Jednotný bod selhání (SPOF) je častým důvodem, proč organizace pracují na distribuci přítomnosti svých databázových prostředí do jiného geografického umístění. Je součástí strategických plánů obnovy po havárii a kontinuity podnikání.
Plánování obnovy po havárii (DR) zahrnuje technické postupy, které pokrývají přípravu na neočekávané problémy, jako jsou přírodní katastrofy, nehody (jako je lidská chyba) nebo incidenty (jako jsou trestné činy).
V posledním desetiletí byla distribuce databázového prostředí na více geografických místech docela běžným nastavením, protože veřejné cloudy nabízejí mnoho způsobů, jak se s tím vypořádat. Výzva přichází v nastavení databázových prostředí. To vytváří problémy, když se pokoušíte spravovat databázi (databáze), přesouvat data do jiné geografické polohy nebo používat zabezpečení s vysokou úrovní pozorovatelnosti.
V tomto blogu si ukážeme, jak to lze provést pomocí replikace MySQL. Probereme, jak můžete zkopírovat svá data do jiného databázového uzlu umístěného v jiné zemi vzdálené od aktuální geografie clusteru MySQL. V tomto příkladu je náš cílový region založen na nás-východ, zatímco moje on-prem je v Asii na Filipínách.
Proč potřebuji cluster databáze geografických poloh?
Dokonce i Amazon AWS, přední poskytovatel veřejného cloudu, tvrdí, že trpí výpadky nebo nezamýšlenými výpadky (jako ten, ke kterému došlo v roce 2017). Řekněme, že kromě vašeho on-prem používáte AWS jako sekundární datové centrum. Nemůžete mít žádný interní přístup k základnímu hardwaru nebo k těm interním sítím, které spravují vaše výpočetní uzly. Jedná se o plně spravované služby, které jste si zaplatili, ale nevyhnete se tomu, že mohou kdykoli trpět výpadkem. Pokud taková geografická poloha utrpí výpadek, můžete mít dlouhé prostoje.
Tento typ problému je třeba předvídat při plánování kontinuity podnikání. Musí být analyzován a implementován na základě toho, co bylo definováno. Obchodní kontinuita pro vaše databáze MySQL by měla zahrnovat vysokou dobu provozuschopnosti. Některá prostředí provádějí srovnávací testy a nastavují vysokou laťku přísných testů, včetně slabých stránek, aby odhalila jakoukoli zranitelnost, jak odolná může být a jak škálovatelná vaše technologická architektura včetně databázové infrastruktury. Pro podniky, zejména ty, které zpracovávají velké transakce, je nezbytné zajistit, aby produkční databáze byly pro aplikace neustále dostupné, i když dojde ke katastrofě. Jinak může dojít k prostojům a může vás to stát velké množství peněz.
S těmito identifikovanými scénáři začnou organizace rozšiřovat svou infrastrukturu na různé poskytovatele cloudu a umísťovat uzly do různých geografických umístění, aby měly delší dobu provozuschopnosti (pokud možno na 99,99999999999), nižší RPO a neměly SPOF.
Chcete-li zajistit, aby produkční databáze přežily katastrofu, musí být nakonfigurována lokalita zotavení po havárii (DR). Produkční a DR místa musí být součástí dvou geograficky vzdálených datových center. To znamená, že v místě DR musí být pro každou produkční databázi nakonfigurována záložní databáze, aby se změny dat, ke kterým dojde v produkční databázi, okamžitě synchronizovaly s rezervní databází prostřednictvím transakčních protokolů. Některá nastavení také používají své uzly DR ke zpracování čtení, aby bylo zajištěno vyvažování zátěže mezi aplikací a datovou vrstvou.
Požadované architektonické nastavení
Na tomto blogu je požadované nastavení jednoduché a v dnešní době velmi běžné. Podívejte se níže na požadované architektonické nastavení pro tento blog:
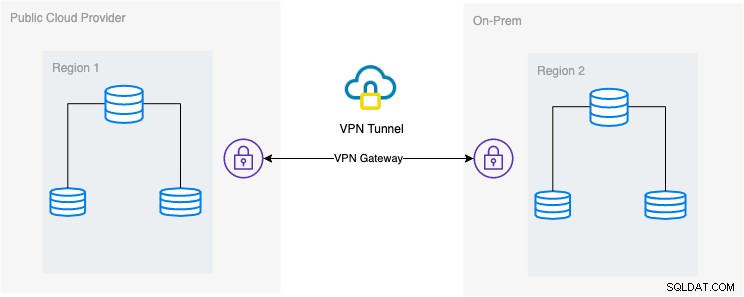
V tomto blogu jsem zvolil Google Cloud Platform (GCP) jako veřejný cloud poskytovatele a používání mé místní sítě jako vlastního databázového prostředí.
Je nutné, abyste při použití tohoto typu designu vždy potřebovali prostředí i platformu, aby komunikovaly velmi bezpečným způsobem. Pomocí VPN nebo pomocí alternativ, jako je AWS Direct Connect. I když tyto veřejné cloudy dnes nabízejí spravované služby VPN, které můžete využít. Ale pro toto nastavení budeme používat OpenVPN, protože pro tento blog nepotřebuji sofistikovaný hardware ani službu.
Nejlepší a nejúčinnější způsob
Pro databázová prostředí MySQL/Percona/MariaDB je nejlepším a nejefektivnějším způsobem pořízení záložní kopie databáze a její odeslání do cílového uzlu k nasazení nebo vytvoření instance. Existují různé způsoby, jak použít tento přístup, buď můžete použít mysqldump, mydump, rsync, nebo použít Percona XtraBackup/Mariabackup a streamovat data směřující do vašeho cílového uzlu.
