V předchozím příspěvku jsme diskutovali o tom, jak můžete převzít kontrolu nad procesem převzetí služeb při selhání v ClusterControl pomocí bílých a černých listin. V tomto příspěvku budeme diskutovat o podobném konceptu. Tentokrát se však zaměříme na integraci s externími skripty a aplikacemi prostřednictvím mnoha háčků zpřístupněných ClusterControl.
Prostředí infrastruktury lze budovat různými způsoby, protože často existuje mnoho možností na výběr pro daný kousek skládačky. Jak definujeme, do kterého databázového uzlu se má zapisovat? Používáte virtuální IP? Používáte nějaký druh vyhledávání služeb? Možná použijete záznamy DNS a v případě potřeby změníte záznamy A? A co proxy vrstva? Spoléháte při rozhodování o zapisovači na hodnotu „pouze pro čtení“ pro vaše proxy, nebo možná provádíte požadované změny přímo v konfiguraci proxy? Jak vaše prostředí zvládá přechody? Můžete to prostě provést, nebo možná budete muset předem udělat nějaké předběžné kroky? Například zastavení některých dalších procesů, než budete moci skutečně provést přepnutí?
Není možné, aby byl software pro přepnutí při selhání předem nakonfigurován tak, aby pokryl všechna různá nastavení, která mohou lidé vytvořit. To je hlavní důvod, proč poskytnout různé způsoby připojení k procesu převzetí služeb při selhání. Tímto způsobem si jej můžete přizpůsobit a umožnit vám zvládnout všechny jemnosti vašeho nastavení. V tomto příspěvku na blogu se podíváme na to, jak lze přizpůsobit proces převzetí služeb při selhání ClusterControl pomocí různých skriptů před a po selhání. Probereme také některé příklady toho, čeho lze dosáhnout takovým přizpůsobením.
Integrace ClusterControl
ClusterControl poskytuje několik háků, které lze použít k připojení externích skriptů. Níže naleznete seznam těch s určitým vysvětlením.
- Replication_onfail_failover_script – tento skript se spustí, jakmile se zjistí, že je potřeba převzetí služeb při selhání. Pokud skript vrátí nenulovou hodnotu, vynutí přerušení převzetí služeb při selhání. Pokud je skript definován, ale nenalezen, převzetí služeb při selhání bude přerušeno. Skript obsahuje čtyři argumenty:arg1='všechny servery' arg2='oldmaster' arg3='kandidát', arg4='slaves of oldmaster' a předány takto:'scripname arg1 arg2 arg3 arg4'. Skript musí být přístupný na ovladači a musí být spustitelný.
- Replication_pre_failover_script – tento skript se spustí předtím, než dojde k převzetí služeb při selhání, ale poté, co byl zvolen kandidát a je možné pokračovat v procesu převzetí služeb při selhání. Pokud skript vrátí nenulovou hodnotu, vynutí přerušení převzetí služeb při selhání. Pokud je skript definován, ale nenalezen, převzetí služeb při selhání bude přerušeno. Skript musí být přístupný na ovladači a musí být spustitelný.
- Replication_post_failover_script – tento skript se spustí po převzetí služeb při selhání. Pokud skript vrátí nenulovou hodnotu, do protokolu úlohy se zapíše Varování. Skript musí být přístupný na ovladači a musí být spustitelný.
- Replication_post_unsuccessful_failover_script – Tento skript se spustí poté, co selhal pokus o převzetí služeb při selhání. Pokud skript vrátí nenulovou hodnotu, do protokolu úlohy se zapíše Varování. Skript musí být přístupný na ovladači a musí být spustitelný.
- Replication_failed_reslave_failover_script – tento skript se spustí poté, co byl povýšen nový hlavní server a pokud selže znovupřiřazení podřízených zařízení novému hlavnímu serveru. Pokud skript vrátí nenulovou hodnotu, do protokolu úlohy se zapíše Varování. Skript musí být přístupný na ovladači a musí být spustitelný.
- Replication_pre_switchover_script – tento skript se spustí předtím, než dojde k přepnutí. Pokud skript vrátí nenulovou hodnotu, přepnutí se nezdaří. Pokud je skript definován, ale nenalezen, přepnutí bude přerušeno. Skript musí být přístupný na ovladači a musí být spustitelný.
