Vyrovnávače zátěže jsou základní součástí každého vysoce dostupného nastavení databáze. Používají se ke zvýšení kapacity a spolehlivosti vašich kritických systémů a aplikací tím, že zabraňují přetížení jednoho serveru. Hodně o nich mluvíme na blogu Somenines, například proč je potřebujete a jak fungují. Jedním z nejpopulárnějších nástrojů pro vyrovnávání zatížení dostupných pro MySQL a MariaDB je HAProxy.
Pokud jde o funkce, HAProxy není srovnatelné s ProxySQL nebo MaxScale. HAProxy je však rychlý, robustní nástroj pro vyrovnávání zátěže, který bude perfektně fungovat v jakémkoli prostředí, pokud aplikace může provádět rozdělení čtení/zápisu a odesílat dotazy SELECT na jeden backend a všechny zápisy a SELECT...FOR UPDATE na samostatný backend.
Sledování všech metrik zpřístupněných HAProxy je velmi důležité; musíte být schopni znát stav svého proxy, zejména abyste věděli, zda jste narazili na nějaké problémy.
ClusterControl vždy zpřístupňoval stavovou stránku HAProxy zobrazující stav proxy v reálném čase. Nyní, s novými řídicími panely SCUMM (Severalnines ClusterControl Unified Monitoring &Management) založenými na Prometheus, je možné snadno sledovat, jak se tyto metriky v průběhu času mění.
