Úvod
Bez ohledu na databázovou technologii je nutné mít nastavené monitorování, a to jak pro detekci problémů, tak pro přijetí opatření, nebo jednoduše pro znalost aktuálního stavu našich systémů.
K tomuto účelu existuje několik nástrojů, placených i bezplatných. V tomto blogu se zaměříme na jeden konkrétní:Nagios Core.
Co je Nagios Core?
Nagios Core je Open Source systém pro monitorování hostitelů, sítí a služeb. Umožňuje konfigurovat výstrahy a má pro ně různé stavy. Umožňuje implementaci pluginů vyvinutých komunitou nebo nám dokonce umožňuje konfigurovat naše vlastní monitorovací skripty.
Jak nainstalovat Nagios?
Oficiální dokumentace nám ukazuje, jak nainstalovat Nagios Core na systémy CentOS nebo Ubuntu.
Podívejme se na příklad nezbytných kroků pro instalaci na CentOS 7.
Vyžadují se balíčky
[example@sqldat.com ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipStáhněte si Nagios Core, Nagios Plugins a NRPE
[example@sqldat.com ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzPřidat uživatele a skupinu Nagios
[example@sqldat.com ~]# useradd nagios
[example@sqldat.com ~]# groupadd nagcmd
[example@sqldat.com ~]# usermod -a -G nagcmd nagios
[example@sqldat.com ~]# usermod -a -G nagios,nagcmd apacheInstalace Nagios
[example@sqldat.com ~]# tar zxvf nagios-4.4.2.tar.gz
[example@sqldat.com ~]# cd nagios-4.4.2
[example@sqldat.com nagios-4.4.2]# ./configure --with-command-group=nagcmd
[example@sqldat.com nagios-4.4.2]# make all
[example@sqldat.com nagios-4.4.2]# make install
[example@sqldat.com nagios-4.4.2]# make install-init
[example@sqldat.com nagios-4.4.2]# make install-config
[example@sqldat.com nagios-4.4.2]# make install-commandmode
[example@sqldat.com nagios-4.4.2]# make install-webconf
[example@sqldat.com nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[example@sqldat.com nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[example@sqldat.com nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgNagios Plugin a instalace NRPE
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com ~]# yum install epel-release
[example@sqldat.com ~]# yum install nagios-plugins-nrpe
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-pluginNa konec našeho souboru /usr/local/nagios/etc/objects/command.cfg přidáváme následující řádek, abychom při kontrole našich serverů použili NRPE:
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Nagios začíná
[example@sqldat.com nagios-4.4.2]# systemctl start nagios
[example@sqldat.com nagios-4.4.2]# systemctl start httpdPřístup na web
Vytvoříme uživatele pro přístup k webovému rozhraní a můžeme vstoupit na web.
[example@sqldat.com nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttps://IP_Address/nagios/
 Nagios Web Access
Nagios Web Access Jak nakonfigurovat Nagios?
Nyní, když máme náš Nagios nainstalovaný, můžeme pokračovat v konfiguraci. K tomu musíme přejít do umístění odpovídající naší instalaci, v našem příkladu /usr/local/nagios/etc.
Existuje několik různých konfiguračních souborů, které budete muset vytvořit nebo upravit, než začnete cokoliv monitorovat.
[example@sqldat.com etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg: Konfigurační soubor CGI obsahuje řadu direktiv, které ovlivňují činnost CGI. Obsahuje také odkaz na hlavní konfigurační soubor, takže CGI vědí, jak jste nakonfigurovali Nagios a kde jsou uloženy definice vašich objektů.
- htpasswd.users: Tento soubor obsahuje uživatele vytvořené pro přístup k webovému rozhraní Nagios.
- nagios.cfg: Hlavní konfigurační soubor obsahuje řadu direktiv, které ovlivňují fungování démona Nagios Core.
