TeamCity je server pro nepřetržitou integraci a nepřetržité doručování postavený v Javě. Je k dispozici jako cloudová služba a místně. Jak si dokážete představit, nástroje pro neustálou integraci a poskytování jsou zásadní pro vývoj softwaru a jejich dostupnost nesmí být ovlivněna. Naštěstí lze TeamCity nasadit ve vysoce dostupném režimu.
Tento příspěvek na blogu se bude zabývat přípravou a nasazením vysoce dostupného prostředí pro TeamCity.
Prostředí
TeamCity se skládá z několika prvků. Existuje Java aplikace a databáze, která to zálohuje. Používá také agenty, kteří komunikují s primární instancí TeamCity. Vysoce dostupné nasazení se skládá z několika instancí TeamCity, kde jedna funguje jako primární a ostatní sekundární. Tyto instance sdílejí přístup ke stejné databázi a datovému adresáři. Užitečné schéma je k dispozici na stránce dokumentace TeamCity, jak je uvedeno níže:

Jak vidíme, existují dva sdílené prvky — datový adresář a databáze. Musíme zajistit, aby byly také vysoce dostupné. Existují různé možnosti, které můžete použít k vytvoření sdíleného držáku; budeme však používat GlusterFS. Pokud jde o databázi, použijeme jeden z podporovaných systémů pro správu relačních databází – PostgreSQL a použijeme ClusterControl k vybudování zásobníku s vysokou dostupností založeného na něm.
Jak nakonfigurovat GlusterFS
Začněme základy. Chceme nakonfigurovat názvy hostitelů a /etc/hosts na našich uzlech TeamCity, kde budeme také nasazovat GlusterFS. Abychom to mohli udělat, musíme na všech z nich nastavit úložiště pro nejnovější balíčky GlusterFS:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updatePak můžeme nainstalovat GlusterFS na všechny naše uzly TeamCity:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS používá port 24007 pro připojení mezi uzly; musíme se ujistit, že je otevřený a přístupný všem uzlům.
Jakmile je konektivita zavedena, můžeme vytvořit cluster GlusterFS spuštěním z jednoho uzlu:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Nyní můžeme otestovat, jak stav vypadá:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Zdá se, že je vše v pořádku a připojení je na místě.
Dále bychom měli připravit blokové zařízení, které bude GlusterFS používat. Toto musí být provedeno na všech uzlech. Nejprve vytvořte oddíl:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Potom naformátujte tento oddíl:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Nakonec musíme na všech uzlech vytvořit adresář, který bude použit k připojení oddílu, a upravit fstab, aby bylo zajištěno, že bude připojen při spuštění:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabPojďme nyní ověřit, že to funguje:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Nyní můžeme použít jeden z uzlů k vytvoření a spuštění svazku GlusterFS:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successUpozorňujeme, že pro počet replik používáme hodnotu „3“. Znamená to, že každý svazek bude existovat ve třech kopiích. V našem případě bude každá cihla, každý svazek /dev/sdb1 na všech uzlech obsahovat všechna data.
Jakmile jsou svazky spuštěny, můžeme ověřit jejich stav:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksJak vidíte, vše vypadá v pořádku. Důležité je, že GlusterFS vybral port 49152 pro přístup k tomuto svazku a musíme zajistit, aby byl dosažitelný na všech uzlech, kam jej budeme připojovat.
Dalším krokem bude instalace klientského balíčku GlusterFS. Pro tento příklad jej potřebujeme nainstalovat na stejné uzly jako server GlusterFS:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Dále musíme vytvořit adresář na všech uzlech, který bude použit jako sdílený datový adresář pro TeamCity. To se musí stát na všech uzlech:
example@sqldat.com:~# sudo mkdir /teamcity-storageNakonec připojte svazek GlusterFS na všechny uzly:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageTím jsou přípravy sdíleného úložiště dokončeny.
Vytvoření vysoce dostupného clusteru PostgreSQL
Jakmile bude nastavení sdíleného úložiště pro TeamCity dokončeno, můžeme nyní budovat naši vysoce dostupnou databázovou infrastrukturu. TeamCity může používat různé databáze; v tomto blogu však budeme používat PostgreSQL. Využijeme ClusterControl k nasazení a následné správě databázového prostředí.
Příručka TeamCity k vytváření nasazení s více uzly je užitečná, ale zdá se, že opomíjí vysokou dostupnost všeho jiného než TeamCity. Průvodce TeamCity navrhuje server NFS nebo SMB pro ukládání dat, který sám o sobě nemá redundanci a stane se jediným bodem selhání. Vyřešili jsme to pomocí GlusterFS. Zmiňují sdílenou databázi, protože jeden databázový uzel zjevně neposkytuje vysokou dostupnost. Musíme sestavit pořádný zásobník:

V našem případě. bude sestávat ze tří uzlů PostgreSQL, jednoho primárního a dvou replik. HAProxy použijeme jako nástroj pro vyrovnávání zátěže a ke správě virtuální IP použijeme Keepalived, abychom poskytli jeden koncový bod, ke kterému se aplikace může připojit. ClusterControl se postará o selhání monitorováním topologie replikace a provedením jakékoli požadované obnovy podle potřeby, jako je restartování neúspěšných procesů nebo selhání jedné z replik, pokud dojde k výpadku primárního uzlu.
Pro začátek nasadíme uzly databáze. Mějte prosím na paměti, že ClusterControl vyžaduje připojení SSH z uzlu ClusterControl ke všem uzlům, které spravuje.

Potom vybereme uživatele, kterého použijeme pro připojení k databázi, její heslo a verzi PostgreSQL k nasazení:

Dále definujeme, které uzly použít pro nasazení PostgreSQL :
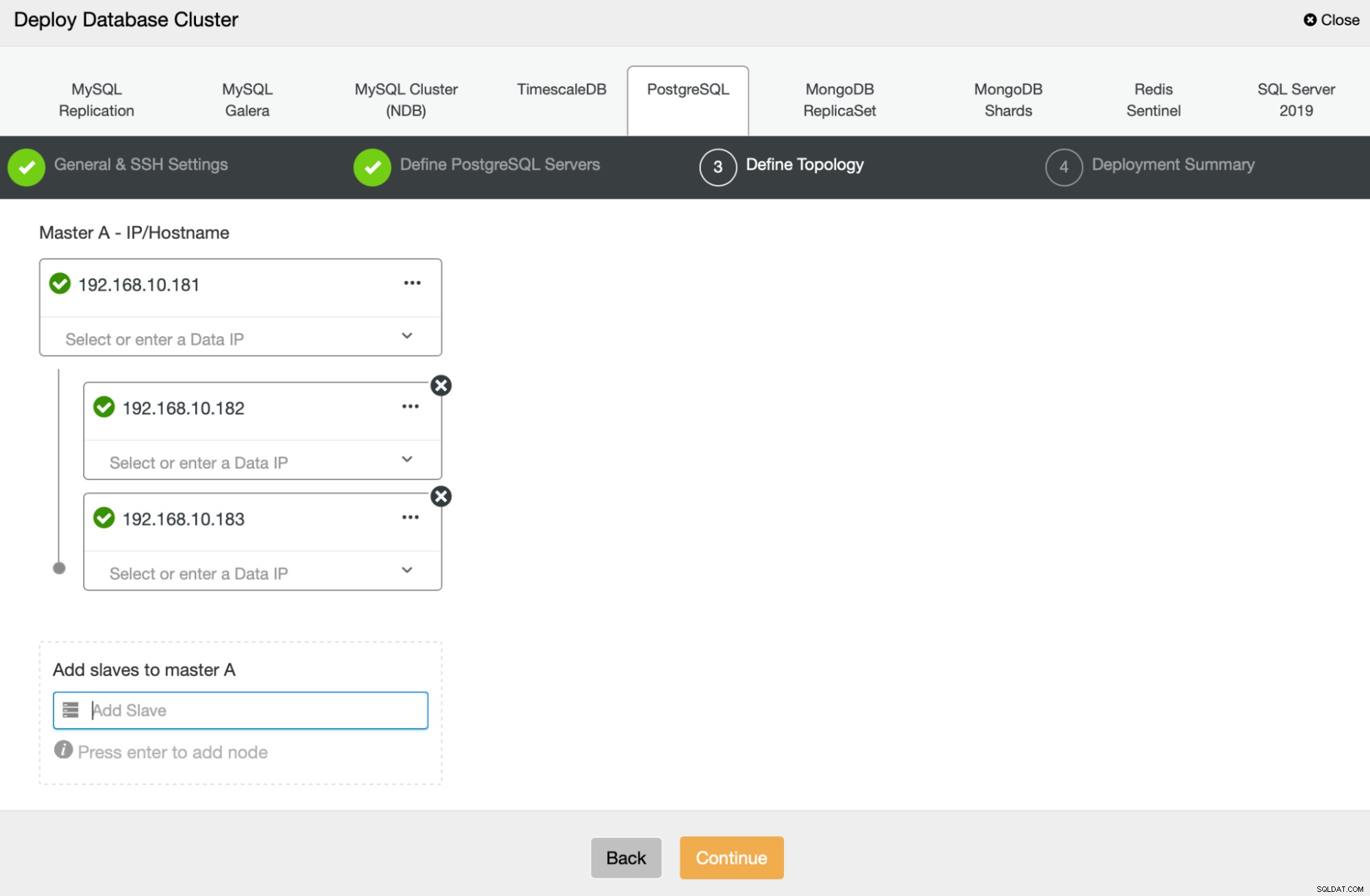
Nakonec můžeme definovat, zda mají uzly používat asynchronní nebo synchronní replikaci. Hlavní rozdíl mezi těmito dvěma je, že synchronní replikace zajišťuje, že každá transakce provedená na primárním uzlu bude vždy replikována na repliky. Synchronní replikace však také zpomaluje odevzdání. Pro nejlepší trvanlivost doporučujeme povolit synchronní replikaci, ale měli byste si později ověřit, zda je výkon přijatelný.

