Tento blog zahajuje vícesérii dokumentující mou cestu při srovnávání PostgreSQL v cloudu.
První část obsahuje přehled nástrojů pro srovnávání a nastartuje zábavu s Amazon Aurora PostgreSQL.
Výběr poskytovatelů cloudových služeb PostgreSQL
Před chvílí jsem narazil na postup benchmarku AWS pro Auroru a řekl jsem si, že by bylo opravdu skvělé, kdybych mohl tento test provést a spustit na jiných poskytovatelích cloudového hostingu. Ke cti Amazonu je třeba přiznat, že ze tří nejznámějších poskytovatelů výpočetní techniky – AWS, Google a Microsoft – je AWS jediným hlavním přispěvatelem k vývoji PostgreSQL a prvním, kdo nabízí spravovanou službu PostgreSQL (z listopadu 2013).
I když jsou spravované služby PostgreSQL dostupné také od velkého množství poskytovatelů hostingu PostgreSQL, chtěl jsem se zaměřit na uvedené tři poskytovatele cloud computingu, protože v jejich prostředí se mnoho organizací, které hledají výhody cloud computingu, rozhodlo provozovat své aplikace za předpokladu, že mají požadované know-how o správě PostgreSQL. Pevně věřím, že v dnešním prostředí IT by organizace pracující s kritickými zátěžemi v cloudu velmi těžily ze služeb specializovaného poskytovatele služeb PostgreSQL, který jim může pomoci orientovat se ve složitém světě GUCS a nesčetných prezentacích SlideShare.
Výběr správného nástroje Benchmark
Benchmarking PostgreSQL se poměrně často objevuje na výkonnostním mailing listu, a jak bylo mnohokrát zdůrazněno, testy nejsou určeny k ověření konfigurace pro reálnou aplikaci. Výběr správného benchmarkového nástroje a parametrů je však důležitý pro získání smysluplných výsledků. Očekával bych, že každý poskytovatel cloudu poskytne postupy pro srovnávání svých služeb, zvláště když první zkušenost s cloudem nemusí začít tou správnou nohou. Dobrou zprávou je, že dva ze tří hráčů v tomto testu zahrnuli benchmarky do své dokumentace. Průvodce AWS Benchmark Procedure pro Auroru lze snadno najít a je k dispozici přímo na stránce Amazon Aurora Resources. Google neposkytuje průvodce specifickým pro PostgreSQL, nicméně dokumentace Compute Engine obsahuje průvodce zátěžovým testováním pro SQL Server založený na HammerDB.
Následuje shrnutí benchmarkových nástrojů na základě jejich referencí, na které stojí za to se podívat:
- Výše zmíněný AWS Benchmark je založen na pgbench a sysbench.
- HammerDB, také zmíněný dříve, je diskutován v nedávném příspěvku na seznamu pgsql-hackers.
- TPC-C testy založené na oltpbench, jak bylo zmíněno v této další diskuzi o pgsql-hackery.
- benchmarksql je další test TPC-C, který byl použit k ověření změn v rozdělení stránek B-Strom.
- pg_ycsb je nové dítě ve městě, které vylepšuje pgbench a již ho používají někteří hackeři PostgreSQL.
- pgbench-tools, jak název napovídá, je založen na pgbench, a přestože od roku 2016 neobdržel žádné aktualizace, je produktem Grega Smithe, autora knih PostgreSQL High Performance.
- Srovnávací test objednávky spojení je srovnávací test, který otestuje optimalizátor dotazů.
- pgreplay, na který jsem narazil při čtení blogu příkazového řádku, je tak blízko, jak jen to může být, k porovnání scénáře ze skutečného života.
Dalším bodem, který je třeba poznamenat, je, že PostgreSQL se zatím příliš nehodí pro standard benchmarku TPC-H, a jak bylo uvedeno výše, všechny nástroje (kromě pgreplay) musí být spouštěny v režimu TPC-C (výchozí je pgbench).
Pro účely tohoto blogu jsem si myslel, že postup AWS Benchmark pro Auroru je dobrým začátkem jednoduše proto, že nastavuje standard pro poskytovatele cloudu a je založen na široce používaných nástrojích.
Také jsem v té době používal nejnovější dostupnou verzi PostgreSQL. Při výběru poskytovatele cloudu je důležité vzít v úvahu frekvenci upgradů, zvláště když důležité funkce zavedené novými verzemi mohou ovlivnit výkon (což je případ verzí 10 a 11 oproti 9). V době psaní tohoto článku máme:
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS pro PostgreSQL 10.6
- Google Cloud SQL pro PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
...a vítězem je zde AWS tím, že nabízí nejnovější verzi (ačkoli není nejnovější, což je v době psaní tohoto článku 11.2).
Nastavení prostředí pro srovnávání
Rozhodl jsem se omezit své testy na průměrnou zátěž z několika důvodů:Za prvé, dostupné cloudové zdroje nejsou u poskytovatelů totožné. V průvodci jsou specifikace AWS pro instanci databáze 64 vCPU / 488 GiB RAM / 25 Gigabit Network, zatímco maximální RAM společnosti Google pro jakoukoli velikost instance (výběr musí být nastaven na „vlastní“ v kalkulačce Google) je 208 GiB, a Microsoft Business Critical Gen5 s 32 vCPU přichází s pouze 163 GiB). Za druhé, inicializace pgbench zvýší velikost databáze na 160GiB, což v případě instance s 488 GiB RAM bude pravděpodobně uloženo v paměti.
