Testy vydání jsou obvykle jedním z kroků v celém procesu nasazení. Napíšete kód a poté ověříte, jak se chová ve zkušebním prostředí, a nakonec nasadíte nový kód do produkčního prostředí. Databáze jsou interní pro jakýkoli druh aplikace, a proto je důležité ověřit, jak změny související s databází mění aplikaci. Je možné to ověřit několika způsoby; jedním z nich by bylo použití vyhrazené repliky. Pojďme se podívat, jak to lze provést.
Je zřejmé, že nechcete, aby byl tento proces manuální – měl by být součástí procesů CI/CD vaší společnosti. V závislosti na přesné aplikaci, prostředí a procesech, které používáte, můžete používat repliky vytvořené ad-hoc nebo repliky, které jsou vždy součástí databázového prostředí.
Cluster Galera funguje tak, že zpracovává změny schématu specifickým způsobem. Je možné provést změnu schématu na jednom uzlu v clusteru, ale je to složité, protože nepodporuje všechny možné změny schématu a pokud se něco pokazí, ovlivní produkci. Takový uzel by musel být plně přestavěn pomocí SST, což znamená, že jeden ze zbývajících uzlů Galera bude muset fungovat jako dárce a přenášet všechna svá data přes síť.
Alternativou bude použití repliky nebo dokonce celého dalšího Galera Cluster fungujícího jako replika. Je zřejmé, že proces musí být automatizován, aby byl zapojen do vývojového kanálu. Existuje mnoho způsobů, jak toho dosáhnout:skripty nebo četné nástroje pro orchestraci infrastruktury, jako je Ansible, Chef, Puppet nebo Salt stack. Nebudeme je podrobně popisovat, ale rádi bychom, abyste ukázali kroky potřebné k tomu, aby celý proces správně fungoval, a implementaci v jednom z nástrojů necháme na vás.
Automatizace testů vydání
Především chceme mít možnost snadno nasadit novou databázi. Měla by být vybavena nejnovějšími daty, a to lze provést mnoha způsoby – můžete zkopírovat data z produkční databáze na testovací server; to je to nejjednodušší. Případně můžete použít nejnovější zálohu – takový přístup má další výhody testování obnovy zálohy. Ověření zálohy je nutností v každém druhu seriózního nasazení a přebudování testovacích nastavení je skvělý způsob, jak znovu zkontrolovat fungování procesu obnovy. Pomáhá vám také načasovat proces obnovy – vědět, jak dlouho trvá obnova zálohy, pomáhá správně vyhodnotit situaci ve scénáři obnovy po havárii.
Jakmile budou data zřízena v databázi, možná budete chtít nastavit tento uzel jako repliku vašeho primárního clusteru. Má to svá pro a proti. Pokud byste mohli znovu spustit veškerý svůj provoz do samostatného uzlu, bylo by to perfektní – v takovém případě není potřeba nastavovat replikaci. Některé z nástrojů pro vyrovnávání zatížení, jako je ProxySQL, vám umožňují zrcadlit provoz a odeslat jeho kopii na jiné místo. Na druhou stranu, replikace je další nejlepší věc. Ano, nemůžete provádět zápisy přímo na tomto uzlu, což vás nutí plánovat, jak budete dotazy znovu provádět, protože nejjednodušší přístup, kterým je pouhé odpovídání, nebude fungovat. Na druhou stranu, všechny zápisy budou nakonec prováděny přes SQL vlákno, takže stačí plánovat, jak se vypořádat s SELECT dotazy.
V závislosti na přesné změně možná budete chtít otestovat proces změny schématu. Změny schématu jsou poměrně běžné a mohou mít dokonce vážný dopad na výkon databáze. Proto je důležité je před použitím ve výrobě ověřit. Chceme se podívat na čas potřebný k provedení změny a ověřit, zda lze změnu aplikovat na uzly samostatně nebo zda je potřeba provést změnu na celé topologii současně. To nám řekne, jaký proces bychom měli použít pro danou změnu schématu.
Použití ClusterControl ke zlepšení automatizace testů vydání
ClusterControl přichází se sadou funkcí, které lze použít k automatizaci testů vydání. Pojďme se podívat, co nabízí. Aby bylo jasno, funkce, které ukážeme, jsou dostupné několika způsoby. Nejjednodušší způsob je použít uživatelské rozhraní, ale je zbytečné, co chcete dělat, pokud máte na mysli automatizaci. Existují dva další způsoby, jak to udělat:Rozhraní příkazového řádku pro ClusterControl a RPC API. V obou případech lze úlohy spouštět z externích skriptů, což vám umožní zapojit je do vašich stávajících procesů CI/CD. Ušetří vám to také spoustu času, protože nasazení clusteru může být jen otázkou provedení jednoho příkazu namísto ručního nastavování.
Nasazení testovacího clusteru
ClusterControl přichází v první řadě s možností nasadit nový cluster a poskytnout mu data ze stávající databáze. Tato funkce sama o sobě umožňuje snadno implementovat zajišťování pracovního serveru.
