Neexistuje dokonalý systém, hardware nebo topologie, která by zabránila všem možným problémům, které by mohly nastat v produkčním prostředí. Překonání těchto výzev vyžaduje efektivní DRP (Disaster Recovery Plan), nakonfigurovaný podle požadavků vaší aplikace, infrastruktury a podnikání. Klíčem k úspěchu v těchto typech situací je vždy to, jak rychle dokážeme problém vyřešit nebo se z něj zotavit.
V tomto blogu se podíváme na nejběžnější scénáře selhání PostgreSQL a ukážeme vám, jak můžete problémy vyřešit nebo se s nimi vyrovnat. Podíváme se také na to, jak nám může ClusterControl pomoci dostat se zpět online
Běžná topologie PostgreSQL
Abyste porozuměli běžným scénářům selhání, musíte nejprve začít s běžnou topologií PostgreSQL. Může to být jakákoli aplikace připojená k primárnímu uzlu PostgreSQL, ke kterému je připojena replika.
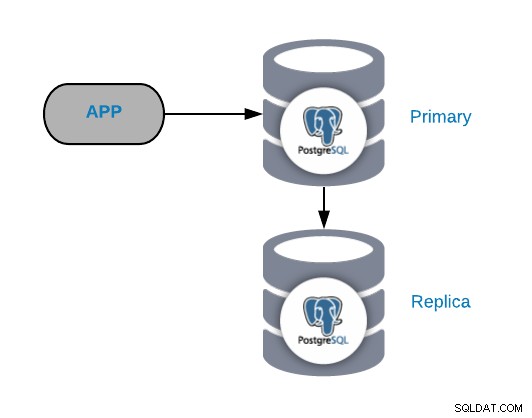
Tuto topologii můžete kdykoli vylepšit nebo rozšířit přidáním dalších uzlů nebo vyrovnávačů zatížení , ale toto je základní topologie, se kterou začneme pracovat.
Selhání primárního uzlu PostgreSQL
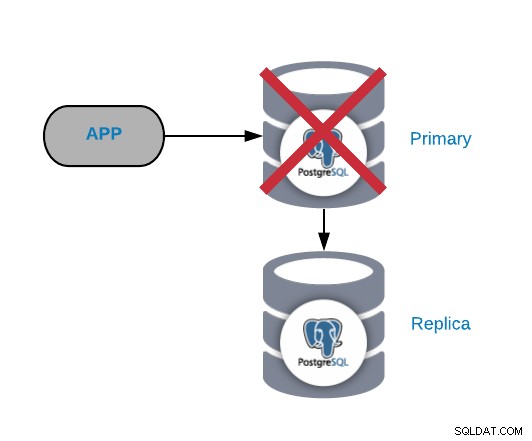
Toto je jedno z nejzávažnějších selhání, protože bychom jej měli co nejdříve opravit, pokud chceme, aby naše systémy zůstaly online. Pro tento typ selhání je důležité mít nějaký druh automatického mechanismu selhání. Po selhání se můžete podívat na důvod problémů. Po procesu převzetí služeb při selhání zajistíme, aby si primární uzel, který selhal, stále nemyslel, že je primárním uzlem. Je to proto, aby se předešlo nekonzistenci dat při zápisu do nich.
Nejčastějšími příčinami tohoto druhu problému jsou selhání operačního systému, selhání hardwaru nebo selhání disku. V každém případě bychom měli zkontrolovat databázi a protokoly operačního systému, abychom našli důvod.
Nejrychlejším řešením tohoto problému je provedení úlohy převzetí služeb při selhání za účelem snížení prostojů. K podpoře repliky můžeme použít příkaz pg_ctl promotion na uzlu slave databáze a poté musíme odeslat provoz z aplikace na nový primární uzel. Pro tento poslední úkol můžeme implementovat load balancer mezi naší aplikací a databázovými uzly, abychom se vyhnuli jakékoli změně ze strany aplikace v případě selhání. Můžeme také nakonfigurovat nástroj pro vyrovnávání zátěže tak, aby detekoval selhání uzlu a místo toho, abychom mu posílali provoz, odeslal provoz do nového primárního uzlu.
Po procesu převzetí služeb při selhání a ujištění se, že systém opět funguje, se můžeme na problém podívat a doporučujeme ponechat vždy funkční alespoň jeden podřízený uzel, takže v případě nového primárního selhání, můžeme znovu provést úlohu převzetí služeb při selhání.
