Správa instalace PostgreSQL zahrnuje kontrolu a kontrolu nad širokou škálou aspektů v zásobníku softwaru/infrastruktury, na kterém PostgreSQL běží. To musí zahrnovat:
- Ladění aplikace týkající se využití databáze/transakcí/připojení
- Kód databáze (dotazy, funkce)
- Databázový systém (výkon, HA, zálohy)
- Hardware/infrastruktura (disky, CPU/paměť)
Jádro PostgreSQL poskytuje databázovou vrstvu, na které věříme, že budou naše data uložena, zpracována a obsluhována. Poskytuje také veškerou technologii pro skutečně moderní, efektivní, spolehlivý a bezpečný systém. Tato technologie však často není v základní distribuci PostgreSQL dostupná jako rafinovaný produkt třídy business/enterprise připravený k použití. Místo toho existuje spousta produktů/řešení od komunity PostgreSQL nebo komerčních nabídek, které tyto potřeby splňují. Tato řešení přicházejí buď jako uživatelsky přívětivá vylepšení základních technologií, nebo rozšíření základních technologií nebo dokonce jako integrace mezi komponentami PostgreSQL a dalšími komponentami systému. V našem předchozím blogu nazvaném Deset tipů pro spuštění výroby s PostgreSQL jsme se podívali na některé z těchto nástrojů, které mohou pomoci spravovat instalaci PostgreSQL v produkci. V tomto blogu podrobněji prozkoumáme aspekty, které je třeba pokrýt při správě instalace PostgreSQL v produkci, a nejběžněji používané nástroje pro tento účel. Budeme se zabývat následujícími tématy:
- Nasazení
- Správa
- Škálování
- Monitorování
Nasazení
Za starých časů lidé stahovali a kompilovali PostgreSQL ručně a poté konfigurovali parametry běhu a řízení přístupu uživatelů. Stále existují případy, kdy to může být potřeba, ale jak systémy dozrávaly a začaly růst, vyvstala potřeba standardizovanějších způsobů nasazení a správy Postgresql. Většina OS poskytuje balíčky pro instalaci, nasazení a správu clusterů PostgreSQL. Debian standardizoval jejich vlastní rozvržení systému podporující mnoho verzí Postgresql a mnoho clusterů na verzi současně. Balíček postgresql-common debian poskytuje potřebné nástroje. Chcete-li například vytvořit nový cluster (nazvaný i18n_cluster) pro PostgreSQL verze 10 v Debianu, můžeme to udělat zadáním následujících příkazů:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsPoté obnovte systemd:
$ sudo systemctl daemon-reloada nakonec spusťte a použijte nový cluster:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(všimněte si, že Debian zpracovává různé clustery pomocí různých portů 5432, 5433 a tak dále)
Jak roste potřeba automatizovanějších a masivnějších nasazení, stále více instalací využívá automatizační nástroje jako Ansible, Chef a Puppet. Kromě automatizace a reprodukovatelnosti nasazení jsou automatizační nástroje skvělé, protože představují pěkný způsob, jak zdokumentovat nasazení a konfiguraci clusteru. Na druhou stranu se automatizace vyvinula a stala se sama o sobě velkým oborem, který vyžaduje kvalifikované lidi, aby psali, spravovali a spouštěli automatizované skripty. Více informací o zajišťování PostgreSQL lze nalézt v tomto blogu:Staňte se PostgreSQL DBA:Provisioning and Deployment.
Správa
Správa živého systému zahrnuje úkoly, jako jsou:plánování záloh a sledování jejich stavu, zotavení po havárii, správa konfigurace, správa vysoké dostupnosti a automatické řešení přepnutí při selhání. Zálohování clusteru Postgresql lze provést různými způsoby. Nízkoúrovňové nástroje:
- tradiční pg_dump (logická záloha)
- Zálohy na úrovni systému souborů (fyzická záloha)
- pg_basebackup (fyzická záloha)
Nebo vyšší úroveň:
- Barman
- PgBackRest
Každý z těchto způsobů pokrývá různé případy použití a scénáře obnovy a liší se složitostí. Zálohování PostgreSQL úzce souvisí s pojmy PITR, WAL archivace a replikace. V průběhu let se postup přijímání, testování a nakonec (držíme si palce!) používání záloh s PostgreSQL vyvinul jako komplexní úkol. Pěkný přehled zálohovacích řešení pro PostgreSQL můžete najít v tomto blogu:Top Backup Tools for PostgreSQL.
