Použití replikace pro vaše databáze PostgreSQL může být užitečné nejen pro zajištění vysoké dostupnosti a odolnosti vůči chybám, ale také pro zlepšení výkonu vašeho systému vyvážením provozu mezi pohotovostními uzly. V této první části dvoudílného blogu se podíváme na některé koncepty související s replikací PostgreSQL.
Metody replikace v PostgreSQL
Existují různé metody replikace dat v PostgreSQL, ale zde se zaměříme na dvě hlavní metody:Streaming Replication a Logical Replication.
Streamování replikace
PostgreSQL Streaming Replication, nejběžnější replikace PostgreSQL, je fyzická replikace, která replikuje změny na úrovni bajtu po bajtu a vytváří identickou kopii databáze na jiném serveru. Je založen na způsobu dopravy protokolu. Záznamy WAL se přímo přesouvají z jednoho databázového serveru na jiný, aby byly použity. Dá se říci, že jde o jakýsi kontinuální PITR.
Tento přenos WAL se provádí dvěma různými způsoby, přenosem záznamů WAL po jednom souboru (segment WAL) (zasílání protokolu na základě souborů) a přenosem záznamů WAL (soubor WAL se skládá z Záznamy WAL) za běhu (zasílání protokolů na základě záznamů), mezi primárním serverem a jedním nebo více servery než na záložních serverech, bez čekání na vyplnění souboru WAL.
V praxi se proces zvaný přijímač WAL, který běží na pohotovostním serveru, připojí k primárnímu serveru pomocí připojení TCP/IP. Na primárním serveru existuje další proces, nazvaný odesílatel WAL, a má na starosti odesílání registrů WAL na záložní server, jakmile k nim dojde.
Základní streamovací replikace může být reprezentována následovně:
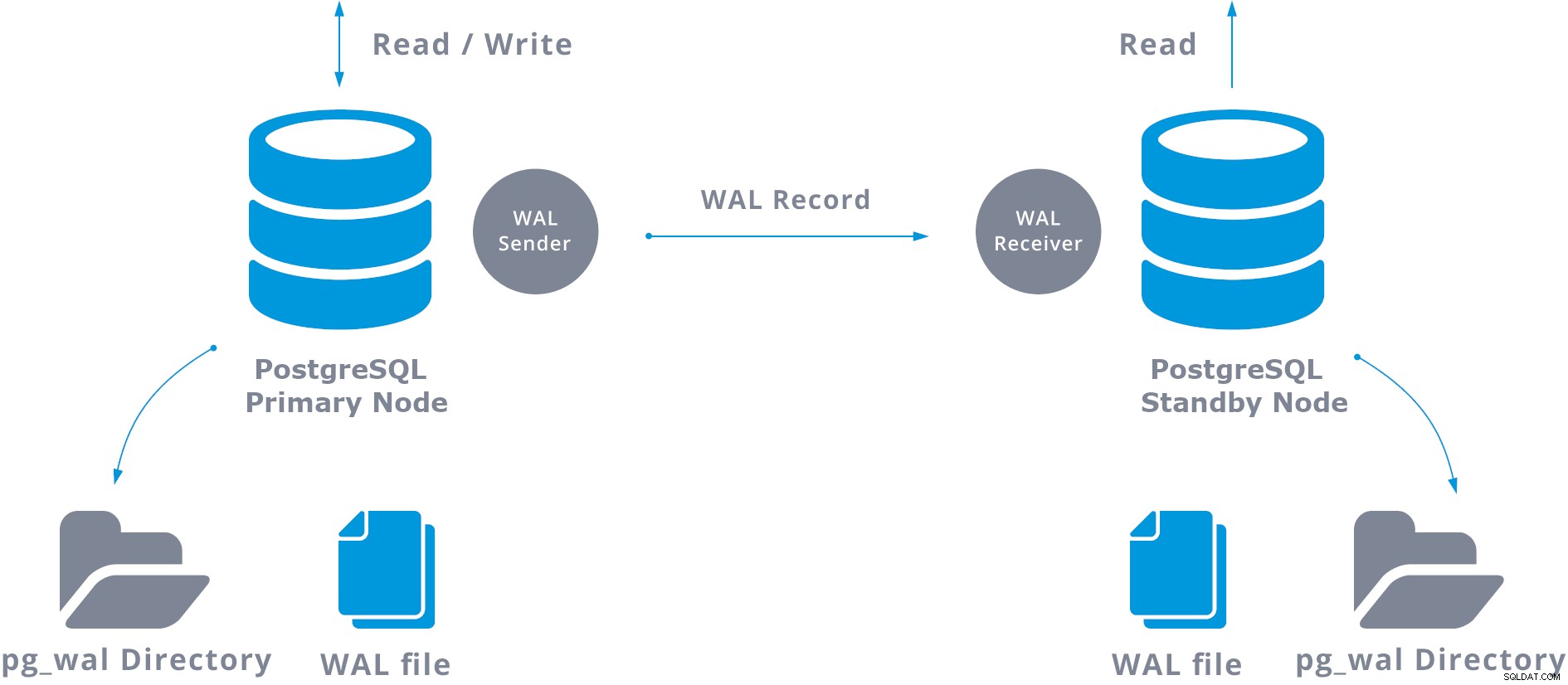