Selhání uzlu repliky PostgreSQL
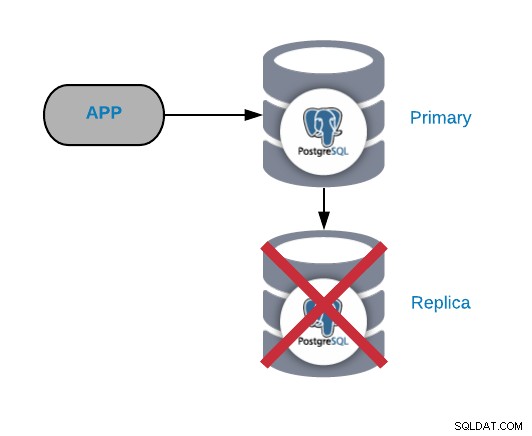
Toto obvykle není kritický problém (pokud máte více než jednu repliku a nepoužívají ji k odesílání čteného produkčního provozu). Pokud máte problémy s primárním uzlem a nemáte svou repliku aktuální, budete mít skutečně kritický problém. Pokud používáte naši repliku pro účely vytváření přehledů nebo velkých dat, pravděpodobně to budete chtít stejně rychle opravit.
Nejběžnější příčiny tohoto druhu problému jsou stejné, jaké jsme viděli u primárního uzlu, selhání operačního systému, selhání hardwaru nebo selhání disku. Měli byste zkontrolovat databázi a protokoly operačního systému najít důvod.
Nedoporučuje se nechat systém fungovat bez repliky, protože v případě selhání nemáte rychlý způsob, jak se dostat zpět online. Pokud máte pouze jednoho otroka, měli byste problém vyřešit ASAP; nejrychlejší způsob je vytvoření nové repliky od začátku. K tomu budete muset provést konzistentní zálohu a obnovit ji do podřízeného uzlu a poté nakonfigurovat replikaci mezi tímto podřízeným uzlem a primárním uzlem.
Pokud chcete znát důvod selhání, měli byste k vytvoření nové repliky použít jiný server a poté se podívat na ten starý, abyste ji našli. Po dokončení této úlohy můžete také překonfigurovat starou repliku a nechat obě fungovat jako budoucí možnost převzetí služeb při selhání.
Pokud repliku používáte pro vytváření přehledů nebo pro účely velkých dat, musíte změnit IP adresu, abyste se mohli připojit k nové. Stejně jako v předchozím případě je jedním ze způsobů, jak se vyhnout této změně, použití nástroje pro vyrovnávání zatížení, který bude znát stav každého serveru a umožní vám přidávat/odebírat repliky, jak si přejete.
Selhání replikace PostgreSQL
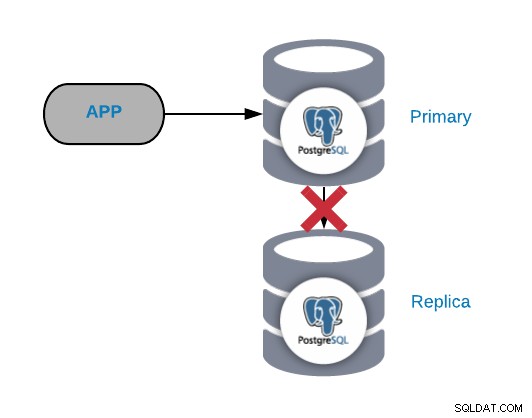
Obecně se tento druh problému generuje kvůli síti nebo konfiguraci problém. Souvisí to se ztrátou WAL (Write-Ahead Logging) v primárním uzlu a se způsobem, jakým PostgreSQL spravuje replikaci.
Pokud máte důležitý provoz, provádíte kontrolní body příliš často nebo ukládáte WALS jen na několik minut; pokud máte problém se sítí, budete mít málo času na jeho vyřešení. Vaše WAL by byly smazány, než je budete moci odeslat a použít na repliku.
Pokud byla odstraněna WAL, kterou replika potřebuje, abyste ji mohli dále fungovat, musíte ji znovu sestavit, takže abychom se tomuto úkolu vyhnuli, měli bychom zkontrolovat konfiguraci naší databáze, abychom zvýšili wal_keep_segments (množství WALS, které je třeba zachovat v adresář pg_xlog) nebo parametry max_wal_senders (maximální počet současně spuštěných procesů odesílatele WAL).
Další doporučenou možností je nakonfigurovat režim archive_mode a odeslat soubory WAL na jinou cestu s parametrem archive_command. Tímto způsobem, pokud PostgreSQL dosáhne limitu a smaže soubor WAL, budeme jej mít stejně v jiné cestě.
Poškození dat PostgreSQL / nekonzistence dat / náhodné smazání

Toto je noční můra každého DBA a pravděpodobně nejsložitější problém. opraveno, v závislosti na tom, jak rozšířený je problém.