Použití mysqldump
mysqldump vytvoří logickou zálohu celé vaší databáze nebo si můžete selektivně vybrat seznam databází, tabulek nebo dokonce konkrétních záznamů, které chcete vypsat.
Jednoduchým příkazem, který můžete použít k vytvoření úplné zálohy, může být
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsPomocí tohoto jednoduchého příkazu přímo spustí příkazy MySQL do cílového databázového uzlu, například do cílového databázového uzlu na výpočetním stroji Google. To může být efektivní, když jsou data menší nebo máte rychlou šířku pásma. V opačném případě může být vaší volbou zabalení databáze do souboru a její odeslání do cílového uzlu.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathPotom spusťte mysqldump do cílového databázového uzlu jako takového,
zcat mydata.db | mysqlNevýhodou používání logického zálohování pomocí mysqldump je, že je pomalejší a spotřebovává místo na disku. Také používá jedno vlákno, takže to nemůžete spustit paralelně. Volitelně můžete použít mydump, zvláště když jsou vaše data příliš velká. mydumper lze spustit paralelně, ale není tak flexibilní ve srovnání s mysqldump.
Použití xtrabackup
xtrabackup je fyzická záloha, do které můžete odesílat streamy nebo binární soubory do cílového uzlu. To je velmi efektivní a většinou se používá při streamování zálohy přes síť, zejména pokud je cílový uzel z jiné geografie nebo jiného regionu. ClusterControl používá xtrabackup při zřizování nebo vytváření instance nového slave zařízení bez ohledu na to, kde se nachází, pokud byl před akcí nastaven přístup a oprávnění.
Pokud používáte xtrabackup k ručnímu spuštění, můžete příkaz spustit jako takový,
## Cílový uzel
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## Zdrojový uzel
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999Aby byly tyto dva příkazy vypracovány, musí být na cílovém uzlu proveden nebo spuštěn první příkaz. Příkaz cílového uzlu naslouchá na portu 9999 a zapíše jakýkoli proud přijatý z portu 9999 v cílovém uzlu. Závisí na příkazech socat a xbstream, což znamená, že musíte mít nainstalované tyto balíčky.
Na zdrojovém uzlu spustí perl skript innobackupex, který na pozadí vyvolá xtrabackup a použije xbstream ke streamování dat, která budou odeslána přes síť. Příkaz socat otevře port 9999 a odešle svá data do požadovaného hostitele, kterým je v tomto příkladu 192.168.10.70. Přesto se při použití tohoto příkazu ujistěte, že máte nainstalovaný socat a xbstream. Alternativní způsob použití socatu je nc, ale socat nabízí ve srovnání s nc pokročilejší funkce, jako je serializace, protože na portu může poslouchat více klientů.
ClusterControl používá tento příkaz při přestavbě slave nebo budování nového slave. Je to rychlé a zaručuje, že přesná kopie vašich zdrojových dat bude zkopírována do vašeho cílového uzlu. Při zřizování nové databáze do samostatného geografického umístění nabízí tento přístup vyšší efektivitu a nabízí rychlejší dokončení úlohy. I když použití logické nebo binární zálohy při streamování po drátě může mít klady a zápory. Použití této metody je velmi běžný přístup při nastavování nového klastru geografických databází do jiné oblasti a vytváření přesné kopie vašeho databázového prostředí.
Efektivita, pozorovatelnost a rychlost
Otázky většiny lidí, kteří nejsou obeznámeni s tímto přístupem, se vždy týkají problémů „JAK, CO, KDE“. V této části se budeme zabývat tím, jak můžete efektivně nastavit databázi geografických poloh s menším úsilím a sledovatelností, proč selhává. Použití ClusterControl je velmi efektivní. V tomto aktuálním nastavení mám následující prostředí, jak bylo původně implementováno:
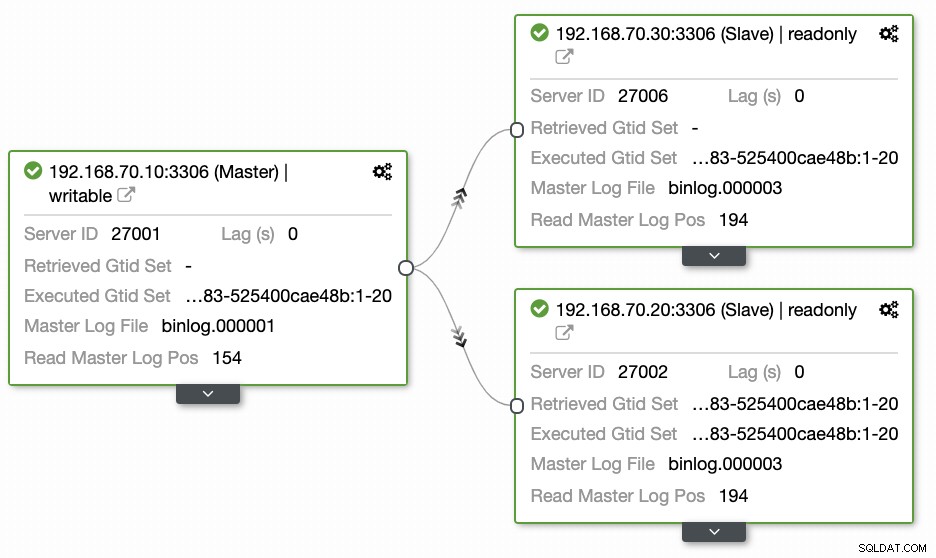
Rozšíření uzlu na GCP
Začnete-li nastavovat klastr databáze geografické polohy, rozšířit klastr a vytvořit kopii snímku klastru, můžete přidat nového slave. Jak již bylo zmíněno dříve, ClusterControl použije xtrabackup (mariabackup pro MariaDB 10.2 a novější) a nasadí nový uzel v rámci vašeho clusteru. Než budete moci zaregistrovat své výpočetní uzly GCP jako cílové uzly, musíte nejprve nastavit příslušného systémového uživatele, který je stejný jako systémový uživatel, kterého jste zaregistrovali v ClusterControl. Můžete to ověřit v souboru /etc/cmon.d/cmon_X.cnf, kde X je cluster_id. Viz například níže:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (v tomto příkladu) musí být přítomen ve vašich výpočetních uzlech GCP. Uživatel ve vašich uzlech GCP musí mít oprávnění sudo nebo superadmin. Musí být také nastaven s přístupem SSH bez hesla. Přečtěte si prosím naši dokumentaci více o uživateli systému a jeho požadovaných oprávněních.