Po kliknutí na „Nasadit“ se spustí úloha nasazení. Jeho průběh můžeme sledovat v záložce Activity v uživatelském rozhraní ClusterControl. Nakonec bychom měli vidět, že úloha byla dokončena a cluster byl úspěšně nasazen.

Nasaďte instance HAProxy v části Spravovat -> Nástroje pro vyrovnávání zatížení. Vyberte HAProxy jako nástroj pro vyrovnávání zatížení a vyplňte formulář. Nejdůležitější volbou je, kam chcete HAProxy nasadit. V tomto případě jsme použili databázový uzel, ale v produkčním prostředí budete s největší pravděpodobností chtít oddělit nástroje pro vyrovnávání zatížení od instancí databáze. Dále vyberte, které uzly PostgreSQL chcete zahrnout do HAProxy. Chceme je všechny.

Nyní se spustí nasazení HAProxy. Chceme to zopakovat ještě alespoň jednou, abychom vytvořili dvě instance HAProxy pro redundanci. V tomto nasazení jsme se rozhodli použít tři HAProxy load balancery. Níže je snímek obrazovky nastavení při konfiguraci nasazení druhého HAProxy:
Když jsou všechny naše instance HAProxy v provozu, můžeme nasadit Keepalived . Myšlenka je taková, že Keepalived bude spojen s HAProxy a bude monitorovat proces HAProxy. Jedna z instancí s funkčním HAProxy bude mít přidělenou virtuální IP. Tento VIP by měl být použit aplikací pro připojení k databázi. Keepalived zjistí, pokud se HAProxy stane nedostupným, a přesune se do jiné dostupné instance HAProxy.
Průvodce nasazením vyžaduje, abychom předali instance HAProxy, které chceme, aby Keepaved monitoroval. Musíme také předat IP adresu a síťové rozhraní pro VIP.

