Jedním z primárních požadavků na jakoukoli databázi je dosáhnout škálovatelnosti. Toho lze dosáhnout pouze tehdy, pokud je spor (uzamykání) co nejvíce minimalizován, pokud není odstraněn vše dohromady. Protože čtení/zápis/aktualizace/mazání jsou některé z hlavních častých operací, které se v databázi odehrávají, je velmi důležité, aby tyto operace probíhaly souběžně, aniž by byly zablokovány. Aby toho bylo dosaženo, používá většina hlavních databází model souběžnosti nazvaný Multi-Version Concurrency Control, což snižuje spory na minimum.
Co je MVCC
Řízení souběžnosti více verzí (zde dále MVCC) je algoritmus, který poskytuje jemné řízení souběžnosti udržováním více verzí stejného objektu, takže operace čtení a zápisu nejsou v konfliktu. Zde WRITE znamená UPDATE a DELETE, protože nově VLOŽENÝ záznam bude chráněn podle úrovně izolace. Každá operace ZÁPISU vytváří novou verzi objektu a každá souběžná operace čtení čte jinou verzi objektu v závislosti na úrovni izolace. Vzhledem k tomu, že čtení a zápis pracují na různých verzích stejného objektu, žádná z těchto operací není nutná k úplnému uzamčení, a proto mohou obě fungovat současně. Jediný případ, kdy může spor stále existovat, je, když se dvě souběžné transakce pokusí ZAPSAT stejný záznam.
Většina současných hlavních databází podporuje MVCC. Záměrem tohoto algoritmu je udržovat více verzí stejného objektu, takže implementace MVCC se liší databázi od databáze pouze z hlediska toho, jak je více verzí vytvořeno a udržováno. V souladu s tím se mění odpovídající databázový provoz a ukládání dat.
Nejuznávanějším přístupem k implementaci MVCC je ten, který používají PostgreSQL a Firebird/Interbase a jiný používají InnoDB a Oracle. V následujících částech podrobně probereme, jak byl implementován v PostgreSQL a InnoDB.
MVCC v PostgreSQL
Aby bylo možné podporovat více verzí, PostgreSQL udržuje další pole pro každý objekt (Tuple v terminologii PostgreSQL), jak je uvedeno níže:
- xmin – ID transakce transakce, která vložila nebo aktualizovala n-tici. V případě UPDATE se s tímto ID transakce přiřadí novější verze n-tice.
- xmax – ID transakce transakce, která odstranila nebo aktualizovala n-tici. V případě UPDATE získá aktuálně existující verze n-tice toto ID transakce. U nově vytvořené n-tice je výchozí hodnota tohoto pole null.
PostgreSQL ukládá všechna data do primárního úložiště zvaného HEAP (stránka výchozí velikosti 8 kB). Veškerá nová n-tice dostane xmin jako transakci, která ji vytvořila, a starší verze n-tice (která byla aktualizována nebo smazána) dostane přiřazeno xmax. Vždy existuje odkaz ze starší verze n-tice na novou verzi. Starší verzi n-tice lze použít k opětovnému vytvoření n-tice v případě vrácení zpět a ke čtení starší verze n-tice příkazem READ v závislosti na úrovni izolace.
