Směrování jarních transakcí
Nejprve vytvoříme DataSourceType Java Enum, které definuje naše možnosti směrování transakcí:
public enum DataSourceType {
READ_WRITE,
READ_ONLY
}
Abychom směrovali transakce pro čtení a zápis do primárního uzlu a transakce pouze pro čtení do uzlu Replica, můžeme definovat ReadWriteDataSource který se připojuje k primárnímu uzlu a ReadOnlyDataSource které se připojují k uzlu Replica.
Směrování transakcí pro čtení, zápis a pouze pro čtení provádí Spring AbstractRoutingDataSource abstrakce, kterou implementuje TransactionRoutingDatasource , jak je znázorněno na následujícím obrázku:
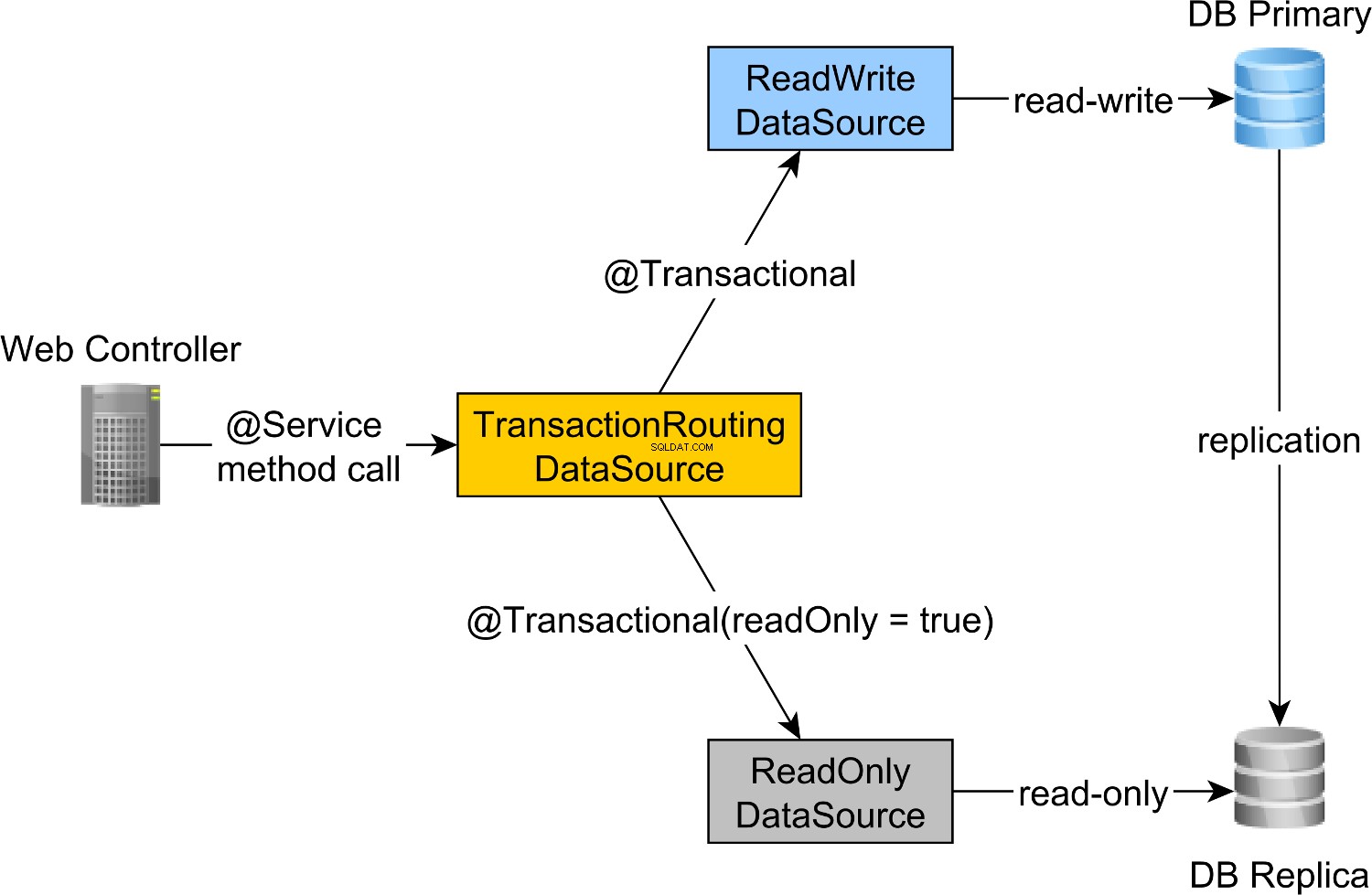
TransactionRoutingDataSource se velmi snadno implementuje a vypadá následovně:
public class TransactionRoutingDataSource
extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager
.isCurrentTransactionReadOnly() ?