Pokud jde o vysokou dostupnost a automatické převzetí služeb při selhání, naprosté minimum, které musí instalace mít, aby bylo možné toto implementovat, je:
- Pracující primární
- Pohotovostní režim s podporou WAL streamovaný z primárního zdroje
- V případě selhání primárního prvku, metoda, která primárnímu uživateli sdělí, že již není primární (někdy se nazývá STONITH)
- Mechanismus prezenčního signálu pro kontrolu konektivity mezi dvěma servery a stavu primárního serveru
- Metoda pro provedení převzetí služeb při selhání (např. prostřednictvím pg_ctl promotion nebo spouštěcího souboru)
- Automatický postup pro obnovení původního primárního zdroje jako nového pohotovostního režimu:Jakmile je zjištěno narušení nebo selhání na primárním zařízení, musí být pohotovostní režim povýšen na nový primární režim. Starý primární již není platný ani použitelný. Systém tedy musí mít způsob, jak zvládnout tento stav mezi převzetím služeb při selhání a opětovným vytvořením starého primárního serveru jako nového pohotovostního režimu. Tento stav se nazývá degenerovaný stav a PostgreSQL poskytuje nástroj nazvaný pg_rewind, aby urychlil proces navrácení starého primárního disku zpět do stavu schopného synchronizace z nového primárního.
- Metoda pro přepínání na vyžádání/plánované
Hojně používaným nástrojem, který zvládá vše výše uvedené, je Repmgr. Popíšeme minimální nastavení, které umožní úspěšné přepnutí. Začneme funkčním primárním PostgreSQL 10.4 běžícím na FreeBSD 11.1, ručně sestaveným a nainstalovaným, a repmgr 4.0 také ručně sestaveným a nainstalovaným pro tuto verzi (10.4). Použijeme dva hostitele pojmenované fbsd (192.168.1.80) a fbsdclone (192.168.1.81) s identickými verzemi PostgreSQL a repmgr. Na primární (původně fbsd , 192.168.1.80) se ujistíme, že jsou nastaveny následující parametry PostgreSQL:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Poté vytvoříme uživatele repmgr (jako superuživatele) a databázi:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgra nastavte řízení přístupu založené na hostiteli v pg_hba.conf umístěním následujících řádků nahoru:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustUjistíme se, že nastavíme přihlášení bez hesla pro uživatele repmgr ve všech uzlech clusteru, v našem případě fbsd a fbsdclone, nastavením autorizovaných_klíčů v .ssh a následným sdílením .ssh. Poté vytvoříme repmrg.conf na primární jako:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Poté zaregistrujeme primární:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredA zkontrolujte stav clusteru:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Nyní pracujeme v pohotovostním režimu nastavením repmgr.conf následovně:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Také se ujistíme, že datový adresář zadaný právě v řádku výše existuje, je prázdný a má správná oprávnění:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataNyní se musíme klonovat do našeho nového pohotovostního režimu:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"A spusťte pohotovostní režim:
example@sqldat.com:~ % pg_ctl -D data startV tomto okamžiku by replikace měla fungovat podle očekávání, ověřte to dotazem na pg_stat_replication (fbsd) a pg_stat_wal_receiver (fbsdclone). Dalším krokem je registrace pohotovostního režimu:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerNyní můžeme získat stav klastru buď na pohotovostním, nebo primárním a ověřit, zda je pohotovostní režim zaregistrován:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Nyní předpokládejme, že chceme provést plánované ruční přepnutí např. udělat nějakou administrativní práci na node fbsd. V pohotovostním uzlu spustíme následující příkaz:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyPřepnutí bylo úspěšně provedeno! Podívejme se, co cluster show přináší:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Tyto dva servery si vyměnily role! Repmgr poskytuje démona repmgrd, který poskytuje monitorování, automatické převzetí služeb při selhání a také upozornění/výstrahy. Kombinací repmgrd s pgbouncer je možné implementovat automatickou aktualizaci informací o připojení k databázi, a tak zajistit oplocení pro neúspěšný primární uzel (zabraňující použití neúspěšného uzlu aplikací) a také zajistit minimální prostoje aplikace. Ve složitějších schématech je další nápad zkombinovat Keepalived s HAProxy na vrcholu pgbouncer a repmgr, aby bylo dosaženo:
- vyrovnávání zátěže (škálování)
- vysoká dostupnost
Všimněte si, že ClusterControl také spravuje převzetí služeb při selhání nastavení replikace PostgreSQL a integruje HAProxy a VirtualIP pro automatické přesměrování klientských připojení k pracovnímu hlavnímu serveru. Více informací lze nalézt v tomto dokumentu o PostgreSQL Automation.
