Když potřebujete implementovat analytický systém pro společnost, často vyvstává otázka, kde by měla být data uložena. Ne vždy existuje perfektní volba pro všechny požadavky a záleží na rozpočtu, množství dat a potřebách společnosti.
PostgreSQL jako nejpokročilejší open source databáze je natolik flexibilní, že může sloužit jako jednoduchá relační databáze, databáze časových řad a dokonce i jako efektivní, nízkonákladové řešení pro ukládání dat. Můžete jej také integrovat s několika analytickými nástroji.
Pokud hledáte široce kompatibilní, levný a výkonný datový sklad, nejlepší možností databáze by mohla být PostgreSQL, ale proč? V tomto blogu uvidíme, co je datový sklad, proč je potřeba a proč by zde mohl být PostgreSQL tou nejlepší volbou.
Co je to datový sklad
Datový sklad je systém standardizovaného, konzistentního a integrovaného systému, který obsahuje aktuální nebo historická data z jednoho nebo více zdrojů, která se používají pro vytváření sestav a analýzu dat. Je považována za základní součást business intelligence, což je strategie a technologie používaná společností k lepšímu pochopení jejího komerčního kontextu.
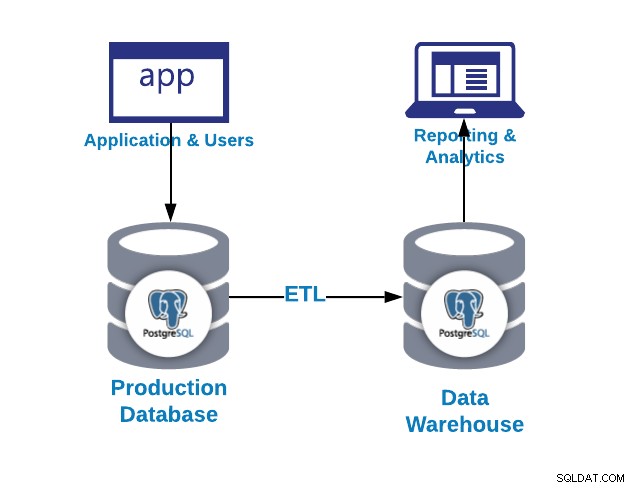
První otázka, kterou si můžete položit, je, proč potřebuji datový sklad?
- Integrace:Integrace/centralizace dat z více systémů/databází
- Standardizovat:Standardizujte všechna data ve stejném formátu
- Analytika:Analýza dat v historickém kontextu
Některé z výhod datového skladu mohou být...
- Integrujte data z více zdrojů do jediné databáze
- Vyhněte se zablokování produkce nebo načítání kvůli dlouhotrvajícím dotazům
- Ukládání historických informací
- Restrukturalizovat data tak, aby odpovídala analytickým požadavkům
Jak jsme mohli vidět na předchozím obrázku, PostgreSQL můžeme použít pro návrhy OLAP i OLTP. Pojďme se podívat na rozdíl.
- OLTP:Zpracování online transakcí. Obecně má velké množství krátkých on-line transakcí (INSERT, UPDATE, DELETE) generovaných aktivitou uživatele. Tyto systémy kladou důraz na velmi rychlé zpracování dotazů a zachování integrity dat v prostředích s více přístupy. Zde se efektivita měří počtem transakcí za sekundu. Databáze OLTP obsahují podrobná a aktuální data.
- OLAP:Online analytické zpracování. Obecně má malý objem komplexních transakcí generovaných velkými sestavami. Doba odezvy je měřítkem účinnosti. Tyto databáze ukládají agregovaná historická data ve vícerozměrných schématech. Databáze OLAP se používají k analýze vícerozměrných dat z různých zdrojů a perspektiv.
