Jednou ze skvělých funkcí v Galeře je automatické zřizování uzlů a kontrola členství. Pokud uzel selže nebo ztratí komunikaci, bude automaticky vyřazen z clusteru a zůstane nefunkční. Dokud většina uzlů stále komunikuje (Galera toto nazývá PC - primární komponenta), existuje velmi vysoká pravděpodobnost, že se neúspěšný uzel bude moci automaticky znovu připojit, znovu synchronizovat a obnovit replikaci, jakmile bude připojení obnoveno.
Obecně jsou všechny uzly Galera stejné. Mají stejnou datovou sadu a stejnou roli jako master, schopné zpracovávat čtení a zápis současně, díky skupinové komunikaci Galera a replikačnímu pluginu založenému na certifikaci. V důsledku této rovnováhy tedy z pohledu databáze ve skutečnosti nedochází k žádnému převzetí služeb při selhání. Pouze ze strany aplikace, která by vyžadovala převzetí služeb při selhání, aby se vynechaly nefunkční uzly, když je cluster rozdělený.
V tomto příspěvku na blogu se podíváme na to, jak Galera Cluster provádí obnovu uzlů a clusteru v případě, že dojde k rozdělení sítě. Jen jako okrajovou poznámku, před časem jsme se podobným tématem zabývali v tomto příspěvku na blogu. Codership velmi podrobně vysvětlil koncept obnovy Galery na stránce dokumentace, Node Failure and Recovery.
Selhání a vyřazení uzlu
Abychom porozuměli obnově, musíme nejprve pochopit, jak Galera detekuje selhání uzlu a proces vyklizení. Pojďme to dát do scénáře řízeného testu, abychom lépe porozuměli procesu vystěhování. Předpokládejme, že máme tříuzlový klastr Galera, jak je znázorněno níže:
Následující příkaz lze použít k načtení našich možností poskytovatele Galera:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GJe to dlouhý seznam, ale pro vysvětlení procesu se musíme zaměřit na některé parametry:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;Za prvé, Galera dodržuje formátování ISO 8601, které představuje trvání. P1D znamená, že doba trvání je jeden den, zatímco PT15S znamená, že doba trvání je 15 sekund (všimněte si časového označení T, které předchází hodnotě času). Například pokud chcete zvýšit evs.view_forget_timeout na 1 den a půl se nastaví P1DT12H nebo PT36H.
Vzhledem k tomu, že u všech hostitelů nebyla nakonfigurována žádná pravidla brány firewall, používáme následující skript s názvem block_galera.sh na galera2 k simulaci selhání sítě do/z tohoto uzlu:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateSpuštěním skriptu získáme následující výstup:
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018Nahlášené časové razítko lze považovat za začátek rozdělení clusteru, kde ztratíme galera2, zatímco galera1 a galera3 jsou stále online a přístupné. V tuto chvíli naše architektura Galera Cluster vypadá asi takto:
Z perspektivy rozděleného uzlu
Na galera2 uvidíte některé výtisky v protokolu chyb MySQL. Rozdělme je na několik částí. Odstávka začala kolem 16:46:02 času UTC a po gmcast.peer_timeout=PT3S , zobrazí se následující:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0Jak prošlo evs.suspect_timeout =PT5S , oba uzly galera1 a galera3 jsou podle galera2 podezřelé jako mrtvé:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactivePoté Galera zreviduje aktuální pohled na cluster a pozici tohoto uzlu:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})S novým zobrazením clusteru Galera provede výpočet kvora, aby rozhodl, zda je tento uzel součástí primární komponenty. Pokud nová komponenta uvidí "primární =ne", Galera sníží stav místního uzlu ze SYNCED na OPEN:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)S poslední změnou v zobrazení clusteru a stavu uzlu Galera vrátí zobrazení clusteru po vyklizení a globální stav, jak je uvedeno níže:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Můžete vidět, že se během tohoto období změnil následující globální stav galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+V tuto chvíli je server MySQL/MariaDB na galera2 stále přístupný (databáze naslouchá na 3306 a Galera na 4567) a můžete se dotazovat na systémové tabulky mysql a vypisovat databáze a tabulky. Když však skočíte do nesystémových tabulek a uděláte jednoduchý dotaz, jako je tento:
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useOkamžitě se zobrazí chyba oznamující, že WSREP je načten, ale není připraven k použití tímto uzlem, jak uvádí wsrep_ready postavení. To je způsobeno tím, že uzel ztratí spojení s primární komponentou a přejde do neprovozního stavu (stav lokálního uzlu byl změněn ze SYNCED na OPEN). Čtení dat z uzlů v neprovozním stavu jsou považována za zastaralá, pokud nenastavíte wsrep_dirty_reads=ON povolit čtení, ačkoli Galera stále odmítá jakýkoli příkaz, který upravuje nebo aktualizuje databázi.
