Spuštění clusteru Galera v hybridním cloudu by se mělo skládat alespoň ze dvou různých geografických lokalit, spojujících hostitele v místním nebo soukromém cloudu s hostiteli ve veřejném cloudu. Ať už používáte nerozbitné soukromé cloudové nebo veřejné cloudové platformy, zotavení po havárii (DR) je skutečně klíčovým problémem. Nejde o zkopírování dat na záložní web a možnost je obnovit, jde o kontinuitu podnikání a o to, jak rychle můžete obnovit služby, když dojde ke katastrofě.
V tomto příspěvku na blogu se podíváme na různé způsoby návrhu vašich Galera Clusters pro odolnost proti chybám v prostředí hybridního cloudu.
Nastavení Active-Active
Cluster Galera by měl běžet s lichým počtem uzlů v clusteru a obvykle začíná se 3 uzly. Je to proto, že Galera Cluster používá kvorum k automatickému určení primární komponenty, kde by většina připojených uzlů měla být schopna obsluhovat cluster najednou, v případě, že by došlo k rozdělení clusteru.
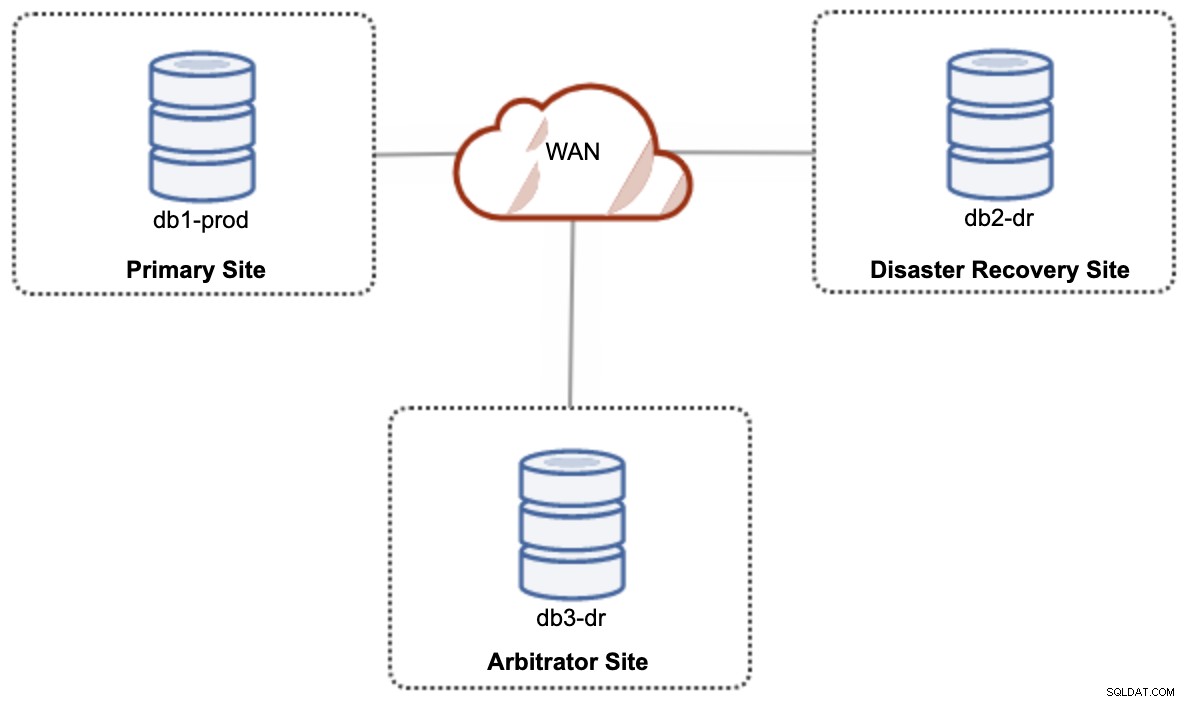
Pro nastavení hybridního cloudu s aktivním a aktivním nastavením vyžaduje Galera alespoň 3 různé weby, které tvoří Galera Cluster napříč WAN. Obecně byste potřebovali třetí místo, které by fungovalo jako rozhodce, hlasovalo pro kvorum a zachovalo „primární složku“, pokud je některá z míst nedostupná. To lze nastavit jako minimálně 3-uzlový cluster na 3 různých webech (1 uzel na web), podobně jako v následujícím diagramu:
Z důvodu výkonu a spolehlivosti se však doporučuje mít 7 -node cluster, jak je znázorněno na následujícím diagramu:
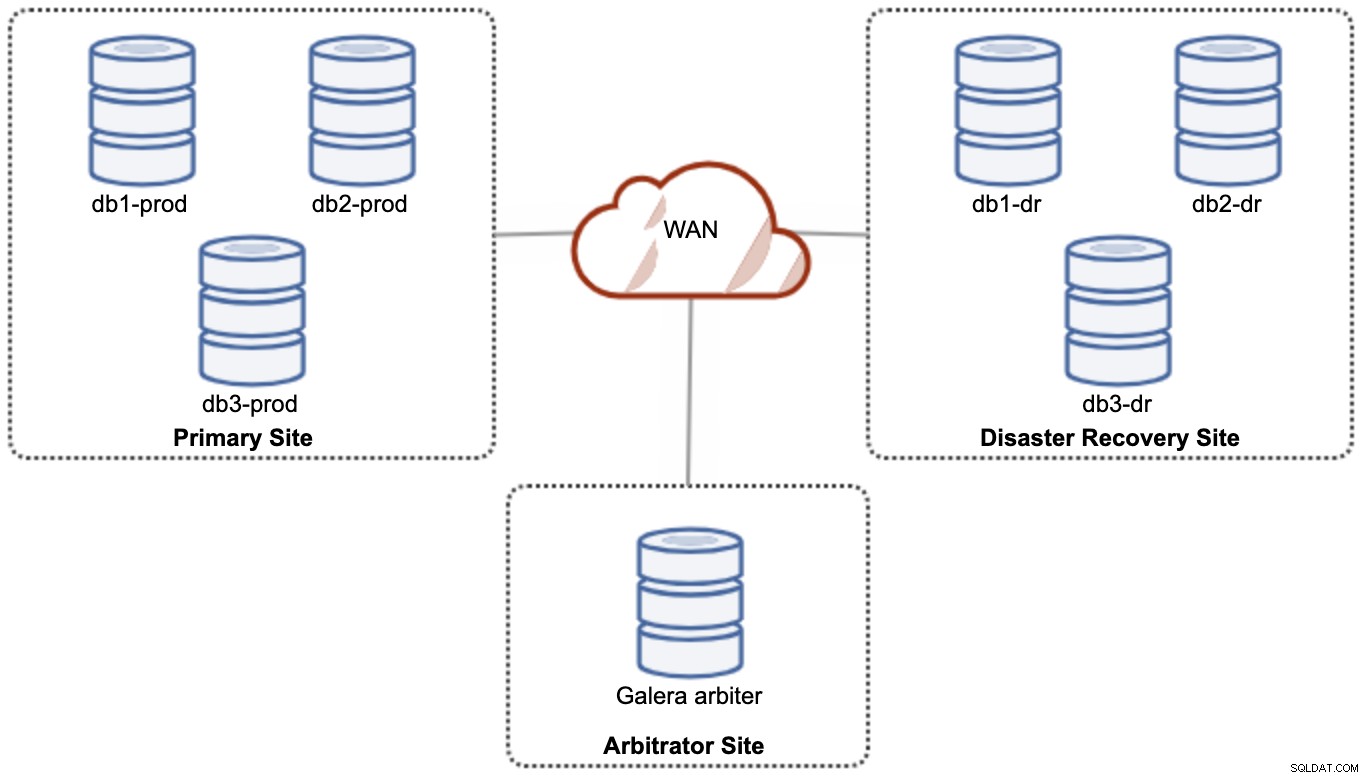
Toto je považováno za nejlepší topologii pro podporu aktivního-aktivního nastavení, kde by měl být web DR dostupný téměř okamžitě, bez jakéhokoli zásahu. Obě místa mohou přijímat čtení/zápis kdykoli za předpokladu, že je cluster v kvoru.