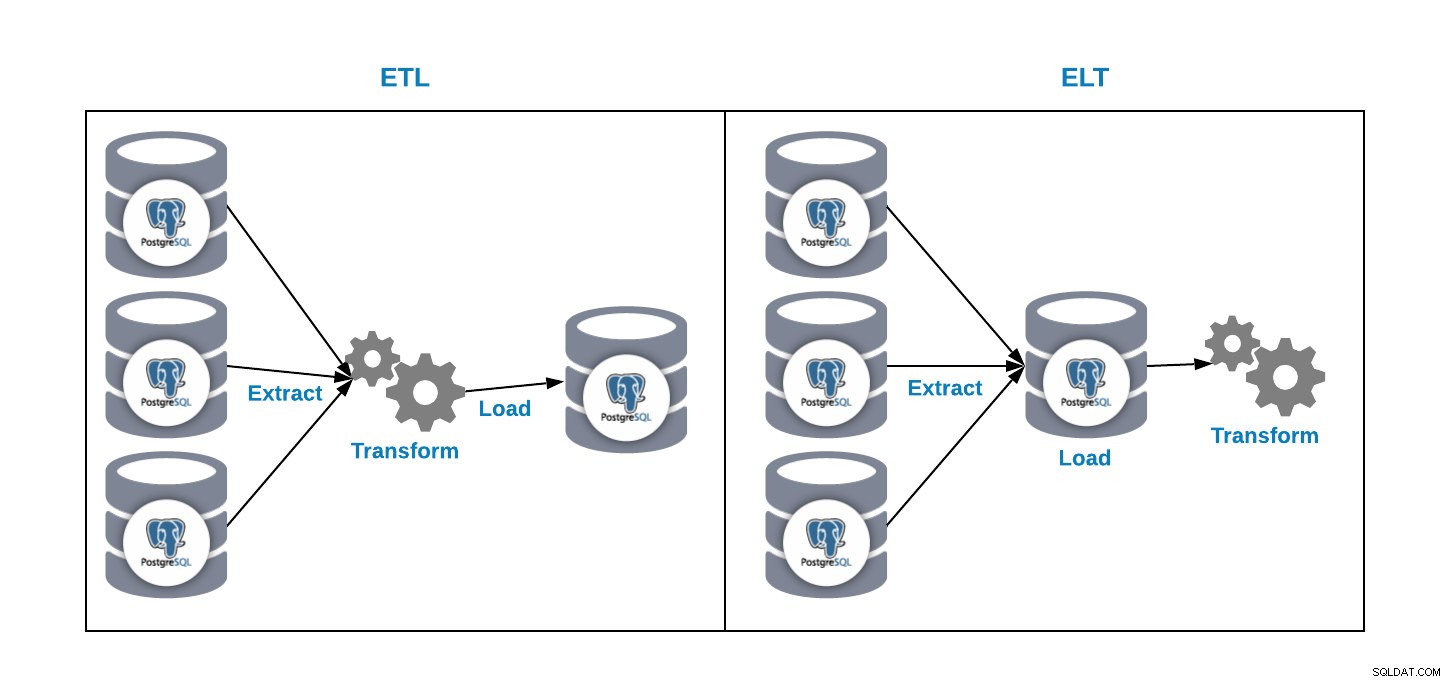
Máme dva způsoby, jak načíst data do naší analytické databáze:
- ETL:Extrahujte, transformujte a načtěte. Toto je způsob, jak generovat náš datový sklad. Nejprve extrahujte data z produkční databáze, transformujte data podle našich požadavků a poté je načtěte do našeho datového skladu.
- ELT:Extrahujte, načtěte a transformujte. Nejprve extrahujte data z produkční databáze, načtěte je do databáze a poté data transformujte. Tento způsob se nazývá Data Lake a je to nový koncept pro správu našich velkých dat.
A teď druhá otázka, proč bych měl používat PostgreSQL pro svůj datový sklad?
Výhody PostgreSQL jako datového skladu
Podívejme se na některé výhody používání PostgreSQL jako datového skladu...
- Cena:Pokud používáte on-prem prostředí, cena za samotný produkt bude 0 $, i když používáte nějaký produkt v cloudu, pravděpodobně budou náklady na produkt založený na PostgreSQL nižší než zbytek produktů.
- Měřítko:Čtení můžete škálovat jednoduchým způsobem přidáním libovolného počtu replikovaných uzlů.
- Výkon:Se správnou konfigurací má PostgreSQL opravdu dobrý výkon v různých scénářích.
- Kompatibilita:PostgreSQL můžete integrovat s externími nástroji nebo aplikacemi pro dolování dat, OLAP a reporting.
- Rozšiřitelnost:PostgreSQL má uživatelsky definované datové typy a funkce.
Existují také některé funkce PostgreSQL, které nám mohou pomoci spravovat informace o našem datovém skladu...
