PostgreSQL je úžasný projekt a vyvíjí se úžasnou rychlostí. Zaměříme se na vývoj schopností odolnosti proti chybám v PostgreSQL ve všech jeho verzích s řadou blogových příspěvků. Toto je druhý příspěvek ze série a budeme hovořit o replikaci a jejím významu pro odolnost vůči chybám a spolehlivost PostgreSQL.
Pokud byste chtěli být svědky pokroku ve vývoji od začátku, podívejte se prosím na první blogový příspěvek série:Evolution of Fault Tolerance in PostgreSQL
Replikace PostgreSQL
Replikace databáze je termín, který používáme k popisu technologie používané k údržbě kopie sady dat na vzdáleném Systém. Udržování spolehlivé kopie běžícího systému je jedním z největších problémů redundance a všichni máme rádi udržovatelné, snadno použitelné a stabilní kopie našich dat.
Podívejme se na základní architekturu. Jednotlivé databázové servery se obvykle označují jako uzly . Celá skupina databázových serverů zapojených do replikace se nazývá klastr . Databázový server, který umožňuje uživateli provádět změny, se nazývá master nebo primární nebo mohou být popsány jako zdroj změn. Databázový server, který pouze umožňuje přístup pouze pro čtení je známý jako horký pohotovostní režim . (Termín horkého pohotovostního režimu je podrobně vysvětlen pod názvem Režimy pohotovostního režimu. )
Klíčovým aspektem replikace je, že změny dat jsou zachyceny na hlavním serveru a poté přeneseny do jiných uzlů. V některých případech může uzel odesílat změny dat jiným uzlům, což je proces známý jako kaskádové nebo relé . Master je tedy odesílající uzel, ale ne všechny odesílající uzly musí být mastery. Replikace je často kategorizována podle toho, zda je povoleno více než jeden hlavní uzel, v takovém případě bude známá jako multimaster replikace .
Podívejme se, jak PostgreSQL zpracovává replikaci v průběhu času a jaká je nejmodernější odolnost proti chybám podle podmínek replikace.
Historie replikace PostgreSQL
Historicky (kolem roku 2000-2005) se Postgres soustředil pouze na toleranci/obnovu chyb jednoho uzlu, které je většinou dosahováno protokolem transakcí WAL. Odolnost vůči chybám je částečně řešena systémem MVCC (multi-version concurrency system), ale je to hlavně optimalizace.
Protokolování napřed bylo a stále je největší metodou odolnosti proti chybám v PostgreSQL. V podstatě stačí mít soubory WAL, kam zapíšete vše, a můžete se zotavit z hlediska selhání jejich přehráním. To stačilo pro architektury s jedním uzlem a replikace je považována za nejlepší řešení pro dosažení odolnosti proti chybám s více uzly.
Komunita Postgresu dlouho věřila, že replikace je něco, co by Postgres neměl poskytovat a mělo by být řešeno externími nástroji, proto se staly nástroje jako Slony a Londiste. (Řešením replikace založeným na spouštěči se budeme věnovat v dalších příspěvcích na blogu této série.)
Nakonec se ukázalo, že jedna tolerance serveru nestačí a více lidí požadovalo správnou odolnost hardwaru a správný způsob přepínání, něco vestavěného v Postgresu. To je okamžik, kdy fyzická (poté fyzické streamování) replikace ožila.
Projdeme si všechny metody replikace později v příspěvku, ale podívejme se na chronologické události historie replikace PostgreSQL podle hlavních vydání:
- PostgreSQL 7.x (~2000)
- Replikace by neměla být součástí jádra Postgres
- Londiste – Slony (logická replikace založená na spouštěči)
- PostgreSQL 8.0 (2005)
- Obnova bodu v čase (WAL)
- PostgreSQL 9.0 (2010)
- Streamová replikace (fyzická)
- PostgreSQL 9.4 (2014)
- Logické dekódování (extrakce sady změn)
Fyzická replikace
PostgreSQL vyřešil potřebu replikace jádra tím, co dělá většina relačních databází; vzal WAL a umožnil jeho odeslání přes síť. Poté jsou tyto soubory WAL aplikovány do samostatné instance Postgres, která běží pouze pro čtení.
