V předchozím blogu jsme diskutovali o tom, jak migrovat samostatné nastavení Moodle na škálovatelné nastavení založené na klastrované databázi. Dalším krokem, na který budete muset myslet, je mechanismus převzetí služeb při selhání – co uděláte, když a když vaše databázová služba selže.
Selhání databázového serveru není nic neobvyklého, pokud máte jako backendovou databázi Moodle replikaci MySQL, a pokud k tomu dojde, budete muset najít způsob, jak obnovit topologii, například podporou záložního serveru. stát se novým primárním serverem. Automatické převzetí služeb při selhání pro databázi Moodle MySQL pomáhá provozu aplikací. Vysvětlíme vám, jak fungují mechanismy převzetí služeb při selhání a jak zabudovat automatické převzetí služeb při selhání do vašeho nastavení.
Architektura vysoké dostupnosti pro databázi MySQL
Architektury vysoké dostupnosti lze dosáhnout shlukováním databáze MySQL několika různými způsoby. Můžete použít replikaci MySQL, nastavit více replik, které úzce sledují vaši primární databázi. Kromě toho můžete použít nástroj pro vyrovnávání zatížení databáze, který rozdělí provoz pro čtení/zápis a distribuuje provoz mezi uzly pro čtení a zápis a pouze pro čtení. Architektura databáze s vysokou dostupností využívající replikaci MySQL může být popsána níže:
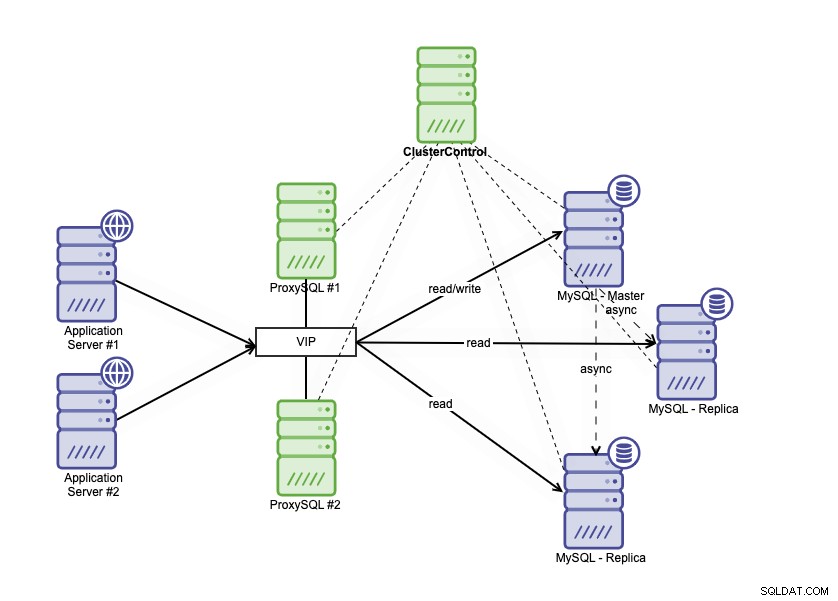
Skládá se z jedné primární databáze, dvou databázových replik a vyvažovačů zatížení databáze (v tomto blogu používáme ProxySQL jako nástroje pro vyrovnávání zatížení databáze) a keepalved jako službu pro monitorování procesů ProxySQL. Virtuální IP adresu používáme jako jediné připojení z aplikace. Provoz bude distribuován do aktivního nástroje pro vyrovnávání zatížení na základě příznaku role v keepalved.
ProxySQL je schopen analyzovat provoz a pochopit, zda je požadavek čtení nebo zápis. Poté předá požadavek příslušnému hostiteli (hostitelům).
Přepnutí při selhání replikace MySQL
Replikace MySQL používá binární protokolování k replikaci dat z primárních do replik. Repliky se připojují k primárnímu uzlu a každá změna je replikována a zapsána do protokolů přenosu uzlů repliky prostřednictvím IO_THREAD. Po uložení změn do protokolu přenosu bude proces SQL_THREAD pokračovat s aplikací dat do databáze replik.
Výchozí nastavení parametru read_only v replice je ZAPNUTO. Slouží k ochraně samotné repliky před jakýmkoli přímým zápisem, takže změny vždy pocházejí z primární databáze. To je důležité, protože nechceme, aby se replika odchýlila od primárního serveru. Scénář převzetí služeb při selhání v replikaci MySQL nastane, když primární není dosažitelné. Důvodů pro to může být mnoho; např. selhání serveru nebo problémy se sítí.
