Ve světě informačních technologií není automatizace pro většinu z nás nic nového. Ve skutečnosti jej většina organizací používá pro různé účely v závislosti na typu jejich práce a cílech. Například datoví analytici používají automatizaci ke generování zpráv, správci systémů používají automatizaci pro své opakující se úkoly, jako je čištění místa na disku, a vývojáři používají automatizaci k automatizaci procesu vývoje.
V dnešní době je k dispozici mnoho automatizačních nástrojů pro IT a lze si je vybrat díky éře DevOps. Jaký je nejlepší nástroj? Odpověď je předvídatelná „záleží“, protože závisí na tom, čeho se snažíme dosáhnout, a také na nastavení našeho prostředí. Některé z automatizačních nástrojů jsou Terraform, Bolt, Chef, SaltStack a velmi trendy je Ansible. Ansible je open-source IT engine bez agentů, který dokáže automatizovat nasazení aplikací, správu konfigurace a orchestraci IT. Ansible byla založena v roce 2012 a byla napsána v nejpopulárnějším jazyce, Pythonu. K implementaci veškeré automatizace používá playbook, kde jsou všechny konfigurace napsány v lidsky čitelném jazyce, YAML.
V dnešním příspěvku se naučíme, jak používat Ansible k nasazení databáze Postgresql.
Co dělá Ansible speciální?
Důvod, proč se ansible používá hlavně kvůli jeho vlastnostem. Tyto funkce jsou:
-
Cokoli lze automatizovat pomocí jednoduchého jazyka YAML čitelného lidem
-
Na vzdálený počítač nebude nainstalován žádný agent (architektura bez agenta)
-
Konfigurace bude přenesena z místního počítače na server z místního počítače (model push)
-
Vyvinuto pomocí Pythonu (jeden z aktuálně používaných populárních jazyků) a lze si vybrat z mnoha knihoven
-
Kolekce modulů Ansible pečlivě vybraných týmem Red Had Engineering
The Way Ansible Works
Než bude moci Ansible spouštět jakékoli provozní úlohy na vzdálených hostitelích, musíme jej nainstalovat do jednoho hostitele, který se stane řídicím uzlem. V tomto uzlu řadiče budeme orchestrovat všechny úkoly, které bychom chtěli provést, do vzdálených hostitelů známých také jako spravované uzly.
Uzel řadiče musí mít inventář spravovaných uzlů a software Ansible k jeho správě. Požadovaná data, která má Ansible používat, jako je název hostitele nebo IP adresa spravovaného uzlu, budou umístěna do tohoto inventáře. Bez řádné inventury by Ansible nemohla automatizaci správně provést. Zde se dozvíte více o inventáři.
Ansible je bez agenta a k prosazení změn používá SSH, což znamená, že nemusíme instalovat Ansible do všech uzlů, ale všechny spravované uzly musí mít nainstalovaný python a všechny potřebné knihovny pythonu. Uzel řadiče i spravované uzly musí být nastaveny jako bez hesla. Stojí za zmínku, že spojení mezi všemi řídicími uzly a spravovanými uzly je dobré a řádně otestované.
Pro tuto ukázku jsem zřídil 4 virtuální počítače Centos 8 pomocí vagrant. Jeden bude fungovat jako uzel řadiče a další 2 virtuální počítače budou fungovat jako uzly databáze, které se mají nasadit. V tomto blogovém příspěvku se nezabýváme podrobnostmi o tom, jak nainstalovat Ansible, ale v případě, že byste chtěli vidět průvodce, neváhejte navštívit tento odkaz. Všimněte si, že k nastavení topologie replikace datového proudu používáme 3 uzly s jedním primárním a 2 pohotovostními uzly. V současné době je mnoho produkčních databází nastaveno na vysokou dostupnost a 3 uzlové nastavení je běžné.