Ukažme si příklad seznamu serverů níže (z konzoly GCP:řídicí panel Compute Engine):
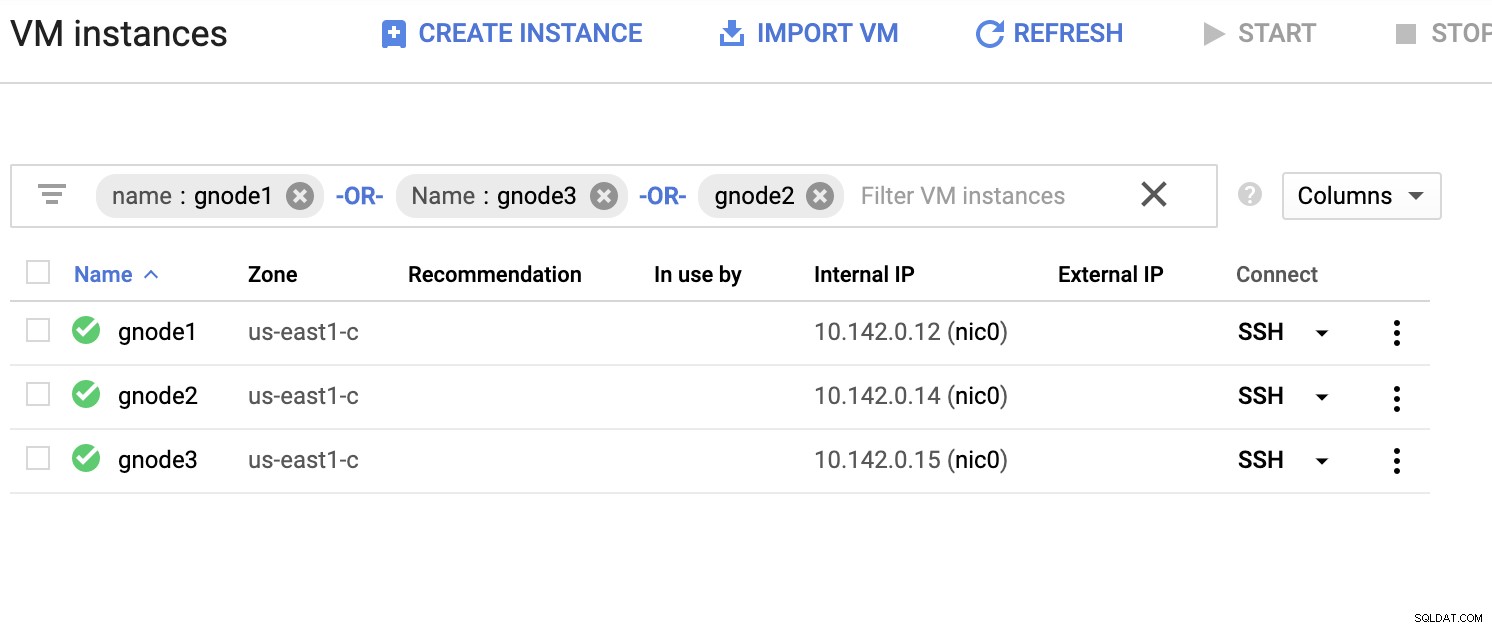
Na výše uvedeném snímku obrazovky je náš cílový region založen na východě USA kraj. Jak bylo uvedeno dříve, moje místní síť je nastavena přes zabezpečenou vrstvu procházející GCP (naopak) pomocí OpenVPN. Takže komunikace z GCP směřující do mé místní sítě je také zapouzdřena přes tunel VPN.