Tento příspěvek na blogu prozkoumá různé metriky prezentované v řídicím panelu HAProxy SCUMM.
Prozkoumání HAProxy Dashboard v ClusterControl
Všechny řídicí panely Prometheus a SCUMM jsou v ClusterControl ve výchozím nastavení zakázány. Jejich nasazení pro jakýkoli daný cluster je však otázkou jednoho kliknutí. Pokud pomocí ClusterControl monitorujete více clusterů, můžete pro každý cluster znovu použít stejnou instanci Prometheus.
Po nasazení můžete získat přístup k řídicímu panelu HAProxy. Podívejme se na data dostupná na řídicím panelu:
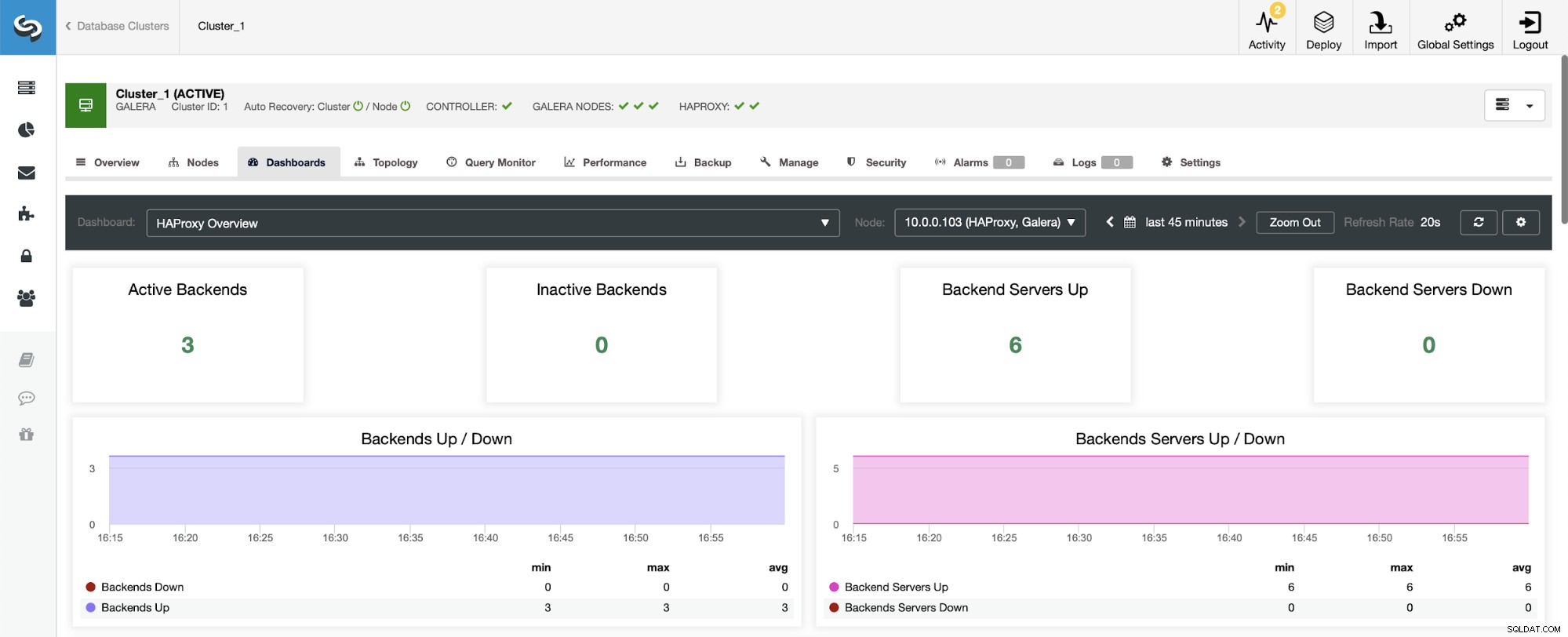
První věc, kterou uvidíte, když přejdete na řídicí panel HAProxy, je informace o stavu vašich backendů. Zde si prosím uvědomte, že to, co vidíte, může záviset na typu clusteru a na tom, jak jste nasadili HAProxy. V tomto případě jsme nasadili cluster Galera a HAProxy bylo nasazeno způsobem round-robin. Proto vidíte tři backendy pro čtení a tři pro zápis – celkem šest. To je také důvod, proč vidíte všechny backendy označené jako „Up.“
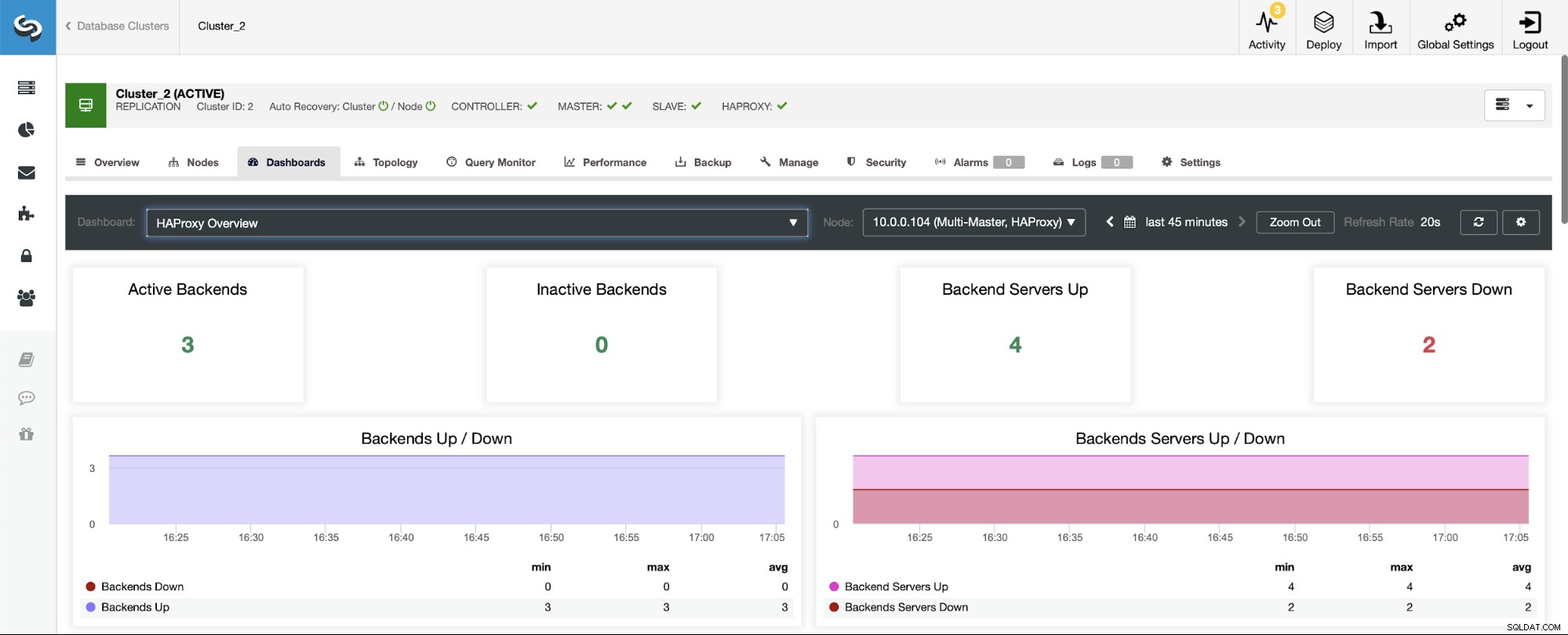
Ve scénáři s replikačním clusterem budou věci vypadat jinak, protože HAProxy bude nasazeno v rozdělení pro čtení/zápis a skripty udrží v provozu pouze jednoho hostitele (hlavního) backend.
