Percona XtraDB Cluster je velmi dobře známé řešení vysoké dostupnosti ve světě MySQL. Je založen na Galera Cluster a poskytuje prakticky synchronní replikaci napříč více uzly. Jako u každé databáze je klíčové sledovat, co se děje v systému, zda je výkon na očekávané úrovni, a pokud ne, jaké je úzké místo. To je nanejvýš důležité, abychom byli schopni správně reagovat v situaci, kdy je výkon ovlivněn. Percona XtraDB Cluster samozřejmě přichází s více metrikami a není vždy jasné, které z nich jsou pro sledování stavu databáze nejdůležitější. V tomto blogu probereme několik klíčových metrik, které chcete mít při práci s PXC na očích.
Aby bylo jasno, zaměříme se na metriky jedinečné pro PXC a Galera, nebudeme se zabývat metrikami pro MySQL nebo InnoDB. Tyto metriky byly diskutovány v našich předchozích blozích.
Pojďme se podívat na některé z nejdůležitějších informací, které nám PXC předkládá.
Řízení toku
Řízení toku je do značné míry nejdůležitější metrika, kterou můžete sledovat v libovolném clusteru Galera, proto si pojďme udělat trochu pozadí. Galera je multimaster, prakticky synchronní cluster. Je možné provádět zápisy na kterýkoli z uzlů databáze, které jej tvoří. Každý zápis musí být odeslán do všech uzlů v clusteru, aby bylo zajištěno jeho použití – tento proces se nazývá certifikace. Žádná transakce nemůže být použita dříve, než všechny uzly souhlasí, že může být potvrzena. Pokud má některý z uzlů problémy s výkonem, které mu znemožňují vypořádat se s provozem, začne vydávat zprávy řízení toku, které mají informovat zbytek clusteru o problémech s výkonem a požádat je, aby snížili zátěž a pomohli zpožděným uzel, aby dohnal zbytek clusteru.
Můžete sledovat, kdy uzly musely zavést umělou pauzu, aby umožnily svým zaostávajícím kolegům dohnat pomocí metriky pozastavení řízení toku (wsrep_flow_control_paused):

Můžete také sledovat, zda uzel odesílá nebo přijímá zprávy řízení toku (wsrep_flow_control_recv a wsrep_flow_control_sent).
Tyto informace vám pomohou lépe porozumět tomu, který uzel nefunguje na stejném úrovni jako jeho vrstevníci. Poté se můžete zaměřit na tento uzel a pokusit se pochopit, v čem je problém a jak odstranit úzké místo.
Fronty pro odesílání a přijímání
Tyto metriky svým způsobem souvisejí s řízením toku. Jak jsme diskutovali, uzel může zaostávat za ostatními uzly v clusteru. Může to být způsobeno nerovnoměrným rozdělením zátěže nebo z jiných důvodů (některý proces běžící na pozadí, záloha nebo některé vlastní, těžké dotazy). Než se spustí řízení toku, zpožďující uzly se pokusí uložit příchozí sady zápisů do fronty příjmu (wsrep_local_recv_queue) v naději, že dopad na výkon je přechodný a že bude moci velmi brzy dohnat. Pouze v případě, že se fronta stane příliš velkou (řídí se nastavením gcs.fc_limit), začnou se přes cluster odesílat zprávy řízení toku.

Frontu příjmu můžete považovat za první značku, která ukazuje, že jsou problémy s výkonem a může se spustit řízení toku.