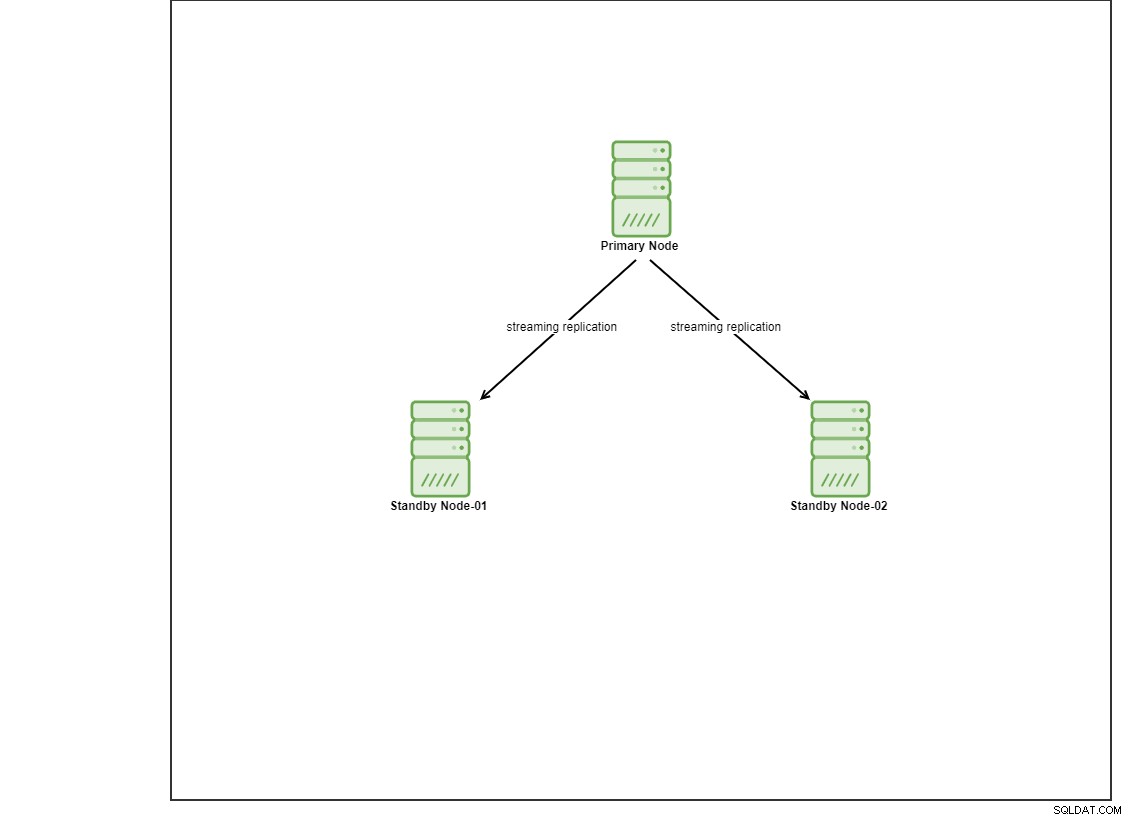
Instalace PostgreSQL
Existuje několik způsobů, jak nainstalovat PostgreSQL pomocí Ansible. Dnes k dosažení tohoto účelu použiji Ansible Roles. Ansible Roles v kostce je sada úloh pro konfiguraci hostitele, aby sloužil určitému účelu, jako je konfigurace služby. Ansible Role jsou definovány pomocí souborů YAML s předdefinovanou adresářovou strukturou dostupnou ke stažení z portálu Ansible Galaxy.
Ansible Galaxy na druhé straně je úložiště pro role Ansible, které lze vložit přímo do vašich Příruček, abyste zefektivnili své projekty automatizace.
Pro toto demo jsem vybral role, které udržoval dudefellah. Abychom mohli tuto roli využívat, musíme si ji stáhnout a nainstalovat do uzlu řadiče. Úloha je docela přímočará a lze ji provést spuštěním následujícího příkazu za předpokladu, že byl na váš uzel řadiče nainstalován Ansible:
$ ansible-galaxy install dudefellah.postgresqlPo úspěšné instalaci role do uzlu řadiče byste měli vidět následující výsledek:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
Abychom mohli nainstalovat PostgreSQL pomocí této role, je potřeba provést několik kroků. Zde přichází Ansible Playbook. Ansible Playbook je místo, kde můžeme napsat Ansible kód nebo kolekci skriptů, které bychom chtěli spouštět na spravovaných uzlech. Ansible Playbook používá YAML a skládá se z jednoho nebo více přehrávání spuštěných v určitém pořadí. Můžete definovat hostitele a také sadu úloh, které byste chtěli spouštět na přiřazených hostitelích nebo spravovaných uzlech.