Také jsem nechal konfiguraci PostgreSQL nedotčenou. Důvodem, proč se držet výchozích hodnot poskytovatele cloudu, je to, že se očekává, že spravovaná služba bude fungovat přiměřeně dobře, když je zdůrazněna standardním benchmarkem. Pamatujte, že komunita PostgreSQL spouští testy pgbench jako součást procesu správy vydání. Průvodce AWS navíc nezmiňuje žádné změny výchozí konfigurace PostgreSQL.
Jak je vysvětleno v průvodci, AWS aplikovalo dvě opravy na pgbench. Vzhledem k tomu, že oprava počtu klientů se na verzi PostgreSQL 10.6 neaplikovala čistě a nechtěl jsem investovat čas do její opravy, byl počet klientů omezen na maximum 1 000.
Průvodce specifikuje požadavek, aby instance klienta měla povoleno rozšířené síťové připojení – pro tento typ instance je to výchozí:
[example@sqldat.com ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 0a:cd:ee:40:2b:e6 brd ff:ff:ff:ff:ff:ff
inet 172.31.19.190/20 brd 172.31.31.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8cd:eeff:fe40:2be6/64 scope link
valid_lft forever preferred_lft forever
[example@sqldat.com ~]$ ethtool -i eth0
driver: ena
version: 2.0.2g
firmware-version:
bus-info: 0000:00:03.0
supports-statistics: yes
supports-test: no
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: no
>>> aws (master *%) ~ $ aws ec2 describe-instances --instance-ids i-0ee51642334c1ec57 --query "Reservations[].Instances[].EnaSupport"
[
true
]Spuštění Benchmarku na Amazon Aurora PostgreSQL
Během samotného běhu jsem se rozhodl udělat ještě jednu odchylku od průvodce:místo běhu testu na 1 hodinu nastavte časový limit na 10 minut, což je obecně akceptováno jako dobrá hodnota.
Spustit #1
Specifika
- Tento test používá specifikace AWS pro velikosti instancí klienta i databáze.
- Klientský počítač:Instance EC2 optimalizovaná pro paměť na vyžádání:
- vCPU:32 (16 jader x 2 vlákna/jádro)
- RAM:244 GiB
- Úložiště:Optimalizováno EBS
- Síť:10 Gigabit
- DB Cluster:db.r4.16xlarge
- vCPU:64
- ECU (kapacita CPU):195 x [1,0–1,2 GHz] Opteron / Xeon 2007
