Někdy je obtížné spravovat velké množství dat ve společnosti, zvláště s exponenciálním nárůstem využití datové analýzy a internetu věcí. V závislosti na velikosti může toto množství dat ovlivnit výkon vašich systémů a pravděpodobně budete muset škálovat své databáze nebo najít způsob, jak to opravit. Existují různé způsoby škálování vašich PostgreSQL databází a jedním z nich je Sharding. V tomto blogu uvidíme, co je Sharding a jak jej nakonfigurovat v PostgreSQL pomocí ClusterControl pro zjednodušení úlohy.
Co je Sharding?
Sharding je akce optimalizace databáze oddělením dat z velké tabulky do několika malých. Menší tabulky jsou Shards (nebo oddíly). Partitioning a Sharding jsou podobné koncepty. Hlavním rozdílem je, že sharding znamená, že data jsou rozložena na více počítačích, zatímco rozdělení je o seskupování podmnožin dat v rámci jedné instance databáze.
Existují dva typy Sharding:
-
Horizontální dělení:Každá nová tabulka má stejné schéma jako velká tabulka, ale jedinečné řádky. Je to užitečné, když dotazy mají tendenci vracet podmnožinu řádků, které jsou často seskupeny.
-
Vertikální sdílení:Každá nová tabulka má schéma, které je podmnožinou schématu původní tabulky. Je to užitečné, když dotazy mají tendenci vracet pouze podmnožinu sloupců dat.
Podívejme se na příklad:
Původní tabulka
| ID | Jméno | Věk | Země |
|---|---|---|---|
| 1 | James Smith | 26 | USA |
| 2 | Mary Johnson | 31 | Německo |
| 3 | Robert Williams | 54 | Kanada |
| 4 | Jennifer Brown | 47 | Francie |
Vertikální dělení
| Shard1 | Shard2 | |||
|---|---|---|---|---|
| ID | Jméno | Věk | ID | Země |
| 1 | James Smith | 26 | 1 | USA |
| 2 | Mary Johnson | 31 | 2 | Německo |
| 3 | Robert Williams | 54 | 3 | Kanada |
| 4 | Jennifer Brown | 47 | 4 | Francie |
Horizontální dělení
| Shard1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Název | Věk | Země | ID | Název | Věk | Země |
| 1 | James Smith | 26 | USA | 3 | Robert Williams | 54 | Kanada |
| 2 | Mary Johnson | 31 | Německo | 4 | Jennifer Brown | 47 | Francie |
Když jsme si nyní prošli některé koncepty Sharding, pojďme k dalšímu kroku.
Jak nasadit klastr PostgreSQL?
Pro tento úkol použijeme ClusterControl. Pokud ClusterControl ještě nepoužíváte, můžete jej nainstalovat a nasadit nebo importovat svou aktuální databázi PostgreSQL výběrem možnosti „Importovat“ a postupujte podle pokynů, abyste mohli využít všechny funkce ClusterControl, jako jsou zálohy, automatické převzetí služeb při selhání, výstrahy, monitorování a další. .
Chcete-li provést nasazení z ClusterControl, jednoduše vyberte možnost „Deploy“ a postupujte podle zobrazených pokynů.
