Při ladění postgresql.conf , možná jste si všimli, že existuje možnost s názvem full_page_writes . Komentář vedle říká něco o částečném zápisu stránky a lidé to obvykle nechávají nastavené na on – což je dobrá věc, jak vysvětlím později v tomto příspěvku. Je však užitečné pochopit, co dělá zápis na celou stránku, protože dopad na výkon může být docela významný.
Na rozdíl od mého předchozího příspěvku o ladění kontrolních bodů, toto není návod, jak vyladit server. Není toho moc, co byste mohli vylepšit, opravdu, ale ukážu vám, jak mohou některá rozhodnutí na úrovni aplikace (např. výběr datových typů) ovlivňovat zápis celé stránky.
Částečné zápisy / roztržené stránky
O čem tedy celá stránka píše? Jako komentář v postgresql.conf říká, že je to způsob, jak se zotavit z částečných zápisů stránek – PostgreSQL používá stránky o velikosti 8 kB (ve výchozím nastavení), ale jiné části zásobníku používají různé velikosti bloků. Souborové systémy Linuxu obvykle používají 4kB stránky (je možné použít menší stránky, ale 4kB je maximum na x86) a na hardwarové úrovni staré disky využívaly 512B sektorů, zatímco nová zařízení často zapisují data ve větších blocích (často 4kB nebo dokonce 8kB) .
Takže když PostgreSQL zapíše stránku o velikosti 8 kB, ostatní vrstvy zásobníku ji mohou rozdělit na menší části, spravované samostatně. To představuje problém týkající se atomicity zápisu. 8kB PostgreSQL stránku lze rozdělit na dvě 4kB stránky souborového systému a poté na 512B sektory. Co když se server zhroutí (výpadek napájení, chyba jádra, …)?
I když server používá úložný systém určený k řešení takovýchto poruch (SSD s kondenzátory, RAID řadiče s bateriemi, …), jádro již rozdělilo data na 4kB stránky. Je tedy možné, že databáze napsala 8kB datovou stránku, ale pouze část z toho se dostala na disk před havárií.
V tuto chvíli si pravděpodobně myslíte, že to je přesně důvod, proč máme protokol transakcí (WAL), a máte pravdu! Po spuštění serveru tedy databáze přečte WAL (od posledního dokončeného kontrolního bodu) a znovu použije změny, aby se ujistil, že jsou datové soubory úplné. Jednoduché.
Má to ale háček – obnova neaplikuje změny slepě, často potřebuje číst datové stránky atd. Což předpokládá, že stránka již není nějakým způsobem orámována, například kvůli částečnému zápisu. Což se zdá být trochu protichůdné, protože při opravě poškození dat předpokládáme, že k žádnému poškození dat nedochází.
Zápis celé stránky je způsob, jak tento hlavolam obejít – při první úpravě stránky po kontrolním bodu se do WAL zapíše celá stránka. To zaručuje, že během obnovy první záznam WAL, který se dotkne stránky, bude obsahovat celou stránku, čímž se eliminuje potřeba číst – možná poškozenou – stránku z datového souboru.
Zapsat zesílení
Negativním důsledkem toho je samozřejmě zvětšená velikost WAL – změna jediného bajtu na stránce 8kB způsobí přihlášení celku do WAL. K zápisu celé stránky dochází pouze při prvním zápisu po kontrolním bodu, takže méně časté kontrolní body je jedním ze způsobů, jak situaci zlepšit – obvykle dojde ke krátkému „shluku“ zápisu celé stránky po kontrolním bodu a poté relativně málo zápisu celé stránky. až do konce kontrolního bodu.
UUID vs. BIGSERIAL klíče
Existuje však několik neočekávaných interakcí s rozhodnutími o návrhu na úrovni aplikace. Předpokládejme, že máme jednoduchou tabulku s primárním klíčem, buď BIGSERIAL nebo UUID a vložíme do něj data. Bude rozdíl v množství generovaných WAL (za předpokladu, že vložíme stejný počet řádků)?