Musíte povýšit jednu z replik na primární, zakázat parametr pouze pro čtení u povýšené repliky, aby do ní bylo možné zapisovat. Musíte také změnit druhou repliku, abyste se mohli připojit k novému primárnímu. V režimu GTID si nemusíte poznamenat název binárního protokolu a pozici, odkud chcete replikaci obnovit. V tradiční replikaci založené na binlogu však rozhodně potřebujete znát název posledního binárního protokolu a pozici, ze které chcete pokračovat. Přepnutí při selhání při replikaci založené na binlogu je poměrně složitý proces, ale ani přepnutí při selhání při replikaci založené na GTID není triviální, protože musíte dávat pozor na věci, jako jsou chybné transakce. Detekce poruchy je jedna věc a reakce na poruchu s krátkou prodlevou se bez automatizace pravděpodobně neobejde.
Jak ClusterControl povoluje automatické převzetí služeb při selhání
ClusterControl má schopnost provádět automatické převzetí služeb při selhání pro vaši databázi Moodle MySQL. Existuje funkce Automatic Recovery for Cluster and Node, která spustí proces převzetí služeb při selhání při selhání primární databáze.
Budeme simulovat, jak probíhá automatické převzetí služeb při selhání v ClusterControl. Uděláme havárii primární databáze a uvidíme se na řídicím panelu ClusterControl. Níže je aktuální topologie clusteru:
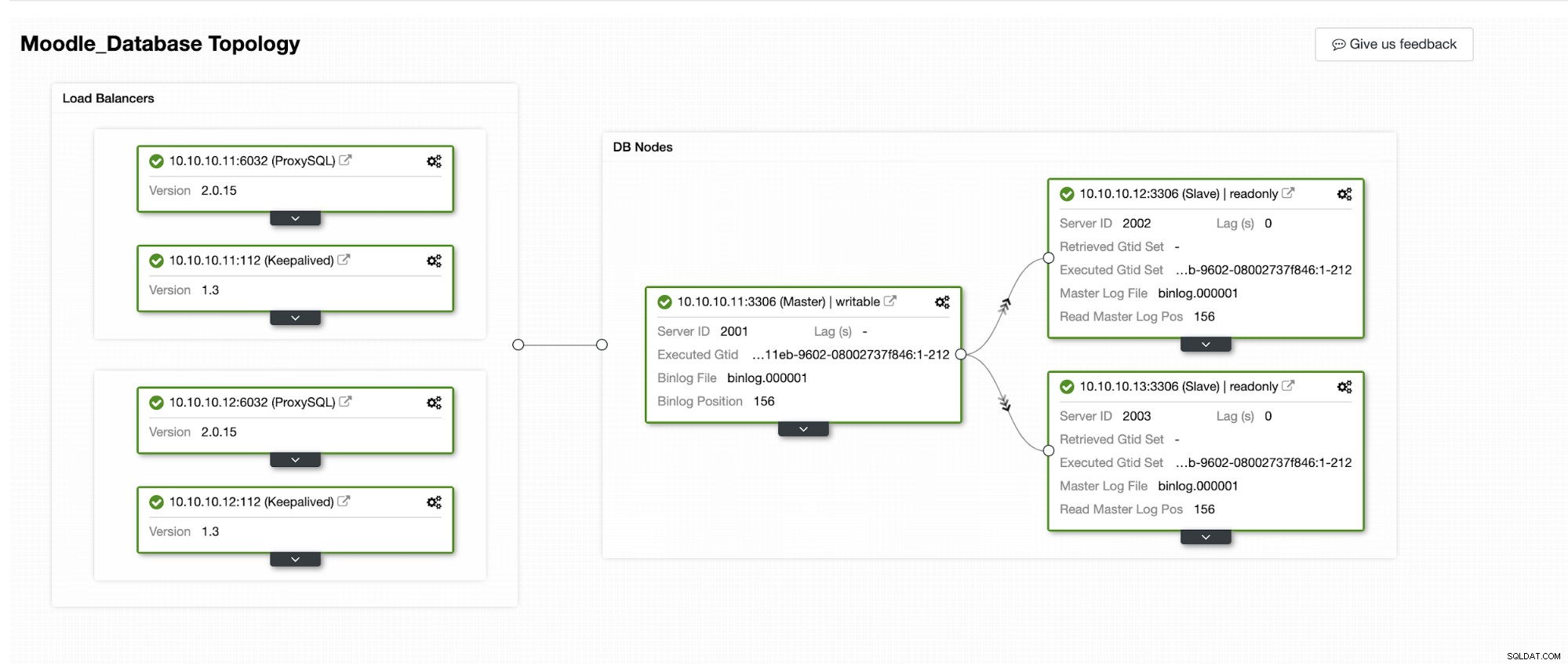
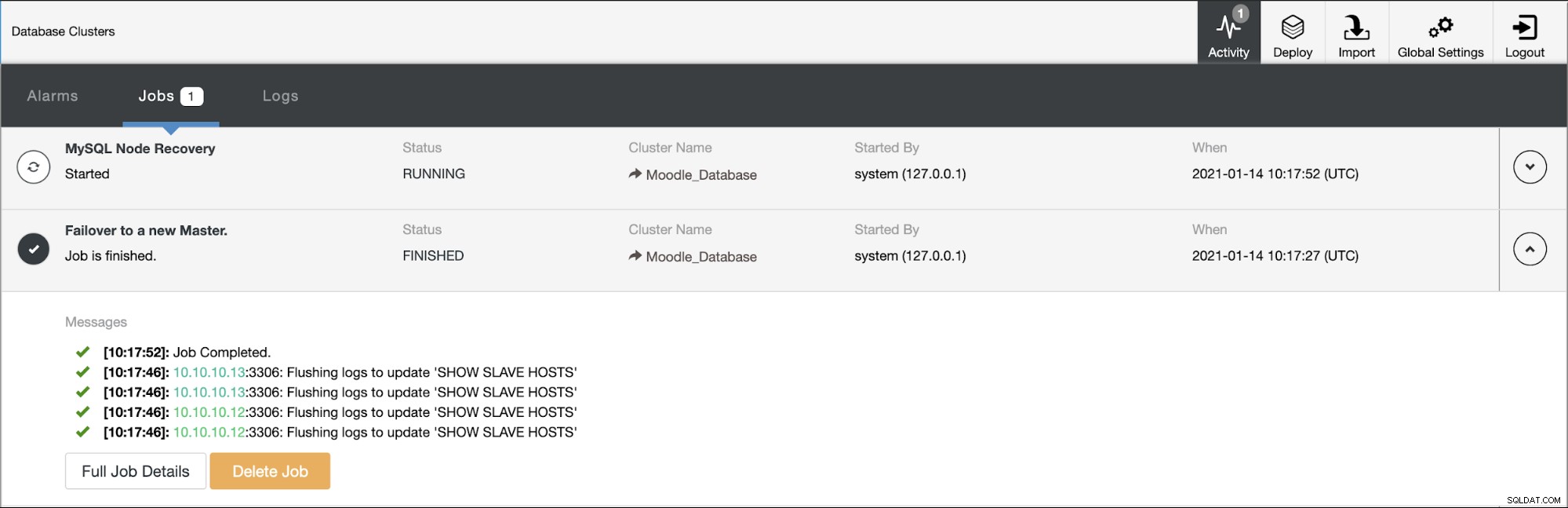
Primární databáze používá IP adresu 10.10.10.11 a repliky jsou:10.10.10.12 a 10.10.10.13. Když dojde k havárii primárního zařízení, ClusterControl spustí výstrahu a spustí se převzetí služeb při selhání, jak je znázorněno na obrázku níže:
Jedna z replik bude povýšena na primární, výsledkem čehož bude topologie jako na obrázku níže:
