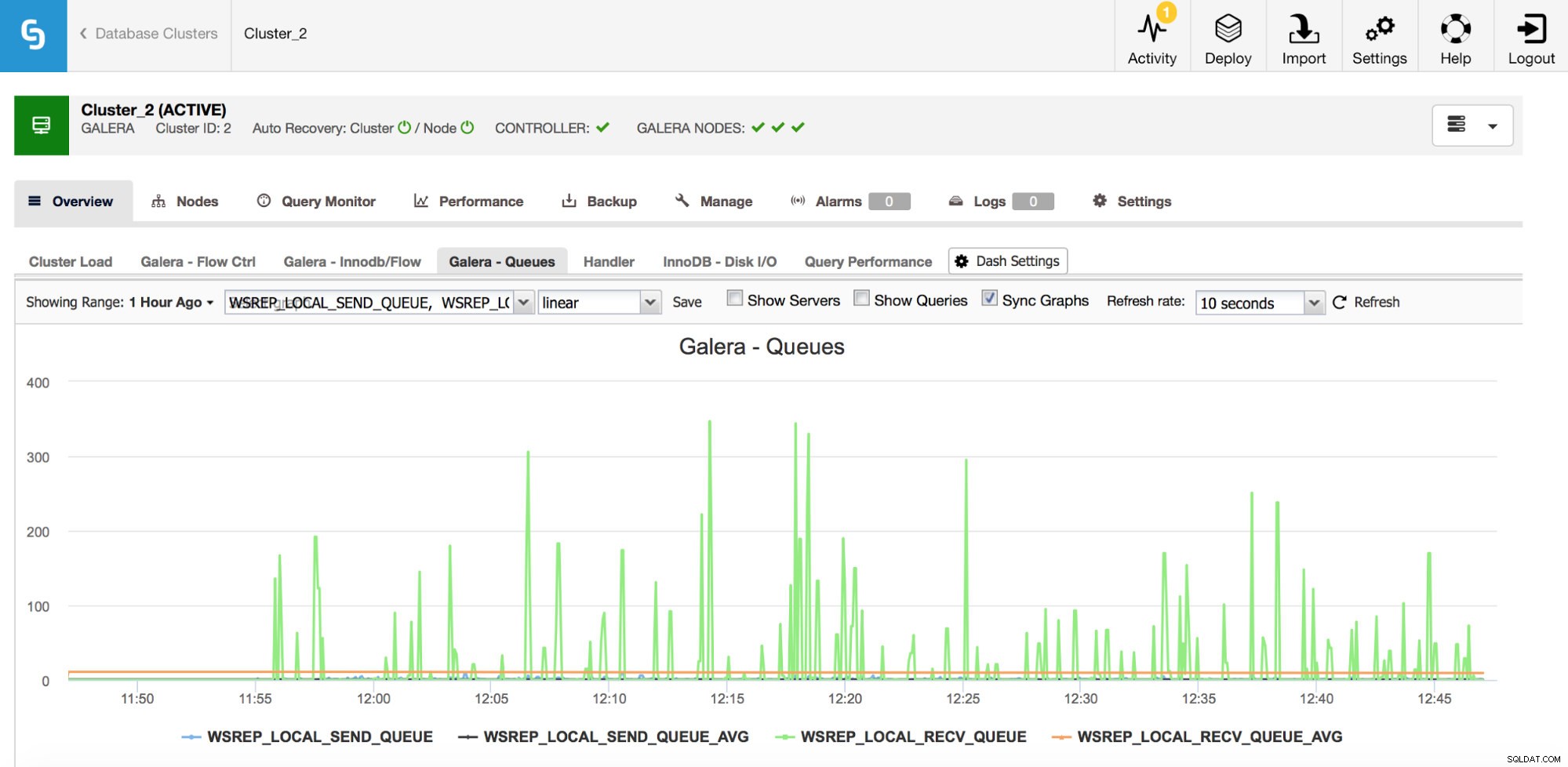
Uzly Galera mohou ukládat sady zápisů (transakce) do mezipaměti, pokud je nemohou všechny okamžitě použít. V případě potřeby mohou také ukládat do mezipaměti sady zápisů, které se chystají odeslat jiným uzlům (pokud daný uzel přijímá zápisy z aplikace). Oba případy jsou příznaky zpomalení, které s největší pravděpodobností povede k odesílání zpráv řízení toku a vyžadují určité vyšetřování – proč k tomu došlo, na kterém uzlu a v jakém čase?
To je samozřejmě jen špička ledovce, když vezmeme v úvahu všechny metriky, které MySQL zpřístupňuje – přesto se nemůžete pokazit, pokud začnete sledovat ty, které jsme zde popsali, kromě běžných metrik OS/hardwaru, jako je CPU , paměť, využití disku a stav služeb.