Při konfiguraci replikace streamování máte možnost povolit archivaci WAL. Toto není povinné, ale je to extrémně důležité pro robustní nastavení replikace, protože je nutné zabránit tomu, aby hlavní server recykloval staré soubory WAL, které ještě nebyly použity na záložní server. Pokud k tomu dojde, budete muset repliku vytvořit znovu od začátku.
Logická replikace
Logická replikace PostgreSQL je metoda replikace datových objektů a jejich změn na základě jejich replikační identity (obvykle primární klíč). Je založen na režimu publikování a odběru, kde jeden nebo více odběratelů odebírá jednu nebo více publikací v uzlu vydavatele.
Publikace je sada změn generovaných z tabulky nebo skupiny tabulek. Uzel, kde je definována publikace, se nazývá vydavatel. Předplatné je následnou stranou logické replikace. Uzel, kde je definováno předplatné, se označuje jako předplatitel a definuje připojení k jiné databázi a sadě publikací (jedné nebo více), ke kterým se chce přihlásit. Předplatitelé získávají data z publikací, které odebírají.
Logická replikace je postavena na architektuře podobné replikaci fyzického streamování. Je implementován procesy „walsender“ a „apply“. Proces walsender spustí logické dekódování WAL a načte standardní plugin pro logické dekódování. Plugin transformuje změny načtené z WAL do protokolu logické replikace a filtruje data podle specifikace publikace. Data jsou pak nepřetržitě přenášena pomocí streamingového replikačního protokolu k aplikačnímu pracovníkovi, který mapuje data do lokálních tabulek a aplikuje jednotlivé změny tak, jak jsou přijímány, ve správném transakčním pořadí.
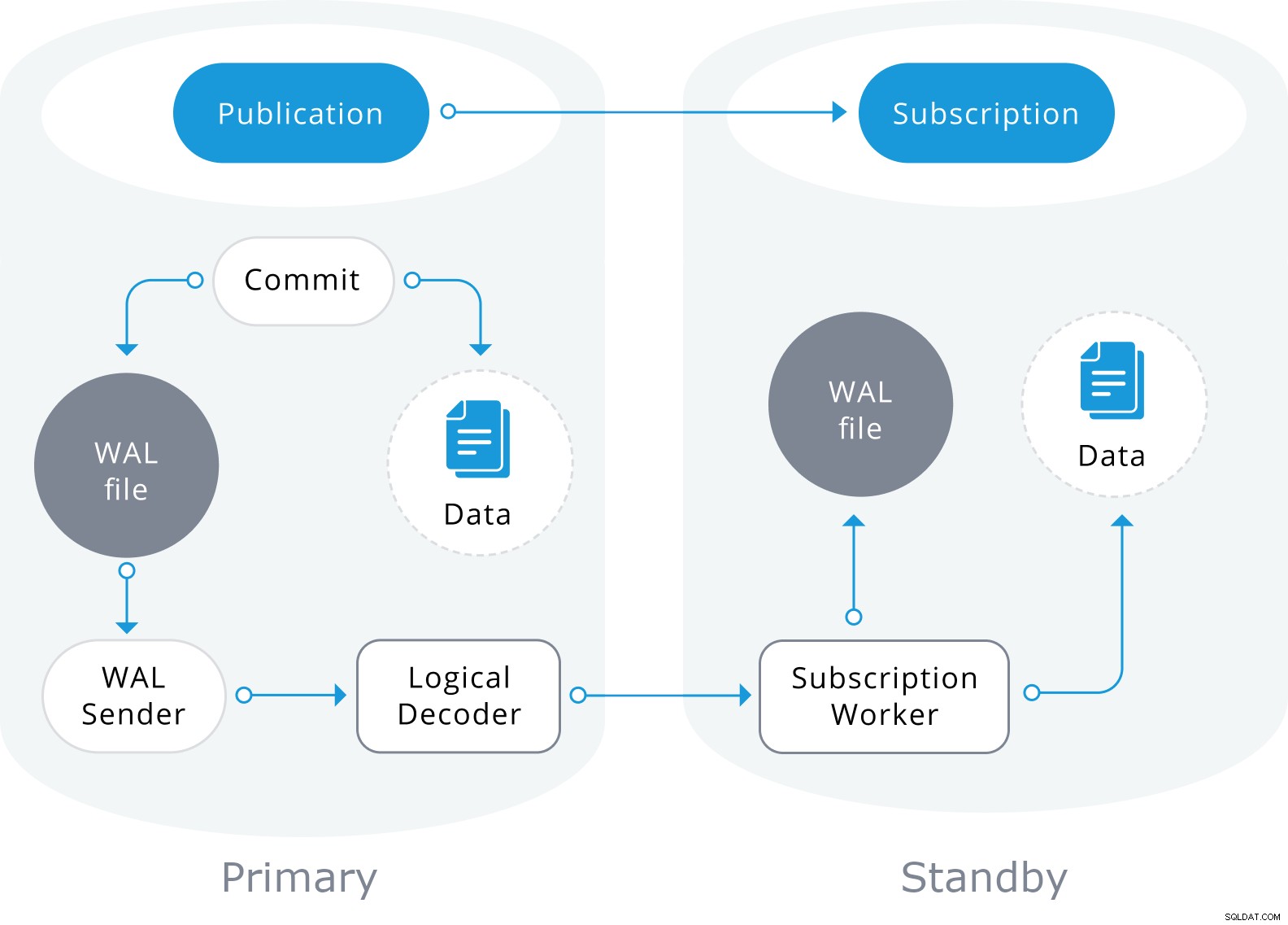