- RAM:488 GiB
- Úložiště:Optimalizováno EBS (vyhrazená kapacita pro I/O)
- Síť:14 000 Mbps maximální šířka pásma v síti 25 Gps
- Klientský počítač:Instance EC2 optimalizovaná pro paměť na vyžádání:
- Nastavení databáze zahrnovalo jednu repliku.
- Úložiště databáze nebylo zašifrováno.
Provádění testů a výsledků
- Při instalaci pgbench a sysbench postupujte podle pokynů v příručce.
- Upravte ~/.bashrc pro nastavení proměnných prostředí pro připojení k databázi a požadované cesty ke knihovnám PostgreSQL:
export PGHOST=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com export PGUSER=postgres export PGPASSWORD=postgres export PGDATABASE=postgres export PATH=$PATH:/usr/local/pgsql/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib - Inicializujte databázi:
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.05 s, remaining 457.23 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 631.70 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 688.29 s) ... 999500000 of 1000000000 tuples (99%) done (elapsed 811.41 s, remaining 0.41 s) 999600000 of 1000000000 tuples (99%) done (elapsed 811.50 s, remaining 0.32 s) 999700000 of 1000000000 tuples (99%) done (elapsed 811.58 s, remaining 0.24 s) 999800000 of 1000000000 tuples (99%) done (elapsed 811.65 s, remaining 0.16 s) 999900000 of 1000000000 tuples (99%) done (elapsed 811.73 s, remaining 0.08 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 811.80 s, remaining 0.00 s) vacuum... set primary keys... done. - Ověřte velikost databáze:
postgres=> \l+ postgres List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description ----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------------------------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 160 GB | pg_default | default administrative connection database (1 row) - Pomocí následujícího dotazu ověřte, že časový interval mezi kontrolními body je nastaven, takže kontrolní body budou během 10minutového běhu vynuceny:
Výsledek:SELECT total_checkpoints, seconds_since_start / total_checkpoints / 60 AS minutes_between_checkpoints FROM ( SELECT EXTRACT( EPOCH FROM ( now() - pg_postmaster_start_time() ) ) AS seconds_since_start, (checkpoints_timed+checkpoints_req) AS total_checkpoints FROM pg_stat_bgwriter) AS sub;postgres=> \e total_checkpoints | minutes_between_checkpoints -------------------+----------------------------- 50 | 0.977392292333333 (1 row) - Spusťte pracovní zátěž čtení/zápis:
Výstup[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048starting vacuum...end. progress: 60.0 s, 35670.3 tps, lat 27.243 ms stddev 10.915 progress: 120.0 s, 36569.5 tps, lat 27.352 ms stddev 11.859 progress: 180.0 s, 35845.2 tps, lat 27.896 ms stddev 12.785 progress: 240.0 s, 36613.7 tps, lat 27.310 ms stddev 11.804 progress: 300.0 s, 37323.4 tps, lat 26.793 ms stddev 11.376 progress: 360.0 s, 36828.8 tps, lat 27.155 ms stddev 11.318 progress: 420.0 s, 36670.7 tps, lat 27.268 ms stddev 12.083 progress: 480.0 s, 37176.1 tps, lat 26.899 ms stddev 10.981 progress: 540.0 s, 37210.8 tps, lat 26.875 ms stddev 11.341 progress: 600.0 s, 37415.4 tps, lat 26.727 ms stddev 11.521 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 22040445 latency average = 27.149 ms latency stddev = 11.617 ms tps = 36710.828624 (including connections establishing) tps = 36811.054851 (excluding connections establishing) - Připravte test sysbench:
Výstup:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250\ --oltp-table-size=450000 \ preparesysbench 0.5: multi-threaded system evaluation benchmark Creating table 'sbtest1'... Inserting 450000 records into 'sbtest1' Creating secondary indexes on 'sbtest1'... Creating table 'sbtest2'... ... Creating table 'sbtest250'... Inserting 450000 records into 'sbtest250' Creating secondary indexes on 'sbtest250'... - Spusťte test sysbench:
Výstup:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250 \ --oltp-table-size=450000 \ --max-requests=0 \ --forced-shutdown \ --report-interval=60 \ --oltp_simple_ranges=0 \ --oltp-distinct-ranges=0 \ --oltp-sum-ranges=0 \ --oltp-order-ranges=0 \ --oltp-point-selects=0 \ --rand-type=uniform \ --max-time=600 \ --num-threads=1000 \ runsysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 20443.09, reads: 0.00, writes: 81834.16, response time: 68.24ms (95%), errors: 0.62, reconnects: 0.00 [ 120s] threads: 1000, tps: 20580.68, reads: 0.00, writes: 82324.33, response time: 70.75ms (95%), errors: 0.73, reconnects: 0.00 [ 180s] threads: 1000, tps: 20531.85, reads: 0.00, writes: 82127.21, response time: 70.63ms (95%), errors: 0.73, reconnects: 0.00 [ 240s] threads: 1000, tps: 20212.67, reads: 0.00, writes: 80861.67, response time: 71.99ms (95%), errors: 0.43, reconnects: 0.00 [ 300s] threads: 1000, tps: 19383.90, reads: 0.00, writes: 77537.87, response time: 75.64ms (95%), errors: 0.75, reconnects: 0.00 [ 360s] threads: 1000, tps: 19797.20, reads: 0.00, writes: 79190.78, response time: 75.27ms (95%), errors: 0.68, reconnects: 0.00 [ 420s] threads: 1000, tps: 20304.43, reads: 0.00, writes: 81212.87, response time: 73.82ms (95%), errors: 0.70, reconnects: 0.00 [ 480s] threads: 1000, tps: 20933.80, reads: 0.00, writes: 83737.16, response time: 74.71ms (95%), errors: 0.68, reconnects: 0.00 [ 540s] threads: 1000, tps: 20663.05, reads: 0.00, writes: 82626.42, response time: 73.56ms (95%), errors: 0.75, reconnects: 0.00 [ 600s] threads: 1000, tps: 20746.02, reads: 0.00, writes: 83015.81, response time: 73.58ms (95%), errors: 0.78, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 48868458 other: 24434022 total: 73302480 transactions: 12216804 (20359.59 per sec.) read/write requests: 48868458 (81440.43 per sec.) other operations: 24434022 (40719.87 per sec.) ignored errors: 414 (0.69 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0516s total number of events: 12216804 total time taken by event execution: 599964.4735s response time: min: 6.27ms avg: 49.11ms max: 350.24ms approx. 95 percentile: 72.90ms Threads fairness: events (avg/stddev): 12216.8040/31.27 execution time (avg/stddev): 599.9645/0.01