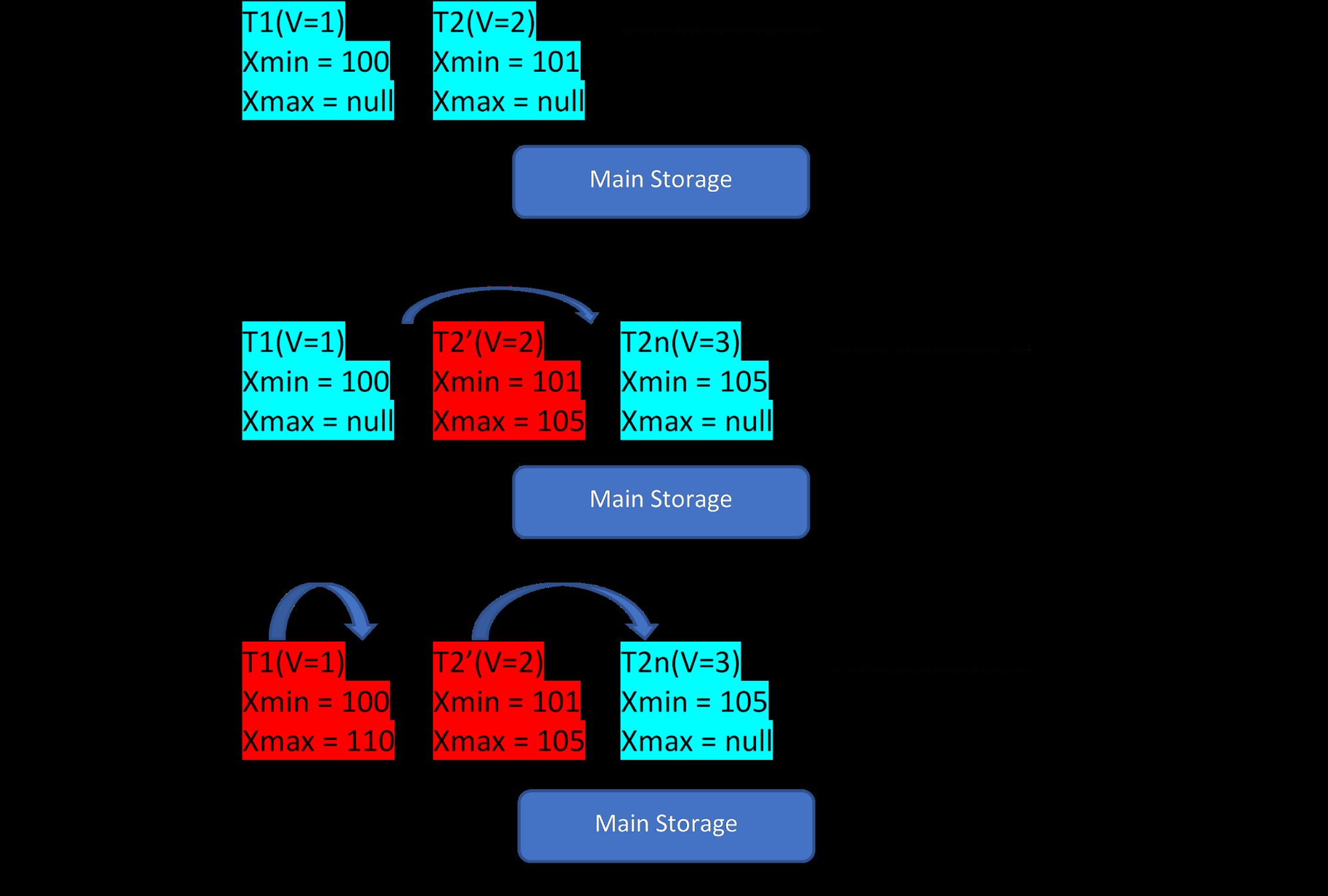
Uvažujme, že existují dvě n-tice, T1 (s hodnotou 1) a T2 (s hodnotou 2) pro tabulku, vytvoření nových řádků lze demonstrovat níže ve 3 krocích:
 MVCC:Ukládání více verzí v PostgreSQL
MVCC:Ukládání více verzí v PostgreSQL Jak je vidět z obrázku, zpočátku jsou v databázi dvě n-tice s hodnotami 1 a 2.
Poté se v druhém kroku řádek T2 s hodnotou 2 aktualizuje o hodnotu 3. V tomto okamžiku se vytvoří nová verze s novou hodnotou a uloží se jako vedle existující n-tice ve stejné oblasti úložiště. . Předtím je starší verzi přiřazeno xmax a ukazuje na nejnovější verzi n-tice.
Podobně ve třetím kroku, když se smaže řádek T1 s hodnotou 1, dojde na stejném místě k virtuálnímu smazání existujícího řádku (tj. právě mu přiřadil xmax k aktuální transakci). Pro toto nebude vytvořena žádná nová verze.
Dále se podívejme, jak každá operace vytváří více verzí a jak je udržována úroveň izolace transakcí bez zamykání s několika skutečnými příklady. Ve všech níže uvedených příkladech je standardně použita izolace „READ COMMITTED“.
VLOŽIT
Pokaždé, když se vloží záznam, vytvoří se nová n-tice, která se přidá na jednu ze stránek patřících do odpovídající tabulky.