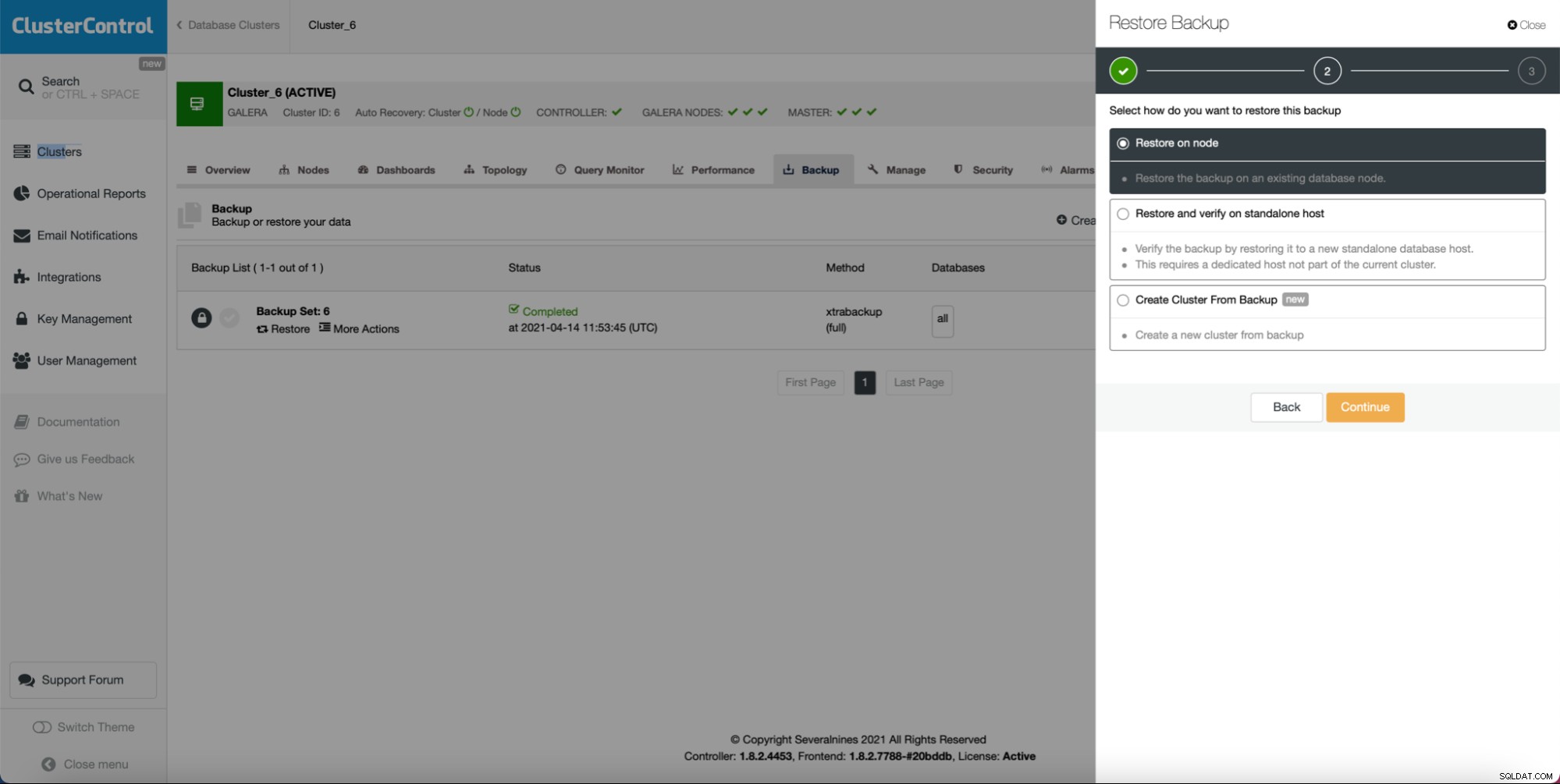
Jak vidíte, pokud máte vytvořenou zálohu, může vytvořit nový cluster a zřídit jej pomocí dat ze zálohy:
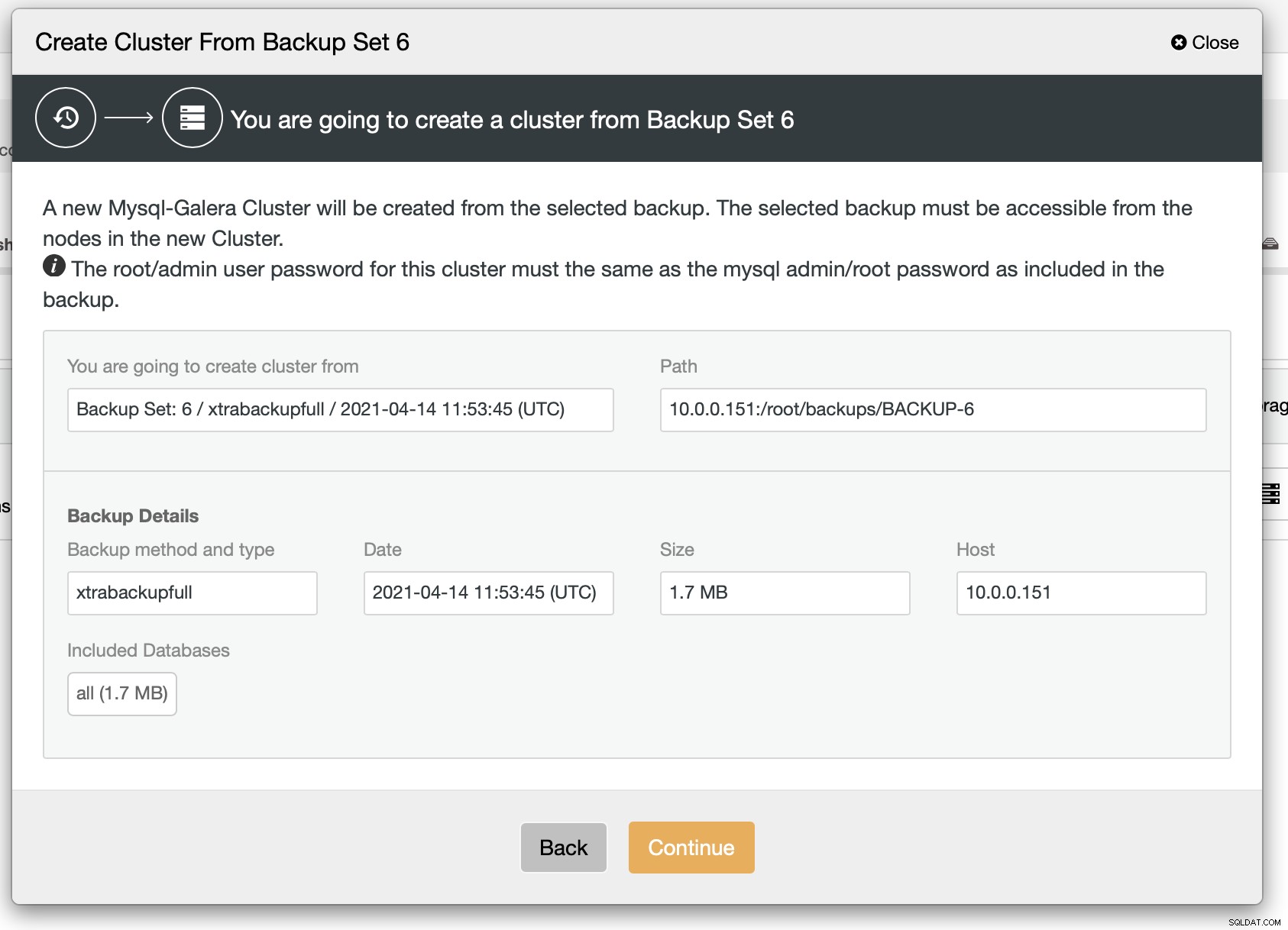