Všimněte si, proto níže vidíte dva backendové servery označené jako „Dolů“:
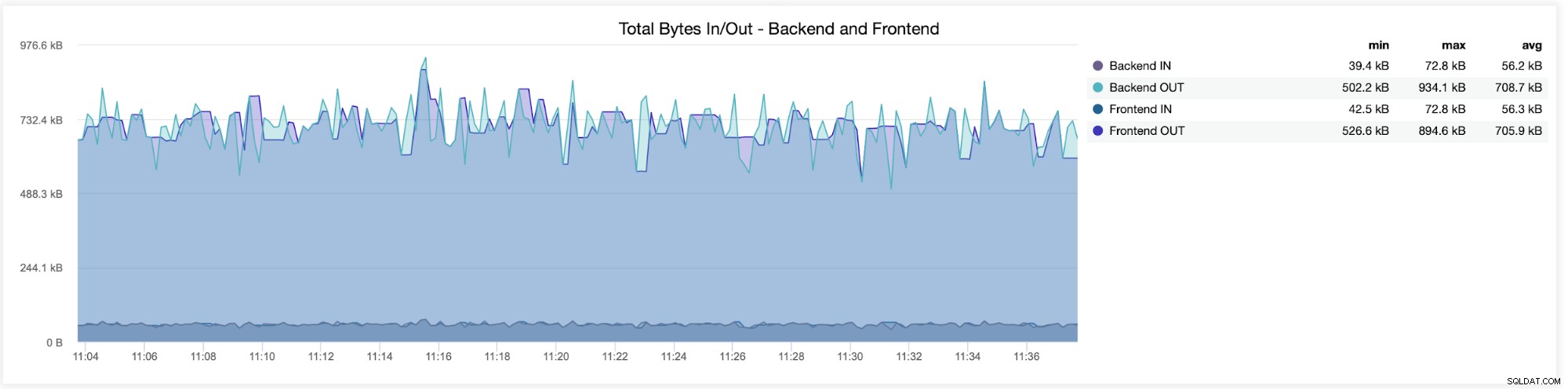
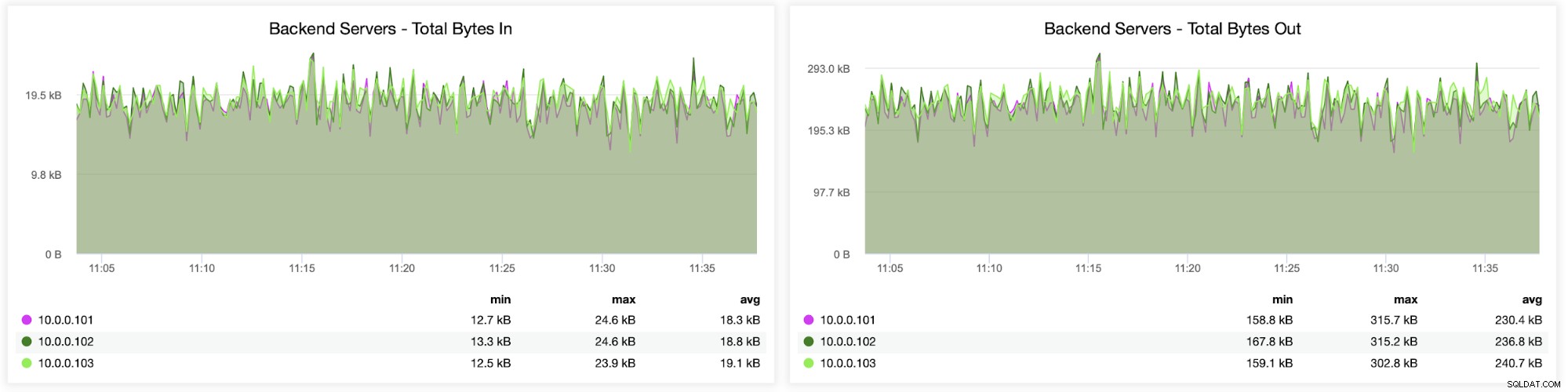
V následujícím grafu uvidíte data odeslaná a přijatá oběma backend (od HAProxy k databázovým serverům) a frontend (mezi HAProxy a klientskými hostiteli):
V konfiguraci HAProxy můžete také zkontrolovat rozložení provozu