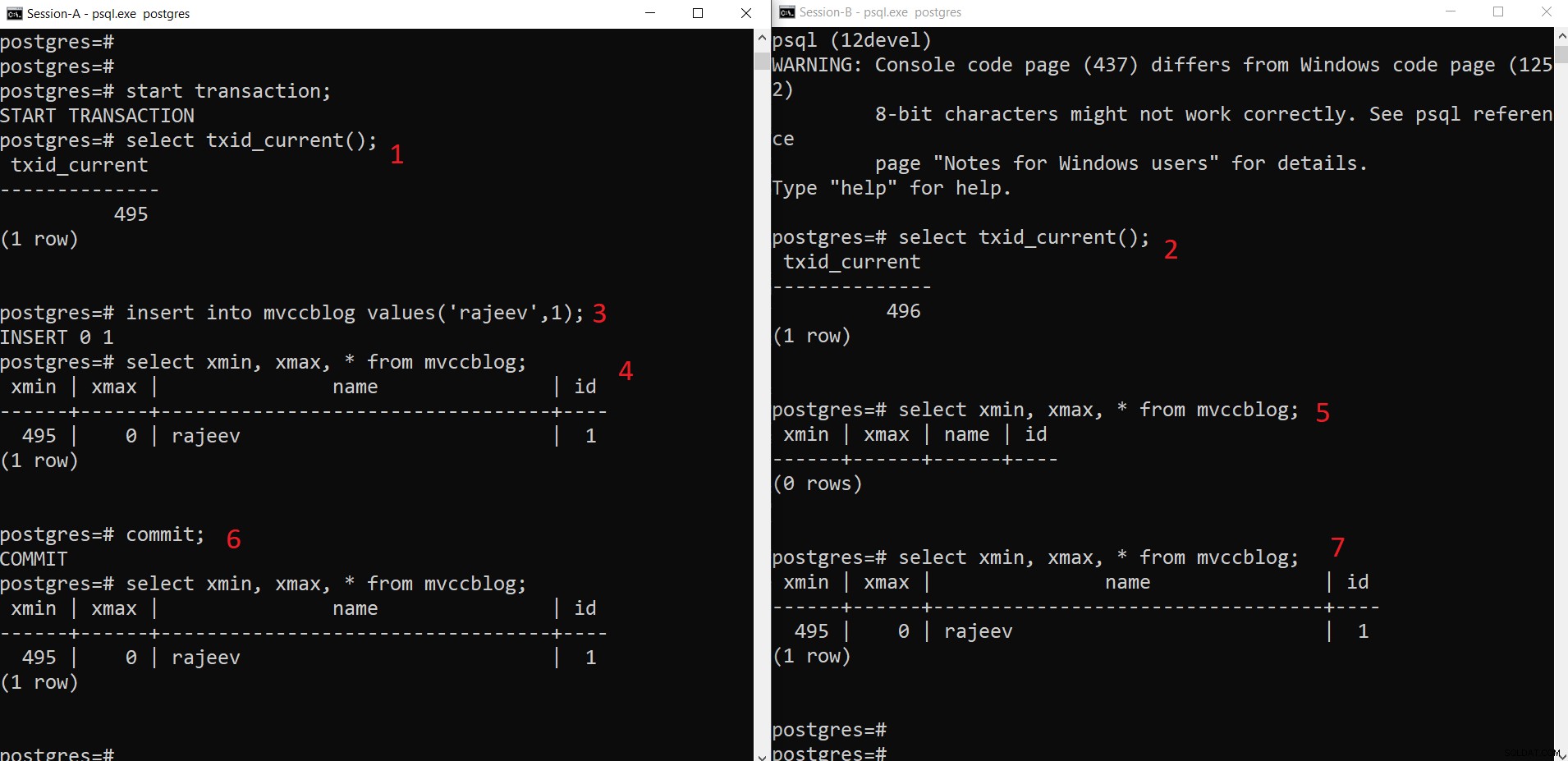 Souběžná operace INSERT v PostgreSQL
Souběžná operace INSERT v PostgreSQL Jak můžeme vidět zde postupně:
- Relace-A zahájí transakci a získá ID transakce 495.
- Relace-B zahájí transakci a získá ID transakce 496.
- Relace-A vloží novou n-tici (uloží se do HEAP)
- Nyní je přidána nová n-tice s xmin nastaveným na aktuální ID transakce 495.
- Totéž ale není vidět z relace-B, protože xmin (tj. 495) stále není potvrzeno.
- Jakmile se zaváže.
- Data jsou viditelná pro obě relace.
