Replikace MySQL master-slave je velmi snadná a přímočará na nastavení. To je hlavní důvod, proč lidé volí tuto technologii jako první krok k dosažení lepší dostupnosti databáze. Je to však za cenu složitosti správy a údržby; je na správci, aby zachoval integritu dat, zejména během převzetí služeb při selhání, navrácení služeb při selhání, údržby, upgradu a tak dále.
Existuje mnoho článků popisujících, jak provést operaci převzetí služeb při selhání pro nastavení replikace. Tomuto tématu jsme se také věnovali v tomto příspěvku na blogu Úvod do převzetí služeb při selhání pro replikaci MySQL – blog 101. V tomto blogovém příspěvku se budeme zabývat úlohami po katastrofě při obnově do původní topologie – provádění operace obnovení při selhání.
Proč potřebujeme Failback?
Vedoucí replikace (master) je nejkritičtějším uzlem v nastavení replikace. Vyžaduje dobré hardwarové specifikace, aby bylo zajištěno, že dokáže zpracovávat zápisy, generovat události replikace, zpracovávat kritická čtení a tak dále stabilním způsobem. Když je při obnově nebo údržbě po havárii vyžadováno převzetí služeb při selhání, nemusí být neobvyklé, že se setkáme s tím, že propagujeme nového lídra s horším hardwarem. Tato situace může být dočasně v pořádku, ale z dlouhodobého hlediska musí být určený master přiveden zpět, aby vedl replikaci poté, co bude považován za zdravý.
Na rozdíl od převzetí služeb při selhání se operace navrácení služeb při selhání obvykle odehrává v kontrolovaném prostředí prostřednictvím přepnutí, zřídka k tomu dochází v panickém režimu. Operačnímu týmu to poskytne určitý čas na pečlivé plánování a nacvičení cvičení pro hladký přechod. Hlavním cílem je jednoduše vrátit starého dobrého mastera do nejnovějšího stavu a obnovit nastavení replikace do původní topologie. Existují však případy, kdy je návrat po selhání kritický, například když nově povýšený hlavní server nefungoval podle očekávání a ovlivnil celkovou databázovou službu.
Jak bezpečně provést navrácení při selhání?
Po převzetí služeb při selhání by starý hlavní server byl mimo replikační řetězec kvůli údržbě nebo obnově. Chcete-li provést přepnutí, musíte provést následující:
- Uveďte starého pána do správného stavu tím, že z něj uděláte nejaktuálnějšího otroka.
- Zastavte aplikaci.
- Ověřte, že jsou všichni otroci zachyceni.
- Povýšit starého mistra jako nového vůdce.
- Přesměrujte všechny otroky na nového velitele.
- Spusťte aplikaci zápisem novému hlavnímu serveru.
Zvažte následující nastavení replikace:
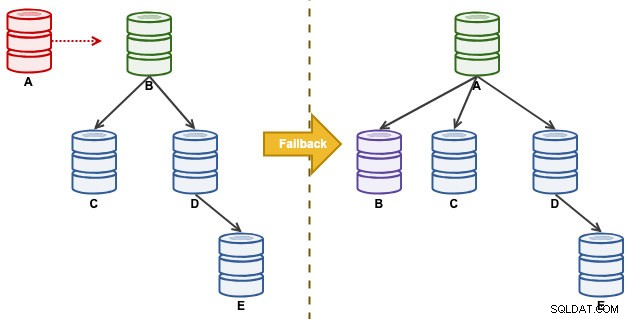
"A" bylo master až do události plného disku, která způsobila chaos v řetězci replikace. Po události převzetí služeb při selhání byla naše topologie replikace vedena B a replikuje se na C až E. Cvičení navrácení služeb při selhání vrátí A jako vedoucí a obnoví původní topologii před katastrofou. Vezměte na vědomí, že všechny uzly běží na MySQL 8.0.15 s povoleným GTID. Různé hlavní verze mohou používat různé příkazy a kroky.