Stáhněte si Whitepaper Today Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si WhitepaperŠkálování
Od PostgreSQL 10 (a 11) stále neexistuje způsob, jak mít replikaci s více mastery, alespoň ne z jádra PostgreSQL. To znamená, že lze zvětšit pouze aktivitu výběru (pouze pro čtení). Škálování v PostgreSQL je dosaženo přidáním více aktivních pohotovostních režimů, což poskytuje více zdrojů pro aktivitu pouze pro čtení. S repmgr je snadné přidat nový pohotovostní režim, jak jsme viděli dříve prostřednictvím klonu pohotovostního režimu a pohotovostní registr příkazy. Přidané (nebo odebrané) pohotovostní režimy musí být uvedeny v konfiguraci load-balanceru. HAProxy, jak je uvedeno výše v tématu správy, je oblíbeným nástrojem pro vyrovnávání zatížení pro PostgreSQL. Obvykle je spojen s Keepalived, který poskytuje virtuální IP přes VRRP. Pěkný přehled používání HAProxy a Keepalived společně s PostgreSQL naleznete v tomto článku:Vyrovnávání zátěže PostgreSQL pomocí HAProxy &Keepalived.
Monitorování
Přehled toho, co monitorovat v PostgreSQL, naleznete v tomto článku:Klíčové věci k monitorování v PostgreSQL – Analýza vaší pracovní zátěže. Existuje mnoho nástrojů, které mohou zajistit monitorování systému a postgresql prostřednictvím pluginů. Některé nástroje pokrývají oblast prezentace grafického grafu historických hodnot (munin), jiné pokrývají oblast sledování živých dat a poskytování živých výstrah (nagios), některé nástroje pokrývají obě oblasti (zabbix). Seznam takových nástrojů pro PostgreSQL lze nalézt zde:https://wiki.postgresql.org/wiki/Monitoring. Oblíbeným nástrojem pro offline monitorování (založené na souborech protokolu) je pgBadger. pgBadger je skript v Perlu, který funguje tak, že analyzuje PostgreSQL log (který obvykle pokrývá aktivitu jednoho dne), extrahuje informace, vypočítá statistiky a nakonec vytvoří efektní html stránku prezentující výsledky. pgBadger neomezuje nastavení log_line_prefix, může se přizpůsobit vašemu již existujícímu formátu. Pokud jste například ve svém postgresql.conf nastavili něco jako:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'pak příkaz pgbadger pro analýzu souboru protokolu a vytvoření výsledků může vypadat takto:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger poskytuje zprávy pro:
- Přehled statistik (většinou provoz SQL)
- Připojení (za sekundu, na databázi/uživatele/hostitele)
- Relace (počet, časy relací, podle databáze/uživatele/hostitele/aplikace)
- Kontrolní body (vyrovnávací paměti, soubory wal, aktivita)
- Využití dočasných souborů
- Vysávání/analýza aktivity (na stůl, odstraněné n-tice/stránky)
- Zámky
- Dotazy (podle typu/databáze/uživatele/hostitele/aplikace, trvání podle uživatele)
- Nejvyšší (Dotazy:nejpomalejší, časově náročné, častější, normalizované nejpomalejší)
- Události (chyby, varování, fatální události atd.)