Pohotovostní instance pouze pro čtení pouze aplikuje změny (podle WAL) a jediné zápisové operace pocházejí znovu ze stejného protokolu WAL. V zásadě jde o replikaci streamování mechanismus funguje. Na začátku replikace původně dodávala všechny soubory –log shipping- , ale později se z toho vyvinulo streamování.
Při odesílání protokolu jsme posílali celé soubory pomocí příkazu archivu . Logika je zde velmi jednoduchá:stačí odeslat archiv a log někam – jako celý 16 MB WAL soubor – a pak použiješ ji někam a pak ji načtete další a použijte ten a jde to tak. Později se to stalo streamováním přes síť pomocí protokolu libpq v PostgreSQL verze 9.0.
Stávající replikace je lépe známá jako Physical Streaming Replication protože streamujeme řadu fyzických změn z jednoho uzlu do druhého. To znamená, že když vložíme řádek do tabulky vygenerujeme záznamy změn provložku plus všechny položky rejstříku .
Když VACUUM tabulka, kterou také generujeme záznamy změn.
Replikace fyzického streamování také zaznamenává všechny změny na úrovni bajtů/bloků , takže je velmi těžké dělat něco jiného, než jen přehrát všechno
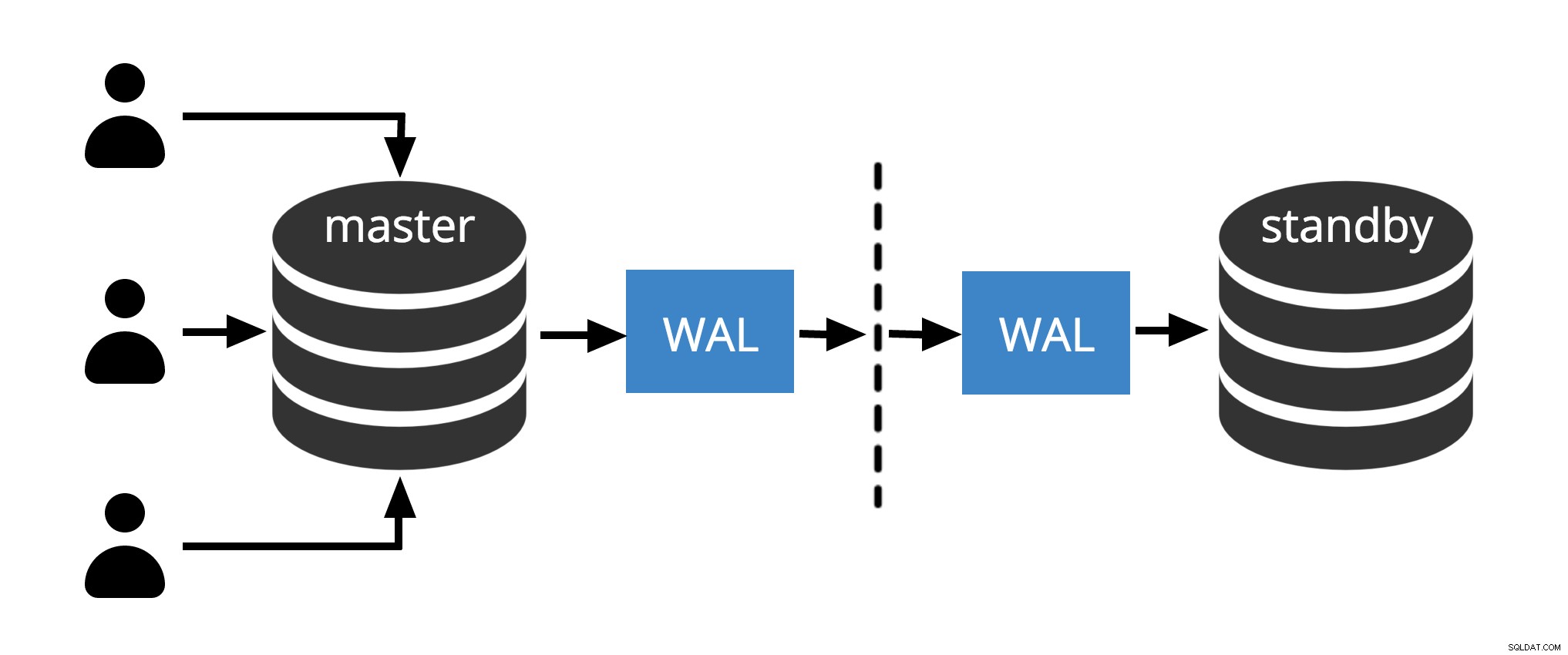
Obr.1 Fyzická replikace