AKTUALIZACE
AKTUALIZACE PostgreSQL není „IN-PLACE“ aktualizace, to znamená, že nemodifikuje existující objekt požadovanou novou hodnotou. Místo toho vytvoří novou verzi objektu. UPDATE tedy obecně zahrnuje následující kroky:
- Označí aktuální objekt jako odstraněný.
- Pak přidá novou verzi objektu.
- Přesměrujte starší verzi objektu na novou verzi.
Takže i když počet záznamů zůstává stejný, HEAP zabírá místo, jako by byl vložen další záznam.
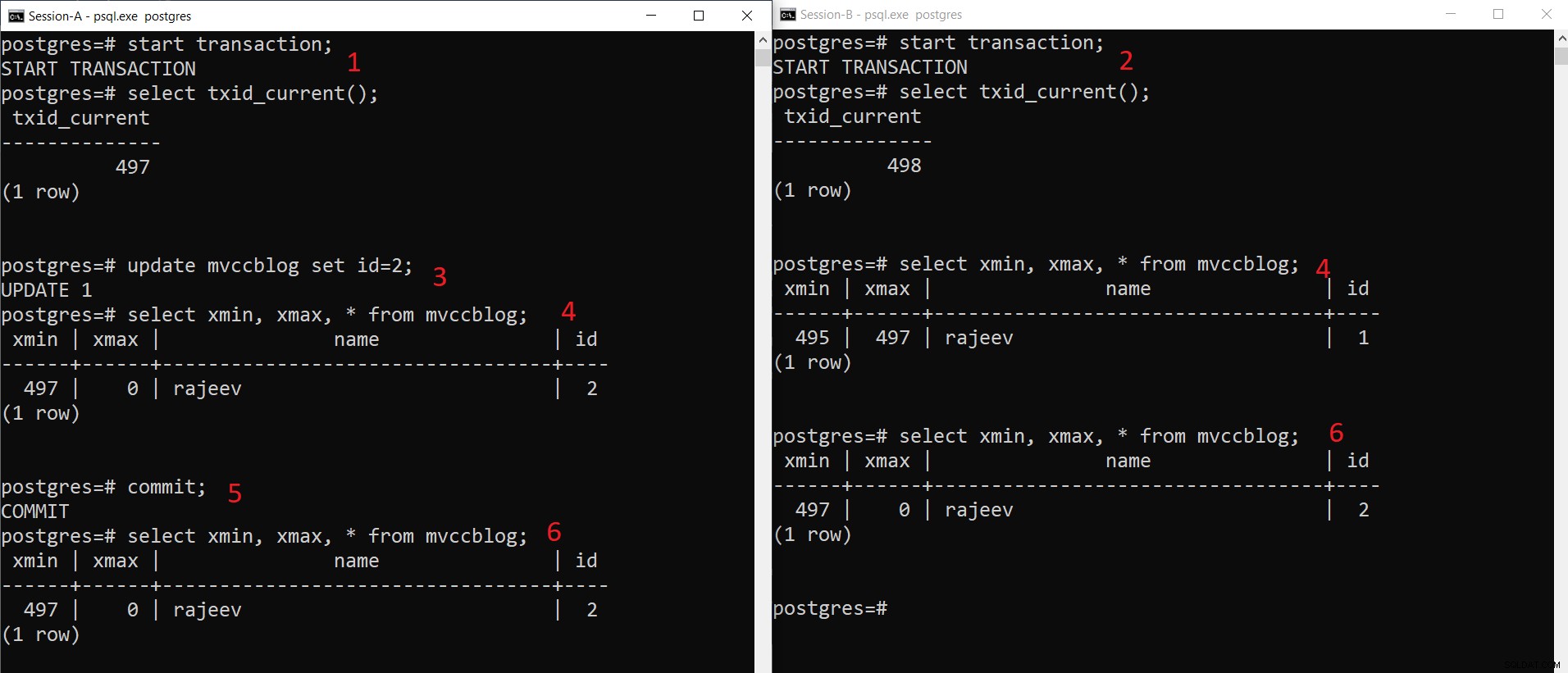 Souběžná operace INSERT v PostgreSQL
Souběžná operace INSERT v PostgreSQL Jak můžeme vidět zde postupně:
- Relace-A zahájí transakci a získá ID transakce 497.
- Relace-B zahájí transakci a získá ID transakce 498.
- Relace-A aktualizuje stávající záznam.