Konečně bude Galera naslouchat a znovu se připojovat k ostatním členům na pozadí:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60Průběh procesu vystěhování komunikací skupiny Galera pro rozdělený uzel během problému se sítí lze shrnout takto:
- Odpojí se od clusteru po gmcast.peer_timeout .
- Po evs.suspect_timeout podezřívá ostatní uzly .
- Načte nové zobrazení clusteru.
- Provádí výpočet kvora za účelem zjištění stavu uzlu.
- Sníží uzel ze SYNCED na OPEN.
- Pokusy se znovu připojit k primární komponentě (jiným uzlům Galera) na pozadí.
Z pohledu primární komponenty
Na galera1 a galera3 v tomto pořadí, po gmcast.peer_timeout=PT3S , v protokolu chyb MySQL se objeví následující:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0Poté, co prošel evs.suspect_timeout =PT5S , galera2 je podezřelá ze smrti podle galera3 (a galera1):
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera zkontroluje, zda ostatní uzly reagují na skupinovou komunikaci na galera3, zjistí, že galera1 je v primárním a stabilním stavu:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera reviduje pohled na cluster tohoto uzlu (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskGalera poté odebere rozdělený uzel z Primární komponenty:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)Nová primární komponenta se nyní skládá ze dvou uzlů, galera1 a galera3:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2Primární komponenta si mezi sebou vymění stav, aby se dohodla na novém zobrazení clusteru a globálním stavu:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera vypočítá a ověří kvorum státní burzy mezi online členy:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera aktualizuje nový pohled na cluster a globální stav po vystěhování galera2:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)V tuto chvíli budou galera1 i galera3 hlásit podobný globální stav:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+Vyjmenují problematického člena v wsrep_evs_delayed postavení. Vzhledem k tomu, že místní stav je "Synced", jsou tyto uzly funkční a můžete přesměrovat připojení klientů z galera2 na kterýkoli z nich. Pokud je tento krok nepohodlný, zvažte použití nástroje pro vyrovnávání zatížení umístěného před databází, abyste zjednodušili koncový bod připojení od klientů.
Obnova uzlu a připojení
Rozdělený uzel Galera se bude neustále pokoušet navázat spojení s primární komponentou. Pojďme propláchnout pravidla iptables na galera2, aby se mohla spojit se zbývajícími uzly:
# on galera2
$ iptables -FJakmile se uzel dokáže připojit k jednomu z uzlů, Galera začne automaticky znovu navazovat skupinovou komunikaci:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableUzel galera2 se poté připojí k jedné z primárních komponent (v tomto případě je galera1, uzel ID 737422d6), aby získal aktuální pohled na cluster a stav uzlů:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskGalera poté provede výměnu stavu se zbytkem členů, kteří mohou tvořit primární komponentu:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)Stavová burza umožňuje galera2 vypočítat kvorum a vytvořit následující výsledek:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcGalera poté povýší stav místního uzlu z OPEN na PRIMARY, aby se spustilo a navázalo připojení uzlu k primární komponentě:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Jak uvádí výše uvedený řádek, Galera vypočítává mezeru podle toho, jak daleko je uzel za shlukem. Tento uzel vyžaduje přenos stavu, aby dohnal číslo sady zápisu 2836958 z 2761994:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera připraví posluchače IST na portu 4568 na tomto uzlu a požádá jakýkoli synchronizovaný uzel v clusteru, aby se stal dárcem. V tomto případě Galera automaticky vybere galera3 (192.168.55.173), nebo může také vybrat dárce ze seznamu pod wsrep_sst_donor (pokud je definováno) pro operaci synchronizace:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.Poté změní stav místního uzlu z PRIMARY na JOINER. V této fázi je galera2 udělen požadavek na přenos stavu a začíná ukládat do mezipaměti zápisové sady:
stav2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetUzel galera2 začne přijímat chybějící sady zápisů z gcache vybraného dárce (galera3):
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.Jakmile budou všechny chybějící sady zápisů přijaty a aplikovány, Galera bude propagovat galera2 jako PŘIPOJENOU až do seqno 2837012:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.Uzel použije všechny zápisové sady uložené v mezipaměti ve své podřízené frontě a dokončí dohánění klastru. Fronta jeho otroků je nyní prázdná. Galera povýší galera2 na SYNCED, což znamená, že uzel je nyní funkční a připravený sloužit klientům:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsV tomto okamžiku jsou všechny uzly opět funkční. Můžete to ověřit pomocí následujících prohlášení na galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+wsrep_cluster_size hlášeno jako 3 a stav clusteru je Primární, což znamená, že galera2 je součástí primární komponenty. wsrep_evs_delayed byl také vymazán a místní stav je nyní synchronizován.