Shromážděné metriky
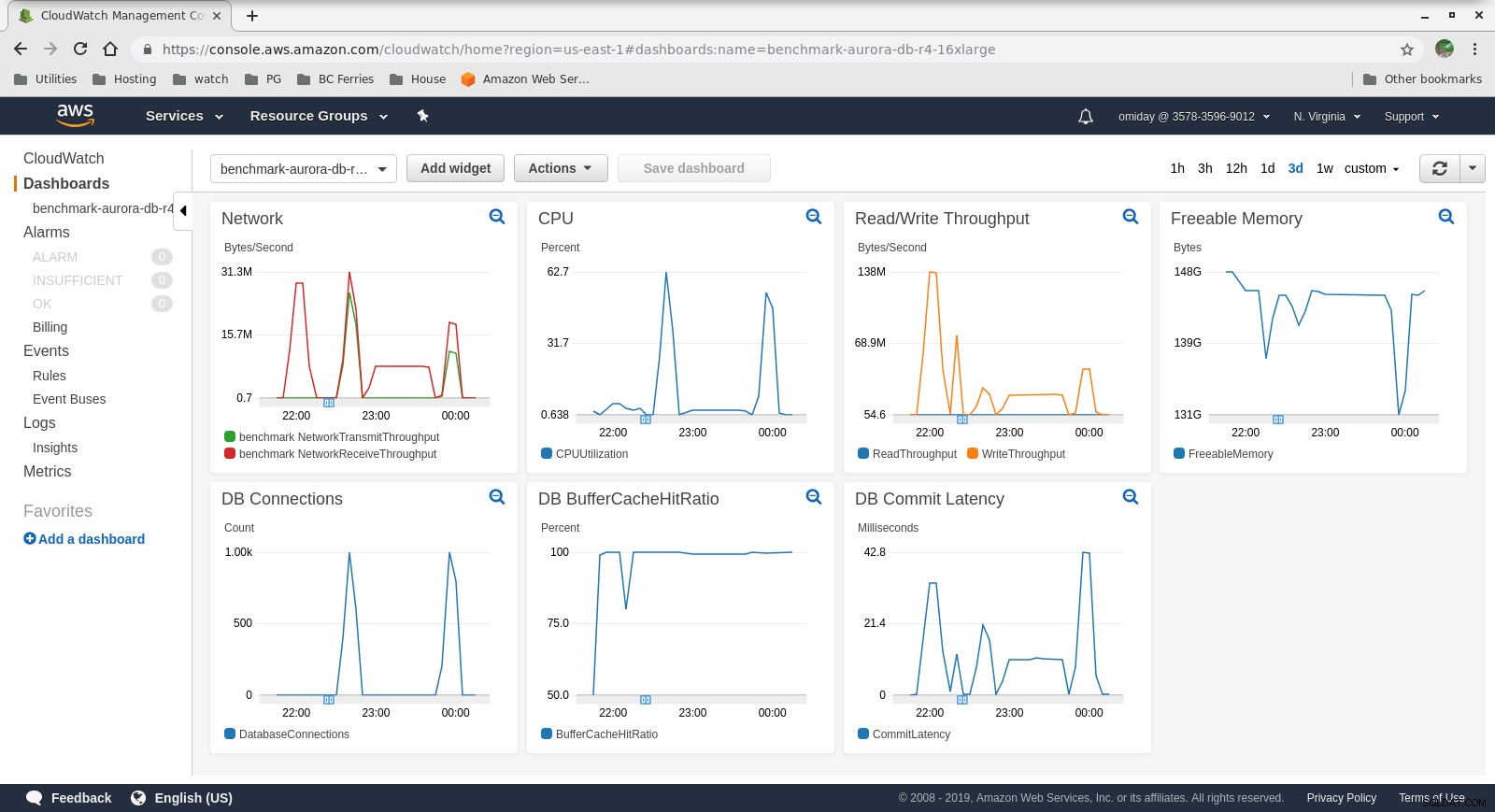 Metriky Cloudwatch
Metriky Cloudwatch 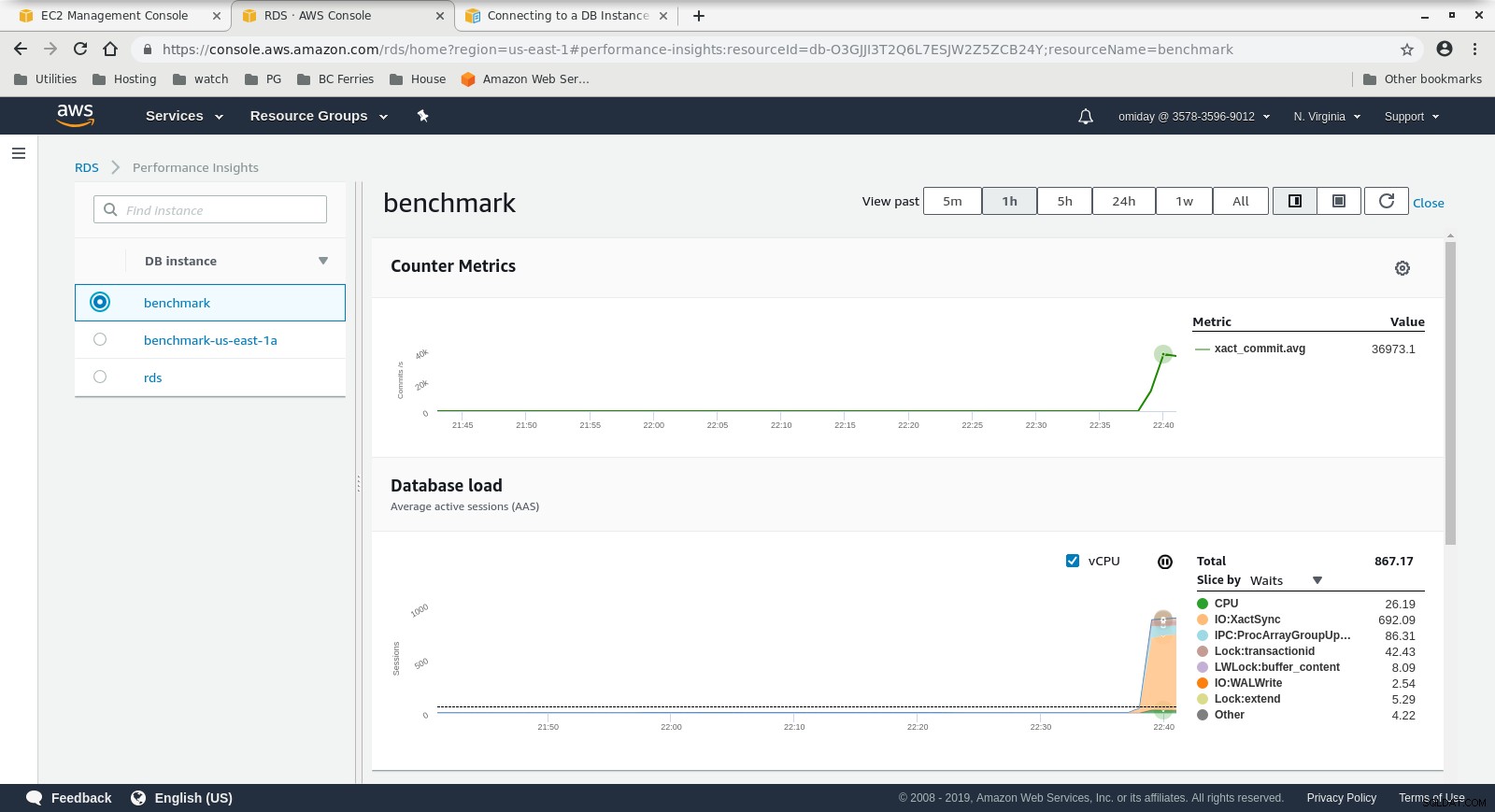 Metriky statistik výkonuStáhněte si dokument ještě dnes Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení spravovat a škálovat PostgreSQLStáhněte si dokument Whitepaper
Metriky statistik výkonuStáhněte si dokument ještě dnes Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení spravovat a škálovat PostgreSQLStáhněte si dokument Whitepaper Spustit #2
Specifika
- Tento test používá specifikace AWS pro klienta a menší velikost instance pro databázi:
- Klientský počítač:Instance EC2 optimalizovaná pro paměť na vyžádání:
- vCPU:32 (16 jader x 2 vlákna/jádro)
- RAM:244 GiB
- Úložiště:Optimalizováno EBS
- Síť:10 Gigabit
- DB Cluster:db.r4.2xlarge:
- vCPU:8
- RAM:61GiB
- Úložiště:Optimalizováno EBS
- Síť:maximální šířka pásma 1 750 Mb/s při připojení až 10 Gb/s
- Klientský počítač:Instance EC2 optimalizovaná pro paměť na vyžádání:
- Databáze neobsahovala repliku.
- Úložiště databáze nebylo zašifrováno.
Provádění testů a výsledků
Kroky jsou totožné s Run #1, takže zobrazujem pouze výstup:
-
pgbench Úloha čtení/zápisu:
... 745700000 of 1000000000 tuples (74%) done (elapsed 794.93 s, remaining 271.09 s) 745800000 of 1000000000 tuples (74%) done (elapsed 795.00 s, remaining 270.97 s) 745900000 of 1000000000 tuples (74%) done (elapsed 795.09 s, remaining 270.86 s) 746000000 of 1000000000 tuples (74%) done (elapsed 795.17 s, remaining 270.74 s) 746100000 of 1000000000 tuples (74%) done (elapsed 795.24 s, remaining 270.62 s) 746200000 of 1000000000 tuples (74%) done (elapsed 795.33 s, remaining 270.51 s) ... 