DataSourceType.READ_ONLY :
DataSourceType.READ_WRITE;
}
}
V podstatě kontrolujeme Spring TransactionSynchronizationManager třída, která ukládá aktuální transakční kontext, aby zkontrolovala, zda je aktuálně spuštěná transakce Spring pouze pro čtení nebo ne.
determineCurrentLookupKey metoda vrací hodnotu diskriminátoru, která bude použita k výběru JDBC pro čtení i zápis nebo pouze pro čtení DataSource .
Jarní konfigurace JDBC DataSource pro čtení i zápis a pouze pro čtení
DataSource konfigurace vypadá následovně:
@Configuration
@ComponentScan(
basePackages = "com.vladmihalcea.book.hpjp.util.spring.routing"
)
@PropertySource(
"/META-INF/jdbc-postgresql-replication.properties"
)
public class TransactionRoutingConfiguration
extends AbstractJPAConfiguration {
@Value("${jdbc.url.primary}")
private String primaryUrl;
@Value("${jdbc.url.replica}")
private String replicaUrl;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Bean
public DataSource readWriteDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(primaryUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public DataSource readOnlyDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(replicaUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public TransactionRoutingDataSource actualDataSource() {
TransactionRoutingDataSource routingDataSource =
new TransactionRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(
DataSourceType.READ_WRITE,
readWriteDataSource()
);
dataSourceMap.put(
DataSourceType.READ_ONLY,
readOnlyDataSource()
);
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
@Override
protected Properties additionalProperties() {
Properties properties = super.additionalProperties();
properties.setProperty(
"hibernate.connection.provider_disables_autocommit",
Boolean.TRUE.toString()
);
return properties;
}
@Override
protected String[] packagesToScan() {
return new String[]{
"com.vladmihalcea.book.hpjp.hibernate.transaction.forum"
};
}
@Override
protected String databaseType() {
return Database.POSTGRESQL.name().toLowerCase();
}
protected HikariConfig hikariConfig(
DataSource dataSource) {
HikariConfig hikariConfig = new HikariConfig();
int cpuCores = Runtime.getRuntime().availableProcessors();
hikariConfig.setMaximumPoolSize(cpuCores * 4);
hikariConfig.setDataSource(dataSource);
hikariConfig.setAutoCommit(false);
return hikariConfig;
}
protected HikariDataSource connectionPoolDataSource(
DataSource dataSource) {
return new HikariDataSource(hikariConfig(dataSource));
}
}
/META-INF/jdbc-postgresql-replication.properties zdrojový soubor poskytuje konfiguraci pro čtení, zápis a pouze pro čtení JDBC DataSource komponenty:
hibernate.dialect=org.hibernate.dialect.PostgreSQL10Dialect
jdbc.url.primary=jdbc:postgresql://localhost:5432/high_performance_java_persistence
jdbc.url.replica=jdbc:postgresql://localhost:5432/high_performance_java_persistence_replica
jdbc.username=postgres
jdbc.password=admin
jdbc.url.primary vlastnost definuje adresu URL primárního uzlu, zatímco jdbc.url.replica definuje adresu URL uzlu Replica.
readWriteDataSource Komponenta Spring definuje DataSource JDBC pro čtení a zápis zatímco readOnlyDataSource komponenta definuje JDBC DataSource pouze pro čtení .
Všimněte si, že zdroje dat pro čtení i zápis i pouze pro čtení používají HikariCP pro sdružování připojení.
actualDataSource funguje jako fasáda pro zdroje dat pro čtení, zápis a pouze pro čtení a je implementována pomocí TransactionRoutingDataSource utility.
readWriteDataSource je registrován pomocí DataSourceType.READ_WRITE klíč a readOnlyDataSource pomocí DataSourceType.READ_ONLY klíč.
Takže při provádění čtení a zápisu @Transactional metoda readWriteDataSource bude použito při provádění @Transactional(readOnly = true) metoda readOnlyDataSource bude místo toho použito.