Jak vidíme, je zde rychlé shrnutí toho, co se stane. Pokud kliknete na Pokračovat, budete pokračovat dále.
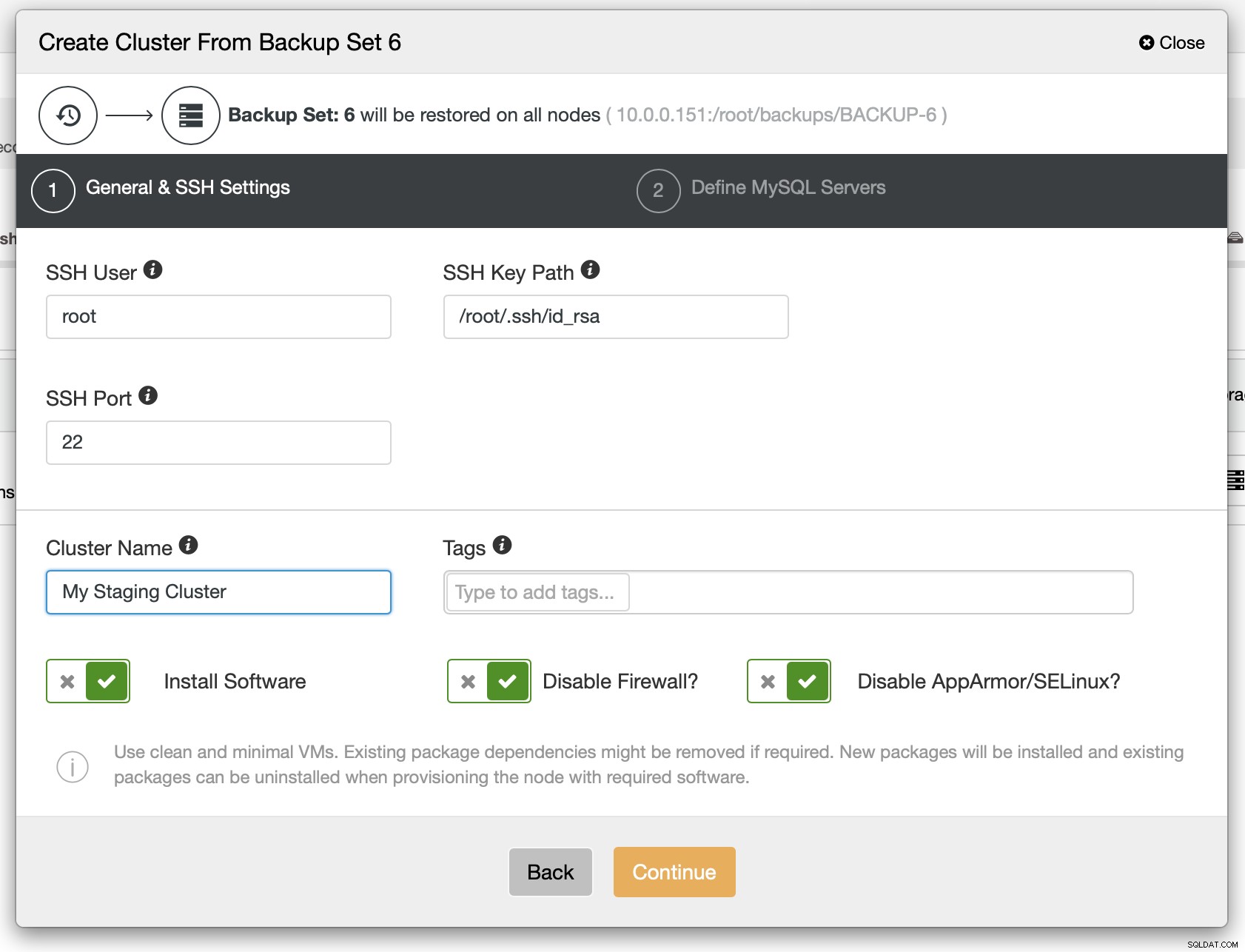
Jako další krok byste měli definovat konektivitu SSH – musí být na svém místě, než