Pokud jsou vaše data ovlivněna některým z těchto problémů, nejběžnějším způsobem, jak to opravit (a pravděpodobně jediným), je obnovení zálohy. Proto jsou zálohy základní formou každého plánu obnovy po havárii a doporučuje se, abyste měli alespoň tři zálohy uložené na různých fyzických místech. Osvědčený postup diktuje, že záložní soubory by měly mít jeden uložený lokálně na databázovém serveru (pro rychlejší obnovu), další na centralizovaném zálohovacím serveru a poslední v cloudu.
Můžeme také vytvořit kombinaci plných/přírůstkových/diferenciálních záloh kompatibilních s PITR, abychom snížili náš cíl bodů obnovy.
Správa selhání PostgreSQL pomocí ClusterControl
Když jsme se nyní podívali na tyto běžné scénáře selhání PostgreSQL, podívejme se, co by se stalo, kdybychom vaše databáze PostgreSQL spravovali z centralizovaného systému správy databází. Takový, který je skvělý, pokud jde o dosažení rychlého a snadného řešení problému, ASAP, v případě selhání.
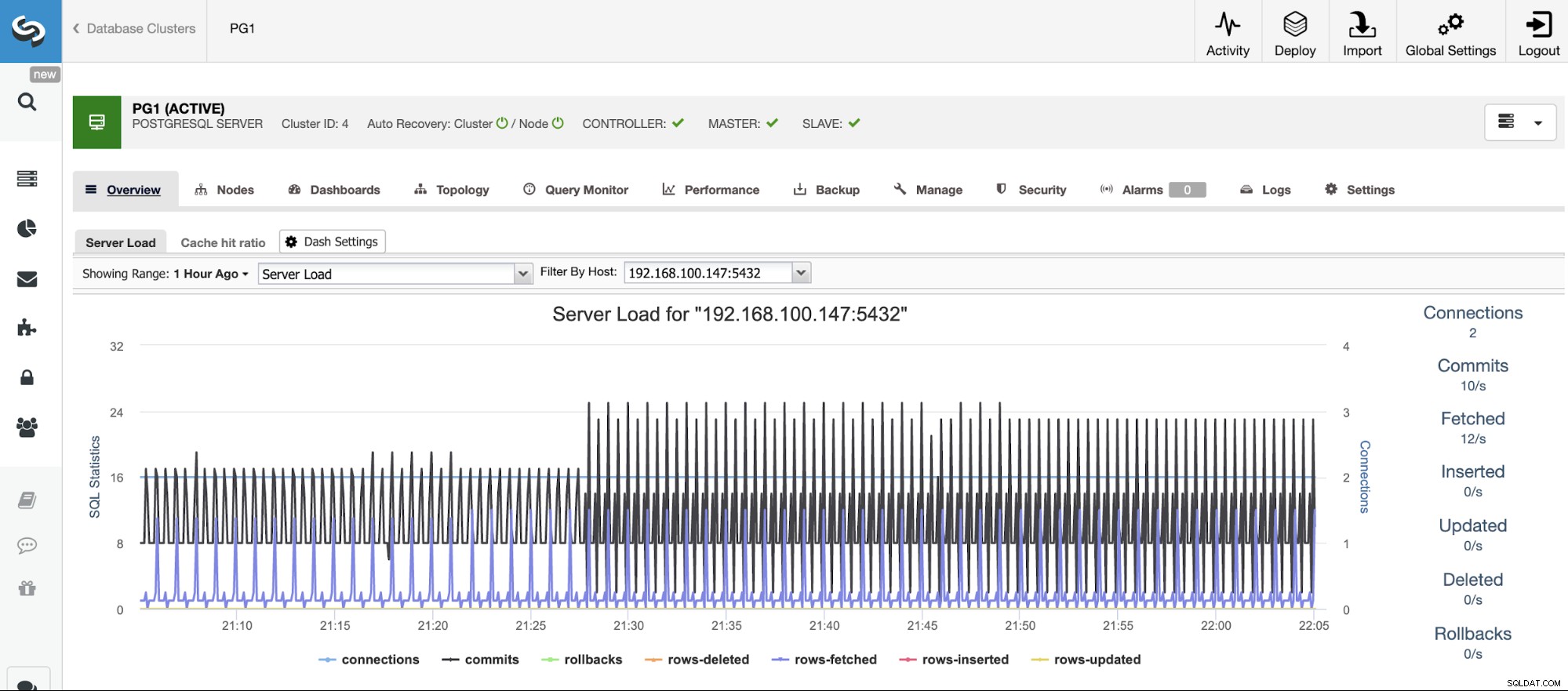
ClusterControl poskytuje automatizaci pro většinu úloh PostgreSQL popsaných výše; vše centralizovaným a uživatelsky přívětivým způsobem. S tímto systémem budete moci snadno konfigurovat věci, které by ručně vyžadovaly čas a úsilí. Nyní si projdeme některé z jeho hlavních funkcí souvisejících se scénáři selhání PostgreSQL.