Přidat podřízený uzel do GCP
Snímek obrazovky níže ukazuje, jak to můžete udělat. Viz obrázky níže:
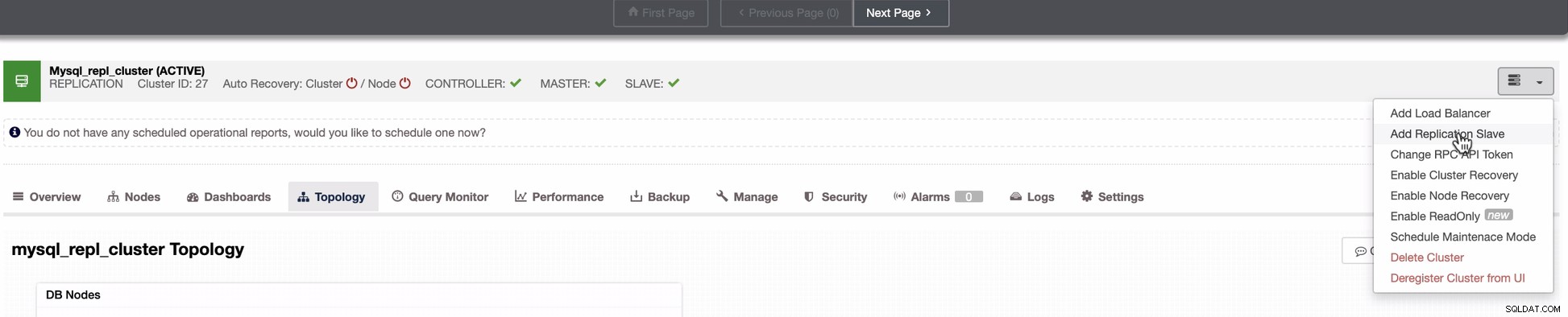
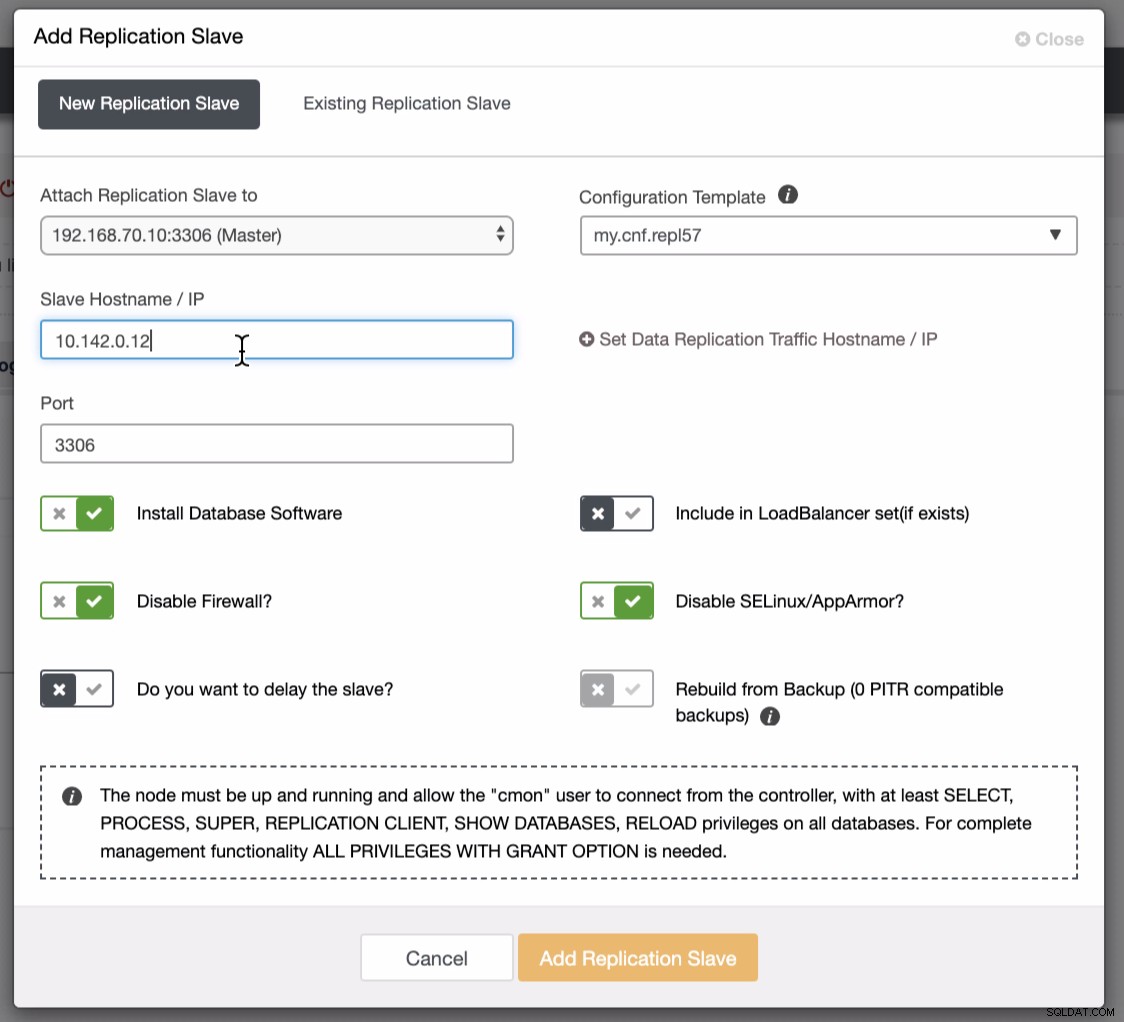
Jak je vidět na druhém snímku obrazovky, cílíme na uzel 10.142.0.12 a jeho zdrojový master je 192.168.70.10. ClusterControl