- Zde relace-A vidí jednu verzi n-tice (aktualizovaná n-tice), zatímco relace-B vidí jinou verzi (starší n-tice, ale xmax je nastaveno na 497). Obě n-ticové verze se uloží do úložiště HEAP (dokonce i na stejnou stránku v závislosti na dostupnosti místa)
- Jakmile relace-A potvrdí transakci, platnost starší n-tice vyprší, protože je potvrzeno xmax starší n-tice.
- Nyní obě relace vidí stejnou verzi záznamu.
SMAZAT
Odstranit je téměř jako operace UPDATE, kromě toho, že není nutné přidávat novou verzi. Pouze označí aktuální objekt jako DELETED, jak je vysvětleno v případě UPDATE.
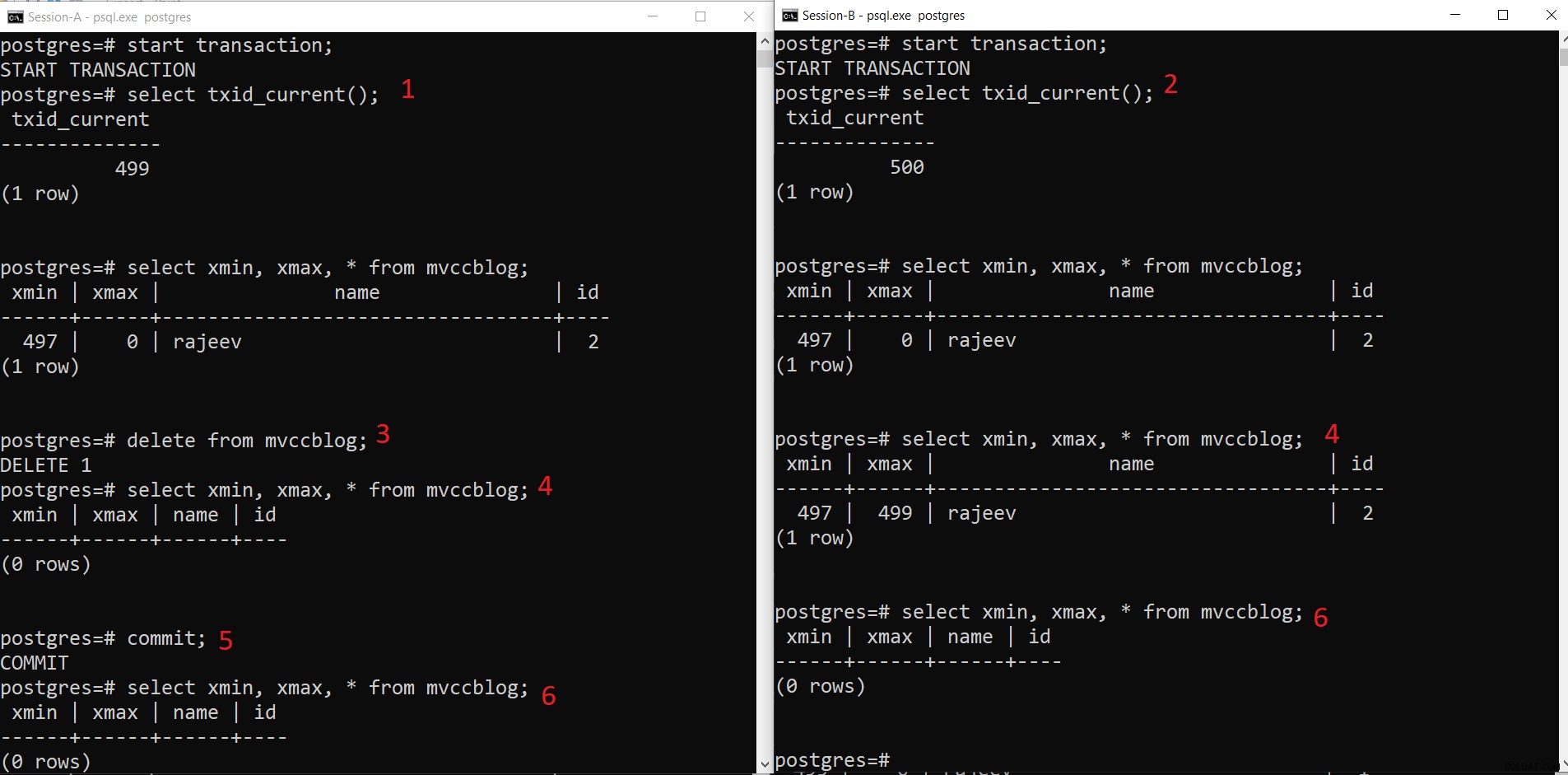 Souběžná operace DELETE v PostgreSQL
Souběžná operace DELETE v PostgreSQL - Relace-A zahájí transakci a získá ID transakce 499.