bude moci ClusterControl nasadit uzly.
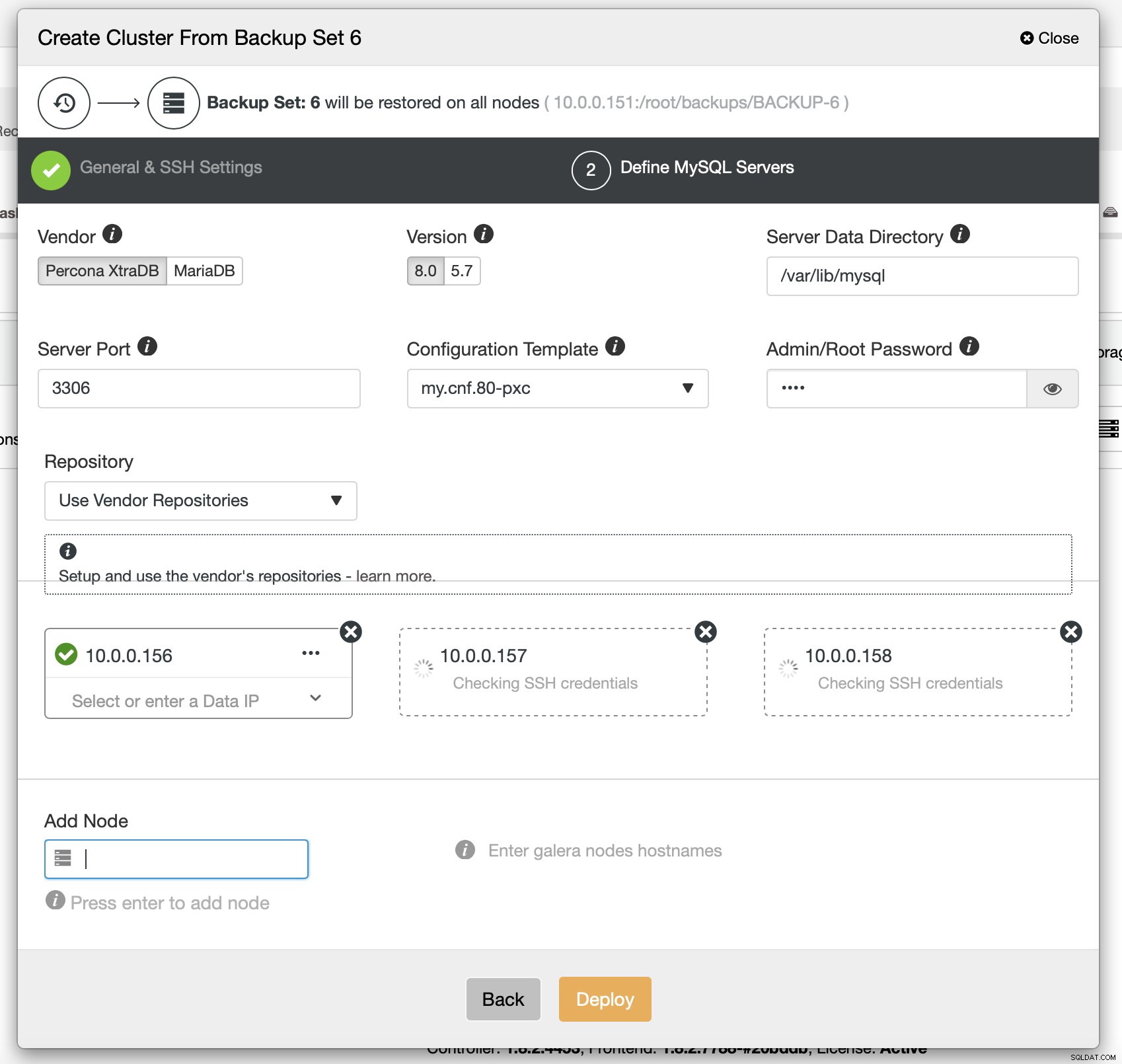
Nakonec musíte vybrat (mimo jiné) dodavatele, verzi a názvy hostitelů uzlů, které chcete v clusteru použít. To je právě to.