- Replication_post_switchover_script – tento skript se spustí po přepnutí. Pokud skript vrátí nenulovou hodnotu, do protokolu úlohy se zapíše Varování. Skript musí být přístupný na ovladači a musí být spustitelný.
Jak můžete vidět, háčky pokrývají většinu případů, kdy možná budete chtít provést nějaké akce – před a po přepnutí, před a po převzetí služeb při selhání, když selže reslave nebo když selže převzetí služeb při selhání. Všechny skripty jsou vyvolány se čtyřmi argumenty (které mohou nebo nemusí být ve skriptu zpracovány, není nutné, aby je skript všechny využíval):všechny servery, název hostitele (nebo IP - jak je definováno v ClusterControl) starého hlavního serveru, název hostitele (nebo IP - jak je definováno v ClusterControl) kandidáta hlavního serveru a čtvrtý, všechny repliky starého hlavního serveru. Tyto možnosti by měly umožnit zvládnout většinu případů.
Všechny tyto háčky by měly být definovány v konfiguračním souboru pro daný cluster (/etc/cmon.d/cmon_X.cnf, kde X je id clusteru). Příklad může vypadat takto:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shVyvolané skripty samozřejmě musí být spustitelné, jinak je cmon nebude schopen spustit. Pojďme si nyní chvíli projít procesem převzetí služeb při selhání v ClusterControl a podívat se, kdy se spouštějí externí skripty.
Proces převzetí služeb při selhání v ClusterControl
Definovali jsme všechny dostupné háčky:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shPoté musíte restartovat proces cmon. Jakmile bude hotovo, jsme připraveni otestovat převzetí služeb při selhání. Původní topologie vypadá takto:
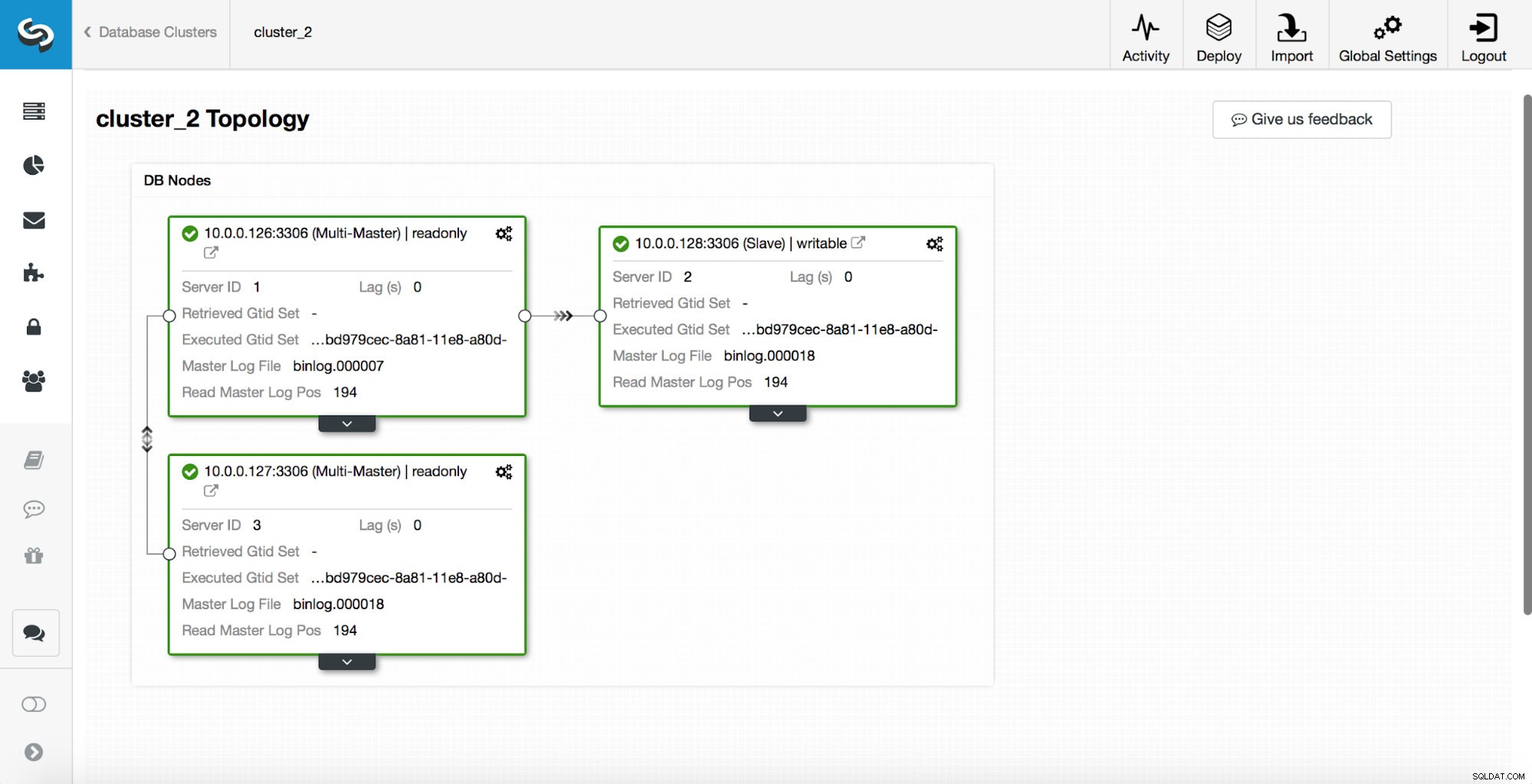
Master byl zabit a byl zahájen proces převzetí služeb při selhání. Upozorňujeme, že novější záznamy protokolu jsou nahoře, takže chcete přepnutí při selhání sledovat zdola nahoru.
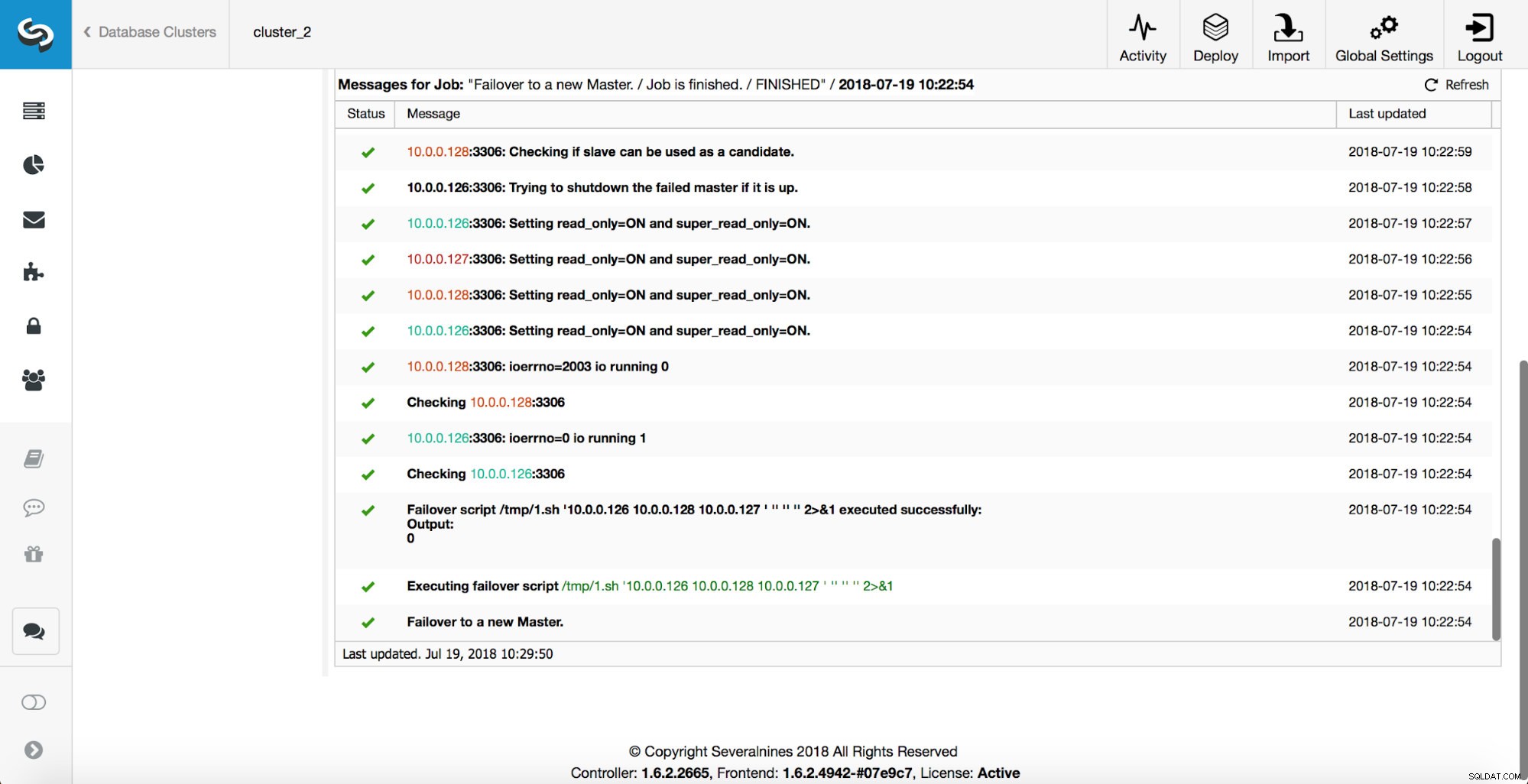
Jak můžete vidět, ihned po spuštění úlohy převzetí služeb při selhání spustí háček ‘replication_onfail_failover_script’. Poté jsou všichni dosažitelní hostitelé označeni jako pouze pro čtení a ClusterControl se pokusí zabránit spuštění starého hlavního serveru.
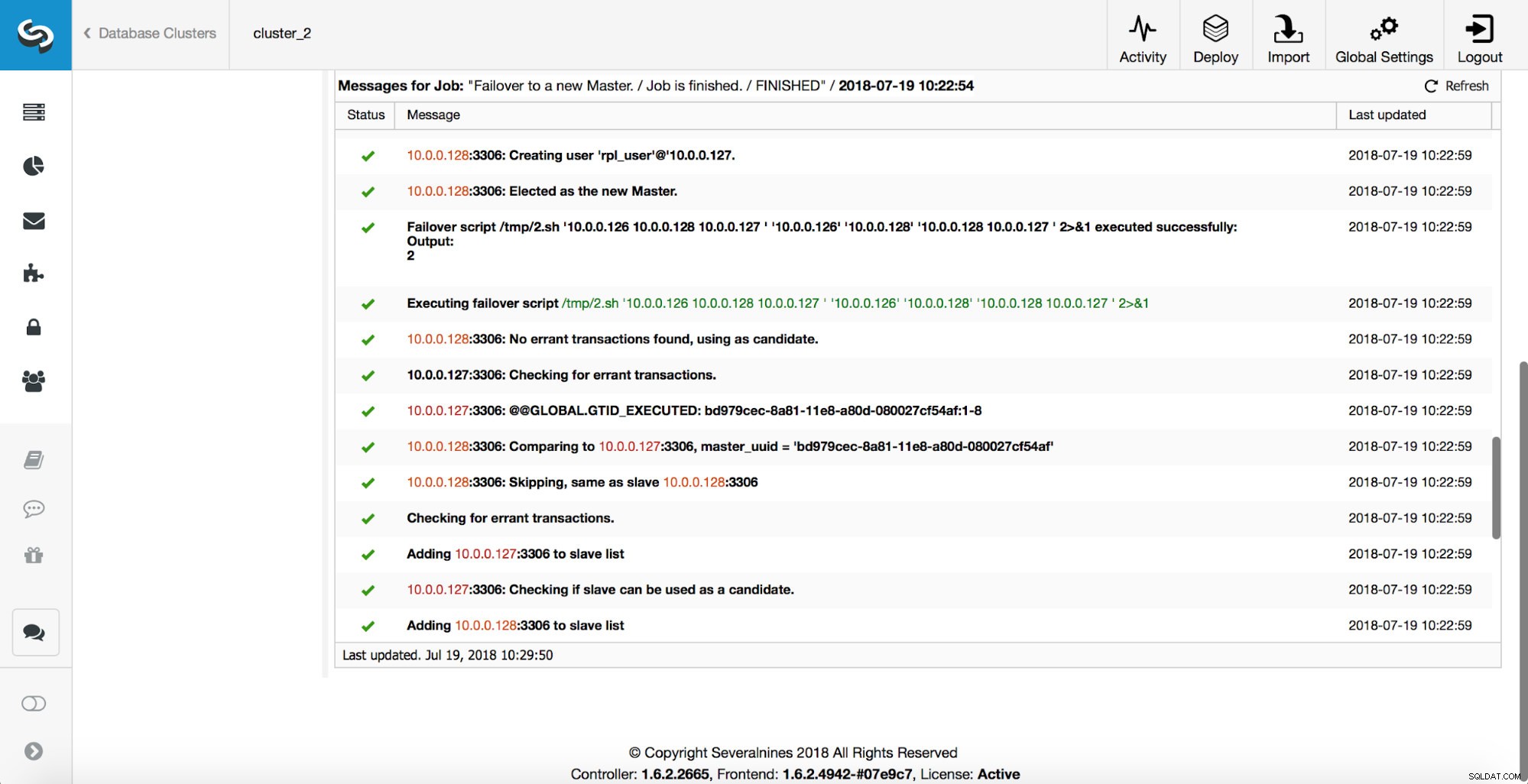
Dále je vybrán hlavní kandidát, jsou provedeny kontroly zdravého rozumu. Jakmile bude potvrzeno, že hlavního kandidáta lze použít jako nového hlavního, spustí se „replication_pre_failover_script“.
