Galera Cluster přichází s mnoha pozoruhodnými funkcemi, které nejsou dostupné ve standardní replikaci MySQL (nebo skupinové replikaci); automatické zřizování uzlů, skutečný multi-master s řešením konfliktů a automatickým převzetím služeb při selhání. Existuje také řada omezení, která by mohla potenciálně ovlivnit výkon clusteru. Naštěstí, pokud si toho nejste vědomi, existují řešení. A pokud to uděláte správně, můžete minimalizovat dopad těchto omezení a zlepšit celkový výkon.
Již dříve jsme probrali mnoho tipů a triků souvisejících s Galera Cluster, včetně spuštění Galera na AWS Cloud. Tento blogový příspěvek se zřetelně ponoří do aspektů výkonu s příklady, jak z Galery vytěžit maximum.
Úžitková zátěž replikace
Trochu úvodu – Galera replikuje sady zápisů během fáze odevzdání a přenáší sady zápisů z uzlu původce do uzlů přijímače synchronně prostřednictvím replikačního pluginu wsrep. Tento plugin bude také certifikovat sady zápisů na uzlech přijímače. Pokud proces certifikace projde, vrátí klientovi v uzlu původce OK a bude aplikován na uzly příjemce později asynchronně. V opačném případě bude transakce vrácena zpět na uzel původce (vrácení chyby klientovi) a sady zápisů, které byly přeneseny do uzlů příjemce, budou vyřazeny.
Zápisová sada se skládá z operací zápisu uvnitř transakce, která mění stav databáze. V Galera Cluster automatické potvrzení výchozí je 1 (povoleno). Doslova jakýkoli příkaz SQL provedený v Galera Cluster bude uzavřen jako transakce, pokud explicitně nezačnete s BEGIN, START TRANSACTION nebo SET autocommit=0. Následující diagram ilustruje zapouzdření jednoho příkazu DML do zapisovací sady:
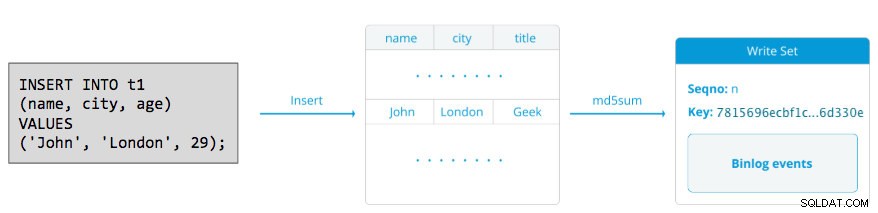
Pro DML (INSERT, UPDATE, DELETE..) se datová část writeset skládá z událostí binárního protokolu pro konkrétní transakci, zatímco pro DDL (ALTER, GRANT, CREATE..) je datová část writeset samotný příkaz DDL. U DML bude muset být sada zápisů certifikována proti konfliktům na uzlu přijímače, zatímco u DDL (v závislosti na wsrep_osu_method , výchozí TOI), klastr klastru spouští příkaz DDL na všech uzlech ve stejné celkové pořadí pořadí, čímž blokuje potvrzení dalších transakcí, zatímco DDL probíhá (viz také RSU). Jednoduše řečeno, Galera Cluster zpracovává replikaci DDL a DML odlišně.
Doba zpáteční cesty
Obecně následující faktory určují, jak rychle dokáže Galera replikovat sadu zápisů z uzlu původce do všech uzlů přijímače:
- Doba zpáteční cesty (RTT) do nejvzdálenějšího uzlu v clusteru od uzlu původce.
- Velikost sady zápisů, která má být přenesena a certifikována pro konflikt v uzlu příjemce.
Máme-li například tříuzlový cluster Galera a jeden z uzlů se nachází 10 milisekund daleko (0,01 sekundy), je velmi nepravděpodobné, že byste mohli do stejného řádku zapisovat více než 100krát za sekundu, aniž by došlo ke konfliktu. Existuje populární citát od Marka Callaghana, který toto chování velmi dobře popisuje:
„[V clusteru Galera] nelze daný řádek upravit více než jednou za RTT“
Chcete-li změřit hodnotu RTT, jednoduše proveďte ping na uzlu původce k nejvzdálenějšímu uzlu v clusteru:
$ ping 192.168.55.173 # the farthest nodePočkejte několik sekund (nebo minut) a ukončete příkaz. Poslední řádek sekce statistiky pingu je to, co hledáme:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msMaximální hodnota je 1,340 ms (0,00134 s) a tuto hodnotu bychom měli vzít při odhadování minima transakcí za sekundu (tps) pro tento cluster. průměr hodnota je 0,431 ms (0,000431 s) a můžeme ji použít k odhadu průměru tps při min hodnota je 0,111 ms (0,000111 s), kterou můžeme použít k odhadu maxima tps. mdev znamená, jak byly vzorky RTT distribuovány z průměru. Nižší hodnota znamená stabilnější RTT.