Příkaz CLI, který by provedl totéž, vypadá takto:
s9s cluster --create --cluster-type=galera --nodes="10.0.0.156;10.0.0.157;10.0.0.158" --vendor=percona --cluster-name=PXC --provider-version=8.0 --os-user=root --os-key-file=/root/.ssh/id_rsa --backup-id=6Konfigurace ProxySQL pro zrcadlení provozu
Pokud máme nasazený klastr, můžeme do něj chtít odeslat produkční provoz, abychom ověřili, jak nové schéma zachází se stávajícím provozem. Jedním ze způsobů, jak toho dosáhnout, je použití ProxySQL.
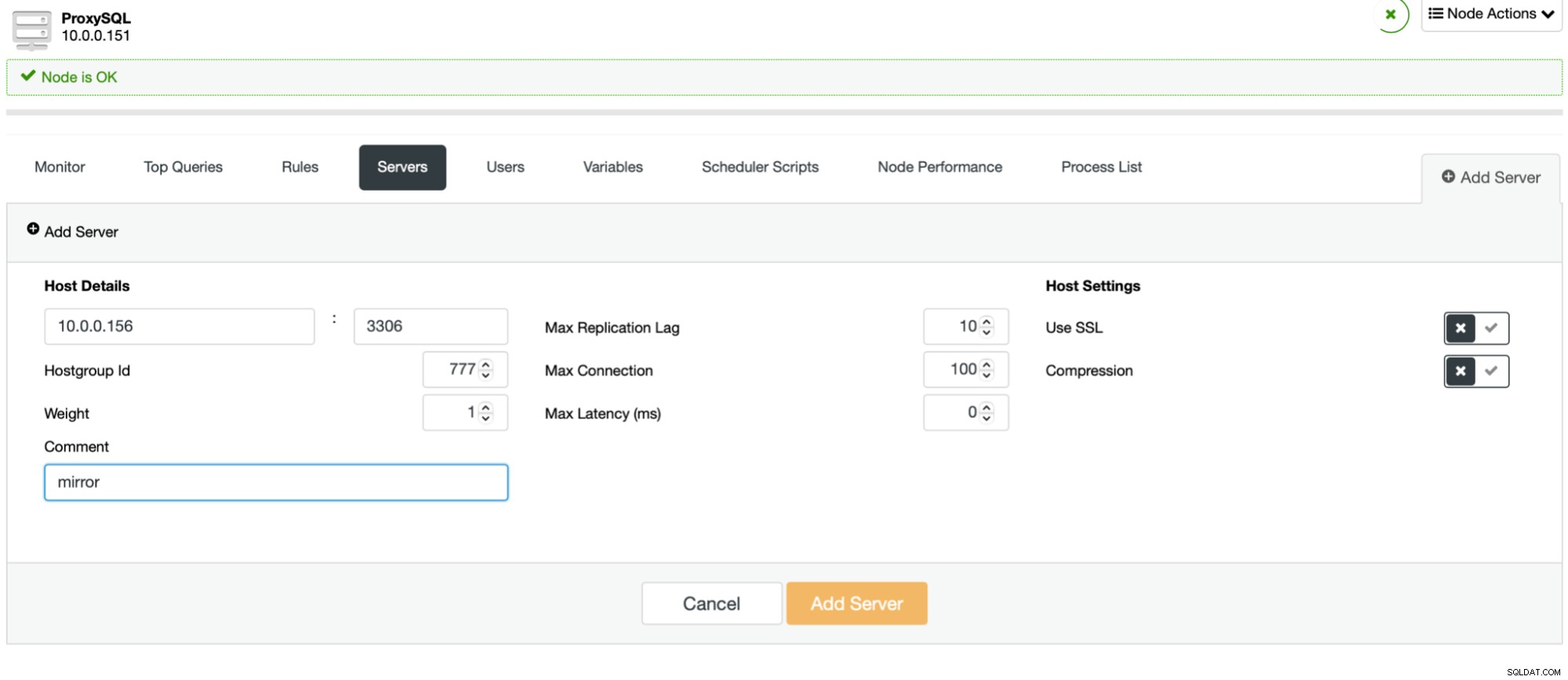
Postup je snadný. Nejprve byste měli přidat uzly do ProxySQL. Měly by patřit do samostatné hostitelské skupiny, která se zatím nepoužívá. Ujistěte se, že uživatel monitoru ProxySQL k nim bude mít přístup.
