Nejprve se musíte rozhodnout, zda chcete udržovat trvalé připojení k MySQL. Ten funguje lépe, ale potřebuje trochu údržby.
Výchozí wait_timeout
v MySQL je 8 hodin. Kdykoli je připojení nečinné déle než wait_timeout je zavřeno. Při restartování serveru MySQL se také zavře všechna navázaná připojení. Pokud tedy používáte trvalé připojení, musíte před použitím připojení zkontrolovat, zda je aktivní (a pokud ne, znovu se připojte). Pokud používáte připojení na žádost, nemusíte udržovat stav připojení, protože připojení jsou vždy nová.
Připojení na žádost
Netrvalé připojení k databázi má zjevnou režii na otevření připojení, handshaking atd. (pro databázový server i klienta) na každý příchozí požadavek HTTP.
Zde je citát z oficiálního tutoriálu Flask ohledně připojení k databázi :
Všimněte si však, že kontext aplikace je inicializováno na žádost (což je trochu zahaleno obavami o efektivitu a Flaskovým žarlem). A tak je to stále velmi neefektivní. Mělo by to však vyřešit váš problém. Zde je zkrácený úryvek toho, co navrhuje při použití na pymysql :
import pymysql
from flask import Flask, g, request
app = Flask(__name__)
def connect_db():
return pymysql.connect(
user = 'guest', password = '', database = 'sakila',
autocommit = True, charset = 'utf8mb4',
cursorclass = pymysql.cursors.DictCursor)
def get_db():
'''Opens a new database connection per request.'''
if not hasattr(g, 'db'):
g.db = connect_db()
return g.db
@app.teardown_appcontext
def close_db(error):
'''Closes the database connection at the end of request.'''
if hasattr(g, 'db'):
g.db.close()
@app.route('/')
def hello_world():
city = request.args.get('city')
cursor = get_db().cursor()
cursor.execute('SELECT city_id FROM city WHERE city = %s', city)
row = cursor.fetchone()
if row:
return 'City "{}" is #{:d}'.format(city, row['city_id'])
else:
return 'City "{}" not found'.format(city)
Trvalé připojení
Pro trvalé připojení k databázi existují dvě hlavní možnosti. Buď máte fond připojení, nebo mapujete připojení k pracovním procesům. Vzhledem k tomu, že aplikace Flask WSGI jsou normálně obsluhovány vláknovými servery s pevným počtem vláken (např. uWSGI), je mapování vláken jednodušší a stejně efektivní.
Existuje balíček, DBUtils
, která implementuje obojí, a PersistentDB
pro připojení s mapou vláken.
Jednou z důležitých výhrad při udržování trvalého připojení jsou transakce. API pro opětovné připojení je ping
. Je to bezpečné pro automatické zadávání jednotlivých příkazů, ale mezi transakcemi to může rušit (trochu více podrobností zde
). DBUtils se o to postará a měl by se znovu připojit pouze na dbapi.OperationalError a dbapi.InternalError (ve výchozím nastavení řízeno failures k inicializátoru PersistentDB ) vzniklé mimo transakci.
Zde je návod, jak bude výše uvedený úryvek vypadat s PersistentDB .
import pymysql
from flask import Flask, g, request
from DBUtils.PersistentDB import PersistentDB
app = Flask(__name__)
def connect_db():
return PersistentDB(
creator = pymysql, # the rest keyword arguments belong to pymysql
user = 'guest', password = '', database = 'sakila',
autocommit = True, charset = 'utf8mb4',
cursorclass = pymysql.cursors.DictCursor)
def get_db():
'''Opens a new database connection per app.'''
if not hasattr(app, 'db'):
app.db = connect_db()
return app.db.connection()
@app.route('/')
def hello_world():
city = request.args.get('city')
cursor = get_db().cursor()
cursor.execute('SELECT city_id FROM city WHERE city = %s', city)
row = cursor.fetchone()
if row:
return 'City "{}" is #{:d}'.format(city, row['city_id'])
else:
return 'City "{}" not found'.format(city)
Mikro-benchmark
Abychom vám trochu napověděli, jaké dopady na výkon jsou v číslech, zde je mikro-benchmark.
Běžel jsem:
uwsgi --http :5000 --wsgi-file app_persistent.py --callable app --master --processes 1 --threads 16uwsgi --http :5000 --wsgi-file app_per_req.py --callable app --master --processes 1 --threads 16
A otestoval je se souběžností 1, 4, 8, 16 přes:
siege -b -t 15s -c 16 https://localhost:5000/?city=london
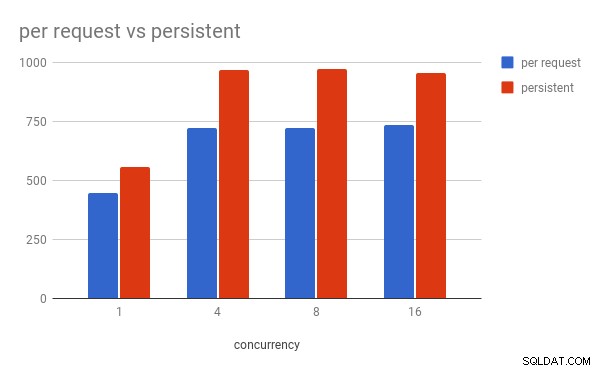
Pozorování (pro moji místní konfiguraci):
- Trvalé připojení je o ~30 % rychlejší
- Na souběžnosti 4 a vyšší má pracovní proces uWSGI vrchol s využitím více než 100 % CPU (
pymysqlmusí analyzovat protokol MySQL v čistém Pythonu, což je úzké hrdlo), - U souběžnosti 16
mysqldVyužití CPU je ~55 % pro každý požadavek a ~45 % pro trvalé připojení.