- objekty: Při instalaci Nagios je zde umístěno několik ukázkových konfiguračních souborů objektů. Pomocí těchto ukázkových souborů můžete vidět, jak funguje dědění objektů, a naučit se, jak definovat vlastní definice objektů. Objekty jsou všechny prvky, které se podílejí na logice monitorování a oznámení.
- resource.cfg: Používá se k určení volitelného souboru prostředků, který může obsahovat definice maker. Makra vám umožňují odkazovat na informace o hostitelích, službách a dalších zdrojích ve vašich příkazech.
V rámci objektů najdeme šablony, které lze použít při vytváření nových objektů. Například můžeme vidět, že v našem souboru /usr/local/nagios/etc/objects/templates.cfg je šablona nazvaná linux-server, která bude použita k přidání našich serverů.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}Pomocí této šablony naši hostitelé zdědí konfiguraci, aniž by je museli zadávat jednoho po druhém na každém serveru, který přidáme.
Máme také předdefinované příkazy, kontakty a časové úseky.
Příkazy bude Nagios používat pro své kontroly, a to je to, co přidáváme do konfiguračního souboru každého serveru, abychom to mohli sledovat. Například PING:
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}Máme možnost vytvořit kontakty nebo skupiny a určit, která upozornění chci zasílat které osobě nebo skupině.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email example@sqldat.com ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}Pro naše kontroly a upozornění můžeme nakonfigurovat, v kolik hodin a dnů je chceme dostávat. Pokud máme službu, která není kritická, pravděpodobně se nechceme probouzet za svítání, takže by bylo dobré varovat pouze v pracovní době, aby se tomu zabránilo.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Podívejme se nyní, jak přidat upozornění do našeho Nagios.
Budeme monitorovat naše PostgreSQL servery, takže je nejprve přidáme jako hostitele do našeho adresáře objektů. Vytvoříme 3 nové soubory:
[example@sqldat.com ~]# cd /usr/local/nagios/etc/objects/
[example@sqldat.com objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[example@sqldat.com objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[example@sqldat.com objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}Poté je musíme přidat do souboru nagios.cfg a zde máme 2 možnosti.
Přidejte naše hostitele (soubory cfg) jeden po druhém pomocí proměnné cfg_file (výchozí možnost) nebo přidejte všechny soubory cfg, které máme v adresáři, pomocí proměnné cfg_dir.
Budeme přidávat soubory jeden po druhém podle výchozí strategie.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgDíky tomu máme naše hostitele monitorované. Teď už jen zbývá přidat, jaké služby chceme monitorovat. K tomu použijeme některé již definované kontroly (check_ssh a check_ping) a přidáme některé základní kontroly operačního systému, jako je zatížení a místo na disku, mimo jiné pomocí NRPE.
Stáhněte si Whitepaper Today Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si WhitepaperCo je NRPE?
Nagios Remote Plugin Executor. Tento nástroj nám umožňuje spouštět pluginy Nagios na vzdáleném hostiteli co nejtransparentnějším způsobem.
Abychom jej mohli používat, musíme nainstalovat server do každého uzlu, který chceme monitorovat, a náš Nagios se ke každému z nich připojí jako klient a spustí odpovídající plugin(y).
Jak nainstalovat NRPE?
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-groups-users
[example@sqldat.com nrpe-3.2.1]# make install
[example@sqldat.com nrpe-3.2.1]# make install-config
[example@sqldat.com nrpe-3.2.1]# make install-init
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com nagios-plugins-2.2.1]# systemctl enable nrpePoté upravíme konfigurační soubor /usr/local/nagios/etc/nrpe.cfg
server_address=<Local IP Address>
allowed_hosts=127.0.0.1,<Nagios Server IP Address>A restartujeme službu NRPE:
[example@sqldat.com ~]# systemctl restart nrpePřipojení můžeme otestovat spuštěním následujícího z našeho serveru Nagios:
[example@sqldat.com ~]# /usr/local/nagios/libexec/check_nrpe -H <Node IP Address>
NRPE v3.2.1Jak monitorovat PostgreSQL?