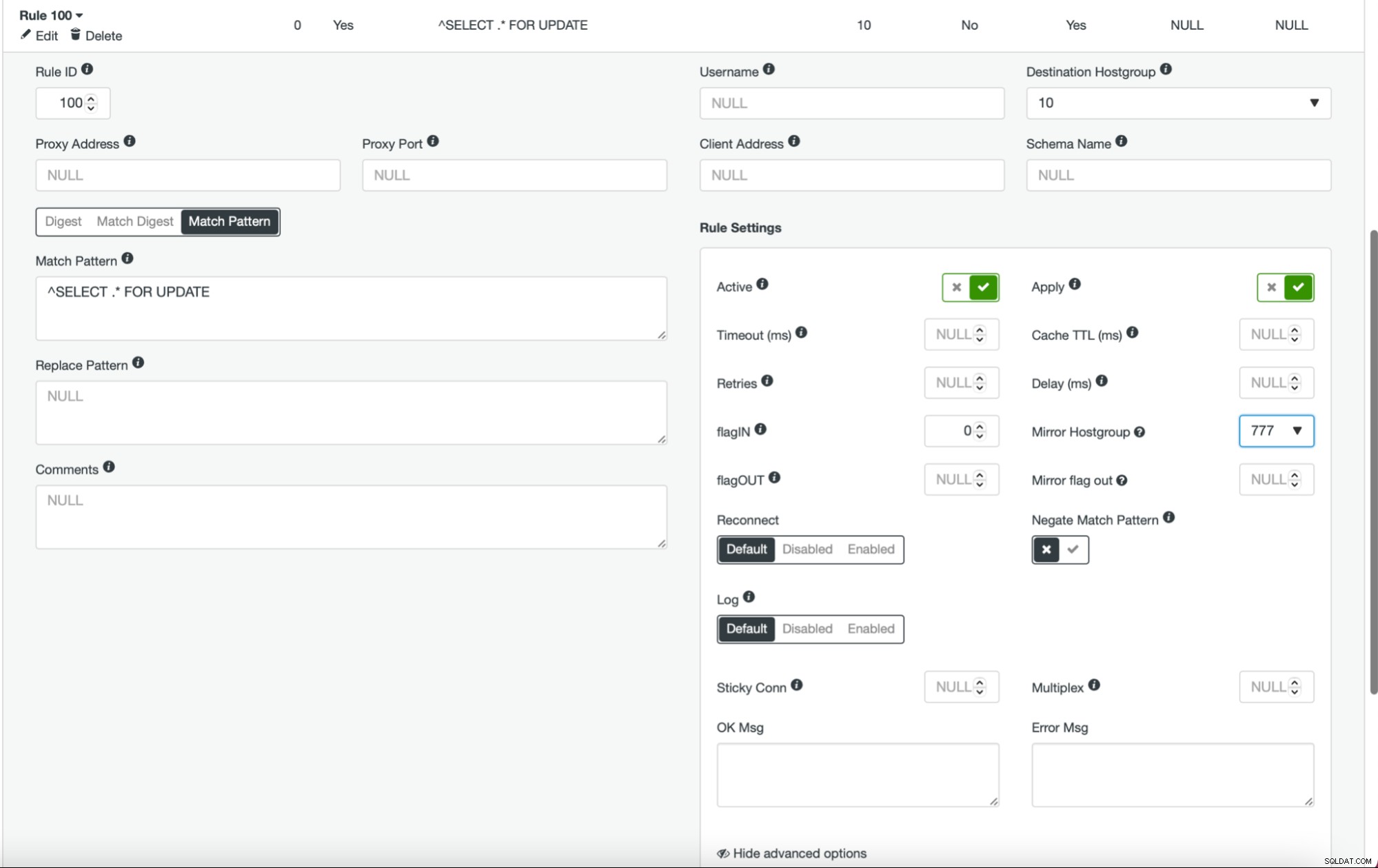
Jakmile to uděláte a budete mít všechny (nebo některé) své uzly nakonfigurovány v hostitelské skupině, můžete upravit pravidla dotazů a definovat zrcadlovou hostitelskou skupinu (je dostupná v rozšířených možnostech). Pokud to chcete udělat pro veškerý provoz, pravděpodobně budete chtít tímto způsobem upravit všechna pravidla dotazu. Pokud chcete zrcadlit pouze SELECT dotazy, měli byste upravit příslušná pravidla dotazů. Poté by měl váš pracovní cluster začít přijímat produkční provoz.
Nasazení clusteru jako slave
Jak jsme si řekli dříve, alternativním řešením by bylo vytvořit nový cluster, který bude fungovat jako replika stávajícího nastavení. S takovým přístupem můžeme nechat všechny zápisy testovat automaticky pomocí replikace. SELECTy lze testovat pomocí přístupu, který jsme popsali výše – zrcadlení přes ProxySQL.
Nasazení slave clusteru je docela jednoduché.
