Chtěli jsme naskočit s možností vyřešit svůj úkol pomocí čistého BigQuery (standardní SQL)
Předpoklady / předpoklady :zdrojová data jsou v sandbox.temp.id1_id2_pairs
Měli byste to nahradit svým vlastním, nebo pokud chcete testovat s fiktivními daty z vaší otázky – můžete vytvořit tuto tabulku, jak je uvedeno níže (samozřejmě nahraďte sandbox.temp s vaší vlastní project.dataset )
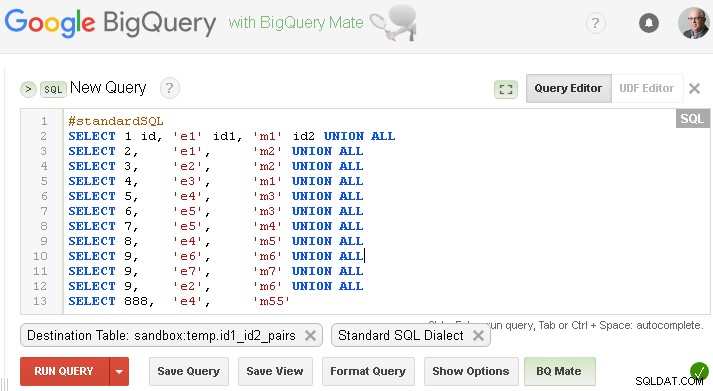
Ujistěte se, že jste nastavili příslušnou cílovou tabulku
Poznámka :všechny příslušné dotazy (jako text) najdete v dolní části této odpovědi, ale prozatím svou odpověď ilustruji snímky obrazovky - takže je uvedeno vše - dotaz, výsledek a použité možnosti
Budou to tedy tři kroky:
Krok 1 – Inicializace
Zde pouze provedeme počáteční seskupení id1 na základě spojení s id2:

Jak můžete vidět zde - vytvořili jsme seznam všech hodnot id1 s příslušnými připojeními na základě jednoduchého jednoúrovňového připojení přes id2
Výstupní tabulka je sandbox.temp.groups
Krok 2 – Seskupování iterací
V každé iteraci obohatíme seskupování na základě již vytvořených skupin.
Zdrojem dotazu je výstupní tabulka z předchozího kroku (sandbox.temp.groups ) a Cíl je stejná tabulka (sandbox.temp.groups ) pomocí Přepsat
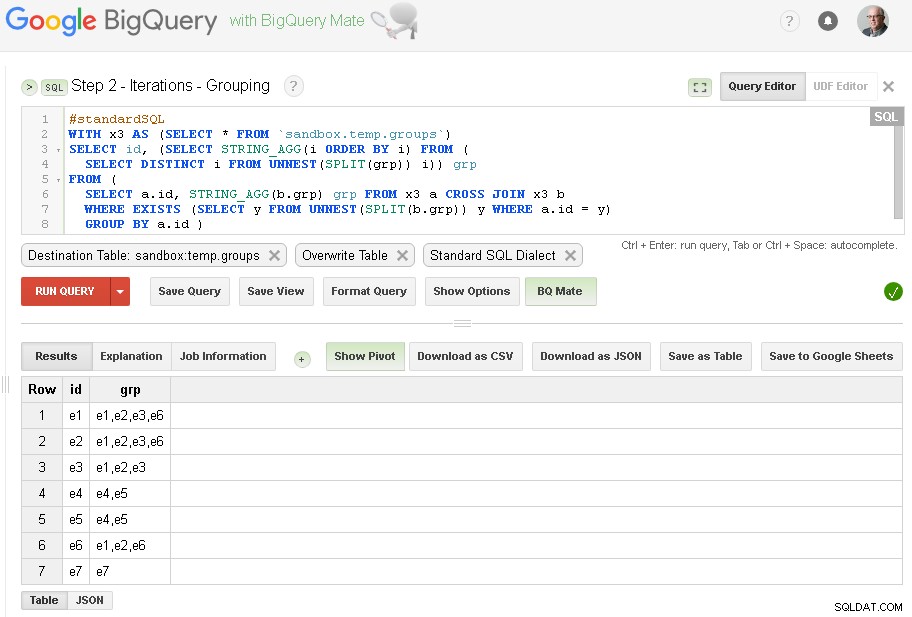
V iteracích budeme pokračovat, dokud počet nalezených skupin nebude stejný jako v předchozí iteraci
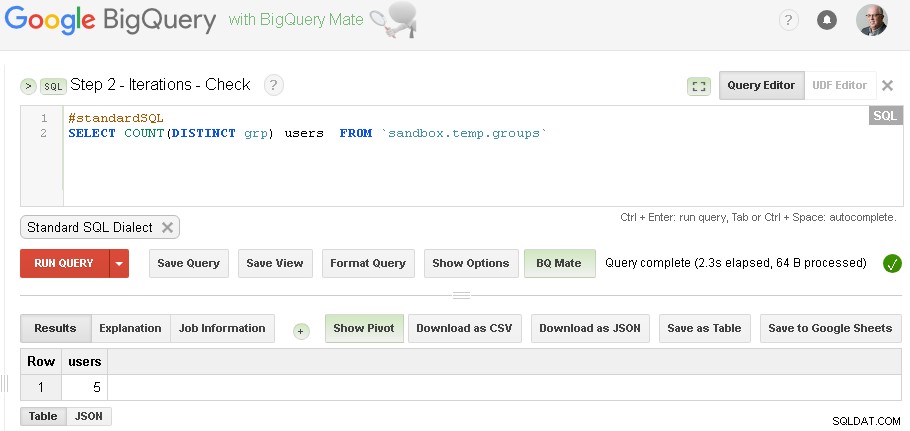