je dostatečně chytrý, aby určil firewally, bezpečnostní moduly, balíčky, konfiguraci a nastavení, které je třeba provést. Níže naleznete příklad protokolu činnosti úlohy:
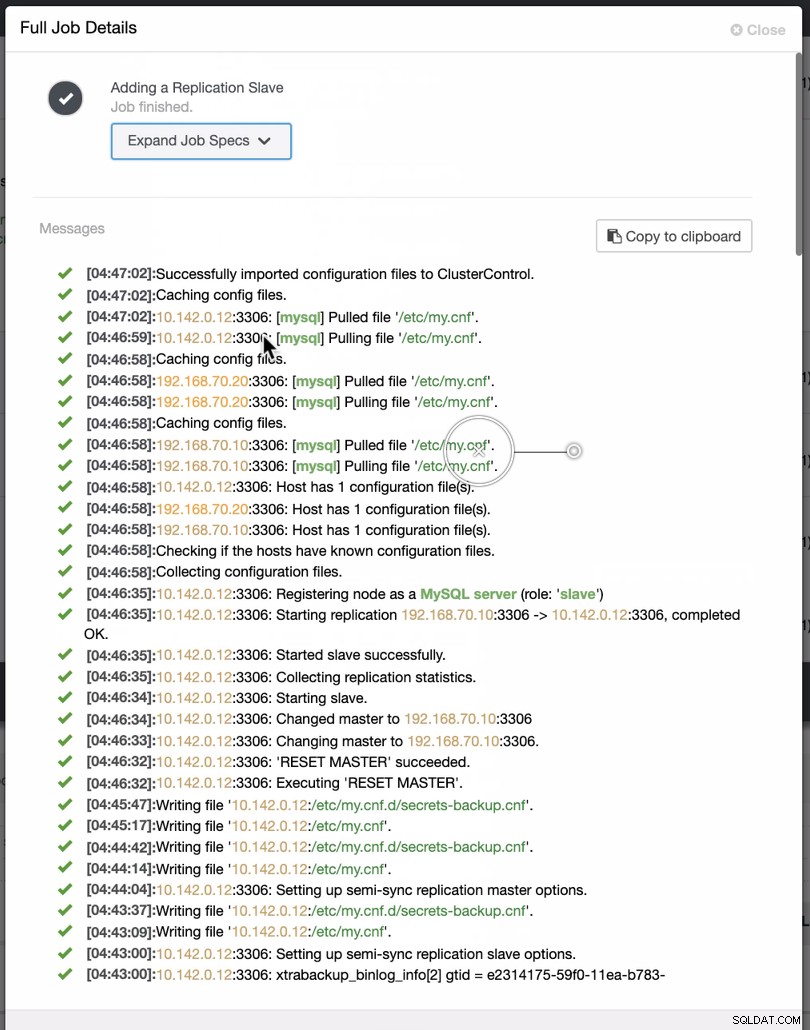
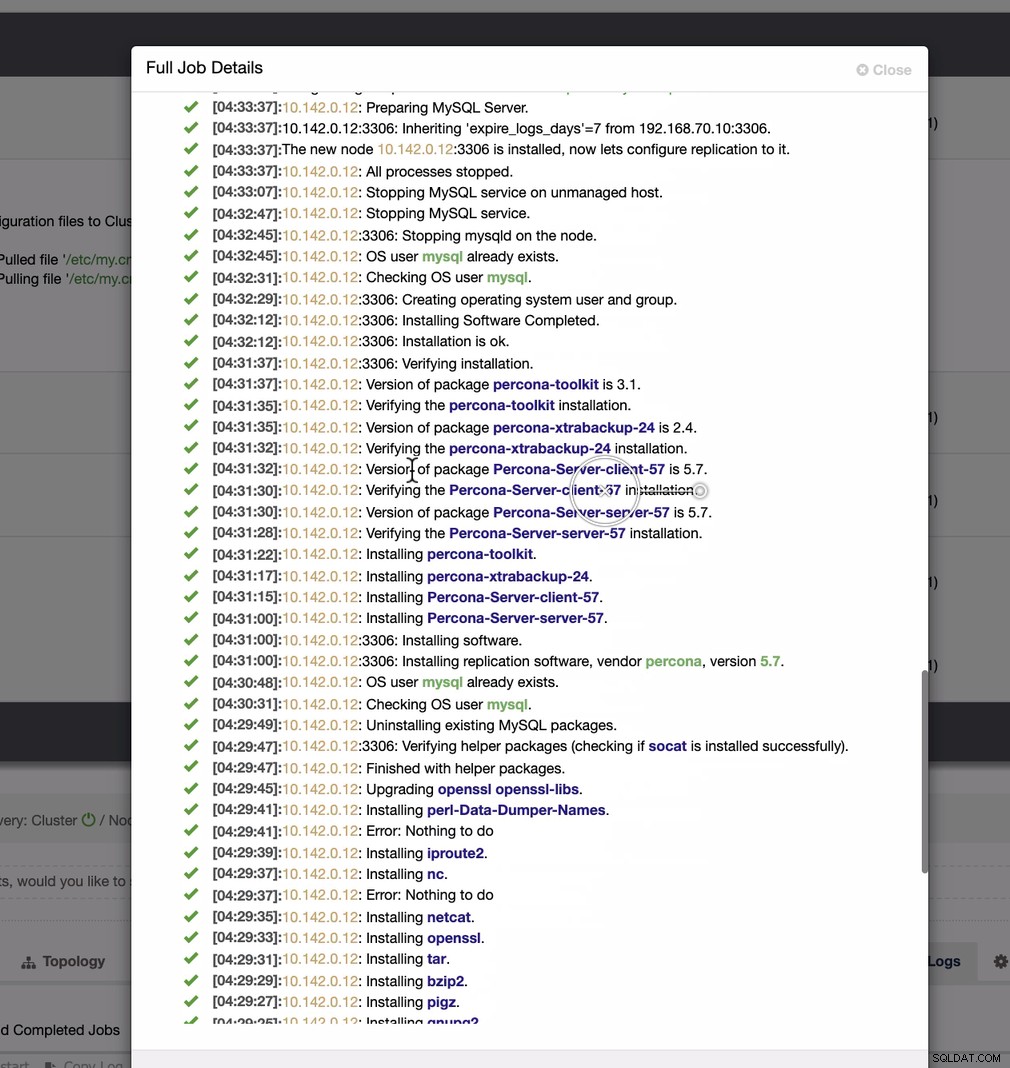
Docela jednoduchý úkol, že?