mezi backendy. V tomto případě máme dva backendy a dotazy se odesílají přes port 3308, který funguje jako kruhový přístupový bod k našemu clusteru Galera:
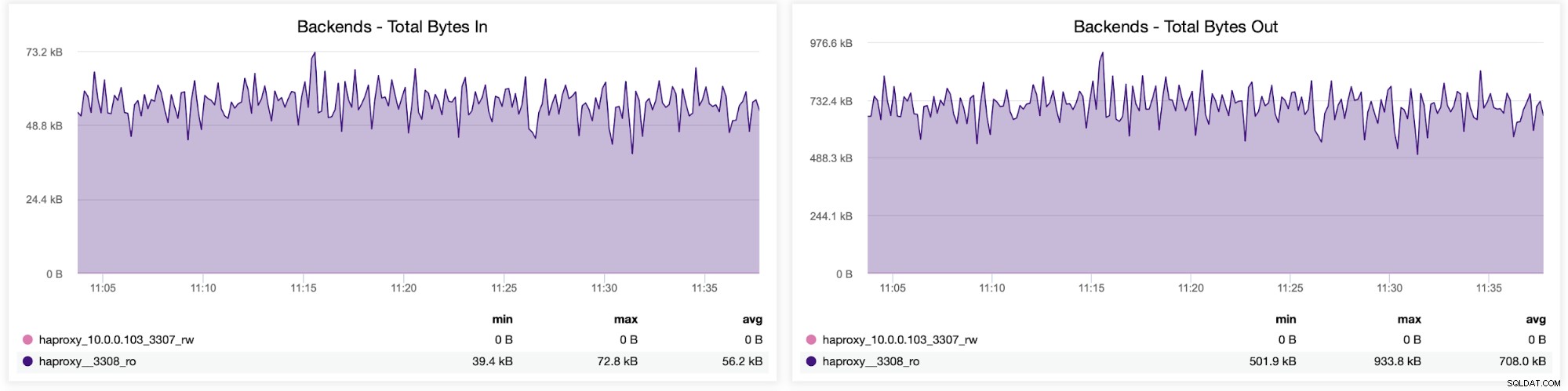
Dále můžete vidět, jak byl provoz distribuován na všechny backendové servery. V tomto scénáři – kvůli kruhovému přístupu – byla data víceméně rovnoměrně distribuována mezi všechny tři backendové servery Galera:
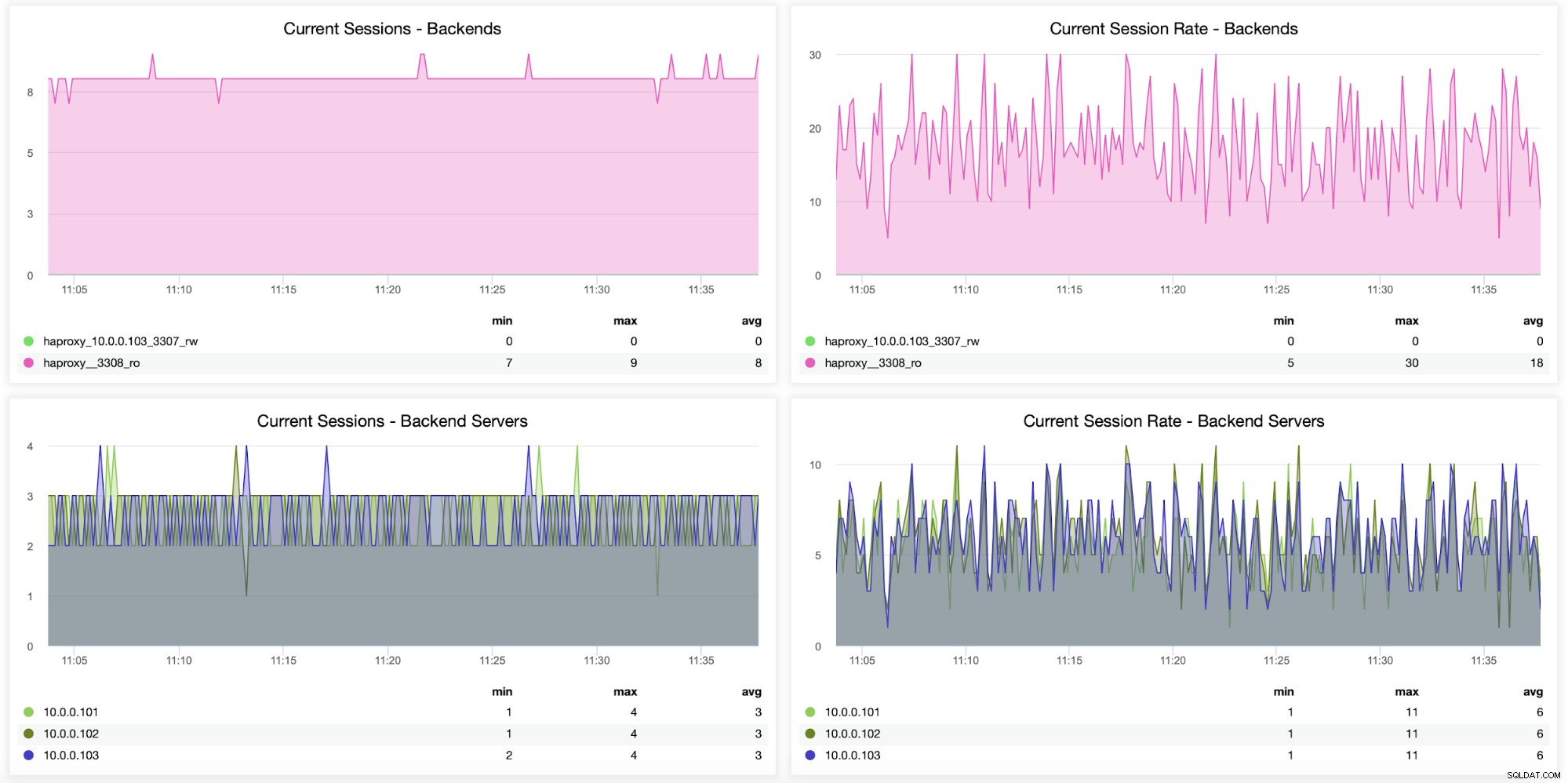
Informace o relacích, včetně toho, kolik relací bylo otevřeno z HAProxy do backendu servery, lze také monitorovat, jak je vidět na následujícím grafu. Můžete také sledovat, kolikrát za sekundu byla otevřena nová relace na backendu a jak tyto metriky vypadají na bázi jednotlivých backendových serverů.