Při monitorování PostgreSQL je třeba vzít v úvahu dvě hlavní oblasti:operační systém a databáze.
Pro operační systém má NRPE nakonfigurované některé základní kontroly, jako je mimo jiné místo na disku a zatížení. Tyto kontroly lze velmi snadno aktivovat následujícím způsobem.
V našich uzlech upravíme soubor /usr/local/nagios/etc/nrpe.cfg a přejdeme na následující řádky:
command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200Názvy v hranatých závorkách jsou názvy, které použijeme na našem serveru Nagios k povolení těchto kontrol.
V našem Nagios upravujeme soubory 3 uzlů:
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgPřidáme tyto kontroly, které jsme viděli dříve, a ponecháme naše soubory takto:
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}A restartujeme službu nagios:
[example@sqldat.com ~]# systemctl start nagiosV tuto chvíli, pokud přejdeme do sekce služeb ve webovém rozhraní našeho Nagios, měli bychom mít něco jako následující:
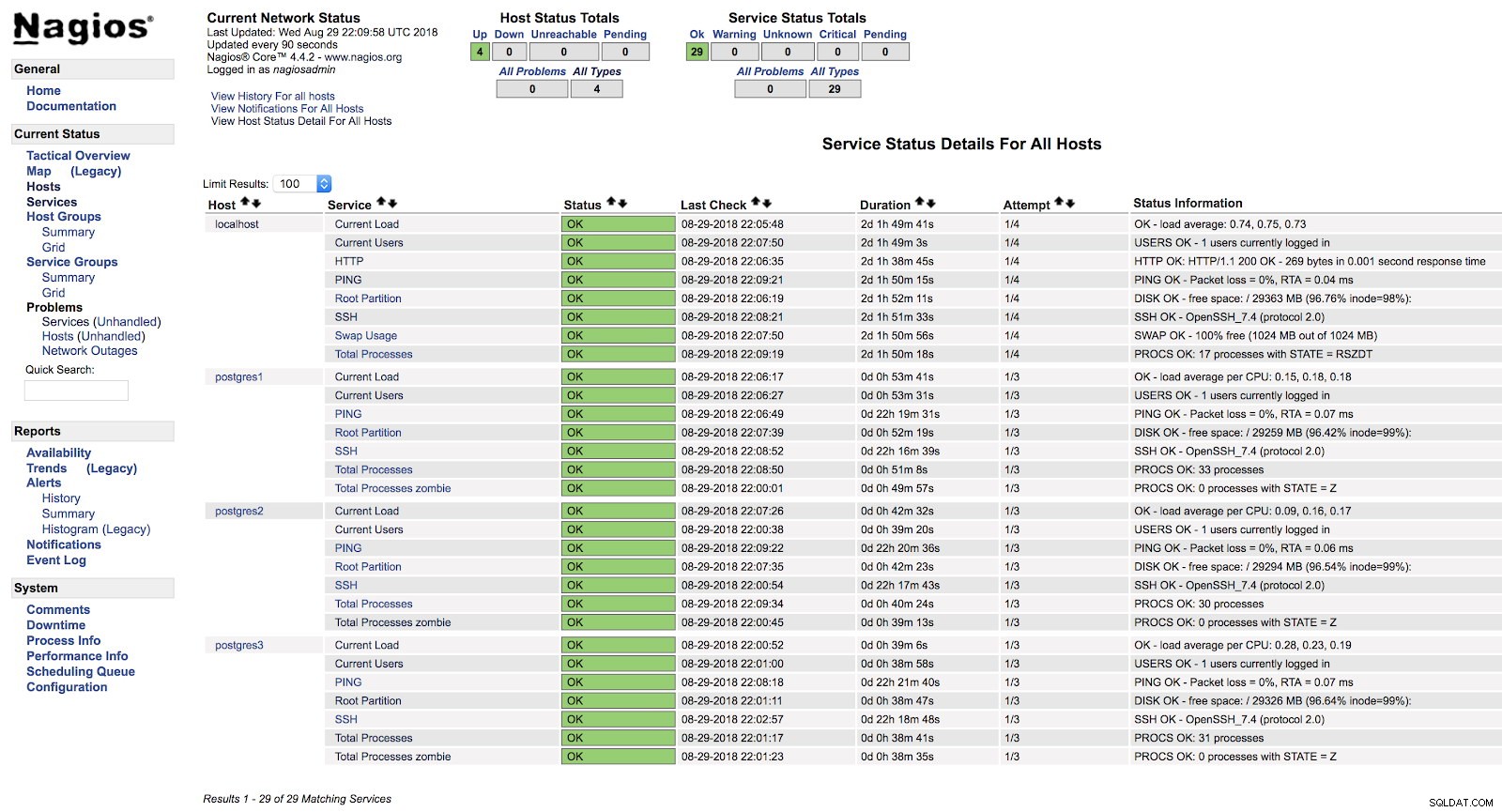 Upozornění hostitele Nagios
Upozornění hostitele Nagios Tímto způsobem pokryjeme základní kontroly našeho serveru na úrovni operačního systému.