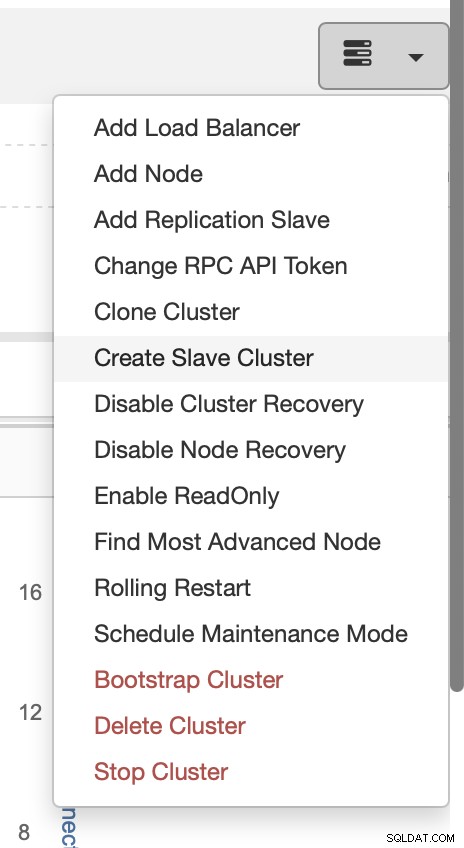
Vyberte úlohu Create Slave Cluster.
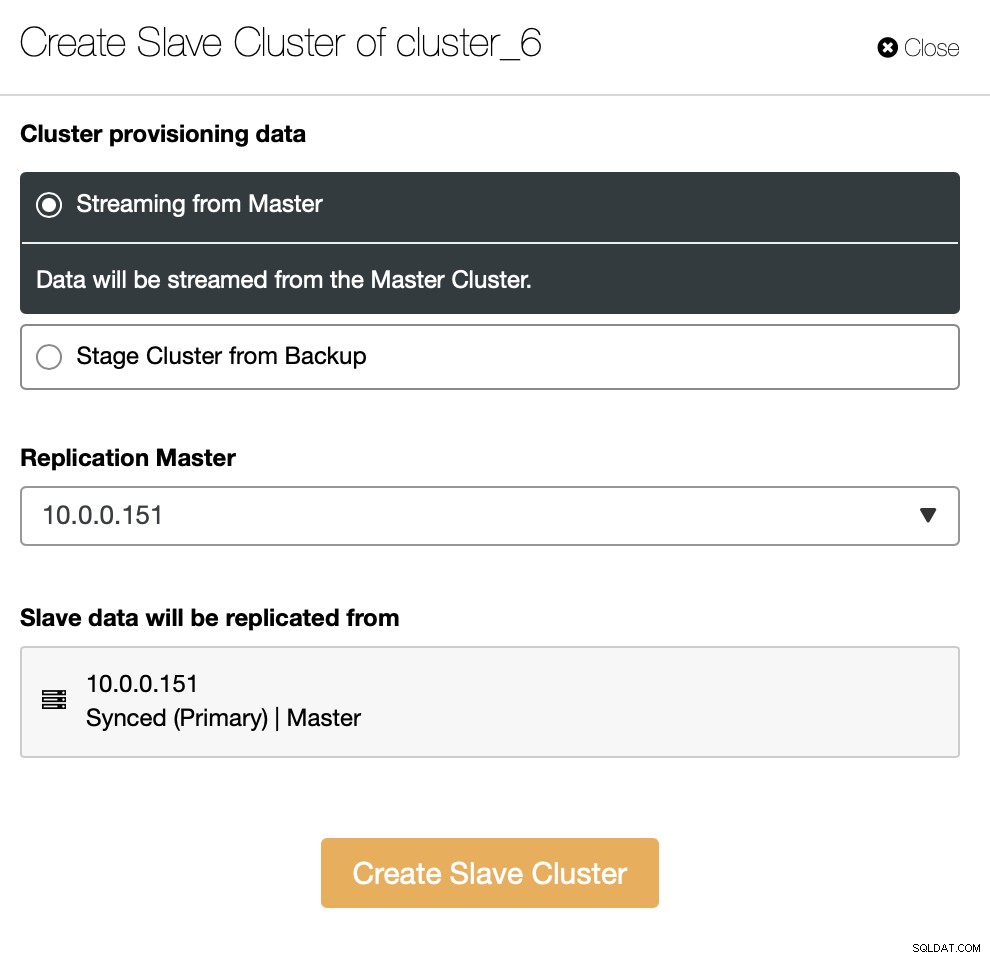
Musíte se rozhodnout, jak chcete mít nastavenou replikaci. Můžete si nechat přenést všechna data z masteru do nových uzlů.