Obrazovka zobrazující relace vypadá takto:
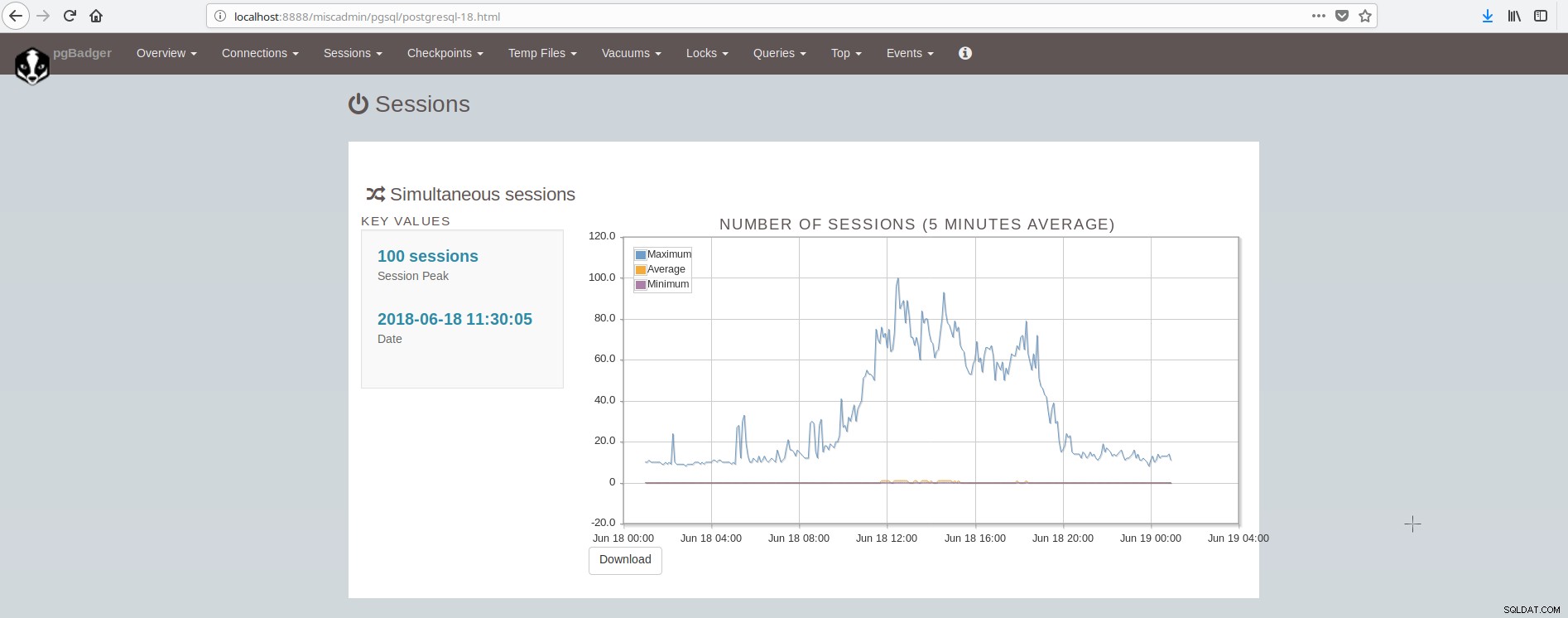
Jak můžeme shrnout, průměrná instalace PostgreSQL musí integrovat a starat se o mnoho nástrojů, aby měla moderní spolehlivou a rychlou infrastrukturu, a to je poměrně složité dosáhnout, pokud nejsou velké týmy zapojené do postgresql a správy systému. Výborná sada, která umí vše výše uvedené a ještě více, je ClusterControl.