Na druhou stranu, fronta odeslání (wsrep_local_send_queue) vám sdělí, že uzel není schopen odeslat sady zápisů jiným členům klastru, což může naznačovat problémy se síťovou konektivitou (posunutí sad zápisu do síť není skutečně náročná na zdroje).
Metriky paralelizace
Cluster Percona XtraDB lze nakonfigurovat tak, aby k použití příchozích sad zápisu používal více vláken – umožňuje mu to lépe zpracovávat více vláken připojujících se ke clusteru a vydávajících zápisy současně. Existují dvě hlavní metriky, na které byste si měli dávat pozor.
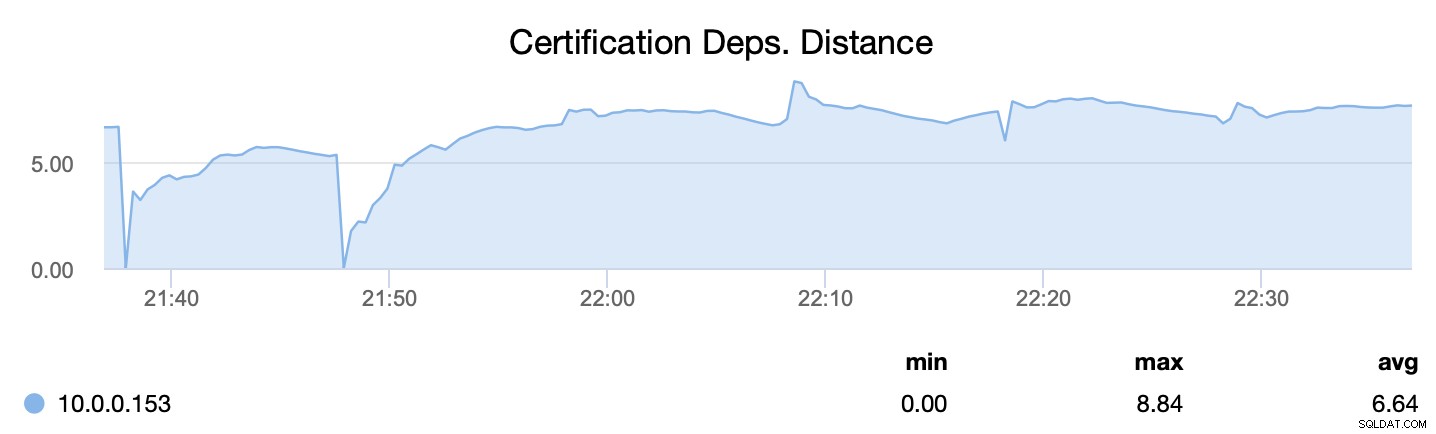
Za prvé, wsrep_cert_deps_distance nám říká, jaký je potenciál paralelizace – kolik sad zápisů lze potenciálně použít současně. Na základě této hodnoty můžete nakonfigurovat počet paralelních podřízených vláken (wsrep_slave_threads), která budou pracovat s aplikací příchozích zápisů. Pravidlem je, že nemá smysl konfigurovat více vláken, než je hodnota wsrep_cert_deps_distance.
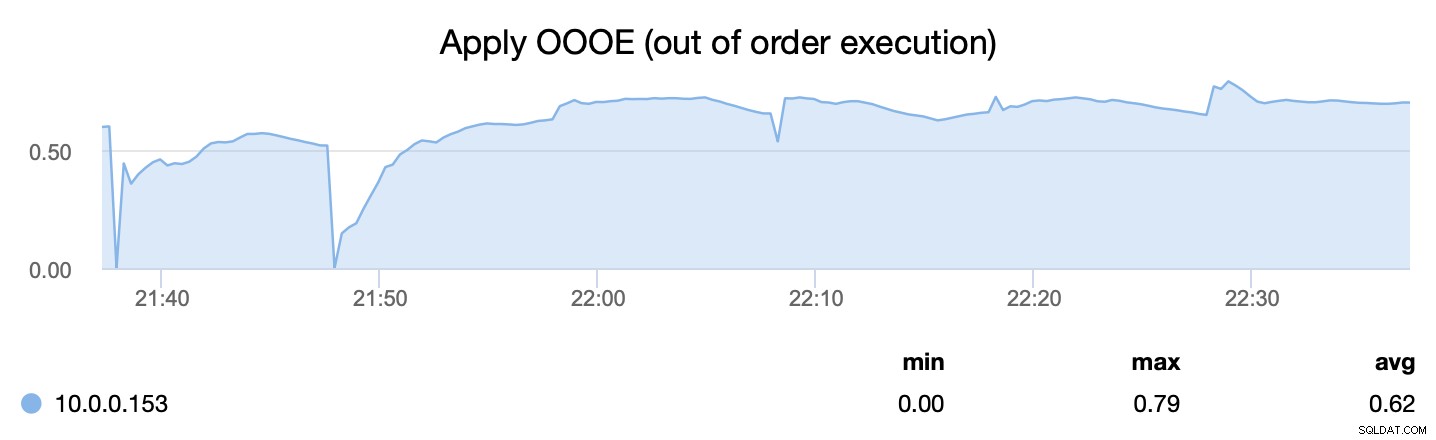
Druhá metrika nám na druhé straně říká, jak efektivně jsme byli schopni paralelizovat proces použití sad zápisů – wsrep_apply_oooe nám říká, jak často aplikace začala používat sady zápisů mimo pořadí (což ukazuje na lepší paralelizaci ).
Závěr
Jak můžete vidět, v Percona XtraDB Cluster je několik metrik, které stojí za pozornost. Samozřejmě, jak jsme uvedli na začátku tohoto blogu, jedná se o metriky striktně související s PXC a Galera Cluster obecně.
Měli byste také sledovat běžné metriky MySQL a InnoDB, abyste lépe porozuměli stavu vaší databáze. A nezapomeňte, že tuto technologii můžete zdarma sledovat pomocí ClusterControl Community Edition.