Máme mnohem více kontrol, které můžeme přidat, a můžeme dokonce vytvořit vlastní kontroly (uvidíme příklad později).
Nyní se podívejme, jak monitorovat náš databázový stroj PostgreSQL pomocí dvou hlavních pluginů navržených pro tento úkol.
Check_postgres
Jeden z nejpopulárnějších pluginů pro kontrolu PostgreSQL je check_postgres od Bucardo.
Podívejme se, jak ji nainstalovat a jak ji používat s naší PostgreSQL databází.
Vyžadují se balíčky
[example@sqldat.com ~]# yum install perl-develInstalace
[example@sqldat.com ~]# wget https://bucardo.org/downloads/check_postgres.tar.gz
[example@sqldat.com ~]# tar zxvf check_postgres.tar.gz
[example@sqldat.com ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[example@sqldat.com ~]# cd /usr/local/nagios/libexec/
[example@sqldat.com libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksTento poslední příkaz vytváří odkazy pro použití všech funkcí této kontroly, jako je mimo jiné check_postgres_connection, check_postgres_last_vacuum nebo check_postgres_replication_slots.
[example@sqldat.com libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…Do našeho konfiguračního souboru NRPE (/usr/local/nagios/etc/nrpe.cfg) přidáme řádek pro provedení kontroly, kterou chceme použít:
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100V našem příkladu jsme přidali 4 základní kontroly pro PostgreSQL. Budeme monitorovat Locks, Bloat, Connection a Backends.
Do souboru odpovídající naší databázi na serveru Nagios (/usr/local/nagios/etc/objects/postgres1.cfg) přidáme následující položky:
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}A po restartu obou služeb (NRPE a Nagios) na obou serverech můžeme vidět, že jsou naše výstrahy nakonfigurované.