Obr.1 ukazuje, jak fyzická replikace funguje pouze se dvěma uzly. Klient provádí dotazy na hlavním uzlu, změny jsou zapsány do transakčního protokolu (WAL) a zkopírovány přes síť do WAL v pohotovostním uzlu. Proces obnovy v pohotovostním uzlu pak načte změny z WAL a aplikuje je na datové soubory stejně jako při obnově po havárii. Pokud je pohotovostní režim v horkém pohotovostním režimu Během tohoto režimu mohou klienti na uzlu zadávat dotazy pouze pro čtení.
Poznámka: Fyzická replikace jednoduše odkazuje na odesílání souborů WAL přes síť z hlavního do pohotovostního uzlu. Soubory lze odesílat různými protokoly, jako je scp, rsync, ftp… rozdíl mezi Fyzickou replikací a Physical Streaming Replication is Streaming Replication používá pro odesílání souborů WAL interní protokol (odesílatel a procesy přijímače )
Pohotovostní režimy
Více uzlů poskytuje vysokou dostupnost. Z tohoto důvodu mají moderní architektury obvykle pohotovostní uzly. Pro uzly pohotovostního režimu existují různé režimy (teplý a horký pohotovostní režim). Níže uvedený seznam vysvětluje základní rozdíly mezi různými pohotovostními režimy a také ukazuje případ architektury multi-master.
Teplý pohotovostní režim
Může být aktivován okamžitě, ale nemůže vykonávat užitečnou práci, dokud není aktivován. Pokud průběžně dodáváme sérii souborů WAL do jiného počítače, který byl načten se stejným základním záložním souborem, máme teplý pohotovostní systém:kdykoli můžeme spustit druhý počítač a ten bude mít téměř aktuální kopii databáze. Teplý pohotovostní režim neumožňuje dotazy pouze pro čtení, tuto skutečnost jednoduše znázorňuje obr.2.