Zdá se rozumné očekávat, že oba případy produkují přibližně stejné množství WAL, ale jak ukazují následující grafy, v praxi existuje obrovský rozdíl.
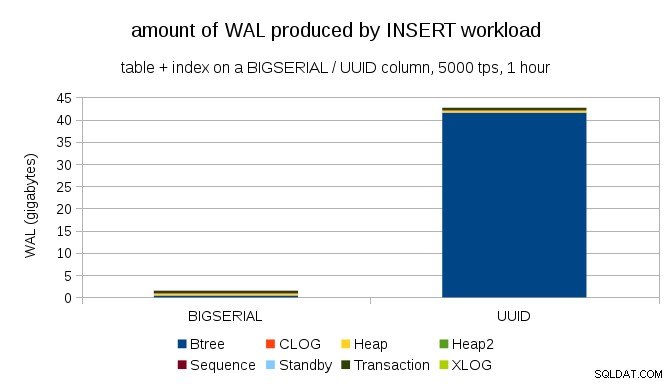
To ukazuje množství WAL produkovaného během 1h benchmarku, omezeného na 5000 vložek za sekundu. S BIGSERIAL primární klíč to vytváří ~2GB WAL, zatímco s UUID je to více než 40 GB. To je docela významný rozdíl a zcela jasně je většina WAL spojena s indexem podporujícím primární klíč. Podívejme se na typy záznamů WAL.
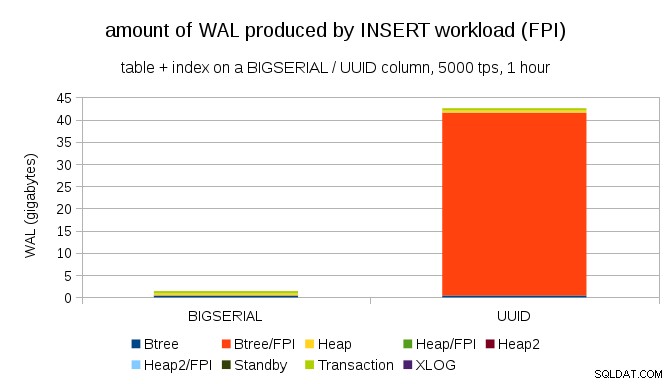
Je zřejmé, že velká většina záznamů jsou celostránkové obrázky (FPI), tedy výsledek celostránkových zápisů. Ale proč se to děje?
Samozřejmě je to kvůli inherentnímu UUID náhodnost. S BIGSERIAL new jsou sekvenční, a tak se vkládají na stejné listové stránky v indexu btree. Protože pouze první úprava stránky spouští zápis na celou stránku, pouze malá část záznamů WAL jsou FPI. S UUID je to samozřejmě úplně jiný případ – hodnoty nejsou vůbec sekvenční, ve skutečnosti se každá vložka pravděpodobně dotkne úplně nové listové stránky indexu (za předpokladu, že index je dostatečně velký).
Databáze toho moc nezmůže – pracovní zátěž je prostě náhodné povahy a spouští mnoho zápisů na celou stránku.
