V mém předchozím blogu jsme diskutovali o různých způsobech výběru nebo skenování dat z jedné tabulky. Prakticky však načítání dat z jedné tabulky nestačí. Vyžaduje výběr dat z více tabulek a poté mezi nimi korelaci. Korelace těchto dat mezi tabulkami se nazývá spojovací tabulky a lze ji provádět různými způsoby. Vzhledem k tomu, že spojování tabulek vyžaduje vstupní data (např. ze skenu tabulky), nikdy nemůže být listovým uzlem ve vygenerovaném plánu.
Např. zvažte jednoduchý příklad dotazu jako SELECT * FROM TBL1, TBL2 kde TBL1.ID> TBL2.ID; a předpokládejme, že vygenerovaný plán je následující:
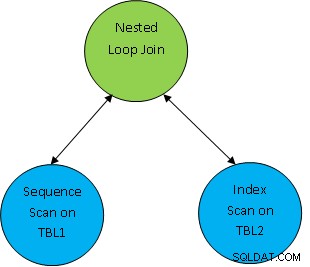
Takže zde se nejprve naskenují obě tabulky a poté se spojí dohromady jako podle korelační podmínky jako TBL.ID> TBL2.ID
Kromě metody spojení je velmi důležité také pořadí spojení. Zvažte níže uvedený příklad:
VYBRAT * Z TBL1, TBL2, TBL3, KDE TBL1.ID=TBL2.ID A TBL2.ID=TBL3.ID;
Uvažte, že TBL1, TBL2 a TBL3 mají 10, 100 a 1000 záznamů.
Podmínka TBL1.ID=TBL2.ID vrátí pouze 5 záznamů, zatímco TBL2.ID=TBL3.ID vrátí 100 záznamů, pak je lepší nejprve spojit TBL1 a TBL2, aby se získal menší počet záznamů spojený s TBL3. Plán bude vypadat následovně:
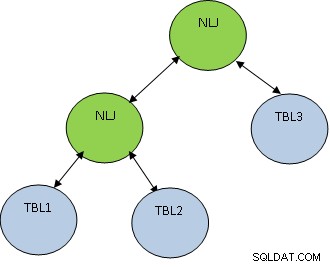
PostgreSQL podporuje níže uvedené druhy spojení:
- Připojení vnořené smyčky
- Hash Join
- Sloučit připojení
Každá z těchto metod spojení je stejně užitečná v závislosti na dotazu a dalších parametrech, např. dotaz, data tabulky, klauzule spojení, selektivita, paměť atd. Tyto metody spojení implementuje většina relačních databází.
Pojďme vytvořit nějakou přednastavenou tabulku a naplnit ji daty, která budou často používána k lepšímu vysvětlení těchto metod skenování.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEVe všech našich následujících příkladech bereme v úvahu výchozí konfigurační parametr, pokud není výslovně uvedeno jinak.
Připojení vnořené smyčky
Nested Loop Join (NLJ) je nejjednodušší spojovací algoritmus, ve kterém je každý záznam vnějšího vztahu spárován s každým záznamem vnitřního vztahu. Spojení mezi vztahem A a B s podmínkou A.ID NLJ (Nested Loop Join) je nejběžnější metoda spojení a lze ji použít téměř u jakékoli datové sady s jakýmkoli typem klauzule spojení. Protože tento algoritmus skenuje všechny n-tice vnitřních a vnějších vztahů, je považován za nejnákladnější operaci spojení. Podle výše uvedené tabulky a údajů bude výsledkem následujícího dotazu spojení Nested Loop Join, jak je uvedeno níže: Vzhledem k tomu, že klauzule spojení je „<“, jedinou možnou metodou spojení je zde spojení Nested Loop Join. Všimněte si jednoho nového druhu uzlu jako Materialize; tento uzel funguje jako mezipaměť výsledků, tj. místo načítání všech n-tic vztahu vícekrát, první načtený výsledek je uložen do paměti a při dalším požadavku na získání n-tice bude obsluhován z paměti namísto opětovného načítání ze stránek vztahu . V případě, že se všechny n-tice nevejdou do paměti, přelévací n-tice přejdou do dočasného souboru. Je to většinou užitečné v případě Nested Loop Join a do určité míry v případě Merge Join, protože spoléhají na rescan vnitřního vztahu. Materialize Node není omezen pouze na ukládání výsledků vztahu do mezipaměti, ale může do mezipaměti ukládat výsledky libovolného uzlu níže ve stromu plánu. TIP:V případě, že klauzule spojení je „=“ a mezi vztahem je vybráno spojení vnořené smyčky, pak je opravdu důležité prozkoumat, zda lze zvolit účinnější metodu spojení, jako je hash nebo sloučení spojení laděním konfigurace (např. work_mem, ale bez omezení na ) nebo přidáním indexu atd. Některé z dotazů nemusí mít klauzuli spojení, v tom případě je také jedinou možností, jak se připojit, spojení Nested Loop Join. Např. zvažte níže uvedené dotazy podle údajů o předběžném nastavení: Spojení ve výše uvedeném příkladu je pouze kartézský součin obou tabulek. Tento algoritmus funguje ve dvou fázích: Spojení mezi vztahem A a B s podmínkou A.ID =B.ID lze znázornit následovně: Podle výše uvedené tabulky přednastavení a dat bude výsledkem následujícího dotazu hash spojení, jak je uvedeno níže: Tady je hashovací tabulka vytvořena v