Transakce za sekundu lze tedy odhadnout vydělením RTT (v sekundách) na 1 sekundu:

Výsledné,
- Minimální TPS:1 / 0,00134 (maximální RTT) =746,26 ~ 746 TPS
- Průměrná TPS:1/0,000431 (průměrná RTT) =2320,19 ~ 2320 TPS
- Maximální tps:1 / 0,000111 (min RTT) =9009,01 ~ 9009 tps
Všimněte si, že se jedná pouze o odhad pro předvídání výkonu replikace. Na straně databáze toho moc zlepšit nemůžeme, jakmile budeme mít vše nasazené a spuštěné. S výjimkou případů, kdy přesunete nebo migrujete databázové servery blíže k sobě, abyste zlepšili RTT mezi uzly nebo upgradovali síťová periferní zařízení nebo infrastrukturu. To by vyžadovalo dobu údržby a správné plánování.
Rozdělit velké transakce
Dalším faktorem je velikost transakce. Po přenosu sady zápisů proběhne proces certifikace. Certifikace je proces, který určuje, zda uzel může nebo nemůže použít sadu zápisů. Galera generuje pseudoklíče kontrolního součtu MD5 z každého celého řádku. Náklady na certifikaci závisí na velikosti sady zápisů, což se promítá do řady jedinečných vyhledávání klíčů v certifikačním indexu (hašovací tabulce). Pokud aktualizujete 500 000 řádků v jedné transakci, například:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Výše uvedené vygeneruje jednu sadu zápisů s 500 000 událostmi binárního protokolu. Tato obrovská sada zápisů nepřesahuje wsrep_max_ws_size (výchozí na 2 GB), takže bude přenesena replikačním modulem Galera do všech uzlů v clusteru, čímž se ověří těchto 500 000 řádků na uzlech přijímače pro jakékoli konfliktní transakce, které jsou stále ve frontě slave. Nakonec je stav certifikace vrácen modulu replikace skupiny. Čím větší je velikost transakce, tím vyšší je riziko, že bude konfliktní s jinými transakcemi, které pocházejí z jiného hlavního serveru. Konfliktní transakce plýtvají zdroji serveru a navíc způsobují obrovský návrat k původnímu uzlu. Všimněte si, že operace vrácení zpět v MySQL je mnohem pomalejší a méně optimalizovaná než operace potvrzení.
Výše uvedený příkaz SQL lze přepsat do příkazu přívětivějšího pro Galera pomocí jednoduché smyčky, jako je příklad níže:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneVýše uvedený příkaz shell by aktualizoval 1000 řádků na transakci 500krát a mezi provedeními by počkal 2 sekundy. K dosažení podobného výsledku můžete také použít uloženou proceduru nebo jiné prostředky. Pokud přepsání SQL dotazu není možné, jednoduše dejte aplikaci pokyn, aby provedla velkou transakci během období údržby, abyste snížili riziko konfliktů.
V případě velkých smazání zvažte použití pt-archiveru z Percona Toolkit – práce s nízkým dopadem, pouze dopředně určená k okusování starých dat z tabulky, aniž by to výrazně ovlivnilo dotazy OLTP.
Paralelní podřízená vlákna
V Galeře je aplikátor vícevláknový proces. Applier je vlákno běžící v Galeře, které aplikuje příchozí zápisové sady z jiného uzlu. Což znamená, že je možné, aby všechny přijímače vykonávaly více DML operací, které přicházejí přímo z původního (master) uzlu současně. Paralelní replikace Galera se aplikuje na transakce pouze tehdy, když je to bezpečné. Zlepšuje pravděpodobnost synchronizace uzlu s uzlem původce. Rychlost replikace je však stále omezena na RTT a velikost sady zápisu.
Abychom z toho dostali to nejlepší, potřebujeme vědět dvě věci:
- Počet jader serveru.