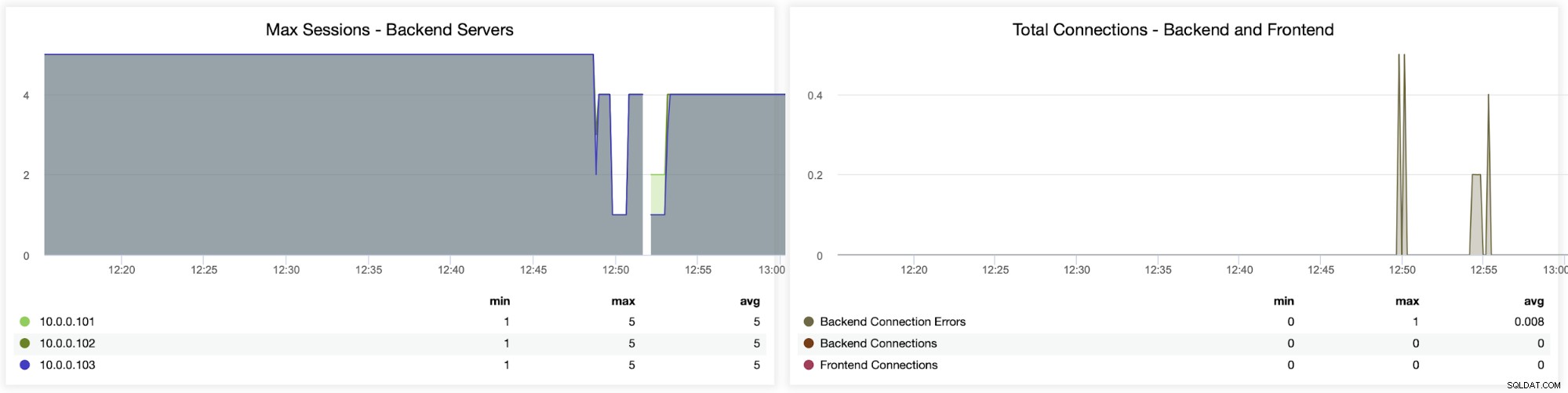
Následující dva grafy znázorňují maximální počet relací na server backend a kdy objevily se problémy s připojením. To může být docela užitečné pro účely ladění, kde narazíte na chybu konfigurace ve vaší instanci HAProxy a spojení začnou vypadávat.
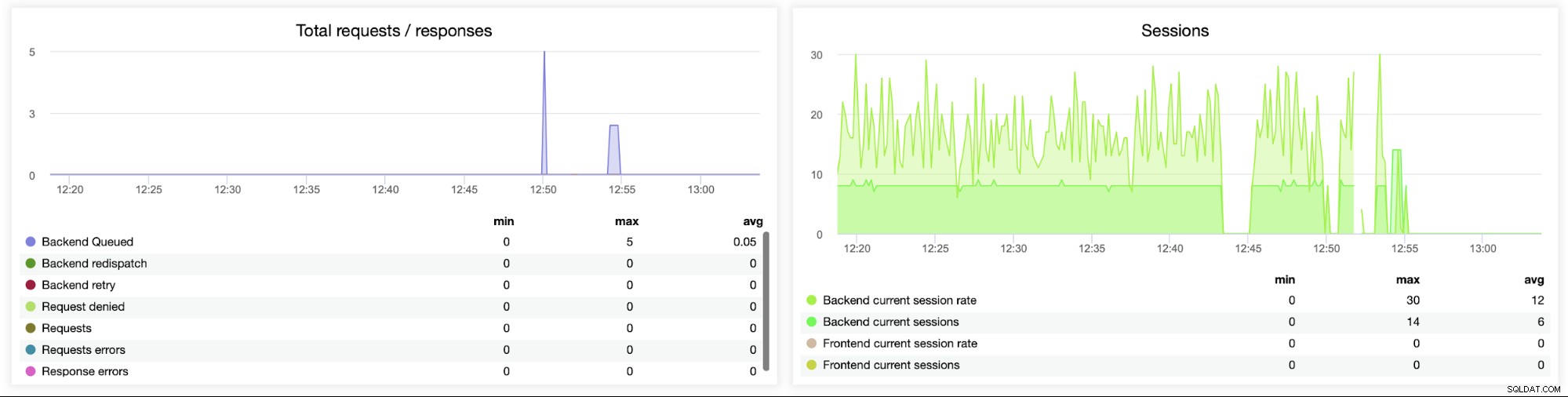