Logická replikace začíná pořízením snímku dat v databázi vydavatelů a zkopíruje to předplatiteli. Počáteční data v existujících odebíraných tabulkách jsou zachycována a zkopírována v paralelní instanci speciálního druhu aplikačního procesu. Tento proces vytvoří svůj vlastní dočasný replikační slot a zkopíruje existující data. Jakmile jsou existující data zkopírována, pracovník přejde do režimu synchronizace, který zajistí, že tabulka bude uvedena do synchronizovaného stavu s hlavním procesem aplikace streamováním jakýchkoli změn, ke kterým došlo během počátečního kopírování dat, pomocí standardní logické replikace. Po dokončení synchronizace je řízení replikace tabulky předáno zpět hlavnímu procesu aplikace, kde replikace pokračuje jako obvykle. Změny ve vydavateli jsou odesílány odběrateli tak, jak k nim dochází v reálném čase.
Replikační režimy v PostgreSQL
Replikace v PostgreSQL může být synchronní nebo asynchronní.
Asynchronní replikace
Je to výchozí režim. Zde je možné mít některé transakce potvrzené v primárním uzlu, které ještě nebyly replikovány na záložní server. To znamená, že existuje možnost určité potenciální ztráty dat. Toto zpoždění v procesu potvrzení by mělo být velmi malé, pokud je záložní server dostatečně výkonný, aby držel krok se zátěží. Pokud toto malé riziko ztráty dat není ve společnosti přijatelné, můžete místo toho použít synchronní replikaci.
Synchronní replikace
Každé potvrzení transakce zápisu bude čekat na potvrzení, že potvrzení bylo zapsáno do protokolu pro zápis na disk primárního i záložního serveru. Tato metoda minimalizuje možnost ztráty dat. Aby došlo ke ztrátě dat, museli byste současně selhat primární i pohotovostní režim.