- Hodnota wsrep_cert_deps_distance stav.
Stav wsrep_cert_deps_distance nám říká potenciální stupeň paralelizace. Je to hodnota průměrné vzdálenosti mezi nejvyšší a nejnižší hodnotou seqno, kterou lze případně aplikovat paralelně. Můžete použít wsrep_cert_deps_distance stavová proměnná k určení maximálního možného počtu podřízených vláken. Vezměte na vědomí, že se jedná o průměrnou hodnotu v průběhu času. Abyste tedy získali dobrou hodnotu, musíte do clusteru zasáhnout operacemi zápisu prostřednictvím testovací zátěže nebo benchmarku, dokud neuvidíte, že vyjde stabilní hodnota.
Chcete-li získat počet jader, můžete jednoduše použít následující příkaz:
$ grep -c processor /proc/cpuinfo
4V ideálním případě jsou 2, 3 nebo 4 vlákna slave aplikace na jádro CPU dobrým začátkem. Minimální hodnota pro podřízená vlákna by tedy měla být 4 x počet jader CPU a nesmí překročit wsrep_cert_deps_distance hodnota:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Počet vláken slave aplikace můžete ovládat pomocí wsrep_slave_thread variabilní. I když se jedná o dynamickou proměnnou, pouze zvýšení čísla by mělo okamžitý účinek. Pokud snížíte hodnotu dynamicky, bude nějakou dobu trvat, než se vlákno aplikace po dokončení aplikace ukončí. Doporučená hodnota je kdekoli mezi 16 až 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Pamatujte, že aby paralelní podřízená vlákna fungovala, musí být nastaveno následující (což je obvykle předkonfigurováno pro Galera Cluster):
innodb_autoinc_lock_mode=2Cache Galera (gcache)
Galera používá předem přidělený soubor se specifickou velikostí zvanou gcache, kde uzel Galera uchovává kopii sad zápisů ve stylu kruhové vyrovnávací paměti. Ve výchozím nastavení je jeho velikost 128 MB, což je poměrně málo. Incremental State Transfer (IST) je metoda, jak připravit spojení odesláním pouze chybějících sad zápisů dostupných v gcache dárce. IST je rychlejší než přenos stavu snímku (SST), je neblokující a nemá žádný významný dopad na výkon na dárce. Měla by to být preferovaná možnost, kdykoli je to možné.
IST lze dosáhnout pouze v případě, že všechny změny, které připojil, jsou stále v souboru gcache dárce. Doporučené nastavení pro toto je být stejně velké jako celá datová sada MySQL. Pokud je místo na disku omezené nebo drahé, je rozhodující určit správnou velikost velikosti gcache, protože může ovlivnit výkon synchronizace dat mezi uzly Galera.
Níže uvedené prohlášení nám poskytne představu o množství dat replikovaných Galerou. Spusťte následující příkaz na jednom z uzlů Galera během špičkových hodin (testováno na MariaDB>10.0 a PXC>5.6, galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Můžeme odhadnout, že uzel Galera může mít přibližně 16 minut výpadku, aniž by bylo vyžadováno připojení SST (pokud Galera nemůže určit stav připojení). Pokud je to příliš krátká doba a na svých uzlech máte dostatek místa na disku, můžete změnit wsrep_provider_options="gcache.size=
Také se doporučuje použít gcache.recover=yes v wsrep_provider_options (Galera>3.19), kde se Galera pokusí obnovit soubor gcache do použitelného stavu při spuštění, místo aby jej smazal, čímž zachová schopnost mít IST a co nejvíce se vyhne SST. Codership a Percona se tomu podrobně věnovaly ve svých blozích. IST je vždy nejlepší metodou pro synchronizaci poté, co se uzel znovu připojí ke clusteru. Je o 50 % rychlejší než xtrabackup nebo mariabackup a 5x rychlejší než mysqldump.
Asynchronní Slave
Uzly Galera jsou těsně propojeny, kde je výkon replikace stejně rychlý jako nejpomalejší uzel. Galera používá mechanismus řízení toku, aby řídil tok replikace mezi členy a eliminoval jakékoli zpoždění slave. Replikace může být rychlá nebo pomalá na každém uzlu a Galera ji upravuje automaticky. Pokud se chcete dozvědět o řízení toku, přečtěte si tento blogový příspěvek od Jaye Janssena z Percona.