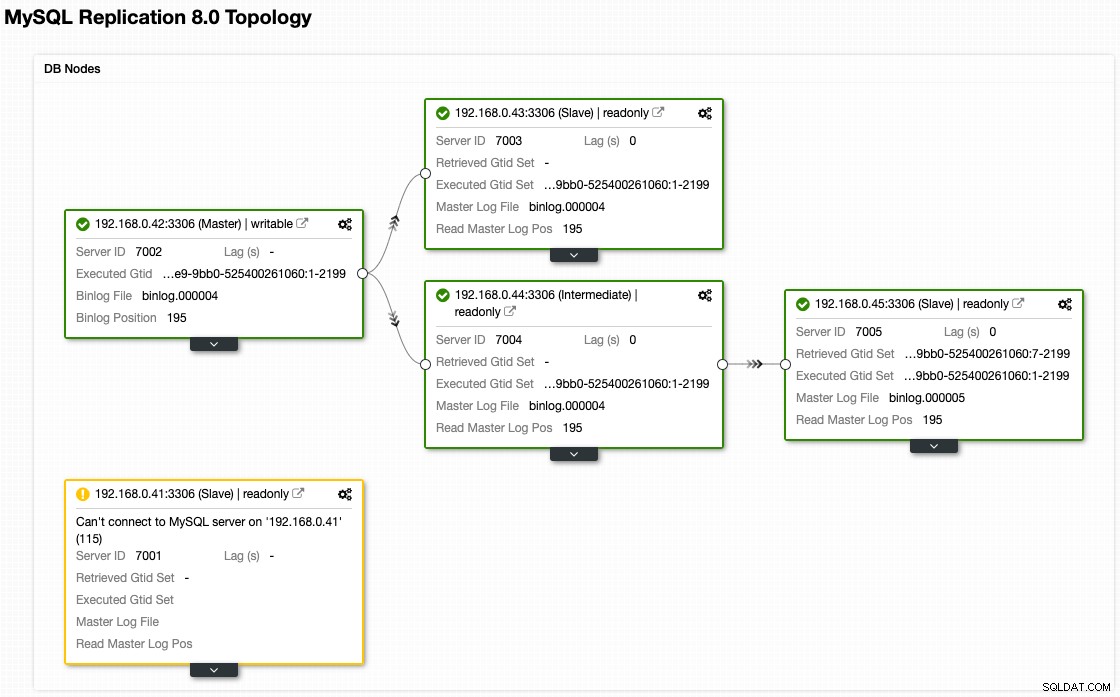
I když naše architektura nyní vypadá po převzetí služeb při selhání takto (převzato z pohledu topologie ClusterControl):
Zřizování uzlů
Než A může být master, musí být aktualizován podle aktuálního stavu databáze. Nejlepší způsob, jak toho dosáhnout, je přepnout A jako slave na aktivní master, B. Protože všechny uzly jsou nakonfigurovány s log_slave_updates=ON (to znamená, že slave také vytváří binární protokoly), můžeme ve skutečnosti vybrat další slave jako C a D jako zdroj pravdy pro počáteční synchronizaci. Čím blíže k aktivnímu pánovi, tím lépe. Při vytváření zálohy mějte na paměti další zatížení, které může způsobit. Tato část zabere většinu hodin obnovení. V závislosti na stavu uzlu a velikosti datové sady může synchronizace starého hlavního serveru nějakou dobu trvat (může to být hodiny a dny).
Jakmile je problém na "A" vyřešen a připraven k připojení k replikačnímu řetězci, nejlepším prvním krokem je pokusit se o replikaci z "B" (192.168.0.42) pomocí příkazu CHANGE MASTER:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Pokud replikace funguje, měli byste ve stavu replikace vidět následující:
Slave_IO_Running: Yes
Slave_SQL_Running: YesPokud se replikace nezdaří, podívejte se na Last_IO_Error nebo Last_SQL_Error z výstupu stavu slave. Pokud se například zobrazí následující chyba:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2Potom musíme vytvořit uživatele replikace na aktuálním aktivním hlavním serveru B:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;Poté restartujte slave na A, aby se znovu započalo s replikací:
mysql> STOP SLAVE;
mysql> START SLAVE;Další běžnou chybou, kterou byste viděli, je tento řádek:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...To pravděpodobně znamená, že slave má problém se čtením souboru binárního protokolu z aktuálního masteru. V některých případech může být slave daleko pozadu, takže na aktuálním masteru chyběly požadované binární události ke spuštění replikace nebo byl binární soubor na masteru vyčištěn během převzetí služeb při selhání a tak dále. V tomto případě je nejlepším způsobem provést úplnou synchronizaci vytvořením plné zálohy na B a jejím obnovením na A. Na B můžete použít buď mysqldump nebo Percona Xtrabackup k vytvoření plné zálohy:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupPřeneste záložní soubor do A, znovu inicializujte stávající instalaci MySQL pro řádné vyčištění a proveďte obnovu databáze:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordPo obnovení nastavte replikační odkaz na aktivní hlavní server B (192.168.0.42) a povolte pouze pro čtení. Na A spusťte následující příkazy:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Pro Percona Xtrabackup se prosím podívejte na stránku s dokumentací, jak obnovit do A. Před výměnou datového adresáře MySQL je nutné nejprve připravit zálohu.