Všechny úlohy budou provedeny jako uživatel, který se přihlásil. Abychom mohli provádět úlohy s jiným uživatelem, včetně uživatele root, můžeme použít příkaz stát. Podívejme se na pg-play.yml níže:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Jak můžete vidět, definoval jsem hostitele jako pgcluster a využil jsem stav, aby Ansible spouštěl úlohy s privilegiem sudo. Uživatel vagrant je již ve skupině sudoer. Také jsem definoval roli, kterou jsem nainstaloval dudefellah.postgresql. pgcluster byl definován v souboru hosts, který jsem vytvořil. Pokud vás zajímá, jak to vypadá, můžete se podívat níže:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleKromě toho jsem vytvořil další vlastní soubor (custom_var.yml), do kterého jsem zahrnul veškerou konfiguraci a nastavení pro PostgreSQL, které bych chtěl implementovat. Podrobnosti pro vlastní soubor jsou uvedeny níže:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }Pro spuštění instalace stačí provést následující příkaz. Bez vytvořeného souboru playbook (v mém případě je to pg-play.yml) nebudete moci spustit příkaz ansible-playbook.
$ ansible-playbook pg-play.yml -i pghostPo provedení tohoto příkazu spustí několik úloh definovaných rolí a v případě úspěšného provedení příkazu zobrazí tuto zprávu:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12Jakmile ansible dokončil úkoly, přihlásil jsem se do slave (n2), zastavil službu PostgreSQL, odstranil obsah datového adresáře (/var/lib/pgsql/13/data/) a spusťte následující příkaz k zahájení úlohy zálohování:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |Po spuštění služby PostgreSQL můžeme také zkontrolovat stav replikace v pohotovostním režimu pomocí následujícího příkazu:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyJak vidíte, je potřeba udělat spoustu práce, abychom mohli nastavit replikaci pro PostgreSQL, i když jsme některé úkoly zautomatizovali. Podívejme se, jak toho lze dosáhnout pomocí ClusterControl.
Nasazení PostgreSQL pomocí GUI ClusterControl
Nyní, když víme, jak nasadit PostgreSQL pomocí Ansible, pojďme se podívat, jak můžeme nasadit pomocí ClusterControl. ClusterControl je software pro správu a automatizaci databázových clusterů včetně MySQL, MariaDB, MongoDB a TimescaleDB. Pomáhá nasazovat, monitorovat, spravovat a škálovat váš databázový cluster. Existují dva způsoby nasazení databáze, v tomto příspěvku na blogu vám ukážeme, jak ji nasadit pomocí grafického uživatelského rozhraní (GUI) za předpokladu, že již máte ve svém prostředí nainstalovaný ClusterControl.
Prvním krokem je přihlásit se do ClusterControl a kliknout na Deploy:
Zobrazí se vám níže uvedený snímek obrazovky pro další krok nasazení , pokračujte výběrem záložky PostgreSQL:
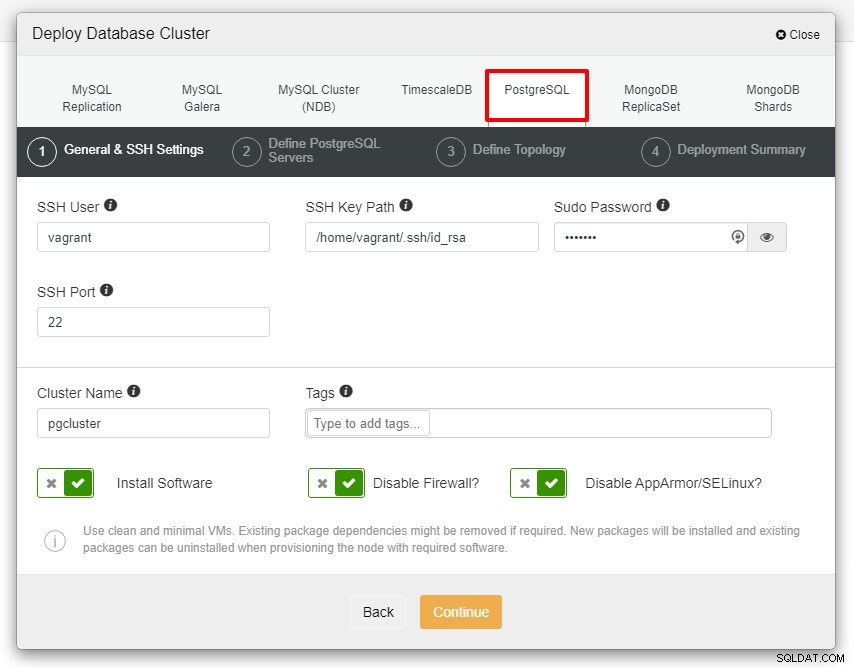
Než se přesuneme dále, rád bych vám připomněl, že spojení mezi uzlem ClusterControl a uzly databází musí být bez hesla. Před nasazením vše, co musíme udělat, je vygenerovat ssh-keygen z uzlu ClusterControl a poté jej zkopírovat do všech uzlů. Vyplňte vstup pro uživatele SSH, heslo Sudo a název clusteru podle svých požadavků a klikněte na Pokračovat.