Je však velmi nákladné mít 3 místa a 7 databázových uzlů (7. uzel lze nahradit garbd, protože je velmi nepravděpodobné, že by se používal k poskytování dat klientům/aplikacím). Na začátku projektu to obvykle není oblíbené nasazení kvůli vysokým počátečním nákladům a citlivosti komunikace a replikace skupiny Galera na latenci sítě.
Aktivní-pasivní nastavení
V konfiguraci aktivní-pasivní jsou vyžadovány alespoň 2 weby a současně je aktivní pouze jeden web, známý jako primární web a uzly na sekundárním webu replikují pouze data pocházející z primárního webu server/cluster. Pro Galera Cluster můžeme použít buď asynchronní replikaci MySQL (replikace master-slave), nebo můžeme také použít virtuálně synchronní replikaci Galery s určitým vyladěním, abychom zmírnili replikaci zápisové sady, aby fungovala jako asynchronní replikace.
Sekundární server musí být chráněn proti náhodnému zápisu pomocí příznaku pouze pro čtení, aplikačního firewallu, reverzního proxy nebo jakýchkoli jiných prostředků, protože tok dat vždy přichází z primárního na sekundární server, pokud převzetí služeb při selhání spustilo a povýšilo sekundární server jako primární.
Použití asynchronní replikace
Dobrá věc na asynchronní replikaci je ta, že replikace neovlivňuje zdrojový server/klastr, ale může zaostávat za hlavním serverem. Toto nastavení způsobí, že primární a DR web budou na sobě nezávislé, volně propojené s asynchronní replikací. To lze nastavit jako minimálně 4uzlový cluster na 2 různých místech, podobně jako v následujícím schématu:
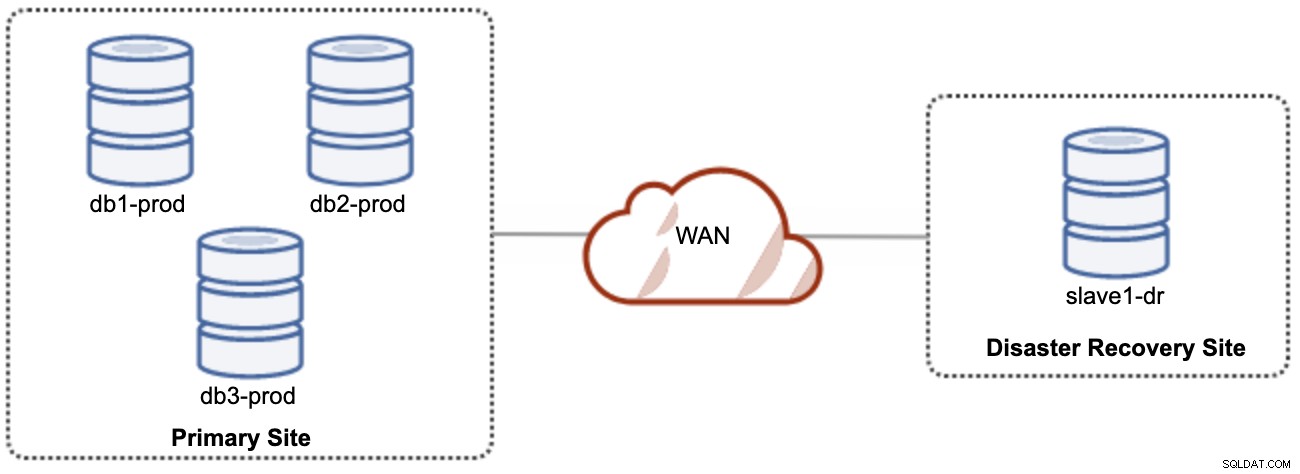
Jeden z uzlů Galera v lokalitě DR bude slave, který se replikuje z jednoho z uzlů Galera (master) v primární lokalitě. Oba weby musí produkovat binární protokoly s GTID a log_slave_updates jsou povoleny – aktualizace pocházející z asynchronního replikačního streamu budou aplikovány na ostatní uzly v clusteru. Pro produkční použití však doporučujeme mít na obou stránkách dvě sady clusterů, jak ukazuje následující diagram:
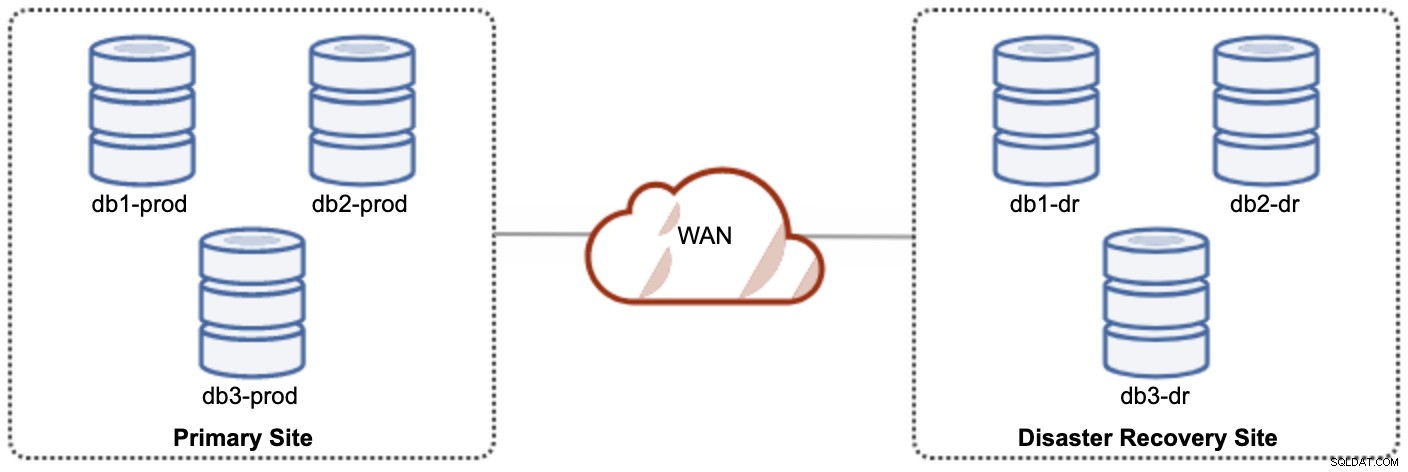
Tím, že budou mít dva samostatné shluky, budou volně spojeny a nebudou se navzájem ovlivňovat, např. Selhání klastru na primární lokalitě neovlivní lokalitu DR. Z hlediska výkonu nebude mít latence WAN vliv na aktualizace v aktivním clusteru. Ty jsou odesílány asynchronně na místo zálohování. Cluster DR by potenciálně mohl běžet na menších instancích v prostředí veřejného cloudu, pokud dokážou držet krok s primárním clusterem. Instance lze v případě potřeby upgradovat. Aplikace by měly odesílat zápisy na primární web a sekundární web musí být nastaven tak, aby běžel v režimu pouze pro čtení. Web pro obnovu po havárii lze použít pro jiné účely, jako je zálohování databáze, zálohování binárních protokolů a vytváření sestav nebo zpracování analytických dotazů (OLAP).