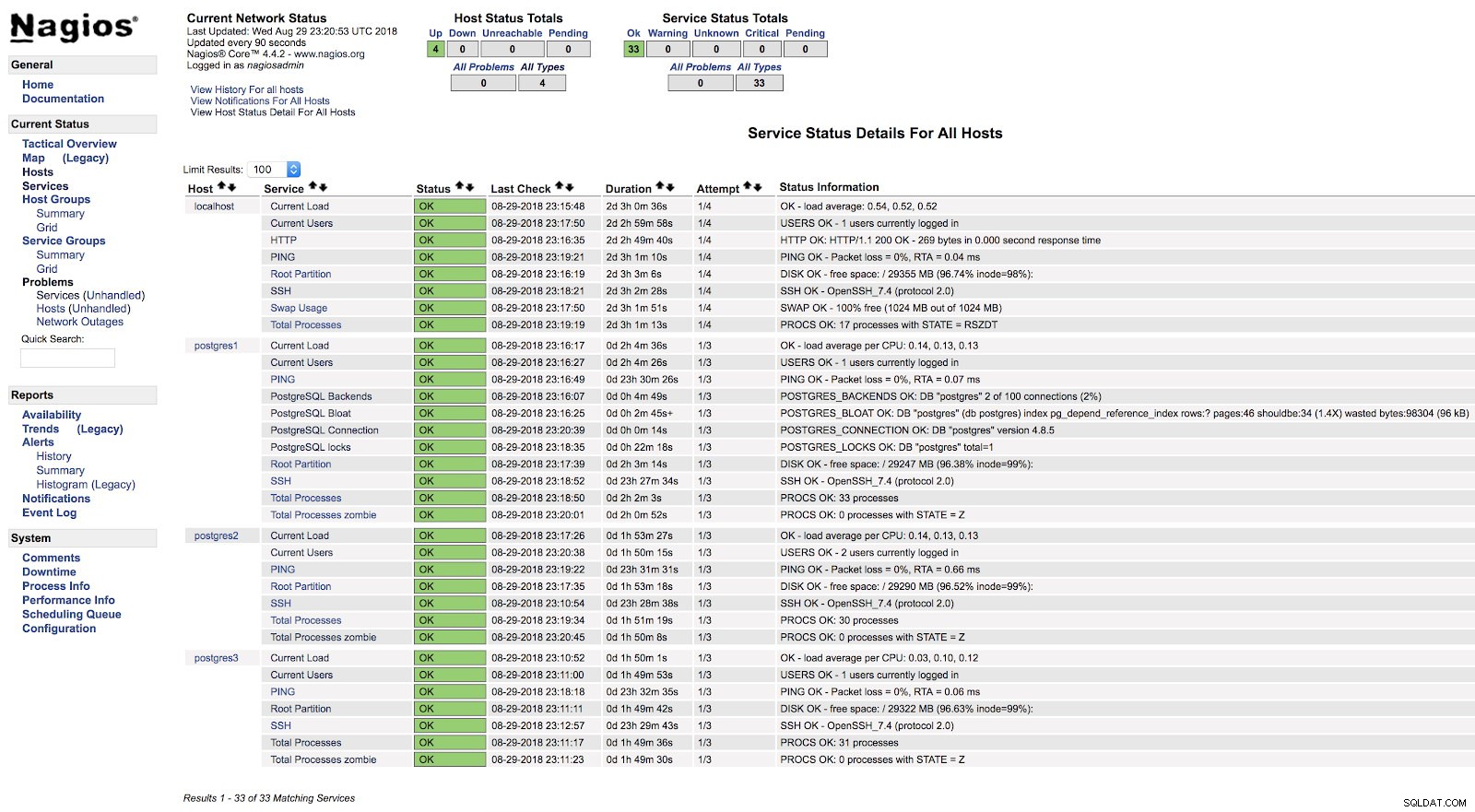 Nagios check_postgres Alerts
Nagios check_postgres Alerts V oficiální dokumentaci pluginu check_postgres najdete informace o tom, co ještě sledovat a jak to udělat.
Check_pgactivity
Nyní je řada na check_pgactivity, také populární pro monitorování naší PostgreSQL databáze.
Instalace
[example@sqldat.com ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[example@sqldat.com ~]# tar zxvf check_pgactivity-2.3.tgz
[example@sqldat.com ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityDo našeho konfiguračního souboru NRPE (/usr/local/nagios/etc/nrpe.cfg) přidáme řádek pro provedení kontroly, kterou chceme použít:
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10V našem příkladu přidáme 4 základní kontroly pro PostgreSQL. Budeme monitorovat backendy, připojení, neplatné indexy a zámky.
Do souboru odpovídající naší databázi na serveru Nagios (/usr/local/nagios/etc/objects/postgres2.cfg) přidáme následující položky:
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}A po restartu obou služeb (NRPE a Nagios) na obou serverech můžeme vidět, že jsou naše výstrahy nakonfigurované.
