Zde je návod, jak budou tyto dva přístupy fyzicky reprezentovány v databázi:
Pojďme analyzovat oba přístupy...
Přiblížení 1 (oba směry uložené v tabulce):
- PRO:Jednodušší dotazy.
- CON:Data mohou být poškozena vložením/aktualizací/vymazáním pouze jedním směrem.
- MINOR PRO:Nevyžaduje další omezení, aby se zajistilo, že přátelství nebude možné duplikovat.
- Je třeba provést další analýzu:
- TIE:Jeden index obálky oběma směry, takže nepotřebujete sekundární index.
- TIE:Požadavky na úložiště.
- TIE:Výkon.
Přiblížení 2 (v tabulce je uložen pouze jeden směr):
- CON:Složitější dotazy.
- PRO:Nelze poškodit data tím, že zapomenete zpracovat opačný směr, protože neexistuje žádný opačný směr .
- MINOR CON:Vyžaduje
CHECK(UID < FriendID), takže stejné přátelství nemůže být nikdy reprezentováno dvěma různými způsoby a klíč na(UID, FriendID)může dělat svou práci. - Je třeba provést další analýzu:
- TIE:K pokrytí
jsou nutné dva indexy oba směry dotazování (složený index na
{UID, FriendID}a složený index na{FriendID, UID}). - TIE:Požadavky na úložiště.
- TIE:Výkon.
- TIE:K pokrytí
jsou nutné dva indexy oba směry dotazování (složený index na
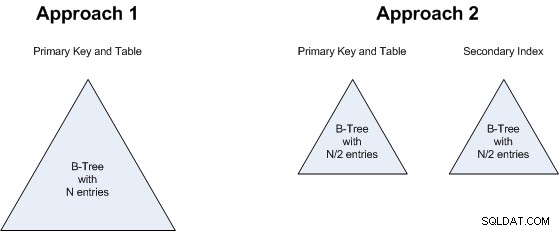
Bod 1 je zvláštní zájem. MySQL/InnoDB vždy klastry data a sekundární indexy mohou být v klastrovaných tabulkách drahé (viz „Nevýhody klastrování“ v tento článek ), takže by se mohlo zdát, že sekundární index v přístupu 2 pohltí všechny výhody menšího počtu řádků. Nicméně , sekundární index obsahuje přesně stejná pole jako primární (pouze v opačném pořadí), takže v tomto konkrétním případě nevzniká žádná režie úložiště. Neexistuje také žádný ukazatel na haldu tabulky (protože neexistuje halda tabulky), takže je pravděpodobně ještě levnější z hlediska úložiště než normální index založený na haldě. A za předpokladu, že je dotaz pokryt indexem, nebude ani v klastrované tabulce normálně spojeno se sekundárním indexem dvojité vyhledávání. Takže toto je v podstatě nerozhodný výsledek (ani přístup 1, ani přístup 2 nemají významnou výhodu).
Bod 2 souvisí s bodem 1:je jedno, zda budeme mít B-strom N hodnot nebo dva B-stromy, každý s N/2 hodnotami. Takže to je také nerozhodné:oba přístupy zaberou přibližně stejné množství úložiště.
Stejná úvaha platí pro bod 3 :zda hledáme jeden větší B-strom nebo 2 menší, není velký rozdíl, takže je to také nerozhodné.
Takže kvůli robustnosti a navzdory poněkud ošklivějším dotazům a potřebě dalšího CHECK , zvolil bych přístup 2.