999800000 of 1000000000 tuples (99%) done (elapsed 1067.11 s, remaining 0.21 s) 999900000 of 1000000000 tuples (99%) done (elapsed 1067.19 s, remaining 0.11 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 1067.28 s, remaining 0.00 s) vacuum... set primary keys... total time: 4386.44 s (insert 1067.33 s, commit 0.46 s, vacuum 2088.25 s, index 1230.41 s) done.starting vacuum...end. progress: 60.0 s, 3361.3 tps, lat 286.143 ms stddev 80.417 progress: 120.0 s, 3466.8 tps, lat 288.386 ms stddev 76.373 progress: 180.0 s, 3683.1 tps, lat 271.840 ms stddev 75.712 progress: 240.0 s, 3444.3 tps, lat 289.909 ms stddev 69.564 progress: 300.0 s, 3475.8 tps, lat 287.736 ms stddev 73.712 progress: 360.0 s, 3449.5 tps, lat 289.832 ms stddev 71.878 progress: 420.0 s, 3518.1 tps, lat 284.432 ms stddev 74.276 progress: 480.0 s, 3430.7 tps, lat 291.359 ms stddev 73.264 progress: 540.0 s, 3515.7 tps, lat 284.522 ms stddev 73.206 progress: 600.0 s, 3482.9 tps, lat 287.037 ms stddev 71.649 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 2090702 latency average = 286.030 ms latency stddev = 74.245 ms tps = 3481.731730 (including connections establishing) tps = 3494.157830 (excluding connections establishing) -
test sysbench:
sysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 4809.05, reads: 0.00, writes: 19301.02, response time: 288.03ms (95%), errors: 0.05, reconnects: 0.00 [ 120s] threads: 1000, tps: 5264.15, reads: 0.00, writes: 21005.40, response time: 255.23ms (95%), errors: 0.08, reconnects: 0.00 [ 180s] threads: 1000, tps: 5178.27, reads: 0.00, writes: 20713.07, response time: 260.40ms (95%), errors: 0.03, reconnects: 0.00 [ 240s] threads: 1000, tps: 5145.95, reads: 0.00, writes: 20610.08, response time: 255.76ms (95%), errors: 0.05, reconnects: 0.00 [ 300s] threads: 1000, tps: 5127.92, reads: 0.00, writes: 20507.98, response time: 264.24ms (95%), errors: 0.05, reconnects: 0.00 [ 360s] threads: 1000, tps: 5063.83, reads: 0.00, writes: 20278.10, response time: 268.55ms (95%), errors: 0.05, reconnects: 0.00 [ 420s] threads: 1000, tps: 5057.51, reads: 0.00, writes: 20237.28, response time: 269.19ms (95%), errors: 0.10, reconnects: 0.00 [ 480s] threads: 1000, tps: 5036.32, reads: 