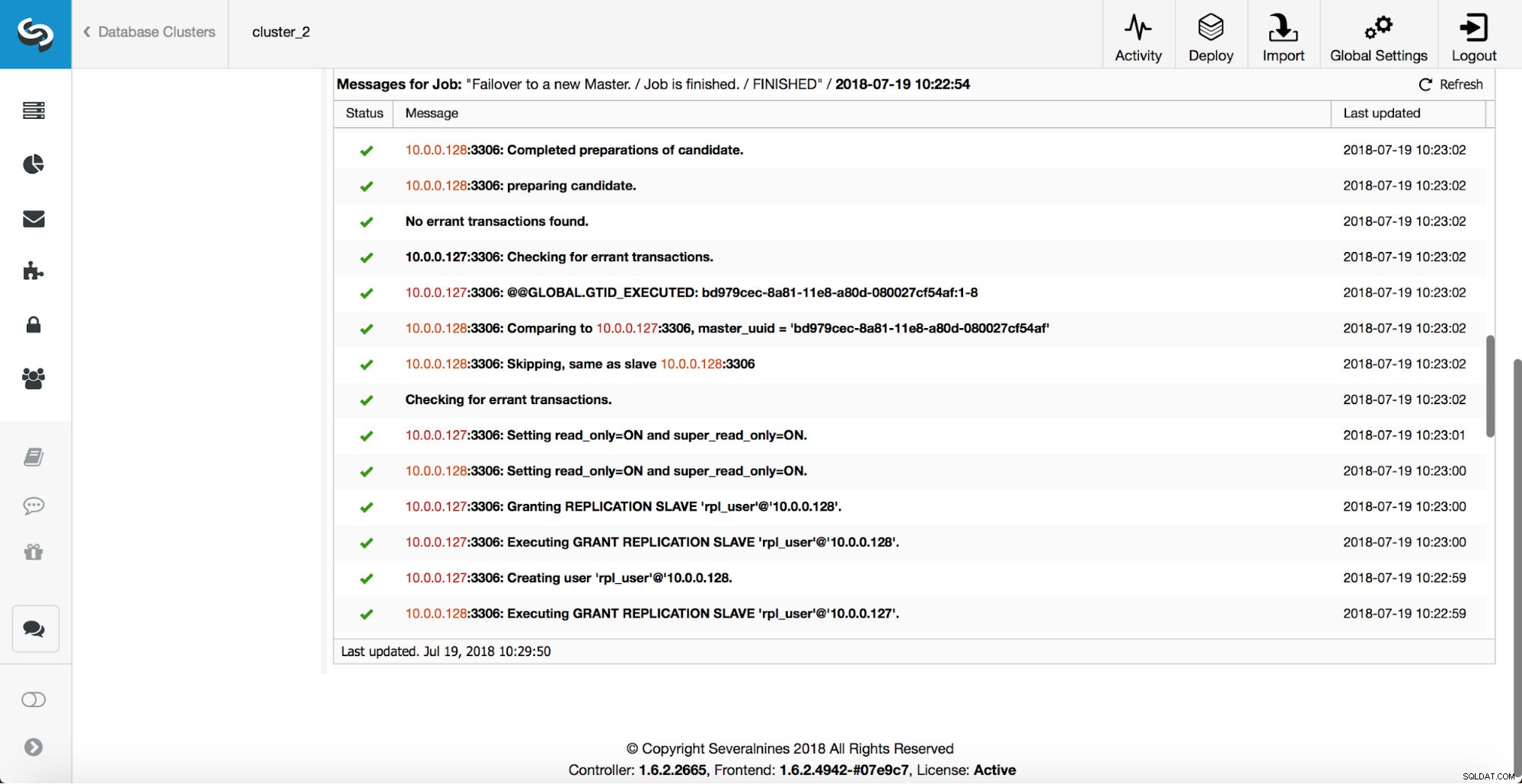
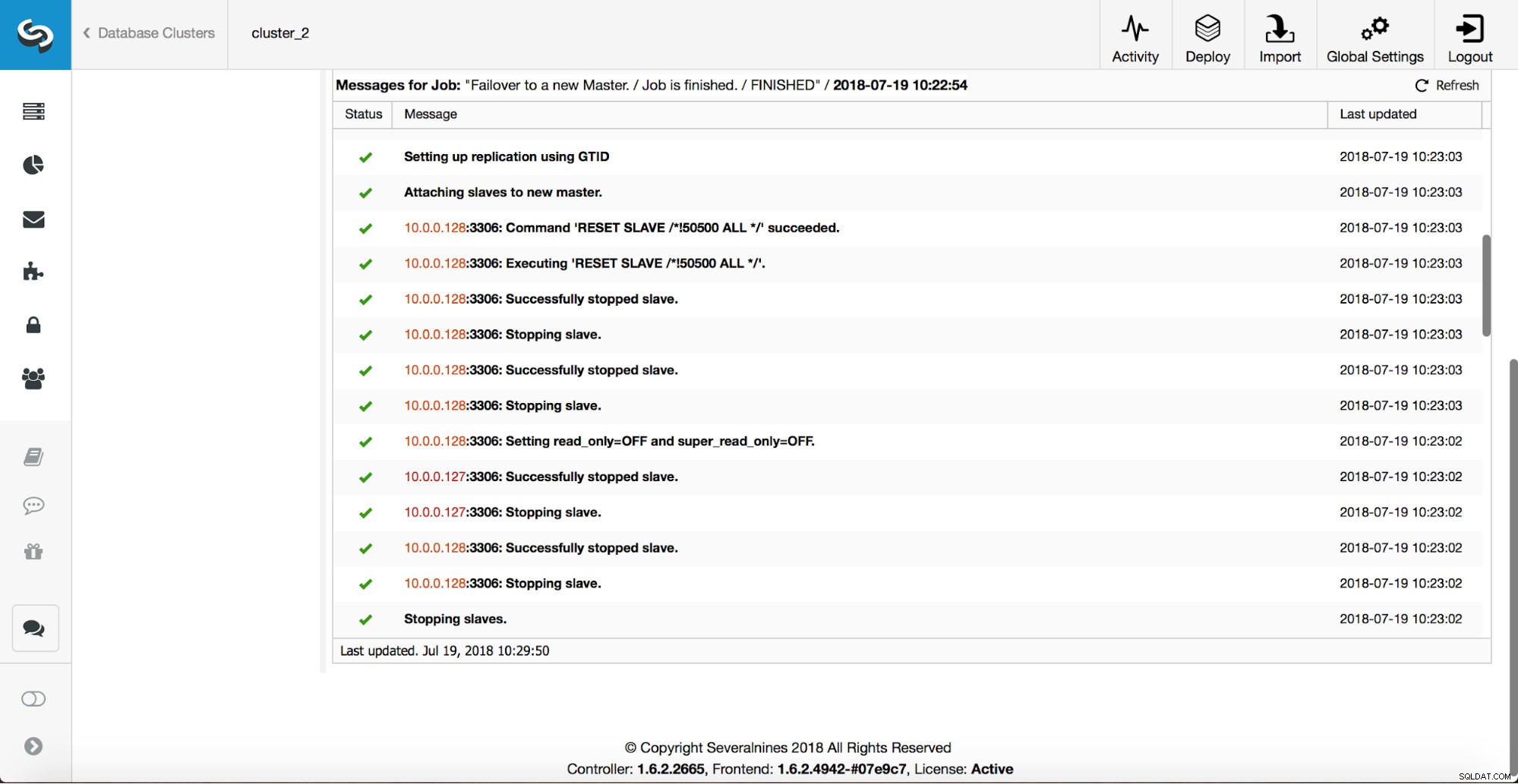
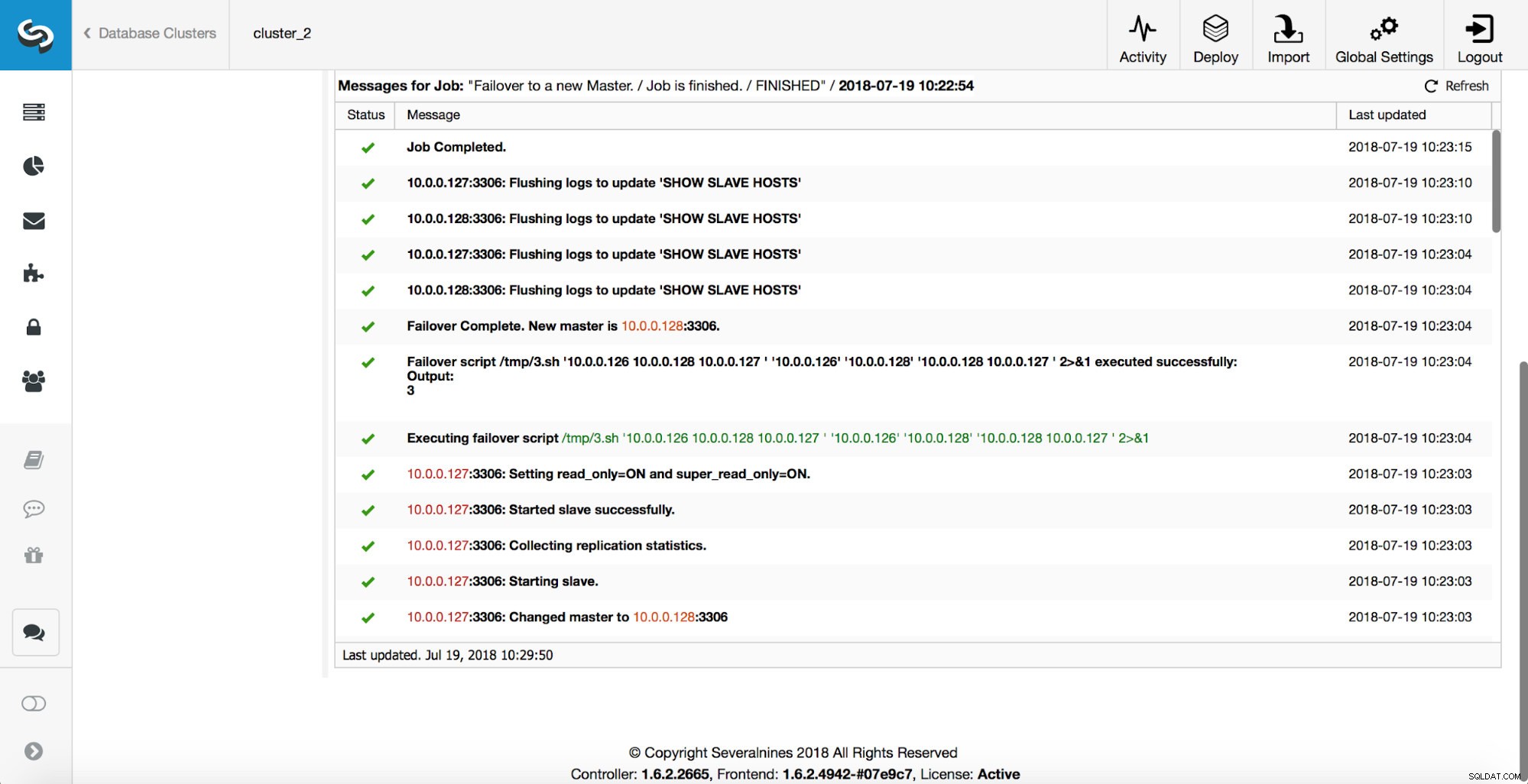
Provedou se další kontroly, repliky se zastaví a podřídí se novému masteru. Nakonec se po dokončení převzetí služeb při selhání spustí poslední háček, ‚replication_post_failover_script‘.