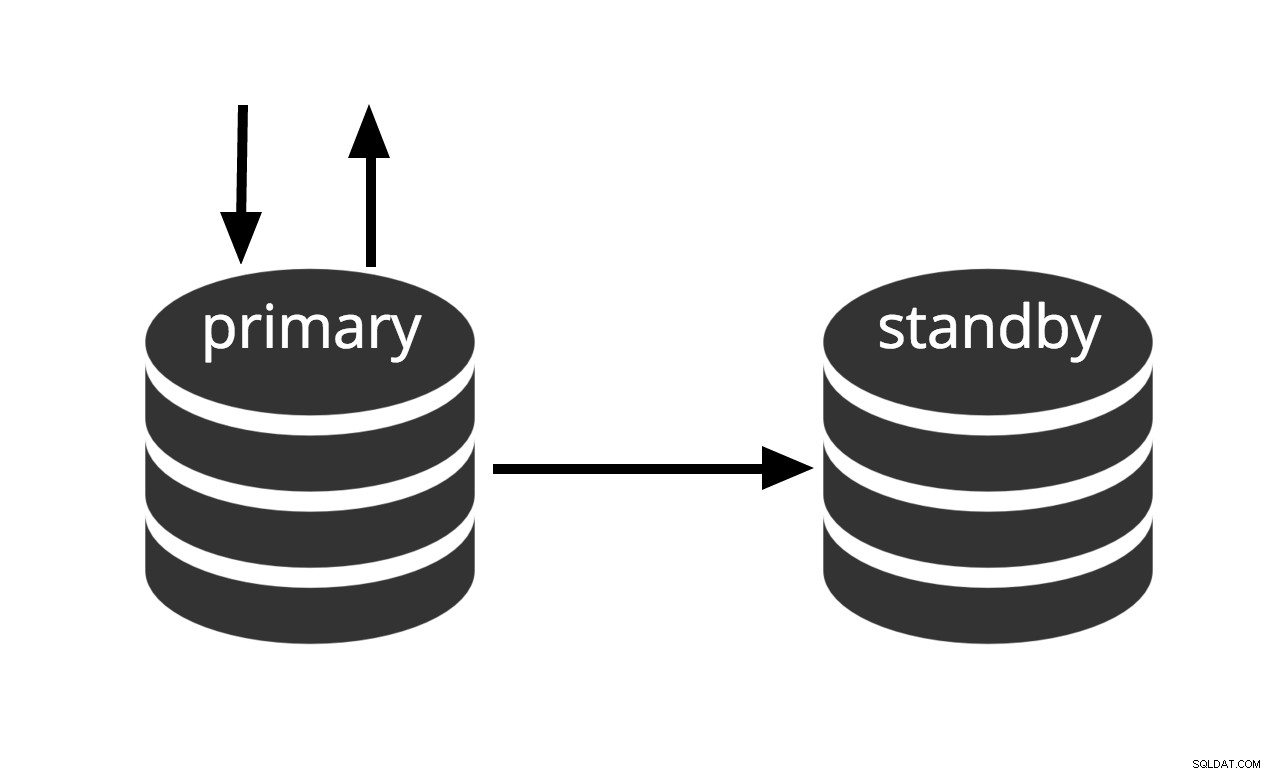
Obr.2 Teplý pohotovostní režim
Výkon obnovy teplého pohotovostního režimu je dostatečně dobrý, že pohotovostní režim bude po aktivaci obvykle jen několik okamžiků od plné dostupnosti. V důsledku toho se tomu říká konfigurace teplého pohotovostního režimu, která nabízí vysokou dostupnost.
Horký pohotovostní režim
Aktivní pohotovostní režim je termín používaný k popisu schopnosti připojit se k serveru a spouštět dotazy pouze pro čtení, když je server v režimu obnovy archivu nebo v pohotovostním režimu. To je užitečné jak pro účely replikace, tak pro obnovení zálohy do požadovaného stavu s velkou přesností.
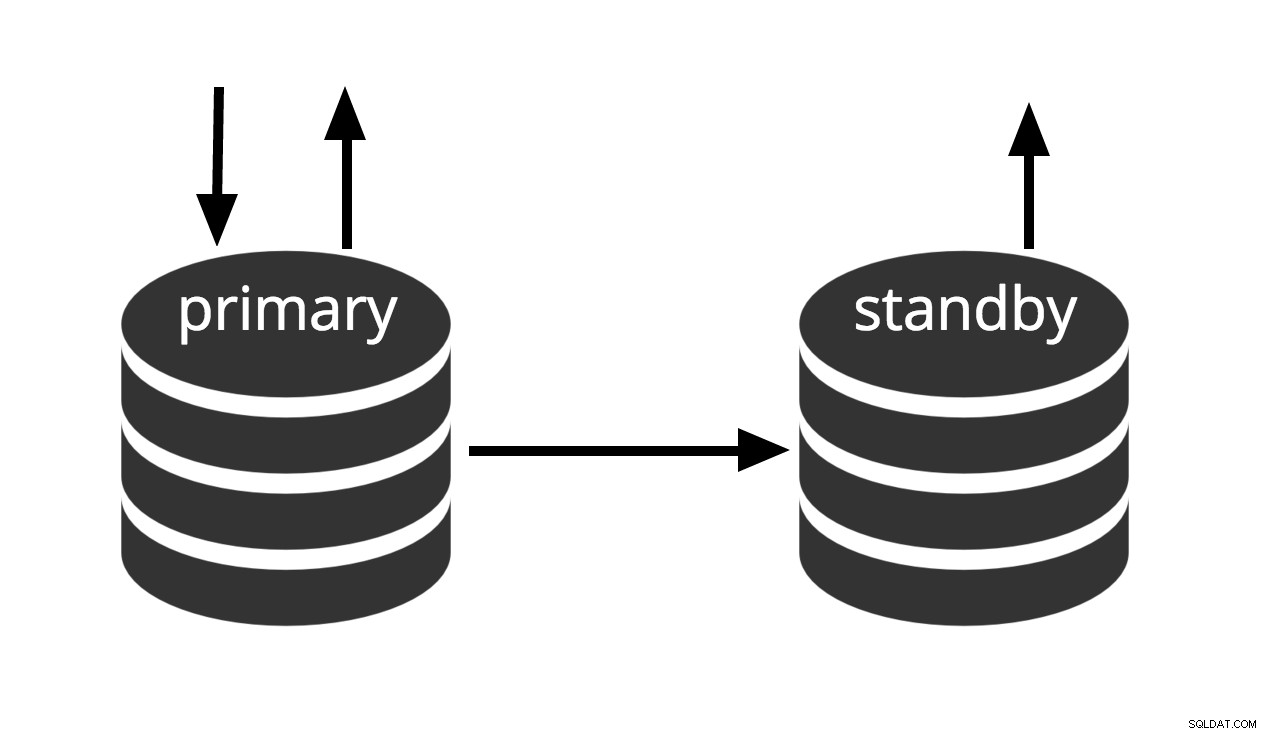 Obr. 3 Hot Standby
Obr. 3 Hot Standby
Termín hot standby také odkazuje na schopnost serveru přejít z obnovy do normálního provozu, zatímco uživatelé pokračují ve spouštění dotazů a/nebo udržují svá připojení otevřená. Obr.3 ukazuje, že pohotovostní režim umožňuje dotazy pouze pro čtení.
Multi-Master
Všechny uzly mohou provádět čtení/zápis. (Multimaster architekturami se budeme zabývat v dalších příspěvcích na blogu této série.)
Parametr úrovně WAL
Mezi nastavením wal_level existuje vztah parametru v souboru postgresql.conf a k čemu je toto nastavení vhodné. Vytvořil jsem tabulku pro zobrazení vztahu pro PostgreSQL verze 9.6.