Dosáhnout podobného zesílení zápisu není těžké ani s BIGSERIAL klíče, samozřejmě. Vyžaduje pouze jinou zátěž – například s UPDATE pracovní zátěž, náhodná aktualizace záznamů s rovnoměrným rozložením, graf vypadá takto:
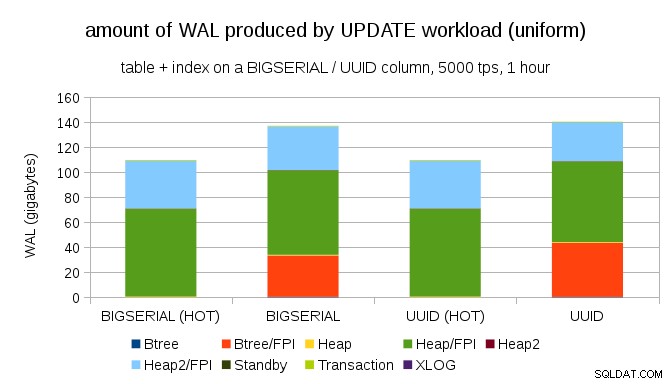
Najednou jsou rozdíly mezi datovými typy pryč – přístup je v obou případech náhodný, výsledkem je téměř přesně stejné množství produkovaných WAL. Dalším rozdílem je, že většina WAL je spojena s „hromadou“, tj. tabulkami, a nikoli indexy. Případy „HOT“ byly navrženy tak, aby umožňovaly optimalizaci HOT UPDATE (tj. aktualizaci bez nutnosti dotýkat se indexu), což v podstatě eliminuje veškerý provoz WAL související s indexem.
Ale můžete namítnout, že většina aplikací neaktualizuje celý soubor dat. Obvykle je „aktivní“ jen malá podmnožina dat – lidé přistupují pouze k příspěvkům z posledních dní na diskuzním fóru, nevyřešeným objednávkám v e-shopu apod. Jak to změní výsledky?
Naštěstí pgbench podporuje nejednotné distribuce a například s exponenciální distribucí, která se dotýká 1 % podmnožiny dat ~ 25 % času, vypadá graf takto:
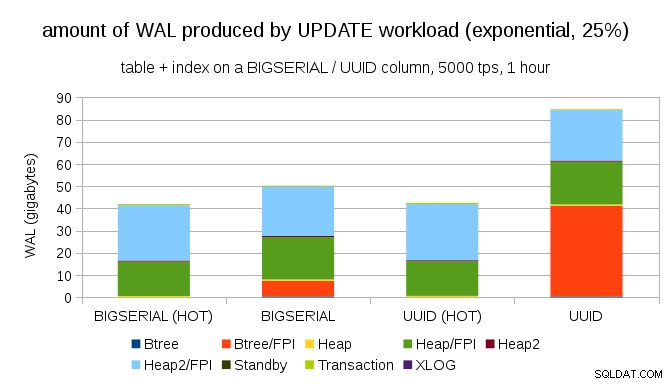
A poté, co rozdělení ještě více zkosíte, dotkněte se podmnožiny 1 % ~ 75 % času:
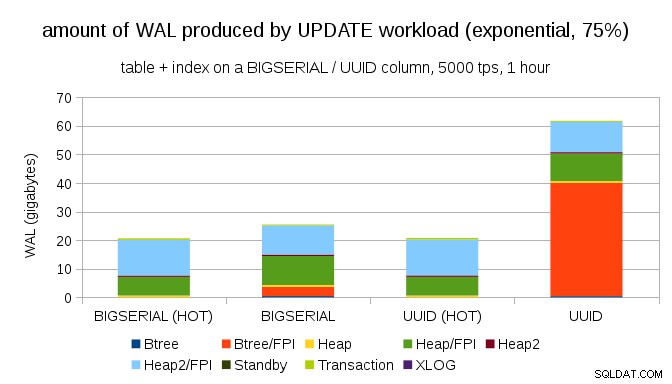
To opět ukazuje, jak velký rozdíl může mít výběr datových typů a také důležitost ladění pro HOT aktualizace.