Kdy mohou být háky užitečné?
V této části si projdeme několik příkladů případů, kdy může být dobrý nápad implementovat externí skripty. Nebudeme se pouštět do žádných podrobností, protože ty jsou příliš úzce spjaty s konkrétním prostředím. Bude to spíše seznam návrhů, které by mohlo být užitečné implementovat.
Skript STONITH
Shoot The Other Node In The Head (STONITH) je proces, který zajišťuje, že starý mistr, který je mrtvý, zůstane mrtvý (a ano... nemáme rádi zombie potulující se po naší infrastruktuře). Poslední věc, kterou pravděpodobně chcete, je mít nereagující starou předlohu, která se poté vrátí online a v důsledku toho skončíte se dvěma zapisovatelnými předlohami. Existují opatření, která můžete učinit, abyste zajistili, že starý vzor nebude použit, i když se znovu objeví, a je bezpečnější, aby zůstal offline. Způsoby, jak to zajistit, se budou lišit prostředí od prostředí. Proto s největší pravděpodobností nebude žádná vestavěná podpora pro STONITH v nástroji pro překonání selhání. V závislosti na prostředí můžete chtít provést příkaz CLI, který zastaví (a dokonce odebere) virtuální počítač, na kterém běží starý hlavní server. Pokud máte vlastní nastavení, můžete mít nad hardwarem větší kontrolu. Možná by bylo možné využít nějakou vzdálenou správu (integrovaný Lights-out nebo nějaký jiný vzdálený přístup k serveru). Můžete mít také přístup ke spravovatelným napájecím zásuvkám a vypnout napájení v jedné z nich, abyste měli jistotu, že se server už nikdy nespustí bez lidského zásahu.
Zjištění služby
Již jsme se trochu zmínili o vyhledávání služeb. Existuje mnoho způsobů, jak lze uložit informace o topologii replikace a zjistit, který hostitel je hlavní. Rozhodně jednou z populárnějších možností je použití etc.d nebo Consul k ukládání dat o aktuální topologii. Díky tomu se může aplikace nebo proxy spolehnout na tato data při odesílání provozu do správného uzlu. ClusterControl (stejně jako většina nástrojů, které podporují zpracování převzetí služeb při selhání) nemá přímou integraci s etc.d ani Consul. Úkol aktualizovat data topologie je na uživateli. K vyvolání některých skriptů a provedení požadovaných změn může použít háčky jako replikační_post_failover_script nebo replication_post_switchover_script. Dalším docela běžným řešením je použití DNS k nasměrování provozu na správné instance. Pokud budete udržovat Time-To-Live DNS záznamu nízkou, měli byste být schopni definovat doménu, která bude ukazovat na vašeho mastera (tj. writes.cluster1.example.com). To vyžaduje změnu DNS záznamů a opět, háčky jako replication_post_failover_script nebo replication_post_switchover_script mohou být opravdu užitečné k provedení požadovaných úprav poté, co došlo k převzetí služeb při selhání.
Rekonfigurace proxy
Každý používaný proxy server musí odesílat provoz do správných instancí. V závislosti na samotném proxy může být způsob provádění hlavní detekce buď (částečně) pevně zakódován, nebo může být na uživateli, aby si definoval, co chce. Mechanismus převzetí služeb při selhání ClusterControl je navržen tak, aby se dobře integroval s proxy servery, které nasadil a nakonfiguroval. Stále se může stát, že jsou na místě proxy, které nebyly nainstalovány ClusterControl a které vyžadují provedení některých ručních akcí, když se provádí převzetí služeb při selhání. Takové servery proxy lze také integrovat do procesu převzetí služeb při selhání ClusterControl prostřednictvím externích skriptů a háčků, jako je replication_post_failover_script nebo replication_post_switchover_script.
Další protokolování
Může se stát, že budete chtít shromáždit data o procesu převzetí služeb při selhání pro účely ladění. ClusterControl má rozsáhlé tiskové výstupy, aby bylo možné sledovat proces a zjistit, co se stalo a proč. Stále se může stát, že byste chtěli shromáždit nějaké další, vlastní informace. Zde lze využít v podstatě všechny háčky – můžete sbírat počáteční stav, před převzetím služeb při selhání, můžete sledovat stav prostředí ve všech fázích převzetí služeb při selhání.