Dokončete GCP MySQL Cluster
Potřebujeme přidat další dva uzly do clusteru GCP, abychom měli topologii rovnováhy, jako jsme měli v místní síti. U druhého a třetího uzlu se ujistěte, že hlavní uzel musí ukazovat na váš uzel GCP. V tomto příkladu je master 10.142.0.12. Podívejte se níže, jak to udělat,
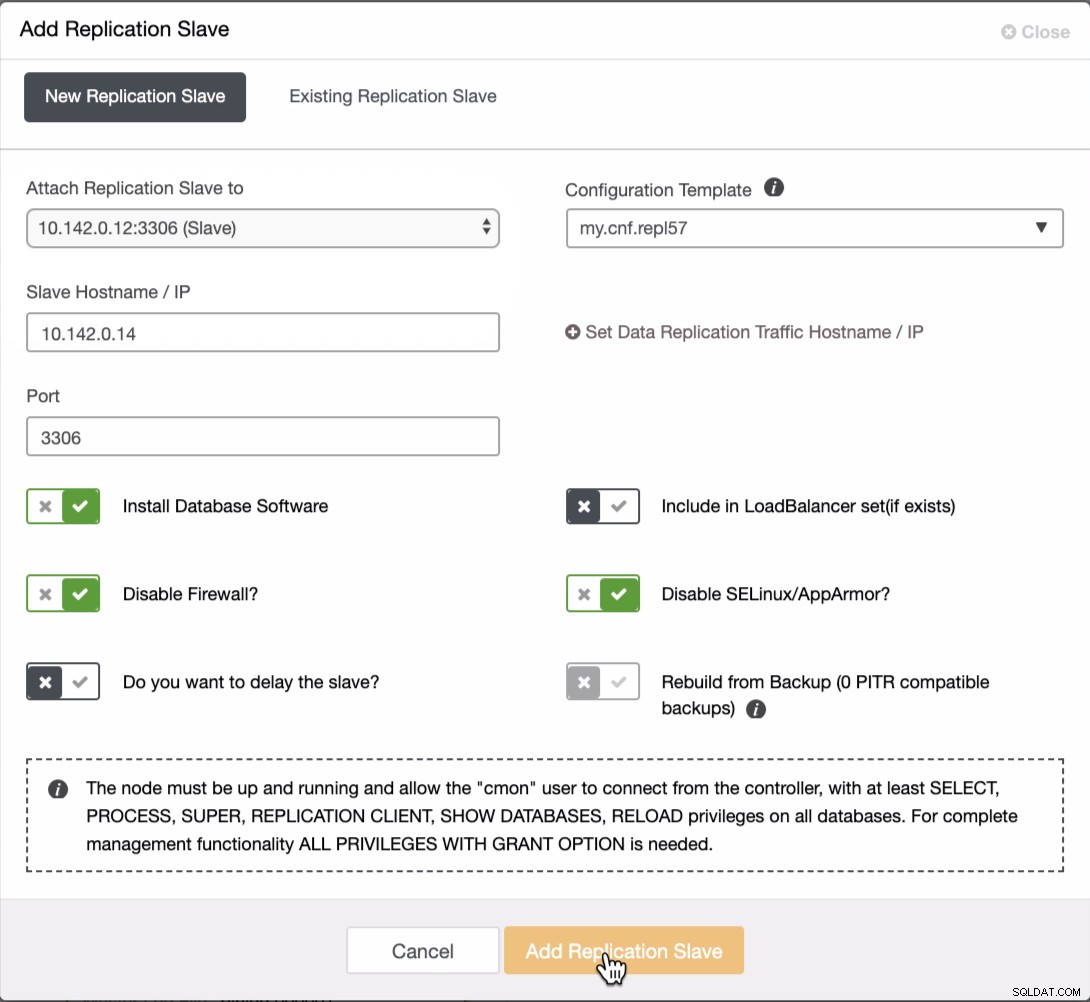
Jak je vidět na snímku obrazovky výše, vybral jsem 10.142.0.12 (slave ), což je první uzel, který jsme přidali do clusteru. Úplný výsledek vypadá následovně,
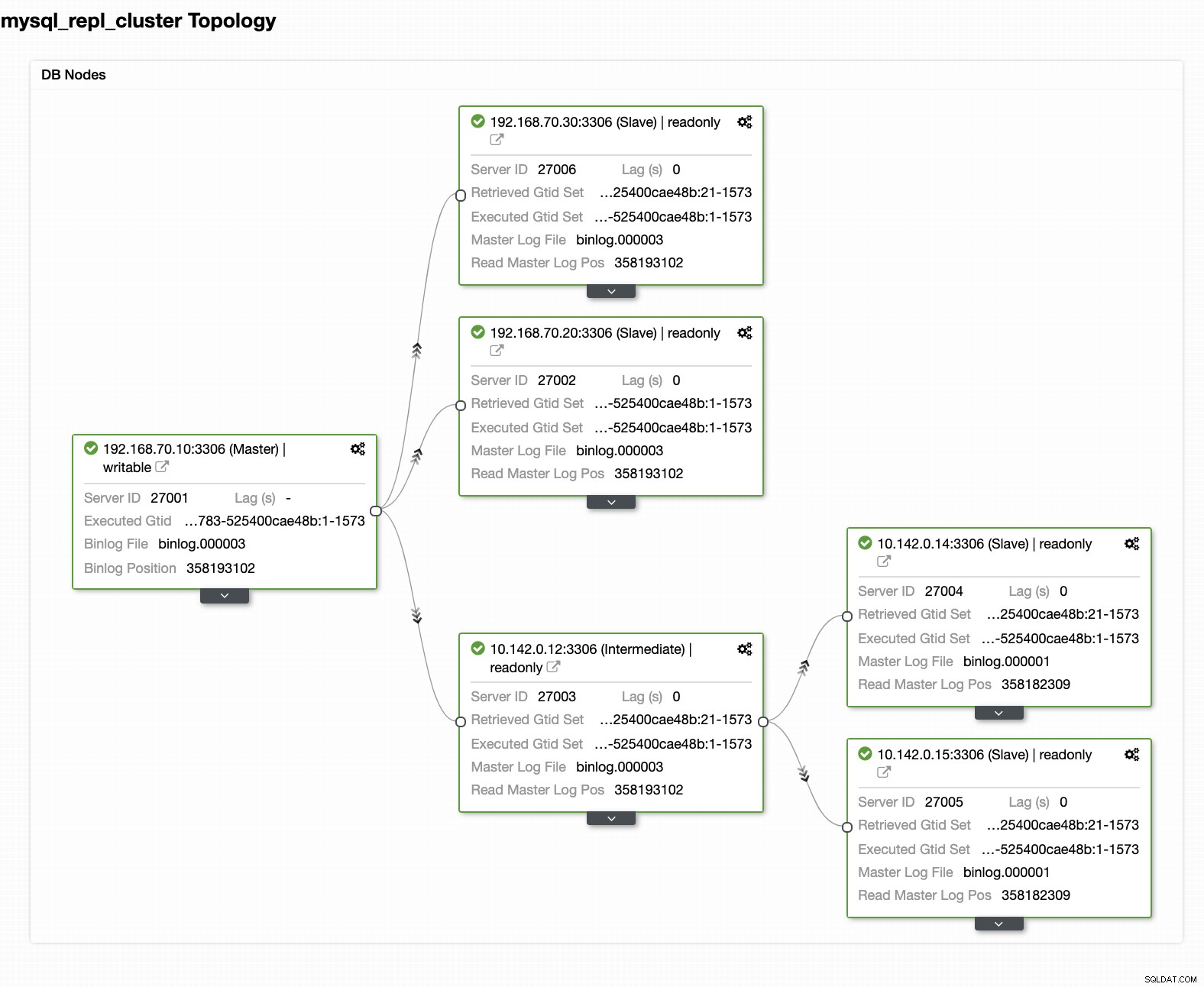
Vaše konečné nastavení clusteru databáze geografických poloh