Všimněte si, že
additionalPropertiesmetoda definujehibernate.connection.provider_disables_autocommitVlastnost Hibernate, kterou jsem přidal do Hibernate, abych odložil pořízení databáze pro transakce RESOURCE_LOCAL JPA.Nejen, že
hibernate.connection.provider_disables_autocommitumožňuje lépe využívat databázová připojení, ale je to jediný způsob, jak můžeme tento příklad zprovoznit, protože bez této konfigurace je připojení získáno před volánímdetermineCurrentLookupKeymetodaTransactionRoutingDataSource.
Zbývající komponenty Spring potřebné pro vytvoření JPA EntityManagerFactory jsou definovány AbstractJPAConfiguration základní třída.
V podstatě actualDataSource je dále zabaleno pomocí DataSource-Proxy a poskytnuto JPA EntityManagerFactory . Další podrobnosti si můžete prohlédnout ve zdrojovém kódu na GitHubu.
Doba testování
Abychom zkontrolovali, zda transakční směrování funguje, povolíme protokol dotazů PostgreSQL nastavením následujících vlastností v postgresql.conf konfigurační soubor:
log_min_duration_statement = 0
log_line_prefix = '[%d] '
log_min_duration_statement nastavení vlastnosti je pro protokolování všech příkazů PostgreSQL, zatímco druhé přidává název databáze do protokolu SQL.
Takže při volání newPost a findAllPostsByTitle metody, jako je tento:
Post post = forumService.newPost(
"High-Performance Java Persistence",
"JDBC", "JPA", "Hibernate"
);
List<Post> posts = forumService.findAllPostsByTitle(
"High-Performance Java Persistence"
);
Vidíme, že PostgreSQL zaznamenává následující zprávy:
[high_performance_java_persistence] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'JDBC', $2 = 'JPA', $3 = 'Hibernate'
[high_performance_java_persistence] LOG: execute <unnamed>:
select tag0_.id as id1_4_, tag0_.name as name2_4_
from tag tag0_ where tag0_.name in ($1 , $2 , $3)
[high_performance_java_persistence] LOG: execute <unnamed>:
select nextval ('hibernate_sequence')
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'High-Performance Java Persistence', $2 = '4'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post (title, id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '1'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '2'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '3'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] LOG: execute S_3:
COMMIT
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence_replica] DETAIL:
parameters: $1 = 'High-Performance Java Persistence'
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
select post0_.id as id1_0_, post0_.title as title2_0_
from post post0_ where post0_.title=$1
[high_performance_java_persistence_replica] LOG: execute S_1:
COMMIT
Prohlášení protokolu pomocí high_performance_java_persistence prefix byly provedeny na primárním uzlu, zatímco ty používající high_performance_java_persistence_replica na uzlu Replica.
Takže všechno funguje jako kouzlo!
Veškerý zdrojový kód lze nalézt v mém High-Performance Java Persistence GitHub úložišti, takže si ho můžete také vyzkoušet.
Závěr
Musíte se ujistit, že jste nastavili správnou velikost pro své fondy připojení, protože to může znamenat obrovský rozdíl. K tomu doporučuji použít Flexy Pool.
Musíte být velmi pečliví a ujistit se, že odpovídajícím způsobem označíte všechny transakce pouze pro čtení. Je neobvyklé, že pouze 10 % vašich transakcí je pouze pro čtení. Je možné, že máte takovou aplikaci s většinou zápisů nebo používáte transakce zápisu, kde pouze zadáváte příkazy dotazu?
Pro dávkové zpracování určitě potřebujete transakce čtení a zápisu, takže se ujistěte, že povolíte dávkové zpracování JDBC, jako je toto:
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_size" value="25"/>
Pro dávkování můžete také použít samostatný DataSource který používá jiný fond připojení, který se připojuje k primárnímu uzlu.
Jen se ujistěte, že vaše celková velikost připojení všech fondů připojení je menší než počet připojení, se kterými byl nakonfigurován PostgreSQL.
Každá dávková úloha musí používat vyhrazenou transakci, takže se ujistěte, že používáte přiměřenou velikost dávky.
Navíc chcete držet zámky a dokončit transakce co nejrychleji. Pokud dávkový procesor používá pracovníky souběžného zpracování, ujistěte se, že velikost souvisejícího fondu připojení je rovna počtu pracovníků, aby nečekali, až ostatní uvolní připojení.