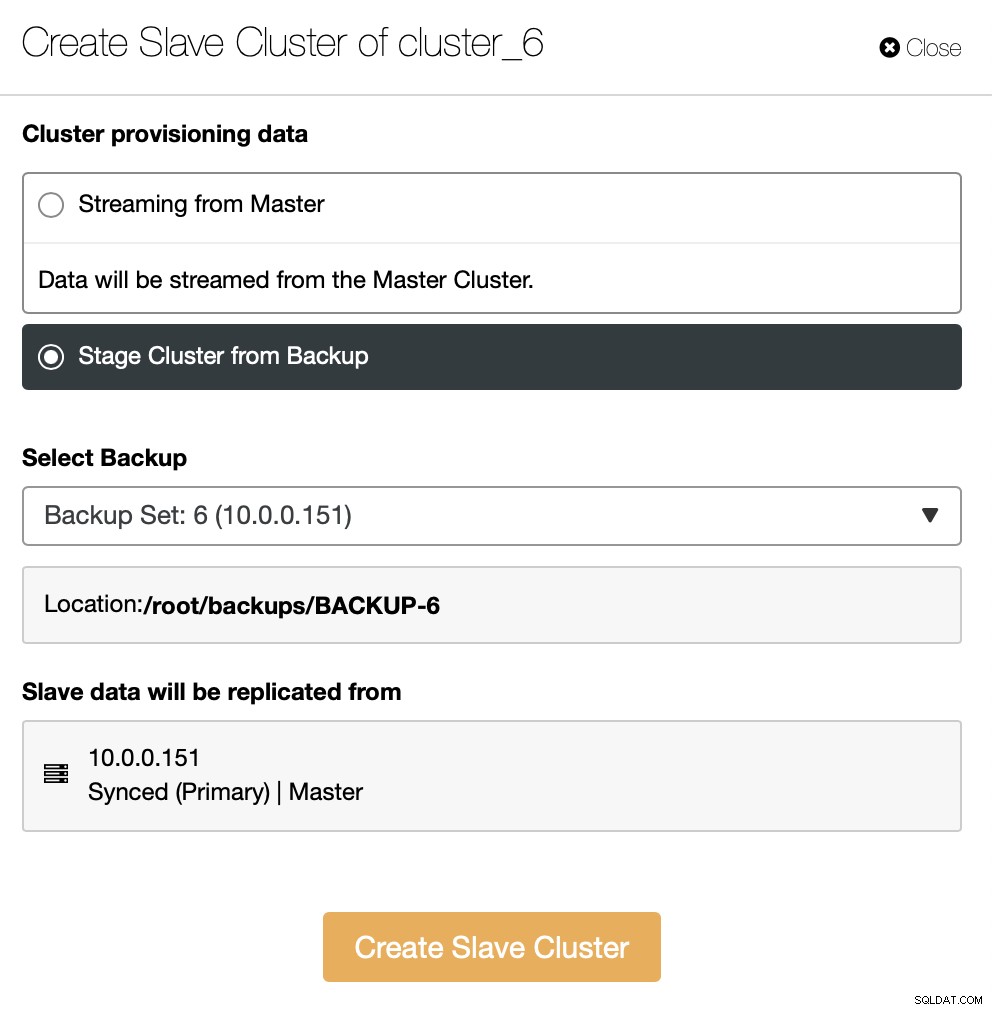
Alternativně můžete k vytvoření nového clusteru použít stávající zálohu. To pomůže snížit zátěž na hlavním uzlu – namísto přenosu všech dat bude nutné přenést pouze transakce, které byly provedeny mezi vytvořením zálohy a okamžikem nastavení replikace.
Zbytek je následovat standardního průvodce nasazením, který definuje připojení SSH, verzi, dodavatele, hostitele a tak dále. Jakmile je nasazen, uvidíte cluster v seznamu.
Alternativním řešením uživatelského rozhraní je to provést prostřednictvím RPC.
{
"command": "create_cluster",
"job_data": {
"cluster_name": "",
"cluster_type": "galera",
"company_id": null,
"config_template": "my.cnf.80-pxc",
"data_center": 0,
"datadir": "/var/lib/mysql",
"db_password": "pass",
"db_user": "root",
"disable_firewall": true,
"disable_selinux": true,
"enable_mysql_uninstall": true,
"generate_token": true,
"install_software": true,
"port": "3306",
"remote_cluster_id": 6,
"software_package": "",
"ssh_keyfile": "/root/.ssh/id_rsa",
"ssh_port": "22",
"ssh_user": "root",
"sudo_password": "",
"type": "mysql",
"user_id": 5,
"vendor": "percona",
"version": "8.0",
"nodes": [
{
"hostname": "10.0.0.155",
"hostname_data": "10.0.0.155",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.159",
"hostname_data": "10.0.0.159",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.160",
"hostname_data": "10.0.0.160",
"hostname_internal": "",
"port": "3306"
}
],
"with_tags": []
}
}Posun vpřed
Pokud se chcete dozvědět více o způsobech, jak můžete integrovat své procesy s ClusterControl, rádi bychom vás odkázali na dokumentaci, kde máme celou sekci o vývoji řešení, kde ClusterControl hraje roli významnou roli:
https://docs.severalnines.com/docs/clustercontrol/developer-guide/cmon-rpc/
https://docs.severalnines.com/docs/clustercontrol/user-guide-cli/
Doufáme, že pro vás byl tento krátký blog informativní a užitečný. Máte-li jakékoli dotazy týkající se integrace ClusterControl do vašeho prostředí, kontaktujte nás a my se pokusíme vám pomoci.