Pokud vaše IT infrastruktura běží na AWS, pravděpodobně jste slyšeli o službě Amazon Relational Database Service (RDS), snadném způsobu, jak nastavit, provozovat a škálovat relační databázi v cloudu. Poskytuje nákladově efektivní kapacitu s měnitelnou velikostí a zároveň automatizuje časově náročné administrativní úlohy, jako je zajišťování hardwaru, nastavení databáze, záplatování a zálohování. Existuje řada nabídek databázových strojů pro RDS, jako jsou MySQL, MariaDB, PostgreSQL, Microsoft SQL Server a Oracle Server.
ClusterControl 1.7.3 funguje podobně jako RDS, protože podporuje nasazení, správu, monitorování a škálování databázového clusteru na platformě AWS. Podporuje také řadu dalších cloudových platforem, jako je Google Cloud Platform a Microsoft Azure. ClusterControl rozumí topologii databáze a je schopen provádět automatickou obnovu, správu topologie a mnoho dalších pokročilých funkcí pro převzetí kontroly nad vaší databází.
V tomto příspěvku na blogu porovnáme doby automatického převzetí služeb při selhání pro Amazon Aurora, Amazon RDS pro MySQL a nastavení replikace MySQL nasazené a spravované ClusterControl. Typ převzetí služeb při selhání, který se chystáme provést, je povýšení podřízeného zařízení v případě, že hlavní zařízení selže. Zde nejnovější slave přebírá hlavní roli v klastru, aby obnovil databázovou službu.
Náš test převzetí služeb při selhání
Abychom změřili dobu převzetí služeb při selhání, spustíme jednoduchý test aktualizace připojení MySQL se smyčkou pro počítání stavu příkazů SQL, které se připojují k jednomu koncovému bodu databáze. Skript vypadá takto:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Výše uvedený skript Bash se jednoduše připojí k hostiteli MySQL a provede aktualizaci na jednom řádku s časovým limitem 1 sekundy u příkazů klienta Bash i mysql. Parametry související s časovými limity jsou povinné, abychom mohli správně měřit prostoje v sekundách, protože klient mysql se ve výchozím nastavení vždy znovu připojí, dokud nedosáhne MySQL wait_timeout. Předem jsme naplnili testovací datovou sadu následujícím příkazem:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareSkript hlásí, zda byl výše uvedený dotaz úspěšný (OK) nebo selhal (Fail). Ukázkové výstupy jsou zobrazeny níže.
Failover s Amazon RDS pro MySQL
V našem testu používáme nejnižší nabídku RDS s následujícími specifikacemi:
- Verze MySQL:5.7.22
- vCPU:4
- RAM:16 GB
- Typ úložiště:Provisioned IOPS (SSD)
- IOPS:1000
- Úložiště:100 GB
- Replikace Multi-AZ:Ano
Poté, co Amazon RDS zřídí vaši instanci DB, můžete k připojení k instanci použít jakoukoli standardní klientskou aplikaci nebo nástroj MySQL. V připojovacím řetězci zadáte adresu DNS z koncového bodu instance DB jako parametr hostitele a jako parametr portu zadejte číslo portu z koncového bodu instance DB.
Podle stránky dokumentace Amazon RDS se v případě plánovaného nebo neplánovaného výpadku vaší instance DB Amazon RDS automaticky přepne do pohotovostní repliky v jiné zóně dostupnosti, pokud jste povolili Multi-AZ. Doba potřebná k dokončení převzetí služeb při selhání závisí na aktivitě databáze a dalších podmínkách v době, kdy se primární instance DB stala nedostupnou. Doby převzetí služeb při selhání jsou obvykle 60–120 sekund.