- Relace-B zahájí transakci a získá ID transakce 500.
- Relace-A smaže existující záznam.
- Zde relace-A nevidí žádnou n-tici jako smazanou z aktuální transakce. Zatímco relace-B vidí starší verzi n-tice (s xmax jako 499; transakce, která smazala tento záznam).
- Jakmile relace-A potvrdí transakci, platnost starší n-tice vyprší, protože je potvrzeno xmax starší n-tice.
- Nyní obě relace nevidí smazanou n-tici.
Jak vidíme, žádná z operací neodstraní stávající verzi objektu přímo a tam, kde je potřeba, přidá další verzi objektu.
Nyní se podívejme, jak se dotaz SELECT provede na n-tici s více verzemi:SELECT potřebuje číst všechny verze n-tice, dokud nenajde vhodnou n-tici podle úrovně izolace. Předpokládejme, že existovala n-tice T1, která byla aktualizována a vytvořila novou verzi T1' a která zase vytvořila T1'' při aktualizaci:
- Operace SELECT projde úložištěm haldy pro tuto tabulku a nejprve zkontroluje T1. Pokud je transakce T1 xmax potvrzena, přesune se na další verzi této n-tice.
- Předpokládejme, že nyní je také potvrzena T1' n-tice xmax, pak se znovu přesune na další verzi této n-tice.
- Nakonec najde T1'' a zjistí, že xmax není potvrzeno (nebo null) a T1'' xmin je viditelné pro aktuální transakci podle úrovně izolace. Nakonec přečte T1’’ n-tice.
Jak vidíme, potřebuje procházet všemi 3 verzemi n-tice, aby našel vhodnou viditelnou n-tice, dokud nebude n-tice smazána sběračem odpadu (VACUUM).
MVCC v InnoDB
Aby bylo možné podporovat více verzí, InnoDB udržuje další pole pro každý řádek, jak je uvedeno níže:
- DB_TRX_ID:ID transakce transakce, která vložila nebo aktualizovala řádek.
- DB_ROLL_PTR:Říká se mu také ukazatel převrácení a ukazuje na vrácení záznamu záznamu zapsaného do segmentu vrácení zpět (více o tom dále).
Stejně jako PostgreSQL, InnoDB také vytváří několik verzí řádku jako součást všech operací, ale úložiště starší verze je jiné.
V případě InnoDB je stará verze změněného řádku uchovávána v samostatném tabulkovém prostoru/úložišti (tzv. undo segment). Na rozdíl od PostgreSQL tedy InnoDB uchovává pouze nejnovější verzi řádků v hlavní úložné oblasti a starší verze je uchovávána v segmentu zpět. Verze řádků ze segmentu undo se používají k vrácení operace v případě vrácení zpět a ke čtení starší verze řádků příkazem READ v závislosti na úrovni izolace.