Poznámka :stačí mít otevřené dvě karty webového uživatelského rozhraní BigQuery (jak je znázorněno výše) a beze změny kódu spustit seskupení a poté znovu a znovu zkontrolovat, dokud se iterace nesblíží
(pro konkrétní data, která jsem použil v sekci pre-rekvizity – měl jsem tři iterace – první iterace vyprodukovala 5 uživatelů, druhá iterace vyprodukovala 3 uživatele a třetí iterace vytvořila opět 3 uživatele – což znamenalo, že jsme s iteracemi skončili.
Samozřejmě, v reálném případě - počet iterací může být více než jen tři - takže potřebujeme nějaký druh automatizace (viz příslušná část ve spodní části odpovědi).
Krok 3 – Konečné seskupení
Když je seskupení id1 dokončeno - můžeme přidat konečné seskupení pro id2
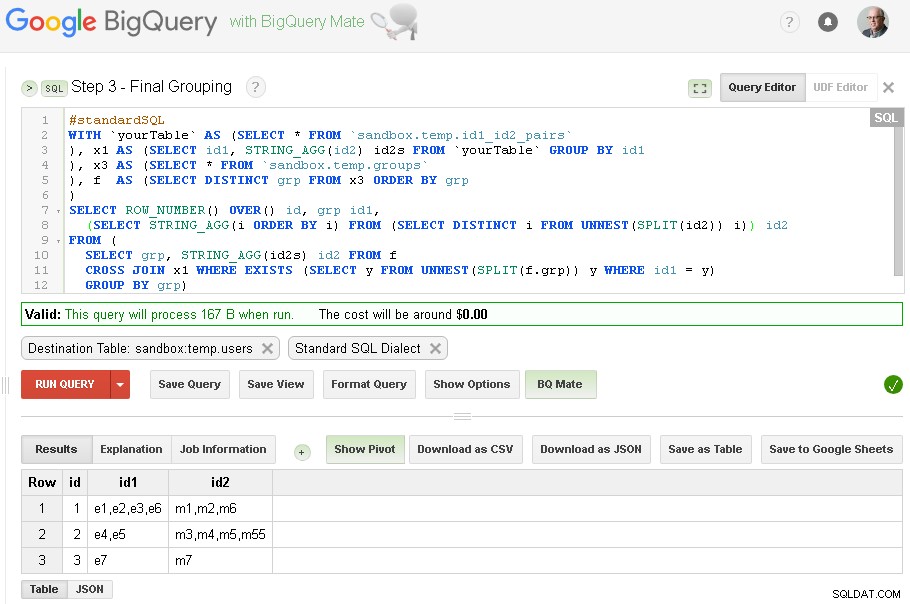
Konečný výsledek je nyní v sandbox.temp.users tabulka
Použité dotazy (nezapomeňte nastavit příslušné cílové tabulky a přepsání v případě potřeby podle výše popsané logiky a snímků obrazovky):
Předpoklady:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Krok 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Krok 2 – Seskupování
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Krok 2 – Zkontrolujte
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Krok 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Automatizace :
Samozřejmě výše uvedený "proces" lze provést ručně v případě, že se iterace rychle sbíhají - takže skončíte s 10-20 spuštěními. Ale v reálnějších případech to můžete snadno automatizovat s jakýmkoli klientem
dle vašeho výběru