Ve většině případů jsou často nevyhnutelné náročné operace, jako jsou dlouhodobé analýzy (intenzivní čtení) a zálohování (intenzivní čtení, zamykání), které by mohly potenciálně snížit výkon clusteru. Nejlepší způsob, jak provést tento typ dotazů, je odeslat je na volně propojený replikovaný server, například asynchronní slave.
Asynchronní slave se replikuje z uzlu Galera pomocí standardního protokolu asynchronní replikace MySQL. Počet podřízených jednotek, které lze připojit k jednomu uzlu Galera, není omezen a je také možné zřetězení s mezilehlým masterem. Operace MySQL, které se provádějí na tomto serveru, neovlivní výkon clusteru, kromě počáteční fáze synchronizace, kdy je třeba provést úplnou zálohu na uzlu Galera, aby bylo možné připravit podřízenou jednotku před vytvořením replikačního spojení (ačkoli ClusterControl umožňuje vytvořit asynchronní slave nejprve z existující zálohy, než ji připojíte ke clusteru).
GTID (Global Transaction Identifier) poskytuje lepší mapování transakcí mezi uzly a je podporován v MySQL 5.6 a MariaDB 10.0. S GTID je operace převzetí služeb při selhání na podřízeném zařízení k jinému masteru (jinému uzlu Galera) zjednodušena, aniž by bylo nutné zjišťovat přesný soubor protokolu a pozici. Galera také přichází s vlastní implementací GTID, ale tyto dvě jsou na sobě nezávislé.
Škálování asynchronního slave zařízení je dostupné jediným kliknutím, pokud používáte funkci ClusterControl -> Add Replication Slave:
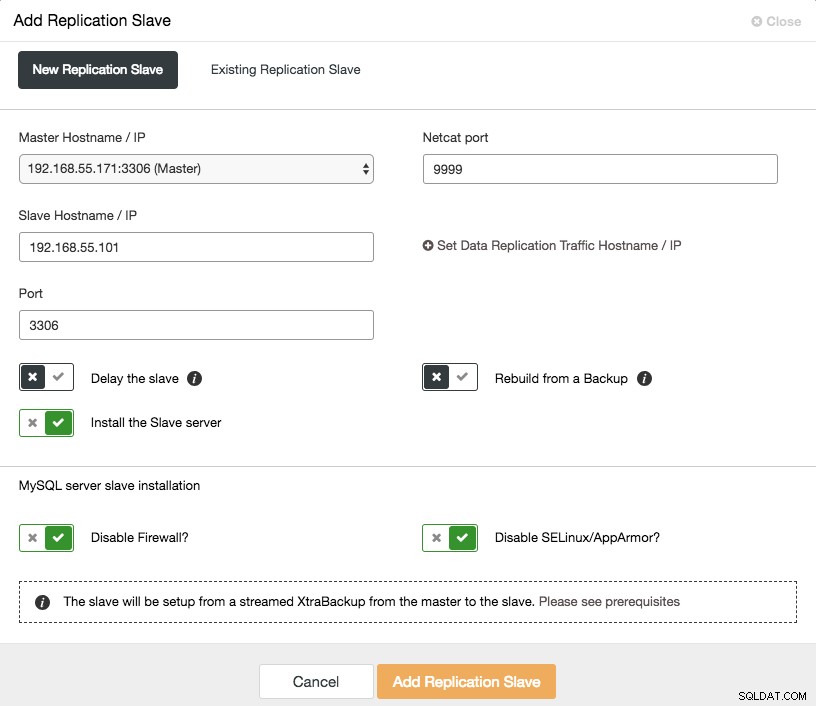
Vezměte na vědomí, že binární protokoly musí být povoleny na hlavním (vybraném uzlu Galera), než budeme moci pokračovat v tomto nastavení. Manuální způsob jsme také popsali v tomto předchozím příspěvku.