8kB a 4kB stránky
Zajímavou otázkou je, kolik provozu WAL bychom mohli ušetřit použitím menších stránek v PostgreSQL (což vyžaduje kompilaci vlastního balíčku). V nejlepším případě by to mohlo ušetřit až 50% WAL, díky logování pouze 4kB místo 8kB stránek. Pro pracovní zátěž s jednotně distribuovanými AKTUALIZACE to vypadá takto:
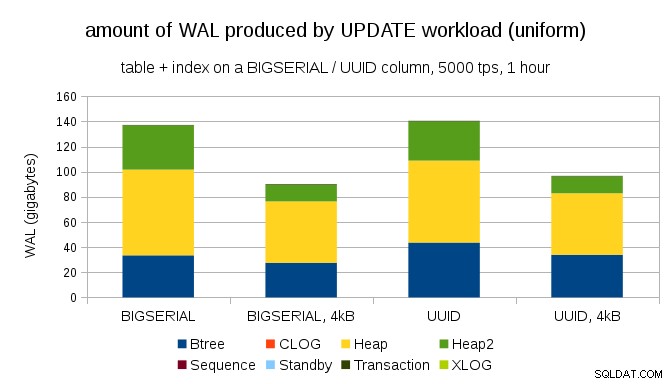
Úspora tedy není přesně 50 %, ale snížení z ~140 GB na ~90 GB je stále poměrně významné.
Potřebujeme stále zápisy na celou stránku?
Po vysvětlení nebezpečí částečného zápisu se to může zdát směšné, ale možná by mohla být schůdná možnost, alespoň v některých případech, zakázání zápisu celé stránky.
Nejprve by mě zajímalo, zda jsou moderní linuxové souborové systémy stále zranitelné vůči částečným zápisům? Parametr byl zaveden v PostgreSQL 8.1 vydaném v roce 2005, takže možná kvůli některým z mnoha vylepšení souborového systému zavedených od té doby to není problém. Pravděpodobně ne univerzálně pro libovolné pracovní zatížení, ale možná by stačila nějaká další podmínka (např. použití velikosti stránky 4 kB v PostgreSQL)? PostgreSQL také nikdy nepřepíše pouze podmnožinu stránky o velikosti 8 kB – vždy se vypíše celá stránka.
Nedávno jsem provedl mnoho testů, které se pokoušely spustit částečný zápis, a zatím se mi nepodařilo způsobit jediný případ. Samozřejmě to není skutečný důkaz, že problém neexistuje. Ale i když se stále jedná o problém, kontrolní součty dat mohou být dostatečnou ochranou (problém nevyřeší, ale alespoň vás upozorní, že je stránka nefunkční).
Zadruhé, mnoho systémů v dnešní době spoléhá na repliky streamované replikace – namísto čekání na restart serveru po hardwarovém problému (což může trvat poměrně dlouho) a následného trávení více času obnovou, se systémy jednoduše přepnou do horkého pohotovostního režimu. Pokud je databáze na neúspěšné primární stránce odstraněna (a poté klonována z nové primární), částečné zápisy nejsou problémem.
Ale myslím, že kdybychom to začali doporučovat, pak "Nevím, jak se data poškodila, právě jsem v systémech nastavil full_page_writes=off!" by se stala jednou z nejčastějších vět těsně před smrtí pro DBA (společně s „Viděl jsem tohoto hada na redditu, není jedovatý.“).
Shrnutí
Pro přímé vyladění celostránkových zápisů toho moc udělat nemůžete. U většiny úloh se většina celostránkových zápisů odehrává hned po kontrolním bodu a poté zmizí až do dalšího kontrolního bodu. Je tedy důležité vyladit kontrolní body, aby se nestávaly příliš často.
Některá rozhodnutí na úrovni aplikace mohou zvýšit náhodnost zápisů do tabulek a indexů – například hodnoty UUID jsou ze své podstaty náhodné, což mění i jednoduchou zátěž INSERT na náhodné aktualizace indexů. Schéma použité v příkladech bylo poměrně triviální – v praxi budou sekundární indexy, cizí klíče atd. Ale interní použití primárních klíčů BIGSERIAL (a ponechání UUID jako náhradních klíčů) by alespoň snížilo zesílení zápisu.
Opravdu mě zajímá diskuse o potřebě celostránkových zápisů na aktuálních jádrech / souborových systémech. Bohužel jsem nenašel mnoho zdrojů, takže pokud máte relevantní informace, dejte mi vědět.