Jakmile A začne správně replikovat, sledujte Seconds_Behind_Master ve stavu slave. To vám dá představu o tom, jak daleko za sebou otrok zanechal a jak dlouho musíte čekat, než to dožene. V tuto chvíli naše architektura vypadá takto:
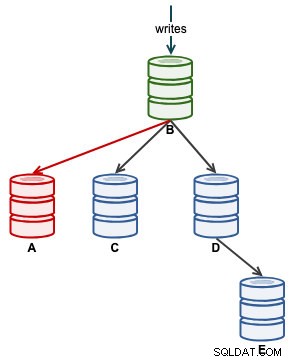
Jakmile Seconds_Behind_Master klesne zpět na 0, to je okamžik, kdy A dohoní jako aktuální otrok.
Pokud používáte ClusterControl, máte možnost znovu synchronizovat uzel obnovením ze stávající zálohy nebo vytvořit a streamovat zálohu přímo z aktivního hlavního uzlu:
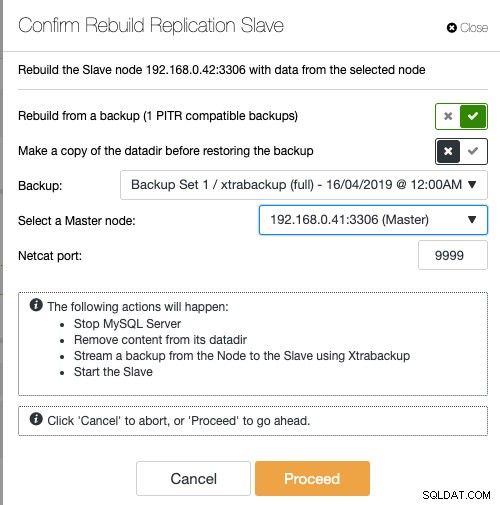
Doporučený způsob vytvoření podřízeného zařízení se stávající zálohou je vytvoření podřízeného zařízení, protože při přípravě uzlu to nijak neovlivní aktivní hlavní server.
Propagujte starého mistra
Před povýšením A jako nového hlavního serveru je nejbezpečnějším způsobem zastavit všechny operace zápisu na B. Pokud to není možné, jednoduše přinuťte B pracovat v režimu pouze pro čtení:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Poté na A spusťte SHOW SLAVE STATUS a zkontrolujte následující stav replikace:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesHodnota Read_Master_Log_Pos a Exec_Master_Log_Pos musí být identická, zatímco Seconds_Behind_Master je 0 a stav musí být 'Slave přečetl celý protokol relé'. Ujistěte se, že všichni podřízení zpracovali všechny příkazy ve svém předávacím protokolu, jinak riskujete, že nové dotazy ovlivní transakce z předávacího protokolu a způsobí nejrůznější problémy (aplikace může například odstranit některé řádky, ke kterým mají transakce přístup. z protokolu relé).
Na A zastavte replikaci a pomocí příkazu RESET SLAVE ALL odstraňte veškerou konfiguraci související s replikací a zakažte pouze čtení:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';V tomto okamžiku je A připraven přijímat zápisy (read_only=OFF), avšak podřízené jednotky k němu nejsou připojeny, jak je znázorněno níže:
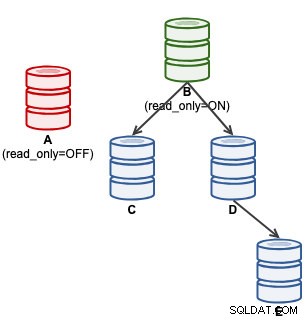
Pro uživatele ClusterControl lze propagaci A provést pomocí funkce "Promote Slave" pod Node Actions. ClusterControl automaticky degraduje aktivního mastera B, povýší slave A jako master a znovu nasměruje C a D, aby se replikovaly z A. B bude odložen a uživatel musí explicitně zvolit "Change Replication Master", aby se znovu připojil k B replikaci z A v pozdější fázi. .