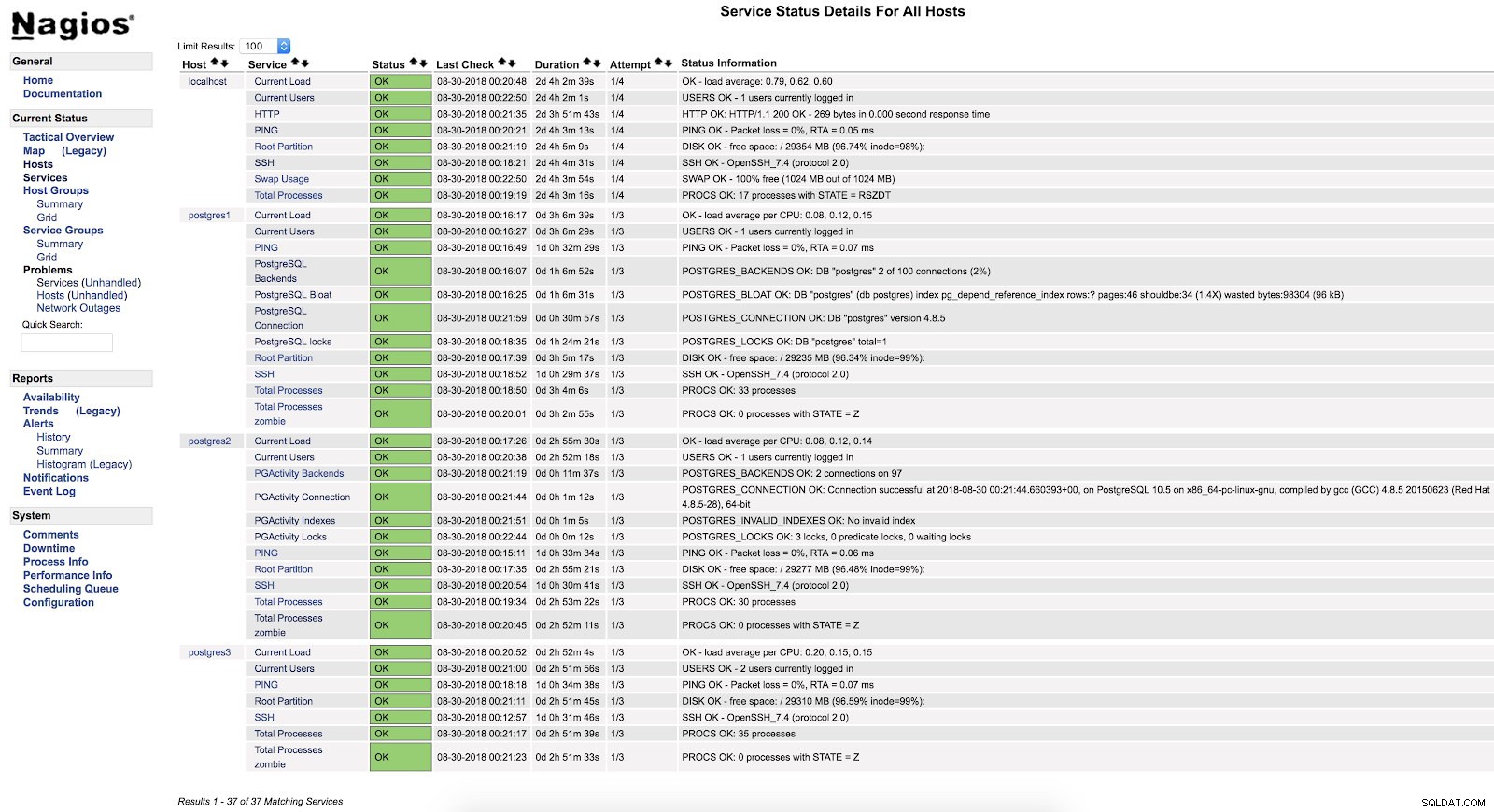 Upozornění Nagios check_pgactivity
Upozornění Nagios check_pgactivity Zkontrolujte protokol chyb
Jednou z nejdůležitějších nebo nejdůležitějších kontrol je kontrola našeho protokolu chyb.