Posledním a posledním krokem bude vytvoření databáze pro TeamCity:

Tím jsme dokončili nasazení vysoce dostupného clusteru PostgreSQL.
Nasazení TeamCity jako víceuzlů
Dalším krokem je nasazení TeamCity v prostředí s více uzly. Použijeme tři uzly TeamCity. Nejprve musíme nainstalovat Java JRE a JDK, které odpovídají požadavkům TeamCity.
apt install default-jre default-jdkNyní musíme na všech uzlech stáhnout TeamCity. Nainstalujeme do místního, nikoli sdíleného adresáře.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzPak můžeme spustit TeamCity na jednom z uzlů:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logPo spuštění TeamCity máme přístup k uživatelskému rozhraní a můžeme začít s nasazením. Zpočátku musíme předat umístění datového adresáře. Toto je sdílený svazek, který jsme vytvořili na GlusterFS.

Dále vyberte databázi. Budeme používat cluster PostgreSQL, který jsme již vytvořili.

Stáhněte si a nainstalujte ovladač JDBC:

Dále vyplňte přístupové údaje. Použijeme virtuální IP adresu poskytnutou Keepalived. Upozorňujeme, že používáme port 5433. Toto je port používaný pro backend pro čtení/zápis HAProxy; bude vždy směřovat k aktivnímu primárnímu uzlu. Dále vyberte uživatele a databázi, které chcete použít s TeamCity.

Jakmile to provedete, TeamCity začne inicializovat strukturu databáze.

Souhlasím s licenční smlouvou:

Nakonec vytvořte uživatele pro TeamCity:

To je ono! Nyní bychom měli být schopni vidět TeamCity GUI:

Nyní musíme nastavit TeamCity v režimu více uzlů. Nejprve musíme upravit spouštěcí skripty na všech uzlech:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shMusíme se ujistit, že jsou exportovány následující dvě proměnné. Ověřte prosím, že používáte správný název hostitele, IP adresu a správné adresáře pro místní a sdílené úložiště:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Jakmile to uděláte, můžete spustit zbývající uzly:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startV části Správa -> Konfigurace uzlů byste měli vidět následující výstup:Jeden hlavní uzel a dva pohotovostní uzly.

Mějte na paměti, že převzetí služeb při selhání v TeamCity není automatické. Pokud hlavní uzel přestane fungovat, měli byste se připojit k jednomu ze sekundárních uzlů. Chcete-li to provést, přejděte na „Konfigurace uzlů“ a povýšte jej na uzel „Hlavní“. Na přihlašovací obrazovce uvidíte jasné označení, že se jedná o sekundární uzel:

V "Konfigurace uzlů" uvidíte, že jeden uzel má vypadl z clusteru:

Obdržíte zprávu, že do tohoto uzlu nemůžete psát. Nebojte se; zápis potřebný k povýšení tohoto uzlu do stavu „hlavní“ bude fungovat dobře:

Klikněte na „Povolit“ a úspěšně jsme povýšili sekundární uzel TimeCity:

Když bude uzel 1 dostupný a na tomto uzlu se znovu spustí TeamCity, vidět, že se znovu připojí ke clusteru:

Pokud chcete výkon dále zlepšit, můžete nasadit HAProxy + Keepalived před uživatelské rozhraní TeamCity a poskytnout tak jediný vstupní bod do GUI. Podrobnosti o konfiguraci HAProxy pro TeamCity naleznete v dokumentaci.
Zabalení
Jak vidíte, nasazení TeamCity pro vysokou dostupnost není tak obtížné – většina z toho byla podrobně popsána v dokumentaci. Pokud hledáte způsoby, jak něco z toho zautomatizovat a přidat vysoce dostupný databázový backend, zvažte možnost vyzkoušet ClusterControl zdarma po dobu 30 dnů. ClusterControl může rychle nasadit a monitorovat backend, poskytuje automatické převzetí služeb při selhání, obnovu, monitorování, správu zálohování a další.
Další tipy na nástroje pro vývoj softwaru a osvědčené postupy najdete v článku, jak podpořit svůj tým DevOps s potřebami databáze.
Chcete-li získat nejnovější zprávy a osvědčené postupy pro správu vaší open source databázové infrastruktury, nezapomeňte nás sledovat na Twitteru nebo LinkedIn a přihlásit se k odběru našeho newsletteru. Uvidíme se brzy!