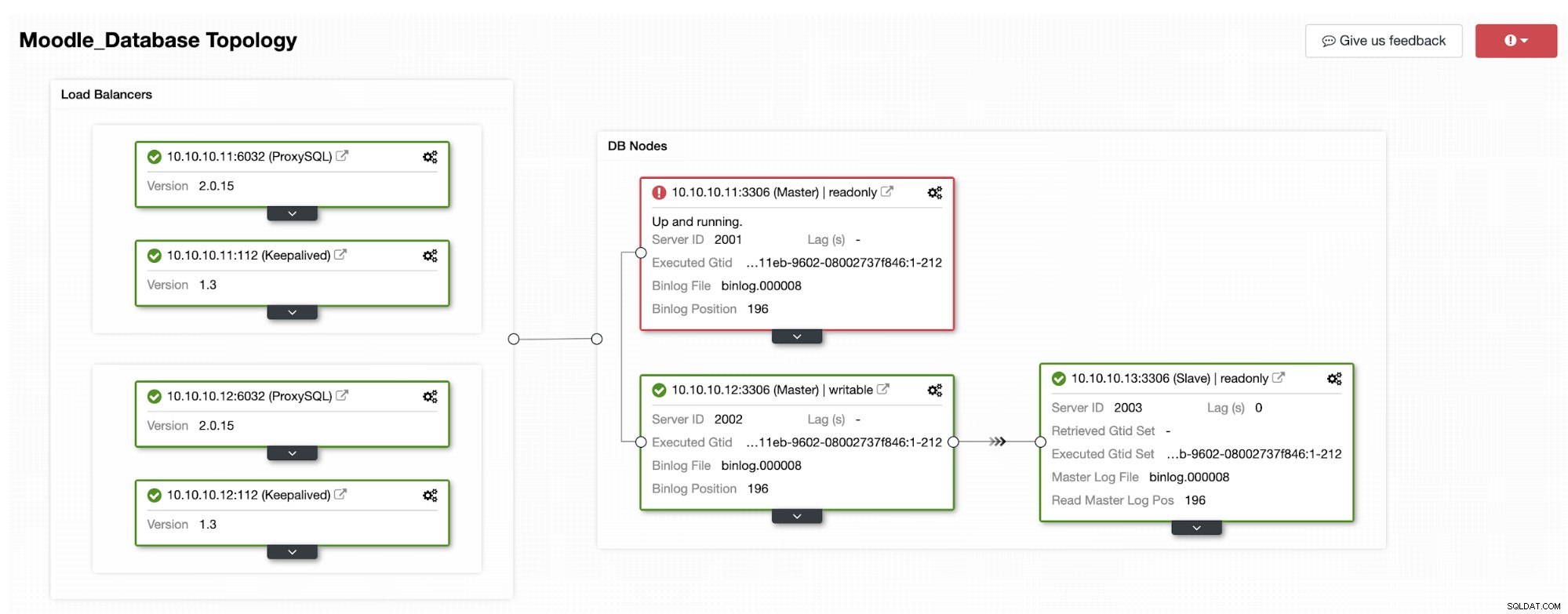
IP adresa 10.10.10.12 nyní slouží pro zápis jako primární, a také nám zbyla pouze jedna replika, která má IP adresu 10.10.10.13. Na straně ProxySQL server proxy automaticky rozpozná nový primární server. Hostgroup (HG10) stále obsluhuje provoz zápisu, který má člena 10.10.10.12, jak je uvedeno níže:

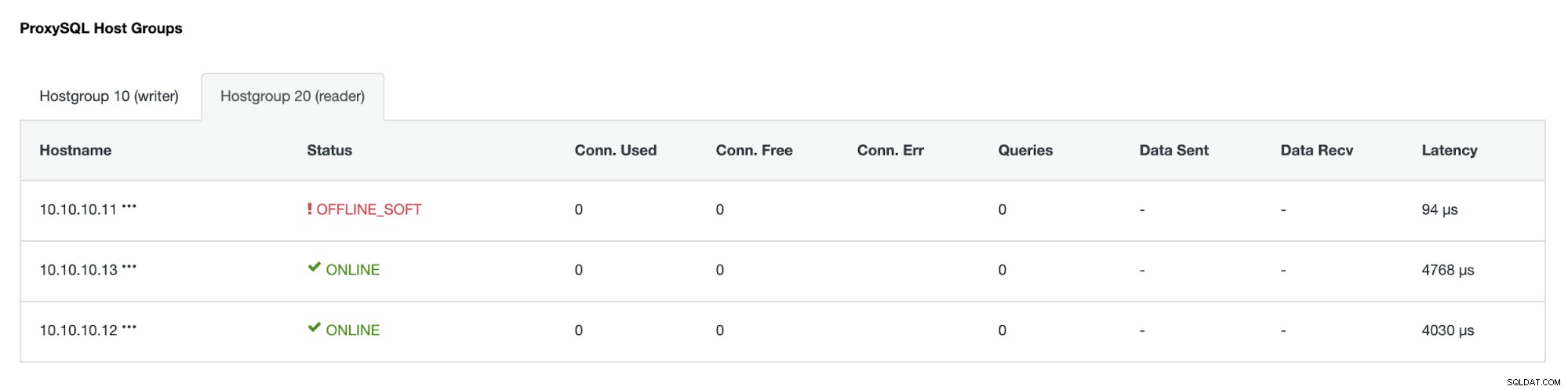
Hostitelská skupina (HG20) stále může obsluhovat čtení, ale jak vidíte uzel 10.10.10.11 je offline kvůli havárii:
Jakmile se primární server se selháním vrátí do režimu online, nebude automaticky znovu -zavedena v topologii databáze. Tím se zabrání ztrátě informací o odstraňování problémů, protože opětovné zavedení uzlu jako repliky může vyžadovat přepsání některých protokolů nebo jiných informací. Je však možné nakonfigurovat automatické opětovné připojení neúspěšného uzlu.