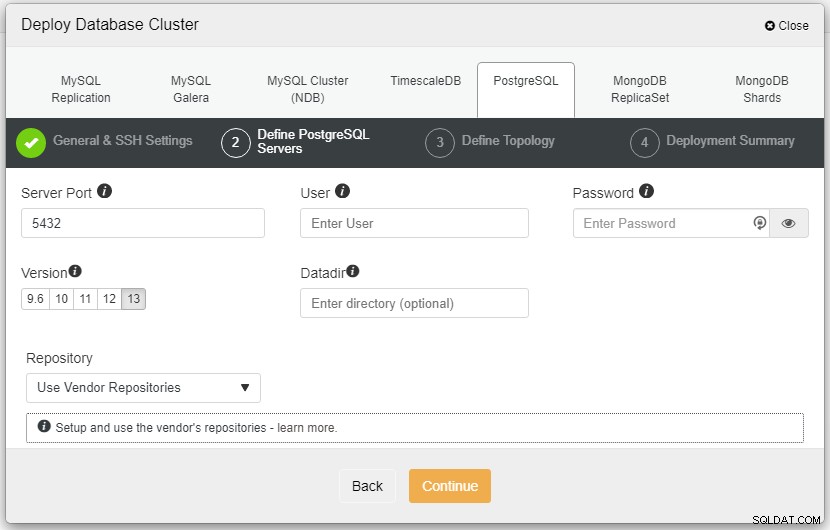
Na výše uvedeném snímku obrazovky budete muset definovat port serveru (v případě, že byste chtěli použít jiné), uživatele, kterého chcete, a také heslo a požadovanou verzi nainstalovat.
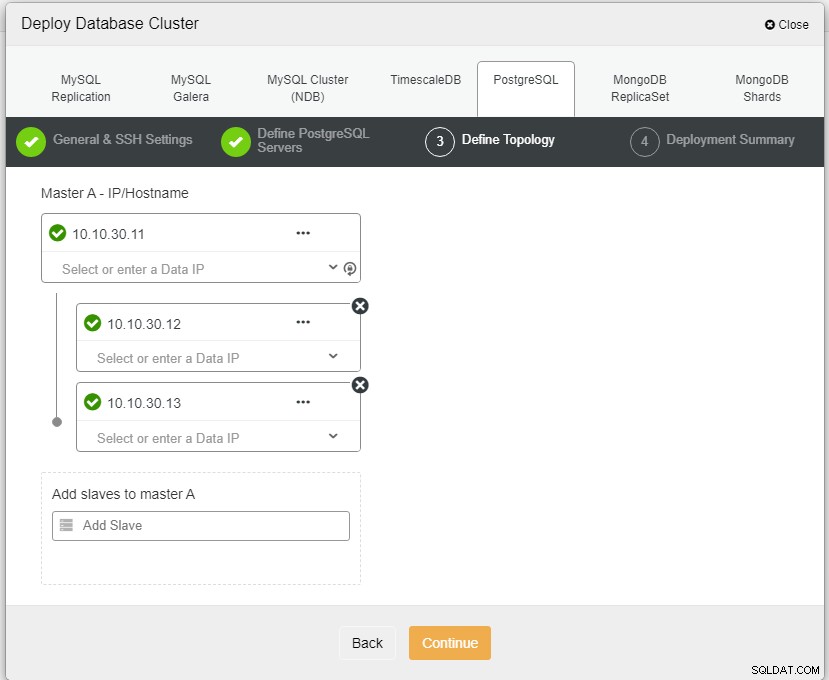
Zde musíme definovat servery buď pomocí názvu hostitele nebo IP adresy, jako v tomto případě 1 master a 2 slave. Posledním krokem je výběr režimu replikace pro náš cluster.