- Dočasné tabulky:Jedná se o krátkodobou tabulku, která existuje po dobu trvání relace databáze. PostgreSQL automaticky zruší dočasné tabulky na konci relace nebo transakce.
- Uložené procedury:Můžete je použít k vytváření procedur nebo funkcí ve více jazycích (PL/pgSQL, PL/Perl, PL/Python atd.).
- Rozdělení:Toto je opravdu užitečné pro údržbu databáze, dotazy pomocí klíče oddílu a výkonu INSERT.
- Materializované zobrazení:Výsledky dotazu se zobrazí jako tabulka.
- Tabulkové prostory:Umístění dat můžete změnit na jiný disk. Tímto způsobem budete mít paralelní přístup k disku.
- Kompatibilní s PITR:Můžete vytvářet zálohy kompatibilní s obnovou v určitém okamžiku, takže v případě selhání můžete obnovit stav databáze v určitém časovém období.
- Obrovská komunita:A v neposlední řadě má PostgreSQL obrovskou komunitu, kde můžete najít podporu v mnoha různých problémech.
Konfigurace PostgreSQL pro použití datového skladu
Neexistuje žádná nejlepší konfigurace pro použití ve všech případech a ve všech databázových technologiích. Závisí to na mnoha faktorech, jako je hardware, použití a systémové požadavky. Níže je uvedeno několik tipů, jak správně nakonfigurovat databázi PostgreSQL, aby fungovala jako datový sklad.
Na základě paměti
- max_connections:Jako databáze datového skladu nepotřebujete velké množství připojení, protože se bude používat pro vytváření sestav a analytické práce, takže pomocí tohoto parametru můžete omezit maximální počet připojení.
- shared_buffers:Nastavuje množství paměti, kterou databázový server používá pro vyrovnávací paměti sdílené paměti. Rozumná hodnota může být od 15 % do 25 % paměti RAM.
- effective_cache_size:Tuto hodnotu používá plánovač dotazů k zohlednění plánů, které se mohou nebo nemusí vejít do paměti. To je zohledněno v odhadech nákladů na použití indexu; vysoká hodnota zvyšuje pravděpodobnost použití indexových skenů a nízká hodnota zvyšuje pravděpodobnost, že budou použita sekvenční skenování. Rozumná hodnota by byla kolem 75 % paměti RAM.
- work mem:Určuje množství paměti, které bude využito vnitřními operacemi tabulek ORDER BY, DISTINCT, JOIN a hash před zápisem do dočasných souborů na disk. Při konfiguraci této hodnoty musíme vzít v úvahu, že tyto operace provádí několik relací současně a každá operace bude mít povoleno použít tolik paměti, kolik určuje tato hodnota, než začne zapisovat data do dočasných souborů. Rozumná hodnota může být kolem 2 % paměti RAM.
- maintenance_work_mem:Určuje maximální množství paměti, kterou budou používat operace údržby, jako je VACUUM, CREATE INDEX a ALTER TABLE ADD FOREIGN KEY. Rozumná hodnota může být kolem 15 % paměti RAM.
Založeno na CPU
- Max_worker_processes:Nastavuje maximální počet procesů na pozadí, které může systém podporovat. Rozumnou hodnotou může být počet CPU.
- Max_parallel_workers_per_gather:Nastavuje maximální počet pracovníků, které může spustit jeden uzel Gather nebo Gather Merge. Přiměřená hodnota může být 50 % počtu CPU.
- Max_parallel_workers:Nastavuje maximální počet pracovníků, které může systém podporovat pro paralelní dotazy. Rozumnou hodnotou může být počet CPU.
Vzhledem k tomu, že data načtená do našeho datového skladu by se neměla měnit, můžeme také vypnout Autovakuum, abychom předešli dodatečnému zatížení vaší PostgreSQL databáze. Procesy vakuování a analýzy mohou být součástí procesu dávkového načítání.
Závěr
Pokud hledáte široce kompatibilní, levný a vysoce výkonný datový sklad, určitě byste měli zvážit PostgreSQL jako možnost pro vaši databázi datového skladu. PostgreSQL má mnoho výhod a funkcí užitečných pro správu našeho datového skladu, jako je dělení nebo uložené procedury a ještě více.