Abychom iniciovali převzetí služeb při selhání více AZ v RDS, provedli jsme operaci restartu se zaškrtnutou možností „Reboot with Failover“, jak ukazuje následující snímek obrazovky:
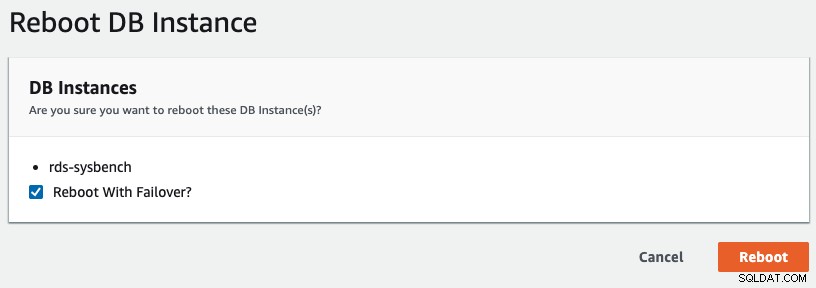
Naše aplikace pozoruje následující:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...Odstávka MySQL, jak je vidět na straně aplikace, byla zahájena od 03:41:09 do 03:41:36, což je celkem asi 27 sekund. Z událostí RDS můžeme vidět, že k převzetí služeb při selhání multi-AZ došlo pouze 15 sekund po skutečném výpadku:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Jakmile se nová instance databáze kolem 03:41:33 restartovala, byla služba MySQL dostupná přibližně o 3 sekundy později.
Failover s Amazon Aurora pro MySQL
Amazon Aurora lze považovat za lepší verzi RDS se spoustou pozoruhodných funkcí, jako je rychlejší replikace se sdíleným úložištěm, žádná ztráta dat při převzetí služeb při selhání a až 64 TB úložného limitu. Amazon Aurora pro MySQL je založen na open source MySQL Edition, ale sám o sobě není open source; je to proprietární databáze s uzavřeným zdrojem. Podobně to funguje s replikací MySQL (jeden a pouze jeden hlavní, s více podřízenými zařízeními) a převzetí služeb při selhání automaticky řeší Amazon Aurora.
Podle nejčastějších dotazů Amazon Aurora, pokud máte repliku Amazon Aurora ve stejné nebo jiné zóně dostupnosti, při selhání Aurora převrátí kanonický záznam názvu (CNAME) pro vaši instanci DB tak, aby ukazoval na zdravou repliku, která je v turn je povýšen na nového primárního. Od začátku do konce, převzetí služeb při selhání obvykle skončí do 30 sekund.
Pokud nemáte repliku Amazon Aurora (tj. jednu instanci), Aurora se nejprve pokusí vytvořit novou instanci DB ve stejné zóně dostupnosti jako původní instance. Pokud tak neučiní, Aurora se pokusí vytvořit novou instanci DB v jiné zóně dostupnosti. Od začátku do konce se převzetí služeb při selhání obvykle dokončí za méně než 15 minut.
Vaše aplikace by se měla v případě ztráty připojení znovu pokusit o připojení k databázi.
Poté, co Amazon Aurora zřídí vaši instanci DB, získáte dva koncové body, jeden pro zapisovače a jeden pro čtenáře. Koncový bod čtečky poskytuje podporu vyrovnávání zátěže pro připojení pouze pro čtení ke clusteru DB. Následující koncové body jsou převzaty z našeho testovacího nastavení:
- autor – aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- čtenář – aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
V našem testu jsme použili následující specifikace Aurora:
- Typ instance:db.r5.large
- Verze MySQL:5.7.12
- vCPU:2
- RAM:16 GB
- Replikace Multi-AZ:Ano
Chcete-li spustit převzetí služeb při selhání, jednoduše vyberte instanci zapisovače -> Akce -> Přepnutí při selhání, jak je znázorněno na následujícím snímku obrazovky:
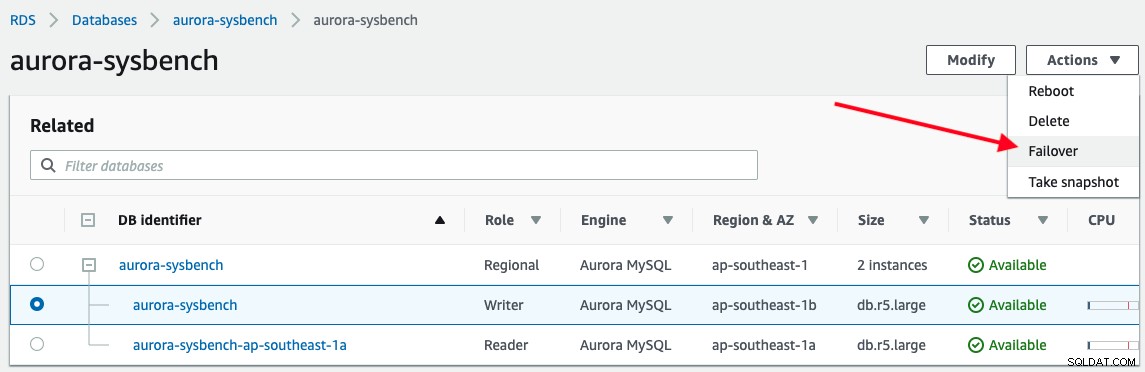
Při připojování ke koncovému bodu zapisovače Aurora je naší aplikací hlášen následující výstup :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...Odstávka databáze byla zahájena v 12:35:49 až 12:35:56 s celkovou dobou 7 sekund. To je docela působivé.