tabulce blogtable2, protože je to menší tabulka, takže minimální paměť potřebná pro hashovací tabulku a celou hashovací tabulku se vejde do paměti. Merge Join je algoritmus, ve kterém je každý záznam vnějšího vztahu spárován s každým záznamem vnitřního vztahu, dokud neexistuje možnost shody klauzule spojení. Tento algoritmus spojení se používá pouze v případě, že jsou oba vztahy seřazeny a operátor klauzule spojení je „=“. Spojení mezi vztahem A a B s podmínkou A.ID =B.ID může být znázorněno následovně: Ukázkový dotaz, jehož výsledkem bylo spojení hash, jak je uvedeno výše, může vést ke spojení sloučení, pokud se index vytvoří v obou tabulkách. Je to proto, že data tabulky lze načíst v seřazeném pořadí kvůli indexu, což je jedno z hlavních kritérií pro metodu Merge Join: Jak tedy vidíme, obě tabulky používají indexové skenování namísto sekvenčního skenování, díky kterému budou obě tabulky vydávat setříděné záznamy. PostgreSQL podporuje různé konfigurace související s plánovačem, které lze použít k tomu, aby optimalizátor dotazů nevybral nějaký konkrétní druh metod spojení. Pokud metoda spojení zvolená optimalizátorem není optimální, lze tyto konfigurační parametry vypnout a přinutit optimalizátor dotazů zvolit jiný druh metod spojení. Všechny tyto konfigurační parametry jsou ve výchozím nastavení „zapnuty“. Níže jsou uvedeny konfigurační parametry plánovače specifické pro metody spojení. Existuje mnoho konfiguračních parametrů souvisejících s plánem používaných pro různé účely. V tomto blogu je omezení omezeno pouze na metody připojení. Tyto parametry lze upravit z konkrétní relace. Takže v případě, že chceme experimentovat s plánem z konkrétní relace, pak lze s těmito konfiguračními parametry manipulovat a ostatní relace budou nadále fungovat tak, jak jsou. Nyní zvažte výše uvedené příklady spojení sloučení a spojení hash. Bez indexu vybral optimalizátor dotazů pro níže uvedený dotaz spojení hash, jak je uvedeno níže, ale po použití konfigurace se přepne na spojení sloučení i bez indexu: Zpočátku je vybráno Hash Join, protože data z tabulek nejsou řazena. Aby bylo možné zvolit plán spojení sloučení, musí nejprve seřadit všechny záznamy získané z obou tabulek a poté použít spojení sloučení. Takže náklady na třídění budou dodatečné, a proto se celkové náklady zvýší. Je tedy možné, že v tomto případě jsou celkové (včetně zvýšených) nákladů vyšší než celkové náklady na Hash Join, takže je vybráno Hash Join. Jakmile je konfigurační parametr enable_hashjoin změněn na „off“, znamená to, že optimalizátor dotazů přímo přiřadí cenu spojení hash jako cenu zakázat (=1,0e10, tj. 10000000000,00). Náklady na případné připojení budou nižší. Takže stejný výsledek dotazu v Merge Join poté, co se enable_hashjoin změnil na „off“, protože i včetně nákladů na řazení jsou celkové náklady na spojení sloučení nižší než náklady na zakázání. Nyní zvažte následující příklad: Jak můžeme vidět výše, i když je konfigurační parametr související se spojením vnořené smyčky změněn na „vypnuto“, stále se volí spojení Nested Loop Join, protože neexistuje žádná alternativní možnost získání jakéhokoli jiného druhu metody spojení vybraný. Jednodušeji řečeno, protože Nested Loop Join je jediným možným spojením, pak bez ohledu na cenu bude vždy vítězem (Stejně jako jsem býval vítězem v závodě na 100 m, když jsem běžel sám...:-)). Všimněte si také rozdílu v nákladech v prvním a druhém plánu. První plán ukazuje skutečnou cenu spojení Nested Loop Join, ale druhý ukazuje cenu za deaktivaci téhož. Všechny druhy metod spojení PostgreSQL jsou užitečné a vybírají se na základě povahy dotazu, dat, klauzule spojení atd. V případě, že dotaz nefunguje podle očekávání, tj. metody spojení nefungují Pokud je pak vybrán podle očekávání, může si uživatel pohrát s různými dostupnými parametry konfigurace plánu a zjistit, zda něco nechybí.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)Hash Join
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Sloučit připojení
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)Konfigurace
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)Závěr