0.00, writes: 20139.29, response time: 279.62ms (95%), errors: 0.10, reconnects: 0.00 [ 540s] threads: 1000, tps: 5115.25, reads: 0.00, writes: 20459.05, response time: 264.64ms (95%), errors: 0.08, reconnects: 0.00 [ 600s] threads: 1000, tps: 5124.89, reads: 0.00, writes: 20510.07, response time: 265.43ms (95%), errors: 0.10, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 12225686 other: 6112822 total: 18338508 transactions: 3056390 (5093.75 per sec.) read/write requests: 12225686 (20375.20 per sec.) other operations: 6112822 (10187.57 per sec.) ignored errors: 42 (0.07 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0277s total number of events: 3056390 total time taken by event execution: 600005.2104s response time: min: 9.57ms avg: 196.31ms max: 608.70ms approx. 95 percentile: 268.71ms Threads fairness: events (avg/stddev): 3056.3900/67.44 execution time (avg/stddev): 600.0052/0.01
Shromážděné metriky
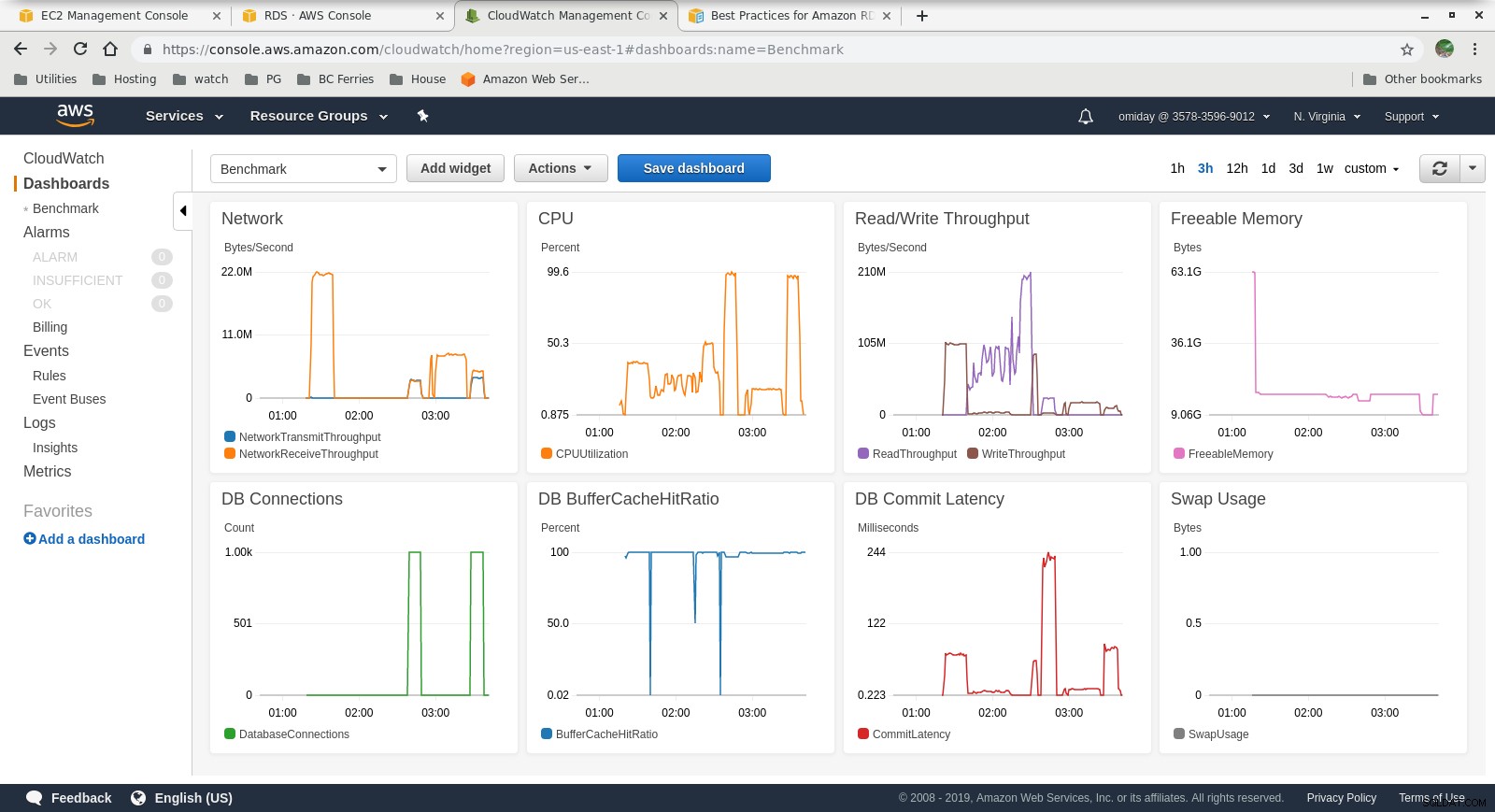 Metriky Cloudwatch
Metriky Cloudwatch 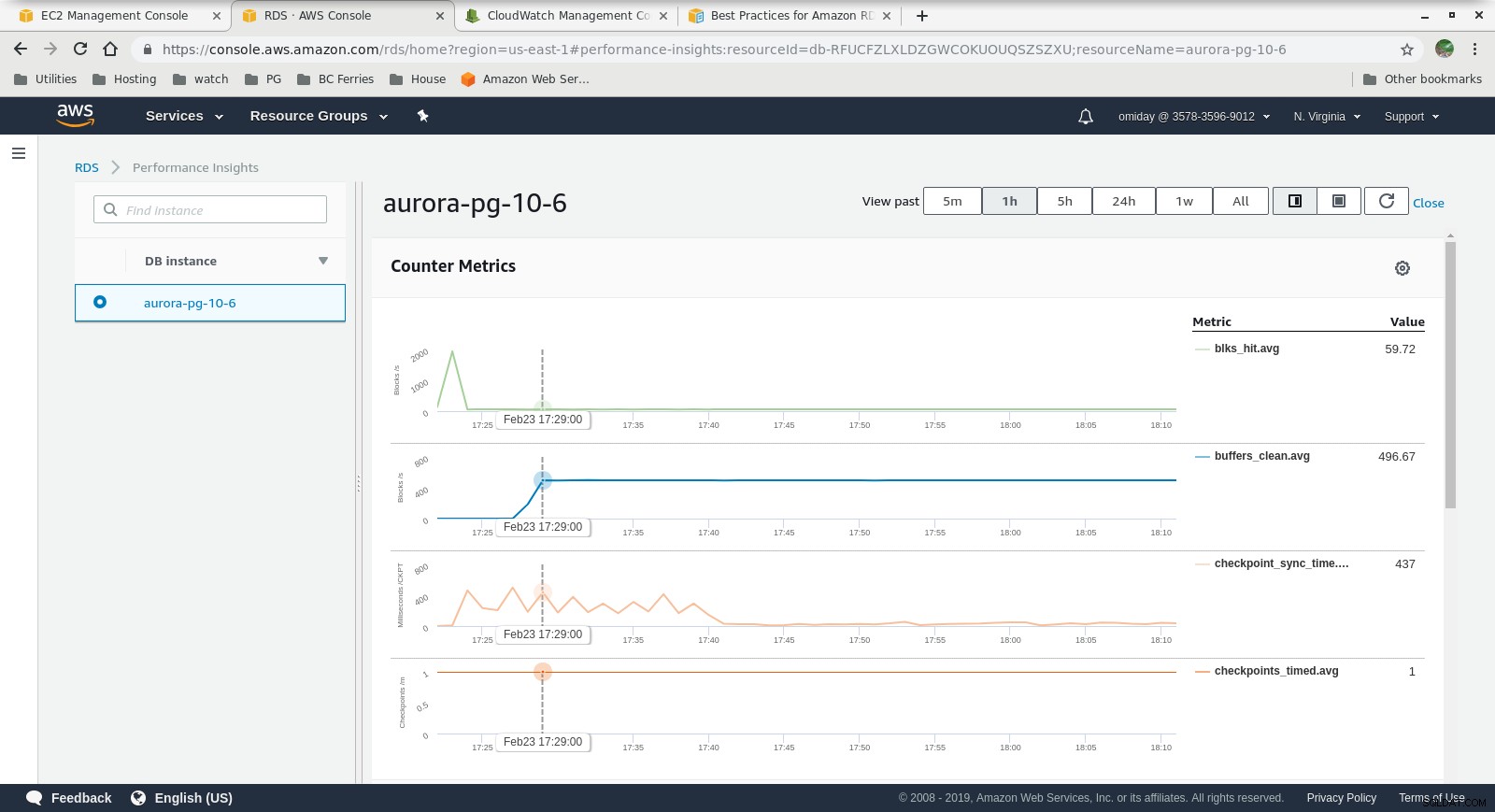 Statistiky výkonu – metriky počítadla
Statistiky výkonu – metriky počítadla 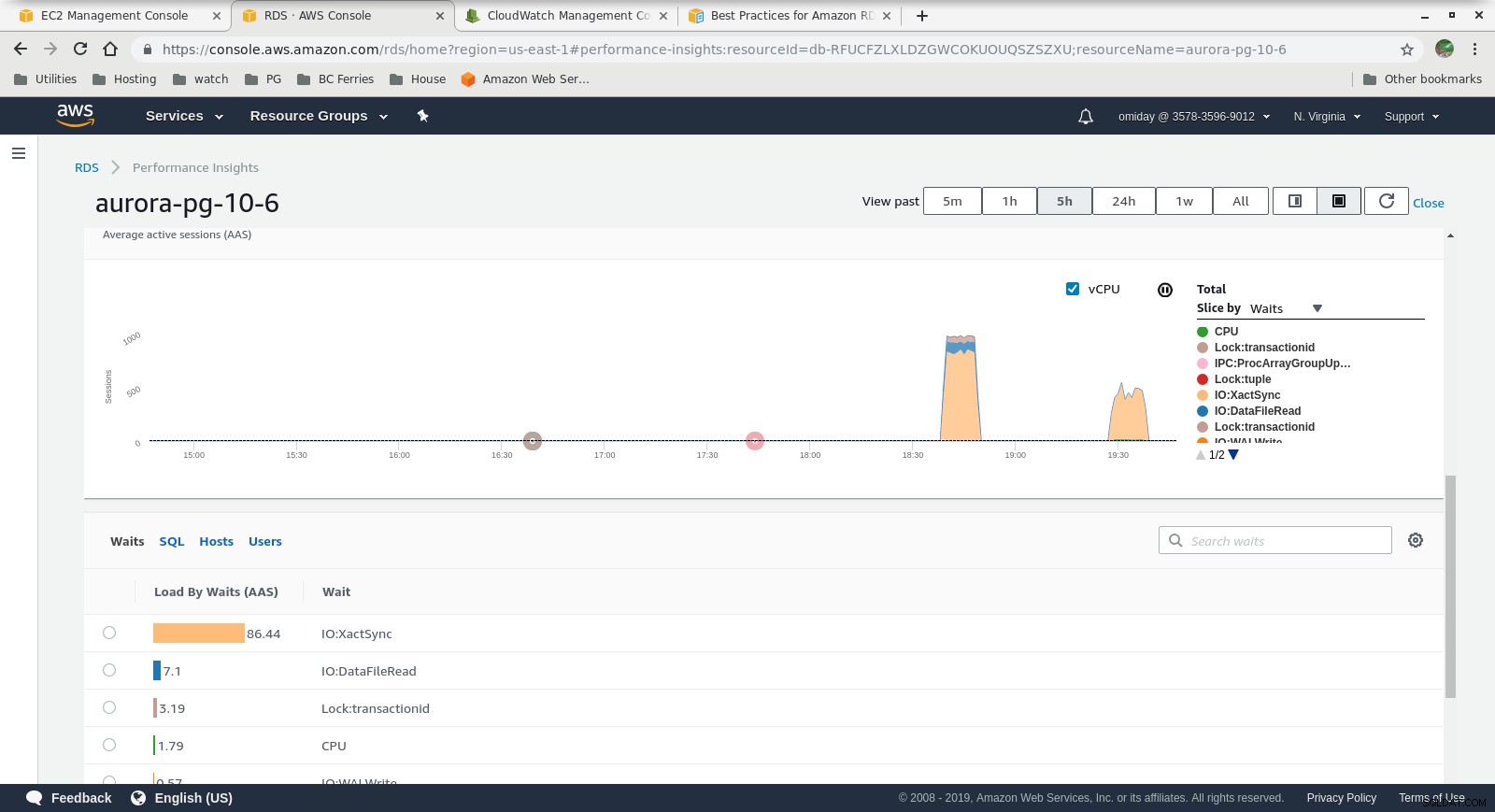 Statistiky výkonu – načítání databáze po čekání
Statistiky výkonu – načítání databáze po čekání Poslední myšlenky
- Uživatelé mohou používat předdefinované velikosti instancí. Nevýhodou je, že pokud benchmark ukazuje, že instance může těžit z další paměti, není možné „jen přidat více RAM“. Přidání více paměti znamená zvětšení velikosti instance, což je spojeno s vyššími náklady (náklady se zdvojnásobí na každou velikost instance).
- Amazon Aurora Storage Engine se výrazně liší od RDS a je postaven na hardwaru SAN. Metriky I/O propustnosti na instanci ukazují, že test se ještě nepřiblížil k maximu pro zřízené objemy IOPS SSD EBS 1 750 MiB/s.
- Další ladění lze provést kontrolou událostí AWS PostgreSQL zahrnutých v grafech Performance Insights.
Další v řadě
Zůstaňte naladěni na další část:Amazon RDS pro PostgreSQL 10.6.