V předchozím příspěvku na blogu jsem stručně vysvětlil, jak jsme získali výkonová čísla zveřejněná v pglogickém oznámení. V tomto příspěvku na blogu bych rád probral limity výkonu řešení logické replikace obecně a také to, jak se vztahují na pglogic.
fyzická replikace
Nejprve se podívejme, jak funguje fyzická replikace (zabudovaná do PostgreSQL od verze 9.0). Poněkud zjednodušený obrázek se dvěma pouze dvěma uzly vypadá takto:
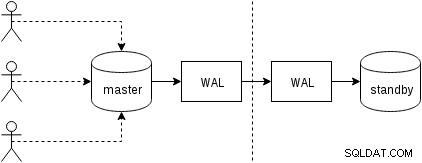
Klienti provádějí dotazy na hlavním uzlu, změny jsou zapsány do protokolu transakcí (WAL) a zkopírovány přes síť do WAL v pohotovostním uzlu. Proces obnovy v pohotovostním režimu v pohotovostním režimu pak načte změny z WAL a aplikuje je na datové soubory stejně jako během obnovy. Pokud je pohotovostní režim v režimu „hot_standby“, mohou klienti během této doby zadávat na uzlu dotazy pouze pro čtení.
To je velmi efektivní, protože je zde velmi málo dodatečného zpracování – změny se přenášejí a zapisují do pohotovostního režimu jako neprůhledný binární blob. Obnova samozřejmě není zdarma (jak z hlediska CPU, tak I/O), ale je obtížné dosáhnout vyšší efektivity.
Zjevnými potenciálními překážkami fyzické replikace jsou šířka pásma sítě (přenos WAL z hlavního do pohotovostního režimu) a také I/O v pohotovostním režimu, které mohou být přesyceny procesem obnovy, který často vydává spoustu náhodných I/O požadavků ( v některých případech více než mistr, ale do toho se nepouštějme).
logická replikace
Logická replikace je o něco složitější, protože se nezabývá neprůhledným binárním WAL proudem, ale proudem „logických“ změn (představte si příkazy INSERT, UPDATE nebo DELETE, i když to není úplně správné, protože se zabýváme strukturovanou reprezentací data). Logické změny umožňují dělat zajímavé věci, jako je řešení konfliktů, replikace pouze vybraných tabulek, do jiného schématu nebo mezi různými verzemi (nebo dokonce různými databázemi).
Existují různé způsoby, jak získat změny – tradičním přístupem je použití spouštěčů, které zaznamenávají změny do tabulky a umožňují vlastnímu procesu průběžně tyto změny číst a aplikovat je v pohotovostním režimu spouštěním SQL dotazů. A to vše je řízeno procesem externího démona (nebo možná více procesů běžících na obou uzlech), jak je znázorněno na dalším obrázku

To je to, co dělají slony nebo londiste, a i když to fungovalo docela dobře, znamená to spoustu režie – například to vyžaduje zachycení změn dat a zapsání dat vícekrát (do původní tabulky a do tabulky „log“ a také na WAL pro obě tyto tabulky). Další zdroje režie probereme později. Zatímco pglogic potřebuje dosáhnout stejných cílů, dosahuje jich odlišně, a to díky několika funkcím přidaným do posledních verzí PostgreSQL (tedy nedostupné, když byly implementovány ostatní nástroje):

To znamená, že místo udržování samostatného protokolu změn se pglogical spoléhá na WAL – to je možné díky logickému dekódování dostupnému v PostgreSQL 9.4, které umožňuje extrahovat logické změny z protokolu WAL. Díky tomu pglogical nepotřebuje žádné drahé spouštěče a obvykle se může vyhnout dvojímu zápisu dat na master (kromě velkých transakcí, které se mohou přelít na disk).
Po dekódování se každá transakce přenese do pohotovostního režimu a proces aplikace aplikuje změny do pohotovostní databáze. pglogical neaplikuje změny spuštěním běžných SQL dotazů, ale na nižší úrovni, čímž obchází režii spojenou s analýzou a plánováním SQL dotazů. To dává pglogic významnou výhodu oproti stávajícím řešením, která všechna procházejí vrstvou SQL (a platí tedy analýzu a plánování).
potenciální úzká hrdla
Je zřejmé, že logická replikace je náchylná ke stejným úzkým místům jako fyzická replikace, tj. je možné saturovat síť při přenosu změn a I/O v pohotovostním režimu, když je aplikujete v pohotovostním režimu. Existuje také značné množství režie kvůli dalším krokům, které nejsou přítomny ve fyzické replikaci.
Potřebujeme nějak shromáždit logické změny, zatímco fyzická replikace jednoduše přepošle WAL jako proud bajtů. Jak již bylo zmíněno, existující řešení obvykle spoléhají na spouštěče zapisující změny do tabulky „log“. pglogical se místo toho spoléhá na záznam napřed (WAL) a logické dekódování, aby dosáhl stejné věci, což je levnější než spouštěče a také nemusí ve většině případů zapisovat data dvakrát (s přidaným bonusem, že změny automaticky aplikujeme v pořadí potvrzení).
To neznamená, že neexistují žádné příležitosti pro další vylepšení – například k dekódování v současnosti dochází až po potvrzení transakce, takže u velkých transakcí to může zvýšit zpoždění replikace. Fyzická replikace jednoduše přenáší změny WAL do jiného uzlu, a proto nemá toto omezení. Velké transakce se také mohou přelít na disk, což způsobí duplicitní zápisy, protože upstream je musí ukládat, dokud nejsou potvrzeny a mohou být odeslány downstreamu.
Budoucí práce jsou plánovány tak, aby umožnily pglogical začít streamovat velké transakce, zatímco jsou stále v procesu na upstreamu, čímž se sníží latence mezi upstreamem a downstream commitem a sníží se zesílení upstream zápisu.
Poté, co se změny přenesou do pohotovostního režimu, musí je proces aplikace nějak skutečně použít. Jak bylo zmíněno v předchozí části, stávající řešení toho dosáhla konstruováním a prováděním příkazů SQL, zatímco pglogic zcela obchází vrstvu SQL a související režii.
Přesto to neznamená, že je aplikace zcela bezplatná, protože stále potřebuje provádět věci, jako je vyhledávání primárního klíče, aktualizace indexů, spouštění spouštěčů a provádění různých dalších kontrol. Ale je to výrazně levnější než přístup založený na SQL. V jistém smyslu to funguje podobně jako COPY a je obzvláště rychlé na jednoduchých tabulkách bez spouštěčů, cizích klíčů atd.
Ve všech řešeních logické replikace se každý z těchto kroků (dekódování a použití) odehrává v jediném procesu, takže je zde poměrně omezené množství času CPU. Toto je pravděpodobně nejnaléhavější překážka ve všech existujících řešeních, protože můžete mít docela robustní stroj s desítkami nebo dokonce stovkami klientů spouštějících dotazy paralelně, ale to vše musí projít jediným procesem dekódování těchto změn (na master) a jeden proces používající tyto změny (v pohotovostním režimu).
Omezení "jednoho procesu" může být poněkud uvolněno použitím samostatných databází, protože každá databáze je zpracovávána samostatným procesem. Pokud jde o jedinou databázi, plánuje se budoucí práce na paralelizaci aplikací prostřednictvím skupiny pracovníků na pozadí, aby se toto úzké místo zmírnilo.