Nasazení / import klastru PostgreSQL
Jakmile vstoupíme do rozhraní ClusterControl, první věcí, kterou musíte udělat, je nasadit nový cluster nebo importovat existující. Chcete-li provést nasazení, jednoduše vyberte možnost Nasadit klastr databáze a postupujte podle zobrazených pokynů.
Škálování vašeho PostgreSQL clusteru
Pokud přejdete do Cluster Actions a vyberete Add Replication Slave, můžete buď vytvořit novou repliku od začátku, nebo přidat existující databázi PostgreSQL jako repliku. Tímto způsobem můžete mít svou novou repliku spuštěnou během několika minut a my můžeme přidat tolik replik, kolik chceme; rozložení čteného provozu mezi nimi pomocí load balanceru (který můžeme implementovat i pomocí ClusterControl).
Automatické převzetí služeb při selhání PostgreSQL
ClusterControl spravuje převzetí služeb při selhání v nastavení replikace. Detekuje selhání masteru a povýší slave s nejaktuálnějšími daty jako nový master. Automaticky také přejde přes zbývající podřízené jednotky k replikaci z nového mastera. Pokud jde o připojení klientů, využívá pro tento úkol dva nástroje:HAProxy a Keepalived.
HAProxy je nástroj pro vyrovnávání zátěže, který distribuuje provoz z jednoho zdroje do jednoho nebo více cílů a může definovat konkrétní pravidla a/nebo protokoly pro danou úlohu. Pokud některý z cílů přestane reagovat, je označen jako offline a provoz je odeslán do jednoho z dostupných cílů. Tím se zabrání odesílání provozu do nepřístupného cíle a ztrátě těchto informací jeho nasměrováním do platného cíle.
Keepalived umožňuje konfigurovat virtuální IP v rámci aktivní/pasivní skupiny serverů. Tato virtuální IP je přiřazena k aktivnímu „hlavnímu“ serveru. Pokud tento server selže, IP je automaticky migrována na „sekundární“ server, který byl shledán pasivním, což mu umožňuje pokračovat v práci se stejnou IP transparentním způsobem pro naše systémy.
Přidání nástroje pro vyrovnávání zatížení PostgreSQL
Pokud přejdete do Cluster Actions a vyberete Add Load Balancer (nebo ze zobrazení clusteru - přejděte na Manage -> Load Balancer), můžete přidat loadbalancery do naší topologie databáze.
Konfigurace potřebná k vytvoření nového nástroje pro vyrovnávání zatížení je poměrně jednoduchá. Stačí přidat IP/Hostname, port, politiku a uzly, které budeme používat. Můžete přidat dva load balancery s Keepalived mezi nimi, což nám umožňuje mít automatické převzetí služeb při selhání našeho load balanceru v případě poruchy. Keepalived používá virtuální IP adresu a v případě selhání ji migruje z jednoho nástroje pro vyrovnávání zatížení do druhého, takže naše nastavení může nadále normálně fungovat.
Zálohy PostgreSQL
O důležitosti zálohování jsme již diskutovali. ClusterControl poskytuje funkci buď pro generování okamžité zálohy, nebo pro plánování zálohy.
Můžete si vybrat mezi třemi různými metodami zálohování, pgdump, pg_basebackup nebo pgBackRest. Můžete také určit, kam se mají zálohy ukládat (na databázovém serveru, na serveru ClusterControl nebo v cloudu), úroveň komprese, požadované šifrování a dobu uchování.
Monitorování a upozornění PostgreSQL
Než budete moci provést akci, musíte vědět, co se děje, takže budete muset monitorovat svůj databázový cluster. ClusterControl vám umožňuje sledovat naše servery v reálném čase. K dispozici jsou grafy se základními daty, jako je CPU, síť, disk, RAM, IOPS, a také metriky specifické pro databázi shromážděné z instancí PostgreSQL. Databázové dotazy lze také prohlížet z Query Monitor.
Stejným způsobem, jakým povolíte sledování z ClusterControl, můžete také nastavit výstrahy, které vás informují o událostech ve vašem clusteru. Tato upozornění jsou konfigurovatelná a lze je přizpůsobit podle potřeby.
Závěr
Každý se nakonec bude muset vypořádat s problémy a selháními PostgreSQL. A protože se tomuto problému nemůžete vyhnout, musíte být schopni jej opravit co nejdříve a udržet systém v chodu. Také jsme viděli, jak může použití ClusterControl pomoci s těmito problémy; vše z jediné a uživatelsky přívětivé platformy.
Toto jsou podle nás některé z nejčastějších scénářů selhání PostgreSQL. Rádi bychom slyšeli o vašich vlastních zkušenostech a o tom, jak jste to napravili.