Následující snímek obrazovky z ClusterControl ukazuje topologii clusteru, ilustruje naši architekturu Galera Cluster s asynchronním slave:
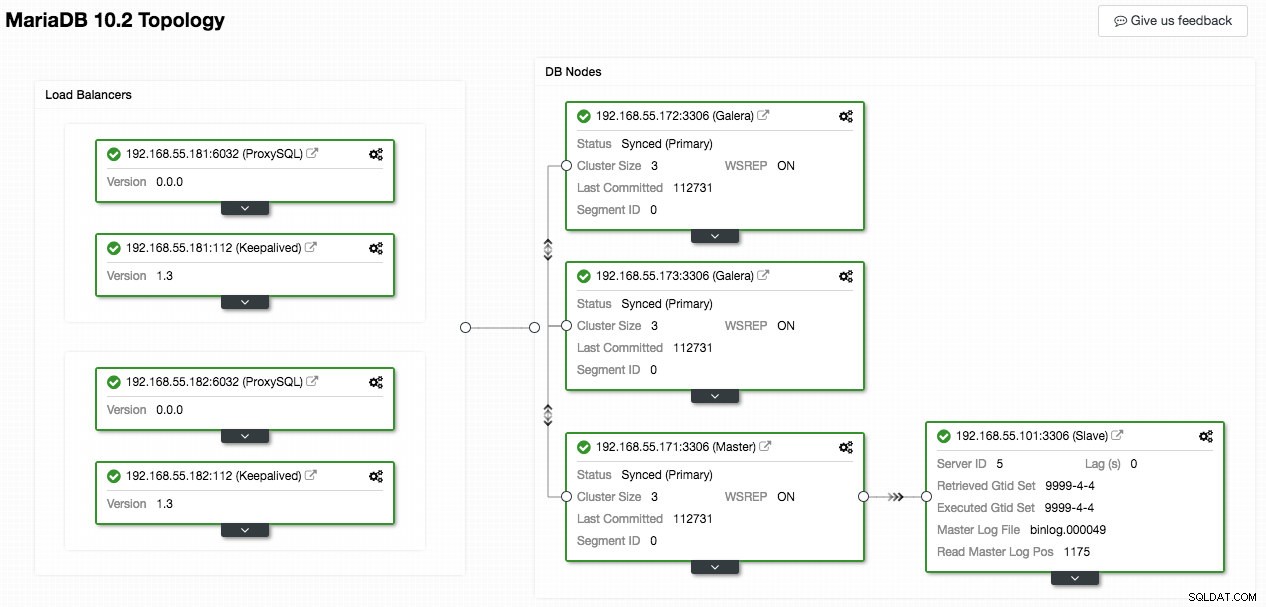
ClusterControl automaticky zjistí topologii a vygeneruje super cool diagram jako výše. Úlohy správy můžete také provádět přímo z této stránky kliknutím na ikonu ozubeného kola v pravém horním rohu každého pole.
Reverzní proxy s podporou SQL
ProxySQL a MariaDB MaxScale jsou inteligentní reverzní proxy, které rozumí protokolu MySQL a jsou schopné fungovat jako brána, router, vyvažovač zátěže a firewall před vašimi uzly Galera. S pomocí poskytovatele virtuálních IP adres, jako je LVS nebo Keepalived, a v kombinaci s technologií replikace multimaster Galera můžeme mít vysoce dostupnou databázovou službu, která eliminuje všechna možná selhání jednoho bodu (SPOF) z bodu aplikace. -pohledu. To jistě zlepší dostupnost a spolehlivost architektury jako celku.
Další výhodou tohoto přístupu je, že budete mít možnost monitorovat, přepisovat nebo přesměrovávat příchozí dotazy SQL na základě sady pravidel předtím, než zasáhnou skutečný databázový server, což minimalizuje změny na straně aplikace nebo klienta a směruje dotazy na vhodnější uzel pro optimální výkon. Rizikovým dotazům pro Galeru, jako jsou LOCK TABLES a FLUSH TABLES WITH READ LOCK, lze zabránit daleko dříve, než by způsobily zmatek v systému, zatímco mohou mít dopad na dotazy jako „hotspot“ dotazy (řádek, ke kterému chtějí mít přístup různé dotazy současně) být přepsány nebo přesměrovány do jediného uzlu Galera, aby se snížilo riziko konfliktů transakcí. V případě náročných dotazů pouze pro čtení, jako je OLAP nebo zálohování, je můžete směrovat na asynchronní slave zařízení, pokud nějaké máte.