Přesměrování podřízených
Nyní je bezpečné změnit master na souvisejících podřízených, aby se replikovaly z A (192.168.0.41). Na všech podřízených zařízeních kromě E nakonfigurujte následující:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Pokud jste uživatelem ClusterControl, můžete tento krok přeskočit, protože přemístění se provádí automaticky, když jste se dříve rozhodli povýšit A.
Potom můžeme spustit naši aplikaci a psát na A. V tuto chvíli naše architektura vypadá asi takto:
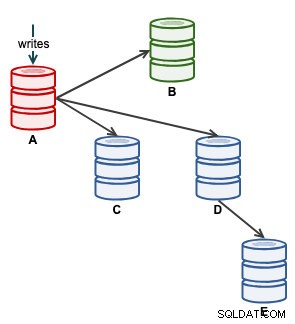
Z pohledu topologie ClusterControl jsme obnovili náš replikační cluster na jeho původní architekturu, která vypadá takto:
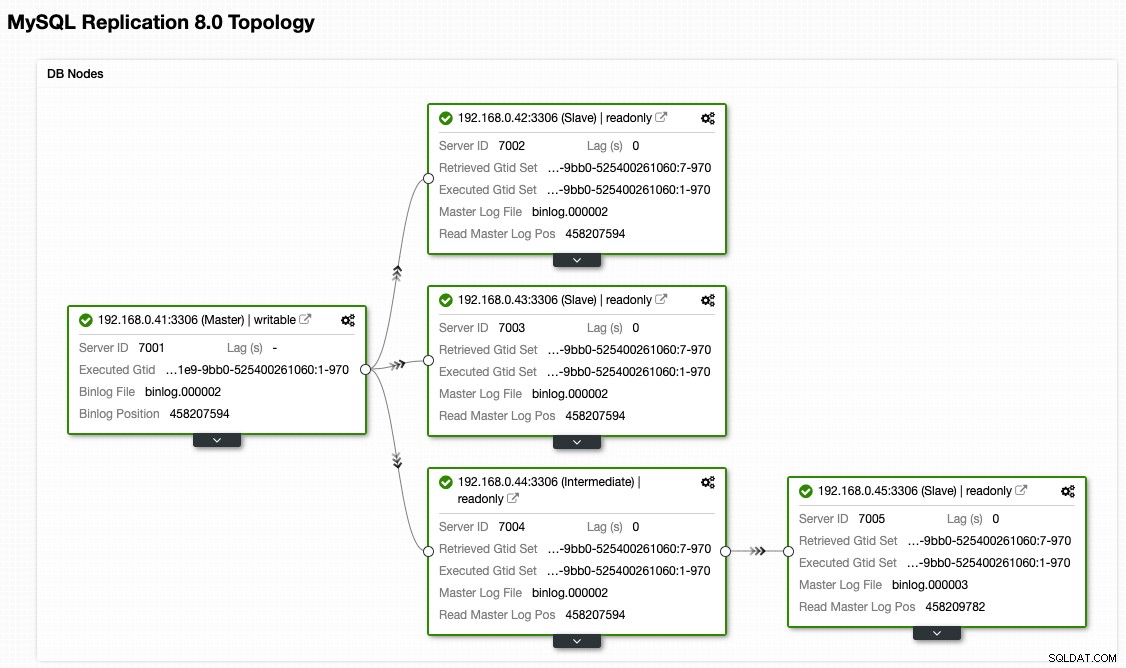
Vezměte na vědomí, že cvičení navrácení při selhání je mnohem méně riskantní ve srovnání s převzetím služeb při selhání. Je důležité naplánovat toto cvičení na hodiny mimo špičku, abyste minimalizovali dopad na vaši firmu.
Poslední myšlenky
Operace převzetí služeb při selhání a navrácení služeb při selhání musí být prováděny opatrně. Operace je poměrně jednoduchá, pokud máte malý počet uzlů, ale pro více uzlů se složitým replikačním řetězcem by to mohlo být riskantní cvičení náchylné k chybám. Také jsme ukázali, jak lze ClusterControl použít ke zjednodušení složitých operací jejich prováděním prostřednictvím uživatelského rozhraní a navíc zobrazení topologie je vizualizováno v reálném čase, takže rozumíte topologii replikace, kterou chcete vytvořit.