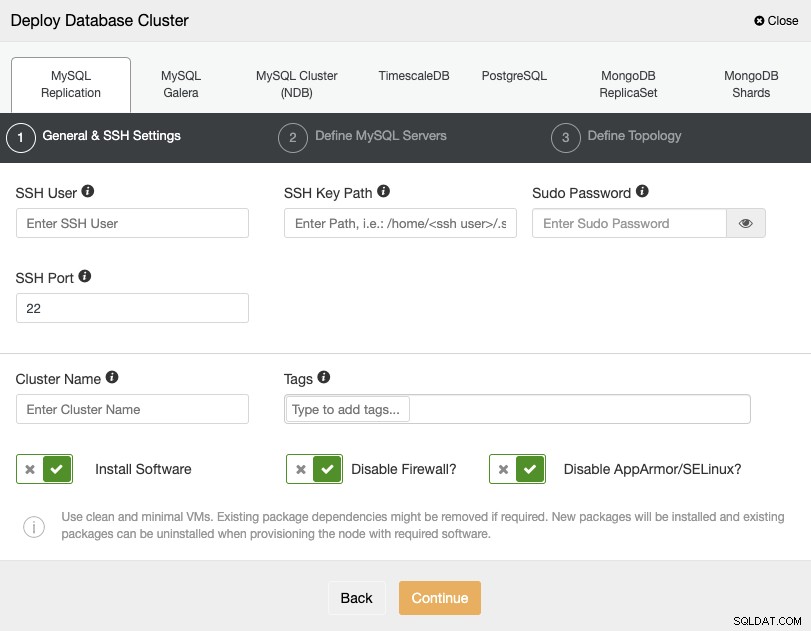
Při výběru PostgreSQL musíte zadat svého uživatele, klíč nebo heslo a Port pro připojení pomocí SSH k vašim serverům. Můžete také přidat název svého nového clusteru a pokud chcete, můžete také použít ClusterControl k instalaci odpovídajícího softwaru a konfigurací.
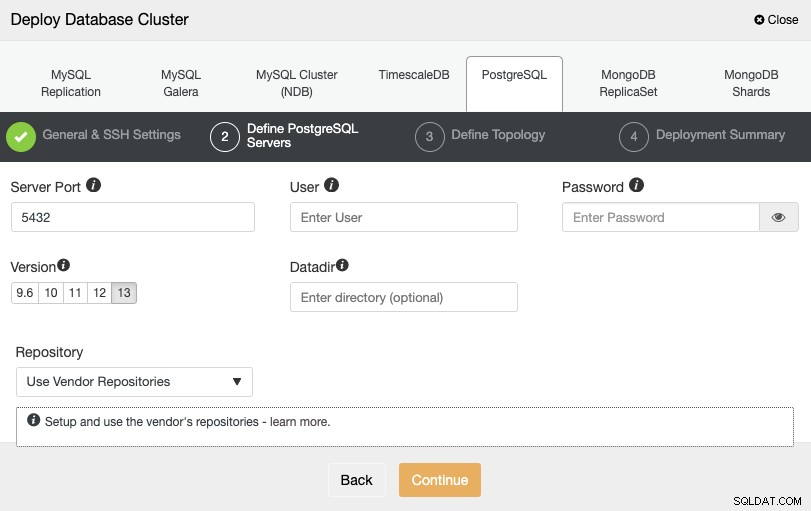
Po nastavení přístupových informací SSH je třeba definovat přihlašovací údaje k databázi , verze a datadir (volitelné). Můžete také určit, které úložiště použít.
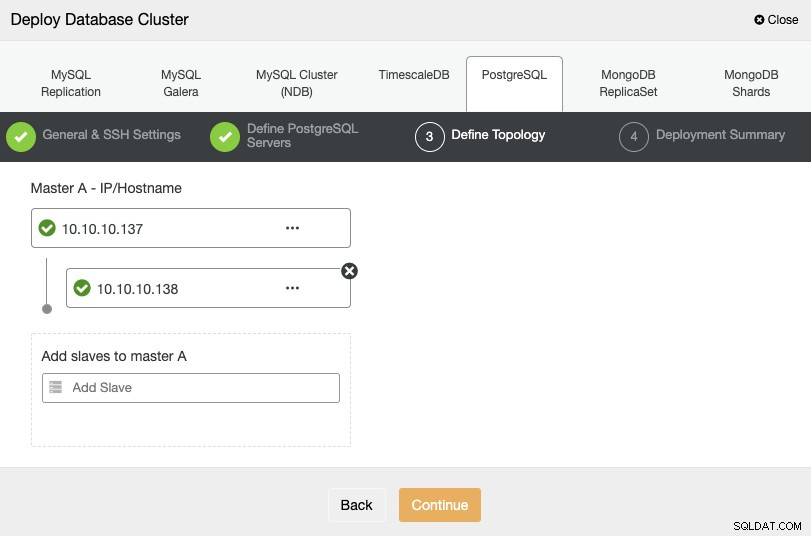
V dalším kroku musíte přidat své servery do clusteru, který se chystáte vytvořit, pomocí adresy IP nebo názvu hostitele.