Reverzní proxy také monitoruje stav databáze, dotazy a proměnné, aby pochopila změny topologie a vytvořila přesné rozhodnutí o směrování na backend servery. Nepřímo centralizuje monitorování uzlů a přehled clusterů, aniž by bylo nutné pravidelně kontrolovat každý jednotlivý uzel Galera. Následující snímek obrazovky ukazuje řídicí panel monitorování ProxySQL v ClusterControl:
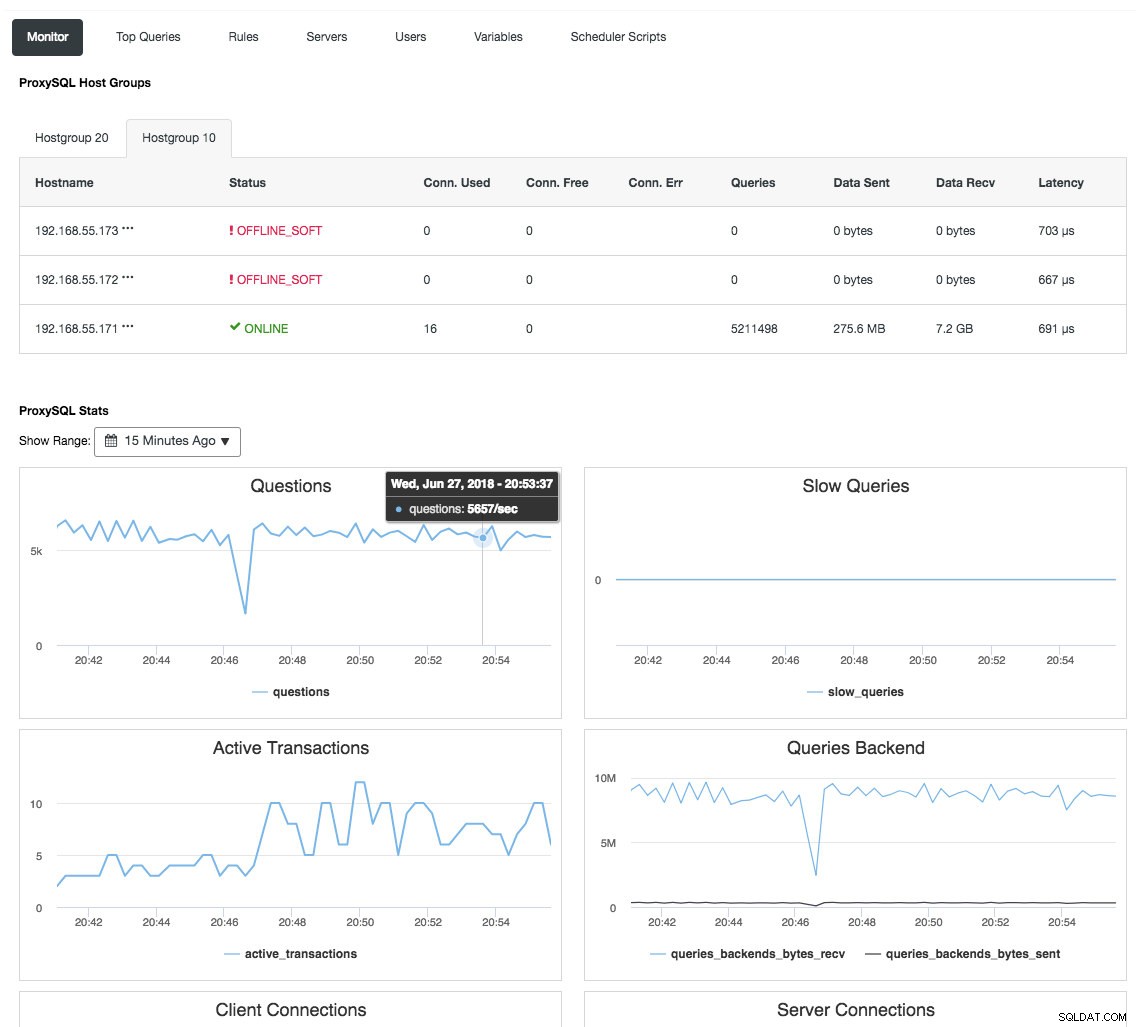
Existuje také mnoho dalších výhod, které může load balancer přinést k výraznému zlepšení Galera Cluster, jak je podrobně popsáno v tomto blogovém příspěvku, Staňte se ClusterControl DBA:Tvorba vašich DB komponent HA pomocí Load Balancers.
Poslední myšlenky
S dobrým pochopením toho, jak Galera Cluster interně funguje, můžeme obejít některá omezení a zlepšit databázovou službu. Šťastné shlukování!