Proces obnovy pro rozdělený uzel během problému se sítí lze shrnout takto:
- Obnoví skupinovou komunikaci s ostatními uzly.
- Načte pohled clusteru z jedné z primárních komponent.
- Provádí výměnu stavu s primární součástí a vypočítává kvorum.
- Změní stav místního uzlu z OPEN na PRIMARY.
- Vypočítá mezeru mezi místním uzlem a shlukem.
- Změní stav místního uzlu z PRIMARY na JOINER.
- Připraví posluchač/přijímač IST na portu 4568.
- Požádá o státní převod prostřednictvím IST a vybere dárce.
- Začne přijímat a aplikovat chybějící sadu zápisů z gcache vybraného dárce.
- Změní stav místního uzlu z JOINER na JOINED.
- Dohání klastr použitím sad zápisů uložených v mezipaměti ve frontě slave.
- Změní stav místního uzlu z JOINED na SYNCED.
Selhání klastru
Cluster Galera je považován za neúspěšný, pokud není k dispozici žádná primární komponenta (PC). Uvažujme podobný tříuzlový klastr Galera, jak je znázorněn na níže uvedeném diagramu:
Cluster je považován za funkční, pokud jsou všechny uzly nebo většina uzlů online. Online znamená, že se mohou navzájem vidět prostřednictvím replikačního provozu Galery nebo skupinové komunikace. Pokud do uzlu nepřichází žádný provoz a z něj neodchází, cluster vyšle signál srdečního signálu, aby uzel včas odpověděl. V opačném případě bude zařazen do seznamu zpoždění nebo podezřelých podle toho, jak uzel odpovídá.
Pokud dojde k výpadku uzlu, řekněme uzel C, klastr zůstane funkční, protože uzel A a B jsou stále v kvoru se 2 hlasy ze 3 pro vytvoření primární komponenty. Na A a B byste měli získat následující stav clusteru:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Řekněme, že primární spínač přešel kaput, jak je znázorněno na následujícím schématu:
V tomto okamžiku každý jednotlivý uzel ztratí vzájemnou komunikaci a stav clusteru bude na všech uzlech hlášen jako Neprimární (jako to, co se stalo s galera2 v předchozím případě). Každý uzel by vypočítal kvorum a zjistil, že je menšinový (1 hlas ze 3), čímž by ztratil kvorum, což znamená, že se nevytvoří žádná primární složka a následně všechny uzly odmítnou poskytovat jakákoli data. To je považováno za selhání clusteru.
Jakmile je problém se sítí vyřešen, Galera automaticky obnoví komunikaci mezi členy, stavy uzlů výměny a určí možnost reformy primární komponenty porovnáním stavu uzlů, UUID a seqnos. Pokud pravděpodobnost existuje, Galera sloučí primární komponenty, jak je znázorněno na následujících řádcích:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
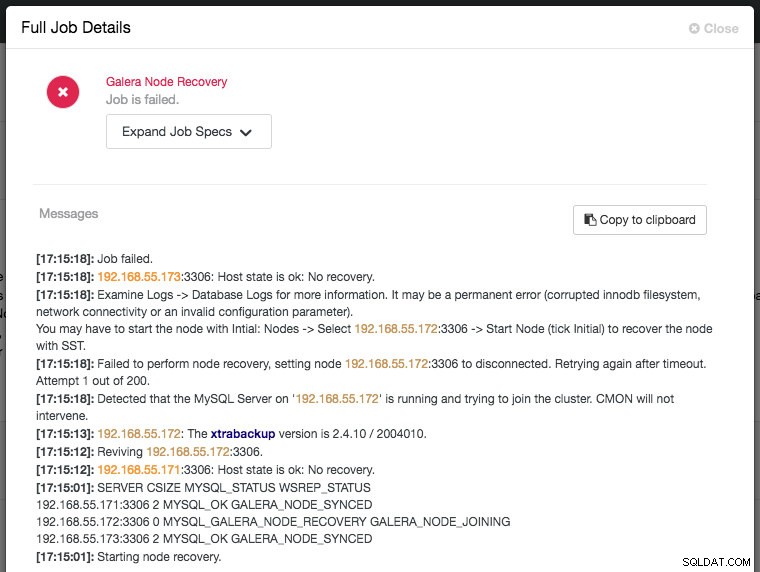
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Závěr
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.