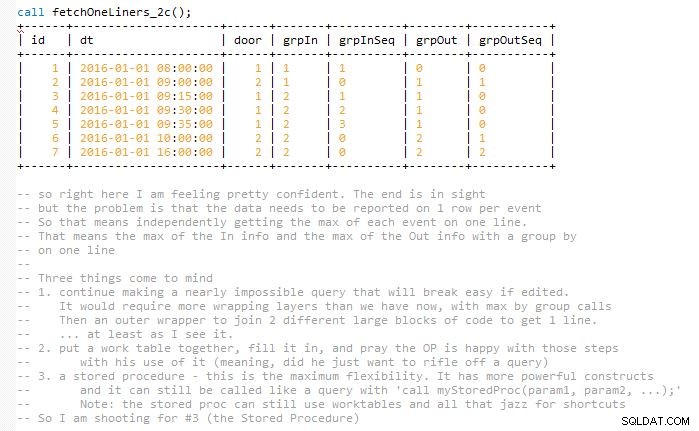
To usiluje o to, aby bylo řešení snadno udržovatelné bez dokončení konečného dotazu najednou, což by téměř zdvojnásobilo jeho velikost (podle mého názoru). Je to proto, že výsledky se musí shodovat a reprezentovat na jednom řádku s odpovídajícími událostmi In a Out. Takže nakonec používám několik pracovních stolů. Je implementován v uložené proceduře.
Uložená procedura používá několik proměnných, které jsou přeneseny pomocí cross join . Přemýšlejte o křížovém spojení pouze jako o mechanismu pro inicializaci proměnných. Proměnné jsou udržovány bezpečně, takže věřím, v duchu tohoto dokument
často odkazované v proměnných dotazech. Důležitými částmi reference je bezpečná manipulace s proměnnými na řádku, vynucené jejich nastavení dříve, než je používají jiné sloupce. Toho je dosaženo pomocí greatest() a least() funkce, které mají vyšší prioritu než proměnné nastavené bez použití těchto funkcí. Všimněte si také, že coalesce() se často používá ke stejnému účelu. Pokud se jejich použití zdá podivné, jako například vzít největší z čísel, o kterých je známo, že je větší než 0 nebo 0, je to záměrné. Záměrně vynutit pořadí priorit nastavených proměnných.
Sloupce v dotazu pojmenovaly věci jako dummy2 atd. jsou sloupce, jejichž výstup nebyl použit, ale byly použity k nastavení proměnných uvnitř, řekněme, greatest() nebo jiný. To bylo zmíněno výše. Výstup jako 7777 byl zástupný symbol ve 3. slotu, protože pro if() byla potřeba nějaká hodnota to bylo použito. Takže to všechno ignorujte.
Zahrnul jsem několik snímků obrazovky kódu, jak postupoval vrstvu po vrstvě, abych vám pomohl vizualizovat výstup. A jak se tyto iterace vývoje pomalu skládají do další fáze, aby se rozšířily na předchozí.
Jsem si jistý, že moji kolegové by to mohli zlepšit jedním dotazem. Mohl jsem to tak dokončit. Ale věřím, že by to vedlo k matoucímu nepořádku, který by se při dotyku rozbil.
Schéma:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Uložená procedura:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Test:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
Toto je konec odpovědi. Níže je pro vývojáře vizualizace kroků, které vedly k dokončení uložené procedury.
Verze vývoje, které vedly až do konce. Doufejme, že to pomůže při vizualizaci, na rozdíl od pouhého vypuštění středně velkého matoucího kusu kódu.
Krok A
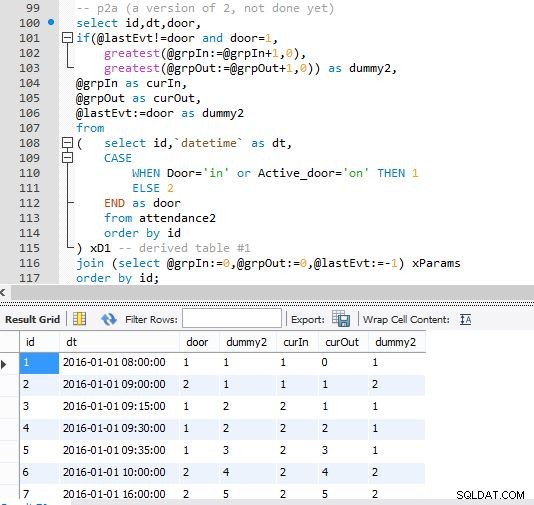
Krok B
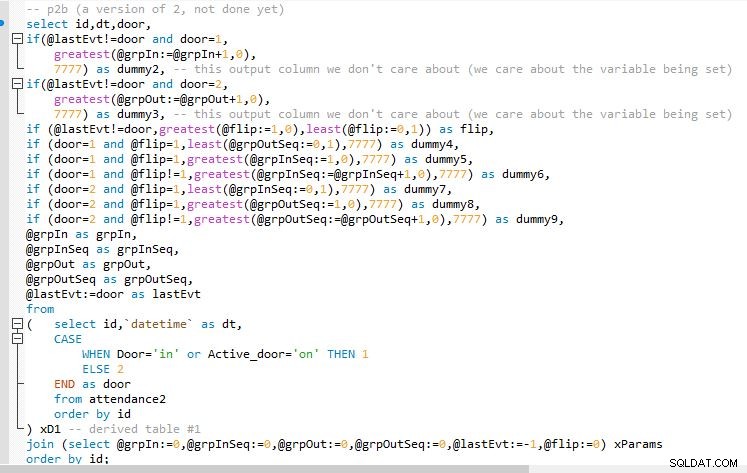
Výstup v kroku B

Krok C
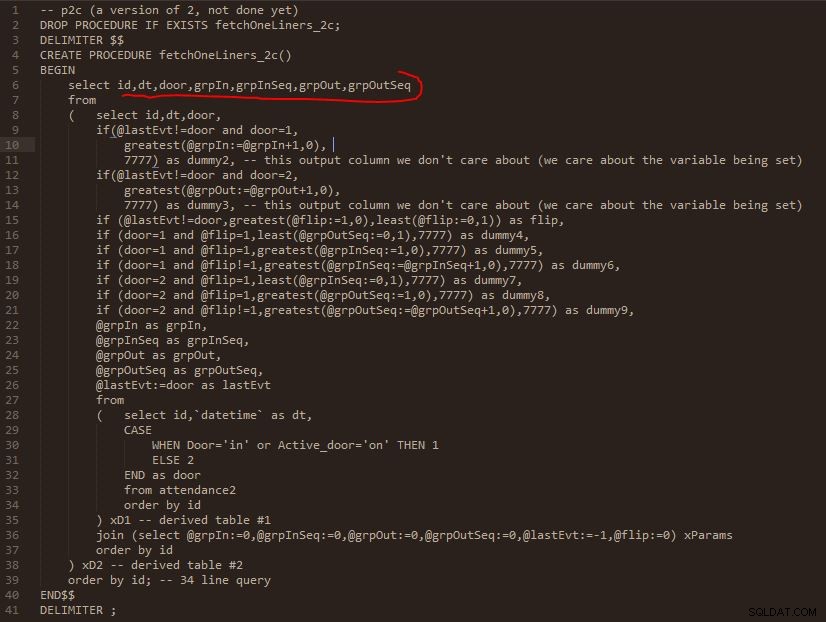
Výstup v kroku C