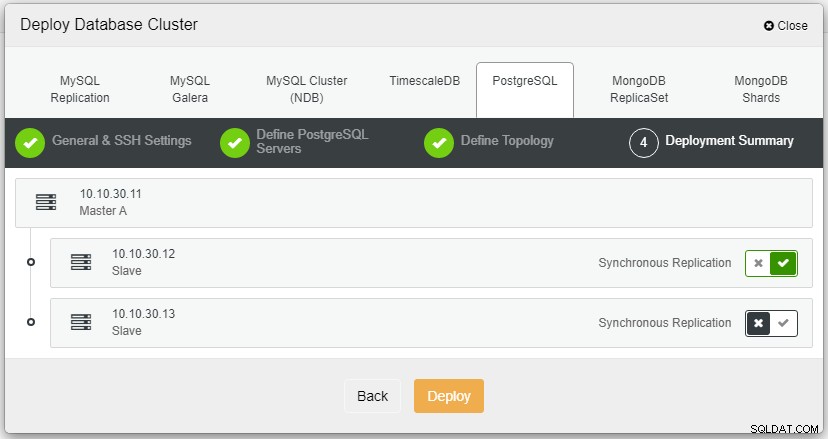
Po kliknutí na Nasadit se zahájí proces nasazení a my můžeme sledovat průběh na kartě Aktivita.
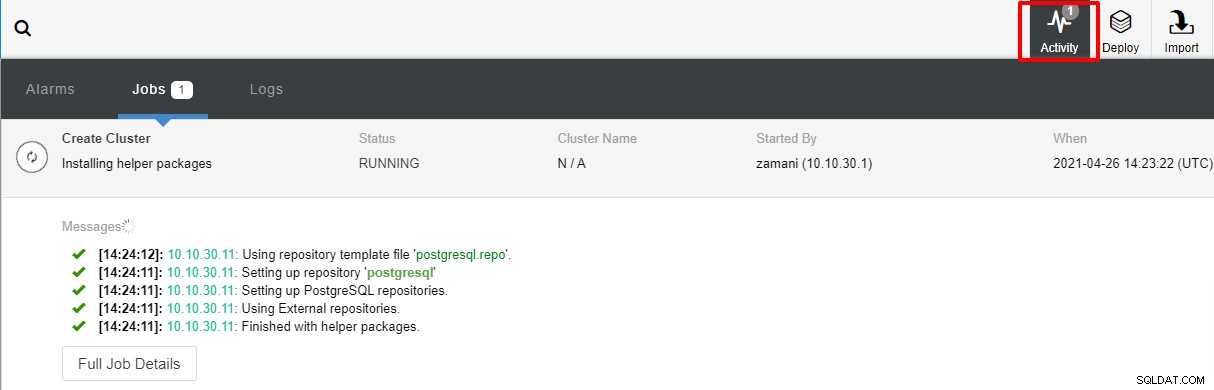
Nasazení obvykle trvá několik minut, výkon závisí především na síti a specifikacích serveru.

Nyní, když máme PostgreSQL nainstalovaný pomocí ClusterControl.
Nasazení PostgreSQL pomocí rozhraní CLI ClusterControl
Dalším alternativním způsobem nasazení PostgreSQL je použití CLI. za předpokladu, že jsme již nakonfigurovali připojení bez hesla, můžeme pouze provést následující příkaz a nechat jej dokončit.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logPo úspěšném dokončení procesu by se měla zobrazit níže uvedená zpráva a můžete se přihlásit na web ClusterControl a ověřit:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Závěr
Jak můžete vidět, existuje několik způsobů, jak nasadit PostgreSQL. V tomto blogovém příspěvku jsme se naučili, jak jej nasadit pomocí Ansible a také pomocí našeho ClusterControl. Oba způsoby jsou snadno sledovatelné a lze jich dosáhnout s minimální křivkou učení. S ClusterControl lze nastavení streamingové replikace doplnit o HAProxy, VIP a PGBouncer a přidat do nastavení převzetí služeb při selhání, virtuální IP a sdružování připojení.
Všimněte si, že nasazení je pouze jedním aspektem prostředí produkční databáze. Udržování v chodu, automatizace převzetí služeb při selhání, obnova poškozených uzlů a další aspekty, jako je monitorování, upozorňování a zálohování, jsou zásadní.
Doufáme, že tento příspěvek na blogu bude pro některé z vás přínosem a poskytne nápad, jak automatizovat nasazení PostgreSQL.