Zde můžeme najít různé typy chyb, jako je FATAL nebo uváznutí, a je to dobrý výchozí bod pro analýzu jakéhokoli problému, který máme v naší databázi.
Abychom zkontrolovali náš protokol chyb, vytvoříme vlastní monitorovací skript a začleníme jej do našeho Nagios (toto je pouze příklad, tento skript bude základní a má spoustu prostoru pro vylepšení).
Skript
Na našem PostgreSQL3 serveru vytvoříme soubor /usr/local/nagios/libexec/check_postgres_log.sh.
[example@sqldat.com ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiDůležité u skriptu je správně vytvořit výstupy odpovídající každému stavu. Tyto výstupy čte Nagios a každé číslo odpovídá stavu:
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNV našem příkladu použijeme pouze 2 stavy, OK a KRITICKÉ, protože nás zajímá pouze to, zda jsou v našem protokolu chyb v aktuální hodině chyby typu FATAL.
Text, který použijeme před naším odchodem, se zobrazí ve webovém rozhraní našeho Nagios, takže by mělo být co nejsrozumitelnější, abychom jej mohli použít jako průvodce problémem.
Jakmile dokončíme náš monitorovací skript, přistoupíme k tomu, že mu udělíme oprávnění ke spuštění, přiřadíme jej uživateli nagios a přidáme jej na náš databázový server NRPE a také do našeho Nagios:
[example@sqldat.com ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Restartujte NRPE a Nagios. Poté můžeme vidět naši kontrolu v rozhraní Nagios:
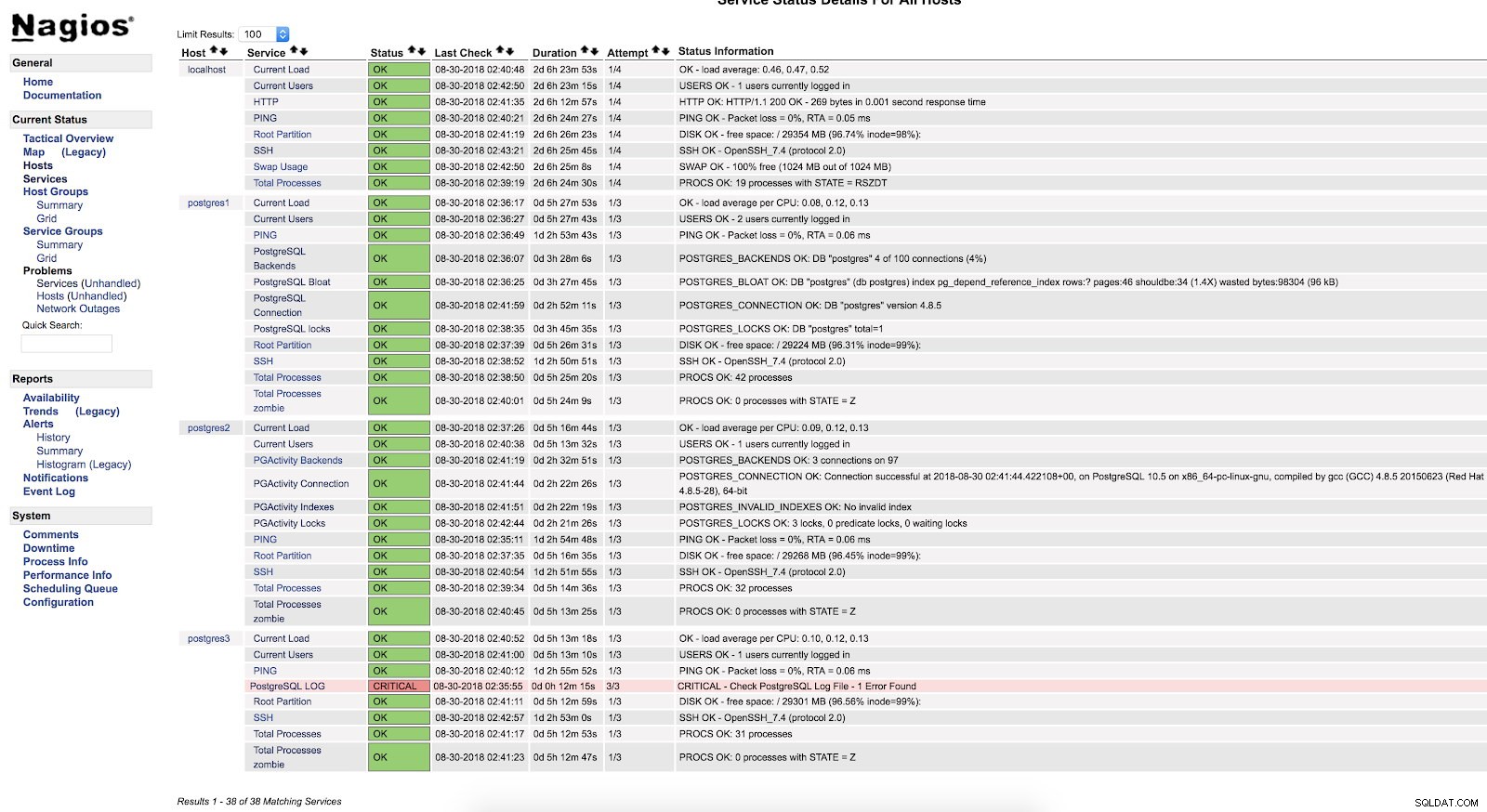 Upozornění skriptu Nagios
Upozornění skriptu Nagios Jak vidíme, je v KRITICKÉM stavu, takže pokud přejdeme do protokolu, můžeme vidět následující:
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"Pro více informací o tom, co můžeme sledovat v naší databázi PostgreSQL, vám doporučuji navštívit naše blogy o výkonu a monitorování nebo tento webinář Postgres Performance.