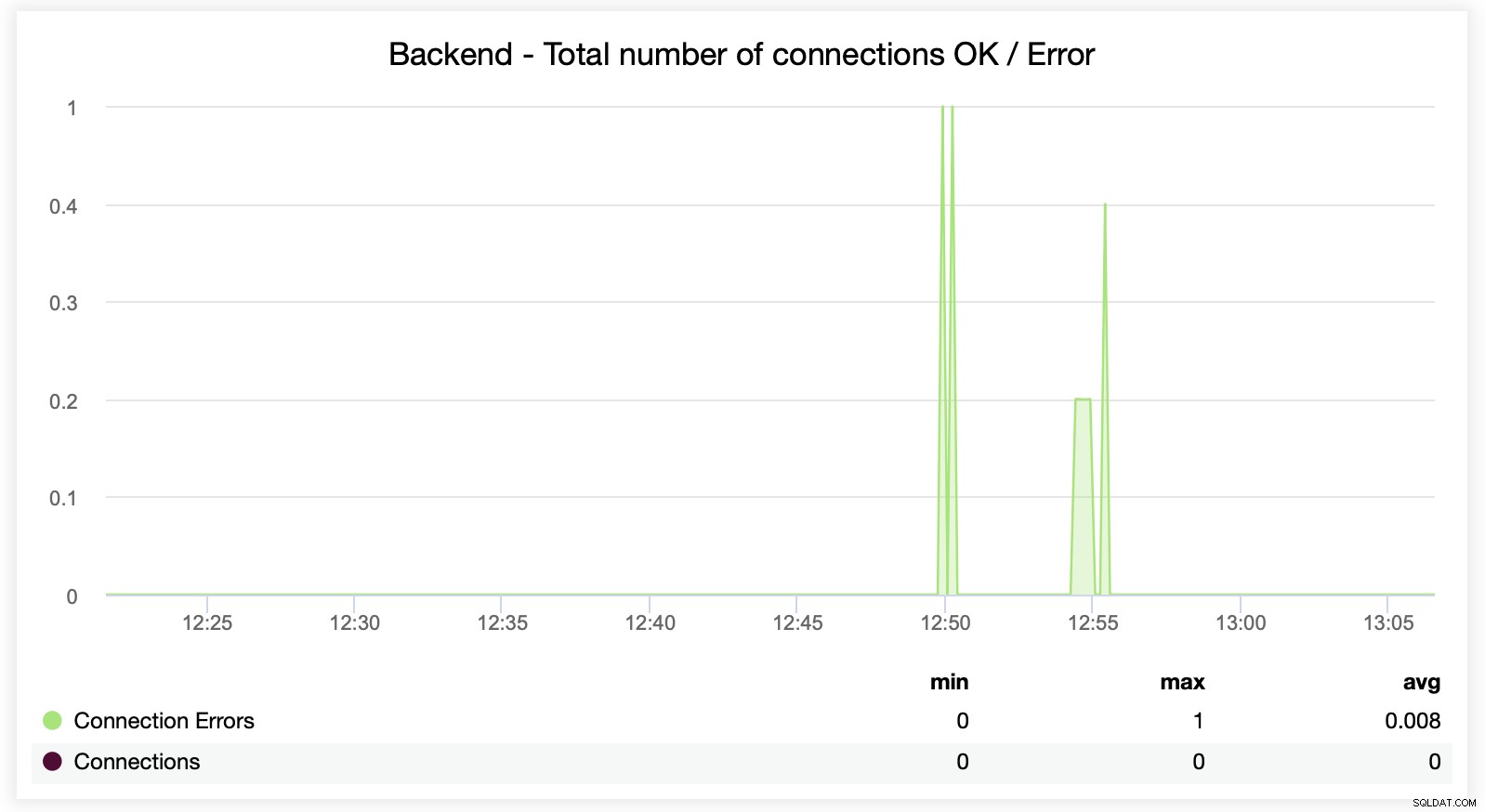
Tento další graf je potenciálně cennější, protože zobrazuje různé metriky související s chybou zpracování, jako jsou chyby, chyby požadavků, opakované pokusy na straně backendu atd. K dispozici je také graf „Relace“ zobrazující přehled metrik relace.