Uvažujme, že pro tabulku existují dva řádky, T1 (s hodnotou 1) a T2 (s hodnotou 2), vytvoření nových řádků lze demonstrovat ve 3 krocích níže:
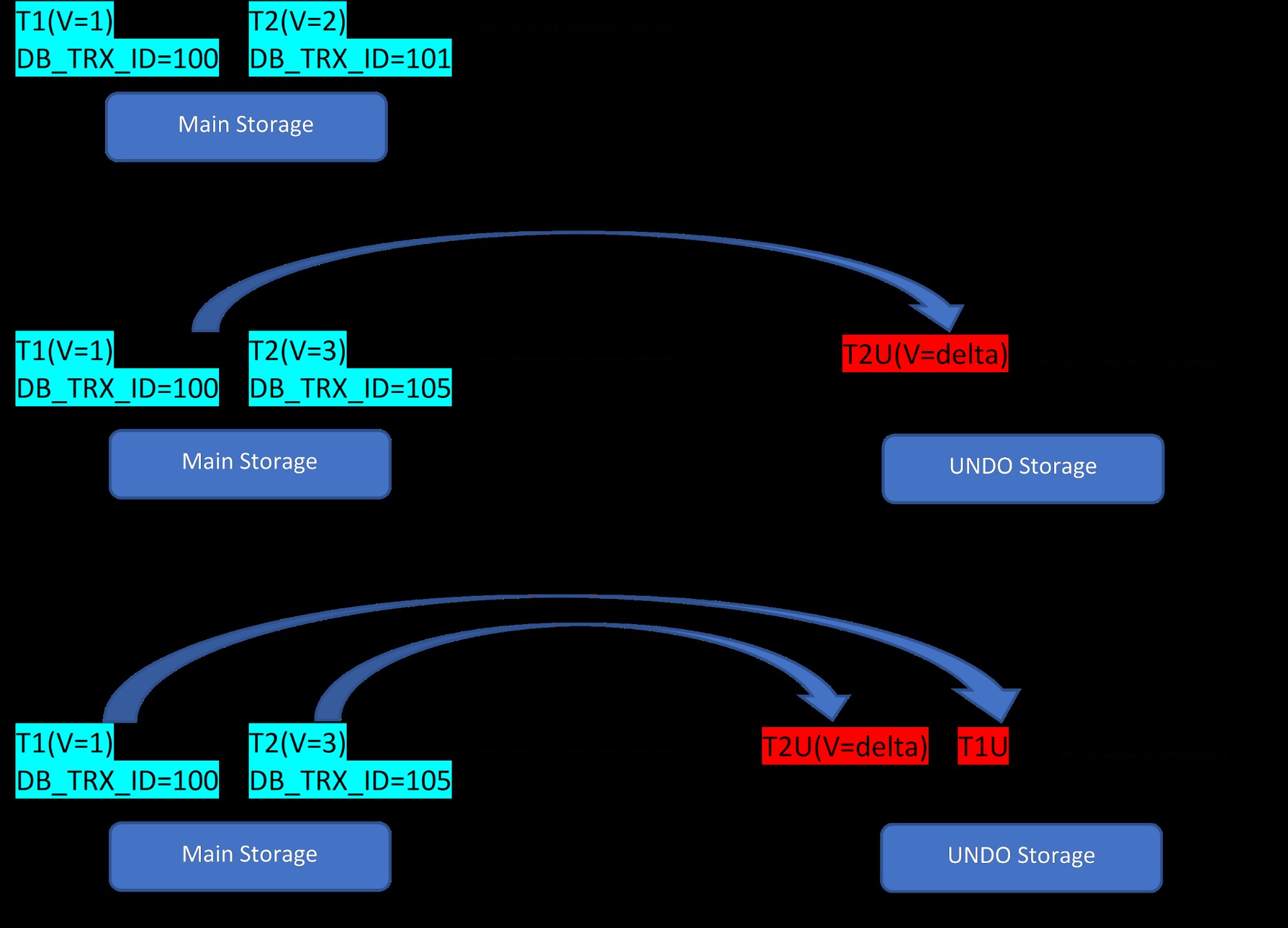 MVCC:Ukládání více verzí v InnoDB
MVCC:Ukládání více verzí v InnoDB Jak je vidět z obrázku, zpočátku jsou v databázi dva řádky s hodnotami 1 a 2.
V druhé fázi se pak řádek T2 s hodnotou 2 aktualizuje o hodnotu 3. V tomto okamžiku se vytvoří nová verze s novou hodnotou a nahradí starší verzi. Předtím se starší verze uloží do segmentu zpět (všimněte si, že verze segmentu UNDO má pouze delta hodnotu). Všimněte si také, že v segmentu vrácení zpět existuje jeden ukazatel z nové verze na starší verzi. Takže na rozdíl od PostgreSQL je aktualizace InnoDB „NA MÍSTĚ“.
Podobně ve třetím kroku, když je smazán řádek T1 s hodnotou 1, existující řádek se virtuálně smaže (tj. pouze označí speciální bit v řádku) v oblasti hlavního úložiště a přidá se nová verze, která tomu odpovídá. segment Zpět. Opět je zde jeden ukazatel role z hlavního úložiště do segmentu zpět.
Všechny operace se při pohledu zvenčí chovají stejně jako v případě PostgreSQL. Liší se pouze interní úložiště více verzí.
Stáhněte si Whitepaper Today Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si WhitepaperMVCC:PostgreSQL vs InnoDB
Nyní pojďme analyzovat, jaké jsou hlavní rozdíly mezi PostgreSQL a InnoDB, pokud jde o jejich implementaci MVCC:
-
Velikost starší verze
PostgreSQL pouze aktualizuje xmax na starší verzi n-tice, takže velikost starší verze zůstává stejná jako u odpovídajícího vloženého záznamu. To znamená, že pokud máte 3 verze starší n-tice, pak všechny budou mít stejnou velikost (kromě rozdílu ve skutečné velikosti dat, pokud existuje při každé aktualizaci).