Bezpečnost a výkon
Při konfiguraci jakéhokoli monitorování, ať už pomocí pluginů nebo vlastního skriptu, musíme být velmi opatrní se 2 velmi důležitými věcmi – bezpečnost a výkon.
Když přidělujeme nezbytná oprávnění pro monitorování, musíme být co nejpřísnější, omezovat přístup pouze lokálně nebo z našeho monitorovacího serveru, používat zabezpečené klíče, šifrovat provoz a umožnit připojení na minimum nezbytné pro fungování monitorování.
S ohledem na výkon je monitoring nezbytný, ale je také nutné jej bezpečně používat pro naše systémy.
Musíme být opatrní, abychom negenerovali nepřiměřeně vysoký přístup k disku nebo nespouštěli dotazy, které negativně ovlivňují výkon naší databáze.
Pokud máme mnoho transakcí za sekundu generujících gigabajty protokolů a neustále hledáme chyby, pravděpodobně to není pro naši databázi to nejlepší. Musíme tedy udržovat rovnováhu mezi tím, co monitorujeme, jak často a dopadem na výkon.
Závěr
Existuje několik způsobů, jak implementovat monitorování nebo jej nakonfigurovat. Můžeme to udělat tak složitě nebo jednoduše, jak chceme. Cílem tohoto blogu bylo seznámit vás s monitorováním PostgreSQL pomocí jednoho z nejpoužívanějších open source nástrojů. Také jsme viděli, že konfigurace je velmi flexibilní a lze ji přizpůsobit různým potřebám.
A nezapomeňte, že se na komunitu můžeme vždy spolehnout, takže zanechám několik odkazů, které by mohly být velkou pomocí.
Fórum podpory:https://support.nagios.com/forum/
Známé problémy:https://github.com/NagiosEnterprises/nagioscore/issues
Pluginy Nagios:https://exchange.nagios.org/directory/Plugins
Nagios Plugin pro ClusterControl:https://severalnines.com/blog/nagios-plugin-clustercontrol