Přepnutí při selhání a přepnutí
V případě replikace s jedním hlavním serverem, pokud hlavní server zemře, musí jej nahradit jeden z pohotovostních režimů (propagace ). V opačném případě nebudeme moci přijímat nové transakce zápisu. Termín označení, hlavní a pohotovostní, jsou tedy pouze role, které může v určitém okamžiku převzít jakýkoli uzel. Chcete-li přesunout hlavní roli do jiného uzlu, provedeme proceduru s názvem Přepnutí .
Pokud master zemře a nevzpamatuje se, pak je závažnější změna role známá jako Failover . V mnoha ohledech si mohou být podobné, ale pomáhá používat pro každou událost jiné výrazy. (Znalost podmínek převzetí služeb při selhání a přepnutí nám pomůže pochopit problémy s časovou osou v příštím příspěvku na blogu.)
Závěr
V tomto příspěvku na blogu jsme diskutovali o replikaci PostgreSQL a jejím významu pro zajištění odolnosti proti chybám a spolehlivosti. Zabývali jsme se replikací fyzického streamování a mluvili o pohotovostních režimech pro PostgreSQL. Zmínili jsme Failover a Switchover. S časovými osami PostgreSQL budeme pokračovat v dalším příspěvku na blogu.
Odkazy
Dokumentace PostgreSQL
Logická replikace v PostgreSQL 5432…prezentace MeetUs od Petra Jelínka
Administrační kuchařka PostgreSQL 9 – druhé vydání