Nevýhoda této metody je u všech synchronních metod stejná, protože u této metody se zvyšuje doba odezvy pro každou transakci zápisu. To je způsobeno nutností počkat na všechna potvrzení, že transakce byla potvrzena. Naštěstí to neovlivní transakce pouze pro čtení, ale; pouze transakce zápisu.
Vysoká dostupnost pro replikaci PostgreSQL
Vysoká dostupnost je požadavkem mnoha systémů, bez ohledu na to, jakou technologii používáme, a existují různé přístupy, jak toho dosáhnout pomocí různých nástrojů.
Vyrovnávání zátěže
Nástroje pro vyrovnávání zatížení jsou nástroje, které lze použít ke správě provozu z vaší aplikace, abyste z architektury své databáze vytěžili maximum. Nejen, že je to užitečné pro vyrovnávání zatížení našich databází, ale také pomáhá aplikacím přesměrovat se na dostupné/zdravé uzly a dokonce specifikovat porty s různými rolemi.
HAProxy je nástroj pro vyrovnávání zatížení, který distribuuje provoz z jednoho zdroje do jednoho nebo více cílů a může pro tento úkol definovat specifická pravidla a/nebo protokoly. Pokud některý z cílů přestane reagovat, je označen jako offline a provoz je odeslán do zbývajících dostupných cílů. Pokud budete mít pouze jeden uzel Load Balancer, vygeneruje se jediný bod selhání, takže abyste tomu zabránili, měli byste nasadit alespoň dva uzly HAProxy a nakonfigurovat mezi nimi Keepalived.
Keepalived je služba, která nám umožňuje konfigurovat virtuální IP v rámci aktivní/pasivní skupiny serverů. Tato virtuální IP adresa je přiřazena aktivnímu serveru. Pokud tento server selže, IP se automaticky migruje na „sekundární“ pasivní server, což mu umožní pokračovat v práci se stejnou IP transparentním způsobem pro systémy.
Zlepšení výkonu replikace PostgreSQL
V každém systému je vždy důležitý výkon. Budete muset dobře využít dostupné zdroje, abyste zajistili co nejlepší dobu odezvy a existují různé způsoby, jak toho dosáhnout. Každé připojení k databázi spotřebovává zdroje, takže jedním ze způsobů, jak zlepšit výkon vaší PostgreSQL databáze, je mít dobrý sdružovač připojení mezi vaší aplikací a databázovými servery.
Poolery připojení
Sdružování připojení je metoda vytváření fondu připojení a jejich opětovného použití, aniž by se neustále otevíraly nová připojení k databázi, což výrazně zvýší výkon vašich aplikací. PgBouncer je populární sdružovač připojení navržený pro PostgreSQL.
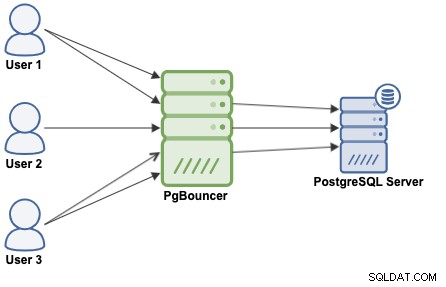
PgBouncer funguje jako PostgreSQL server, takže stačí mít přístup k databázi pomocí informací PgBouncer (IP adresa/název hostitele a port) a PgBouncer vytvoří připojení k serveru PostgreSQL nebo jej znovu použije, pokud existuje.
Když PgBouncer přijme spojení, provede ověření, které závisí na metodě uvedené v konfiguračním souboru. PgBouncer podporuje všechny autentizační mechanismy, které PostgreSQL server podporuje. Poté PgBouncer zkontroluje připojení uložené v mezipaměti se stejnou kombinací uživatelského jména a databáze. Pokud je nalezeno připojení uložené v mezipaměti, vrátí připojení klientovi, pokud ne, vytvoří nové připojení. V závislosti na konfiguraci PgBouncer a počtu aktivních připojení je možné, že nové připojení bude zařazeno do fronty, dokud nebude možné vytvořit, nebo dokonce přerušit.
Se všemi těmito zmíněnými koncepty v druhé části tohoto blogu uvidíme, jak je můžete zkombinovat, abyste měli dobré replikační prostředí v PostgreSQL.