Při pohledu na událost databáze z konzoly pro správu Aurora se staly pouze tyto dvě události:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedAuroře netrvá dlouho, než povýší otroka na pána a degraduje pána na otroka. Všimněte si, že všechny repliky Aurora sdílejí stejný základní svazek s primární instancí a to znamená, že replikaci lze provést během milisekund, protože aktualizace provedené primární instancí jsou okamžitě dostupné všem replikám Aurora. Proto má minimální zpoždění replikace (Amazon tvrdil, že je 100 milisekund a méně). To výrazně zkrátí dobu kontroly stavu a výrazně zlepší dobu zotavení.
Přepnutí při selhání s ClusterControl
V tomto příkladu napodobujeme podobné nastavení s Amazon RDS pomocí instancí m5.xlarge, s ProxySQL mezi nimi pro automatizaci převzetí služeb při selhání z aplikace využívající přístup z jednoho koncového bodu, stejně jako RDS. Následující diagram ilustruje naši architekturu:
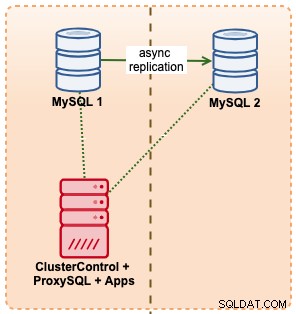
Vzhledem k tomu, že máme přímý přístup k instancím databáze, spustili bychom automatické převzetí služeb při selhání jednoduchým ukončením procesu MySQL na aktivním hlavním serveru:
$ kill -9 $(pidof mysqld)Výše uvedený příkaz spustil automatické obnovení uvnitř ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Zatímco z pohledu naší testovací aplikace došlo k výpadku v následující době při připojování k hostitelskému portu ProxySQL 6033:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Při pohledu na události úlohy obnovy a výstup z naší aplikace byl databázový uzel MySQL mimo provoz 4 sekundy před zahájením úlohy obnovy clusteru, od 11:08:28 do 11:08:39, s celkovým výpadkem MySQL 11 sekund. . Jednou z nejpůsobivějších věcí na ClusterControl je, že můžete sledovat průběh obnovy podle toho, jaké akce ClusterControl provádí a provádí během převzetí služeb při selhání. Poskytuje úroveň transparentnosti, kterou nebudete moci získat s žádnou databázovou nabídkou poskytovatelů cloudu.
Pro replikaci MySQL/MariaDB/PostgreSQL vám ClusterControl umožňuje mít jemnější srovnání s databázemi s podporou následující pokročilé konfigurace a parametrů:
- Správa topologie replikace Master-master
- Správa topologie replikace řetězce
- Prohlížeč topologie
- Otroci na bílé/černé listině budou povýšeni na velitele
- Chybná kontrola transakcí
- Před/po, úspěch/neúspěšné převzetí služeb při selhání/přepnutí se spojí s externím skriptem
- Automatické znovu sestavení slave při chybě
- Rozšířit podřízenou jednotku ze stávající zálohy
Shrnutí doby převzetí služeb při selhání
Pokud jde o dobu převzetí služeb při selhání, Amazon RDS Aurora pro MySQL je jasným vítězem s 7 sekundami a poté ClusterControl 11 sekund a Amazon RDS pro MySQL s 27 sekundami .
Všimněte si, že se jedná pouze o jednoduchý test s jedním klientem a jednou transakcí za sekundu k měření nejrychlejší doby zotavení. Velké transakce nebo zdlouhavý proces obnovy mohou prodloužit dobu převzetí služeb při selhání, např. dlouho běžící transakce mohou trvat dlouho, než se vrátí zpět při vypínání MySQL.