Podle posledního snímku obrazovky nemusí být tento druh topologie vaším ideálním nastavením. Většinou se musí jednat o multi-master nastavení, kde váš DR cluster slouží jako pohotovostní cluster, kde jako váš on-prem slouží jako primární aktivní cluster. V ClusterControl je to docela jednoduché. Chcete-li tohoto cíle dosáhnout, podívejte se na následující snímky obrazovky.
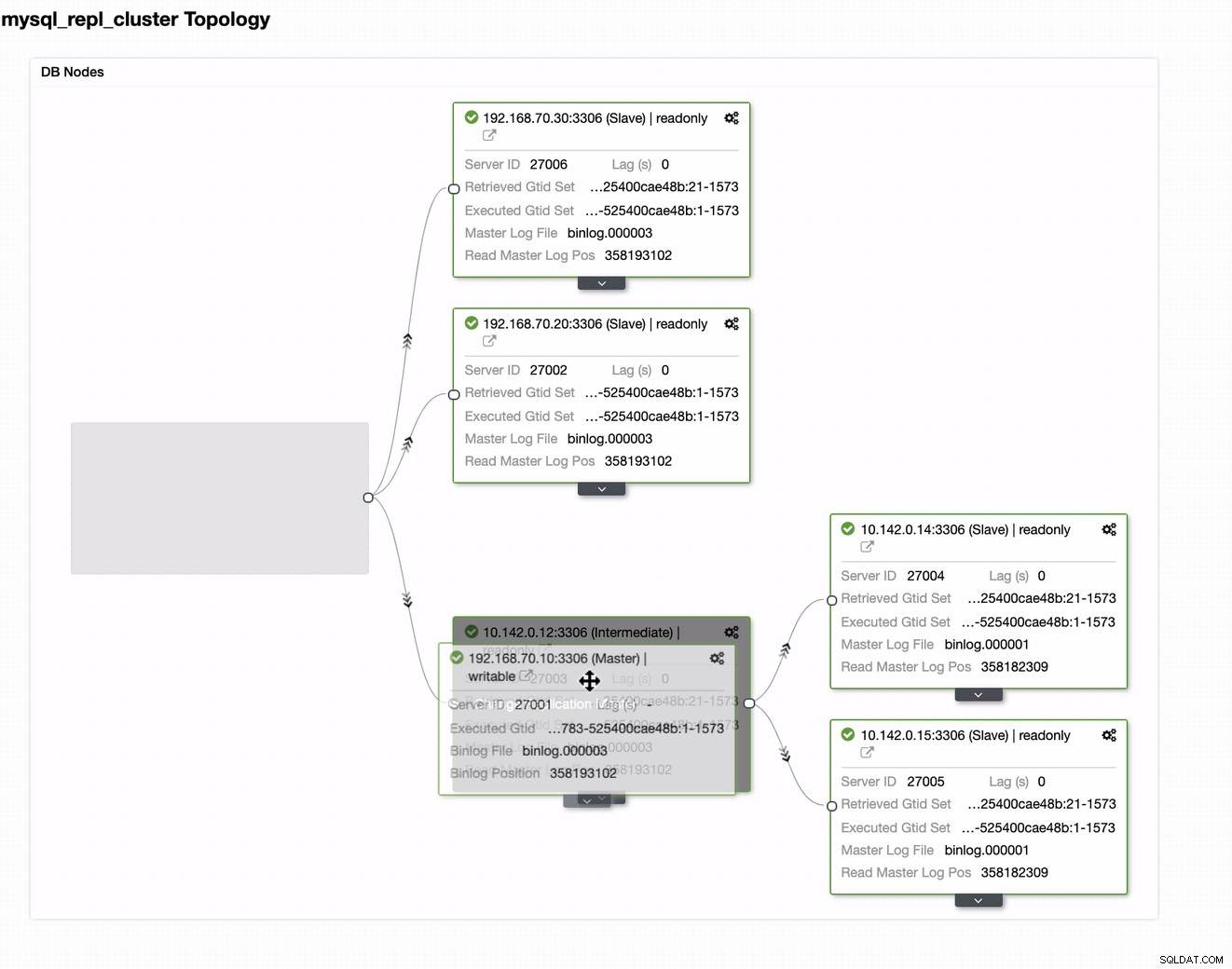
Svou aktuální předlohu můžete jednoduše přetáhnout do cílové předlohy, která musí být nastavit jako primární záložní zapisovač pro případ, že by došlo k poškození vašeho on-prem. V tomto příkladu přetáhneme cílového hostitele 10.142.0.12 (výpočetní uzel GCP). Konečný výsledek je uveden níže:
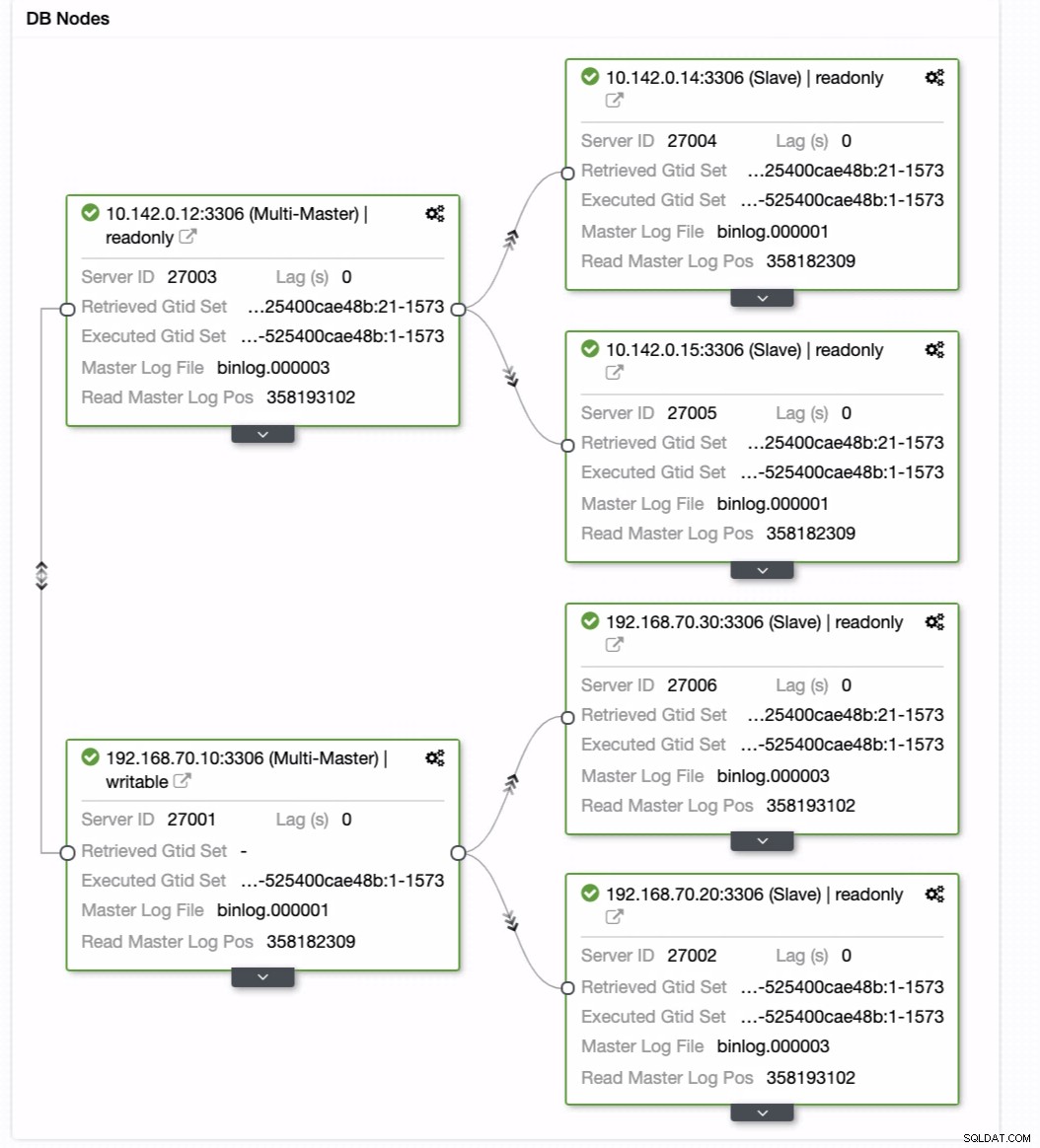
Pak dosáhne požadovaného výsledku. Snadné a velmi rychlé vytvoření clusteru geo-lokační databáze pomocí replikace MySQL.
Závěr
Mít klastr geografické databáze není nic nového. Bylo to požadované nastavení pro společnosti a organizace, které se vyhýbají SPOF, které chtějí odolnost a nižší RPO.
Hlavními přínosy pro toto nastavení jsou bezpečnost, redundance a odolnost. Také popisuje, jak proveditelné a efektivní můžete nasadit svůj nový cluster v jiné geografické oblasti. I když to ClusterControl může nabídnout, očekávejte, že v tomto budeme moci dosáhnout dalšího zlepšení dříve, kde budete moci efektivně vytvářet ze zálohy a vytvářet svůj nový jiný cluster v ClusterControl, takže zůstaňte naladěni.