Zde můžete vidět, že ClusterControl sleduje chyby připojení v reálném čase, což může pomoci určit přesný čas, kdy se problémy začaly vyvíjet.
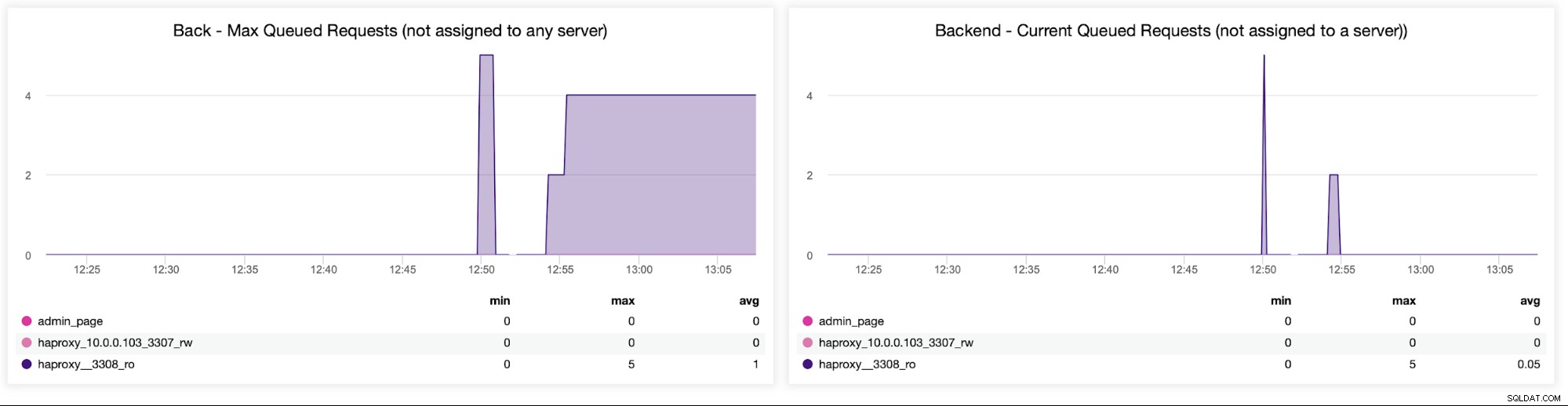
Nakonec se podíváme na následující dva grafy související s požadavky ve frontě . HAProxy řadí požadavky na backend, pokud jsou servery backend přesycené. To může ukazovat například na přetížené databázové servery, které nezvládají žádný další provoz.
Zabalení
Nasazení a sledování vašeho HAProxy load balanceru v ClusterControl vám může usnadnit práci se správou a monitorováním vašich připojení. Jasný přehled o výkonu vašich backendů, rozložení provozu, metrikách relací, chybách připojení a počtu požadavků ve frontě může pomoci zajistit dostupnost a škálovatelnost jakéhokoli nastavení databáze.
Díky ClusterControl je nastavení a sledování vyvažovačů zátěže hračkou pro jakoukoli konfiguraci databáze. Ještě nepoužíváte ClusterControl? Pokud se chcete sami přesvědčit, jak snadné je nasadit a monitorovat váš HAProxy load balancer pomocí ClusterControl, zveme vás na bezplatnou 30denní zkušební verzi platformy bez jakýchkoliv podmínek. Pro podrobnější návod, proč a jak používat HAProxy pro vyrovnávání zátěže, se podívejte na náš tutoriál o vyvažování zátěže MySQL pomocí HAProxy.