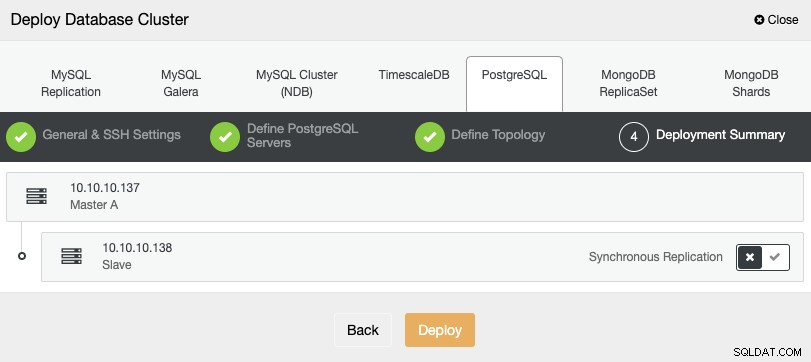
V posledním kroku si můžete vybrat, zda bude vaše replikace synchronní nebo Asynchronní a poté stačí stisknout „Deploy“.
Po dokončení úlohy uvidíte svůj nový cluster PostgreSQL v hlavní obrazovka ClusterControl.

Nyní, když máte cluster vytvořený, můžete na něm provádět několik úkolů jako je přidání nástroje pro vyrovnávání zatížení (HAProxy), sdružování připojení (pgBouncer) nebo nové repliky.
Opakujte proces, abyste měli alespoň dva samostatné clustery PostgreSQL pro konfiguraci Sharding, což je další krok.
Jak nakonfigurovat sdílení PostgreSQL?
Nyní nakonfigurujeme Sharding pomocí PostgreSQL Partitions a Foreign Data Wrapper (FDW). Tato funkce umožňuje PostgreSQL přistupovat k datům uloženým na jiných serverech. Jedná se o rozšíření dostupné ve výchozím nastavení v běžné instalaci PostgreSQL.
Budeme používat následující prostředí:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersChcete-li povolit rozšíření FDW, stačí na svém hlavním serveru, v tomto případě Shard1, spustit následující příkaz:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONNyní vytvoříme tabulku zákazníků rozdělenou podle data registrace:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);A následující oddíly:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Tyto oddíly jsou místní. Nyní vložíme nějaké testovací hodnoty a zkontrolujeme je:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Zde se můžete dotazovat na hlavní oddíl a zobrazit všechna data:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)Nebo dokonce dotaz na odpovídající oddíl:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Jak můžete vidět, data byla vložena do různých oddílů podle data registrace. Nyní ve vzdáleném uzlu, v tomto případě Shard2, vytvoříme další tabulku:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Tento server Shard2 musíte vytvořit v Shard1 tímto způsobem:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');A uživatel, který k němu má přístup:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Nyní vytvořte CIZÍ TABULKU v Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;A vložíme data do této nové vzdálené tabulky ze Shard1:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Pokud vše proběhlo v pořádku, měli byste mít přístup k datům z Shard1 i Shard2:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Shard2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)To je ono. Nyní používáte Sharding ve svém PostgreSQL Clusteru.
Závěr
Rozdělení a sdílení v PostgreSQL jsou dobré funkce. Pomůže vám v případě, že potřebujete oddělit data ve velké tabulce, abyste zlepšili výkon, nebo dokonce data jednoduše vyčistili, mimo jiné. Důležitým bodem při používání Sharding je vybrat si dobrý shard klíč, který distribuuje data mezi uzly nejlepším způsobem. ClusterControl můžete také použít ke zjednodušení nasazení PostgreSQL a k využití některých funkcí, jako je monitorování, upozornění, automatické převzetí služeb při selhání, zálohování, obnovení v určitém okamžiku a další.