Zatímco v případě InnoDB je verze objektu uložená v segmentu Zpět obvykle menší než odpovídající vložený záznam. Je to proto, že do protokolu UNDO se zapisují pouze změněné hodnoty (tj. rozdíl).
-
Operace VLOŽENÍ
InnoDB potřebuje zapsat jeden další záznam do segmentu UNDO i pro INSERT, zatímco PostgreSQL vytváří novou verzi pouze v případě UPDATE.
-
Obnovení starší verze v případě vrácení zpět
PostgreSQL nepotřebuje nic konkrétního, aby obnovil starší verzi v případě vrácení zpět. Pamatujte, že starší verze má xmax rovné transakci, která aktualizovala tuto n-tici. Dokud se tedy toto ID transakce nepotvrdí, je považováno za aktivní n-tici pro souběžný snímek. Jakmile je transakce vrácena zpět, bude odpovídající transakce automaticky považována za aktuální pro všechny transakce, protože se bude jednat o přerušenou transakci.
Zatímco v případě InnoDB je výslovně požadováno znovu sestavit starší verzi objektu, jakmile dojde k vrácení.
-
Obnovení místa obsazeného starší verzí
V případě PostgreSQL lze prostor obsazený starší verzí považovat za mrtvý pouze v případě, že neexistuje paralelní snímek pro čtení této verze. Jakmile je starší verze mrtvá, může operace VACUUM získat zpět místo, které zabírají. VACUUM lze spustit ručně nebo jako úlohu na pozadí v závislosti na konfiguraci.
Protokoly InnoDB UNDO se primárně dělí na INSERT UNDO a UPDATE UNDO. První bude zahozena, jakmile se příslušná transakce potvrdí. Druhý musí být zachován, dokud nebude rovnoběžný s jakýmkoli jiným snímkem. InnoDB nemá explicitní operaci VACUUM, ale na podobné lince má asynchronní PURGE pro vyřazení protokolů UNDO, které běží jako úloha na pozadí.
-
Dopad zpožděného vakua
Jak bylo uvedeno v předchozím bodě, v případě PostgreSQL existuje obrovský dopad zpožděného vakua. Způsobí to, že se tabulka začne nadýmat a způsobí nárůst úložného prostoru, i když jsou záznamy neustále odstraňovány. Může to také dosáhnout bodu, kdy je třeba provést VACUUM FULL, což je velmi nákladná operace.
-
Sekvenční skenování v případě nafouknutého stolu
PostgreSQL sekvenční skenování musí procházet všemi staršími verzemi objektu, i když jsou všechny mrtvé (dokud nejsou odstraněny pomocí vakua). Toto je typický a nejčastěji diskutovaný problém v PostgreSQL. Pamatujte, že PostgreSQL ukládá všechny verze n-tice do stejného úložiště.
Zatímco v případě InnoDB nemusí číst záznam Undo, pokud to není vyžadováno. V případě, že jsou všechny zpětné záznamy mrtvé, bude stačit pouze přečíst všechny nejnovější verze objektů.
-
Index
PostgreSQL ukládá index do samostatného úložiště, které uchovává jeden odkaz na aktuální data v HEAP. PostgreSQL tedy musí aktualizovat část INDEX také, i když v INDEXu nedošlo k žádné změně. Ačkoli později byl tento problém vyřešen implementací HOT (Heap Only Tuple) aktualizace, ale stále má omezení, že pokud novou haldu n-tice nelze umístit na stejnou stránku, vrátí se k normální UPDATE.
InnoDB tento problém nemá, protože používá clusterovaný index.
Závěr
PostgreSQL MVCC má několik nedostatků, zejména pokud jde o přeplněné úložiště, pokud vaše pracovní zatížení často UPDATE/DELETE. Pokud se tedy rozhodnete používat PostgreSQL, měli byste být velmi opatrní a konfigurovat VACUUM moudře.
Komunita PostgreSQL to také uznala jako hlavní problém a již začala pracovat na přístupu MVCC založeném na UNDO (předběžný název jako ZHEAP) a totéž bychom mohli vidět v budoucí verzi.