Na druhou stranu existuje možnost ztráty dat během převzetí služeb při selhání/obnovení, pokud se slave zařízení zpožďuje. Proto se doporučuje povolit semisynchronní replikaci, aby se snížilo riziko ztráty dat. Všimněte si, že použití semisynchronní replikace stále neposkytuje silné záruky proti ztrátě dat ve srovnání s virtuálně synchronní replikací Galera. Přečtěte si pozorně tento manuál MySQL, například tyto věty:
"Pokud u semisynchronní replikace dojde k selhání zdroje a dojde k převzetí služeb při selhání do repliky, neměl by být zdroj, který selhal, znovu použit jako zdroj replikace a měl by být zahozen. Může mít transakce, které byly nebyly potvrzeny žádnou replikou, které proto nebyly před převzetím služeb při selhání potvrzeny.“
Proces převzetí služeb při selhání je docela přímočarý. Chcete-li propagovat lokalitu zotavení po havárii, jednoduše vypněte příznak pouze pro čtení a začněte směrovat aplikaci do uzlů databáze v lokalitě DR. Záložní strategie je však trochu ošemetná a vyžaduje určitou odbornost při vytváření dat na obou lokalitách, přepínání role master/slave klastru a přesměrování toku slave replikace opačným způsobem.
Použití replikace Galera
Pro aktivní-pasivní nastavení můžeme umístit většinu uzlů umístěných v primární lokalitě, zatímco menšinu uzlů umístěných v lokalitě obnovy po havárii, jak ukazuje následující snímek obrazovky pro 3- uzel Galera Cluster:
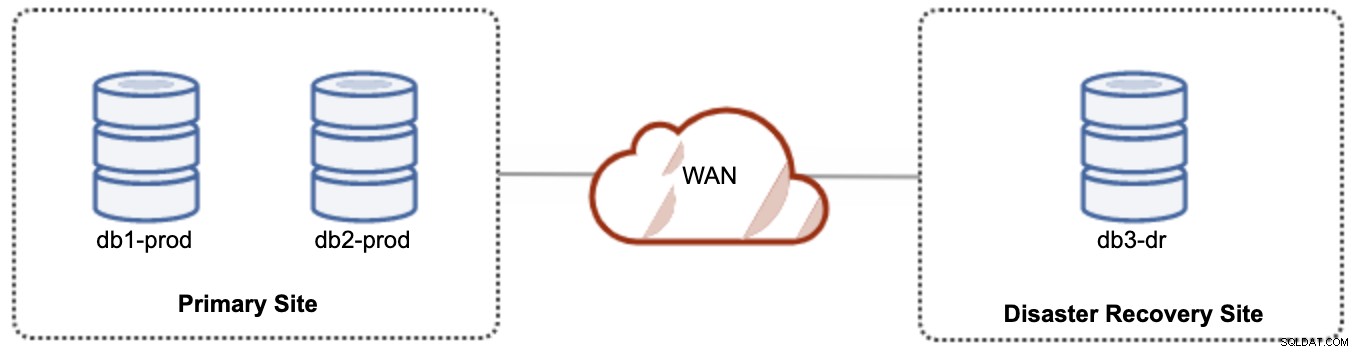
Pokud je primární web mimo provoz, cluster selže, protože je mimo kvorum. Uzel Galera na webu zotavení po havárii (db3-dr) bude nutné zavést ručně jako primární komponentu jediného uzlu. Jakmile se primární lokalita znovu spustí, oba uzly primární lokality (db1-prod a db2-prod) se musí znovu připojit ke galera3, aby se synchronizovaly. Poměrně velká gcache by měla pomoci snížit riziko SST přes WAN. Tuto architekturu lze snadno nastavit a spravovat a je velmi nákladově efektivní.
Failover je manuální, protože administrátor potřebuje povýšit jeden uzel jako primární komponentu (bootstrap db3-dr nebo použijte set pc.bootstrap=1 v parametru wsrep_provider_options. Mezitím by došlo k výpadku . Problémem může být výkon, protože web DR poběží s menším počtem uzlů (protože web DR je vždy v menšině), aby spustil veškerou zátěž. Po přepnutí na DR stránky, ale dejte si pozor na dodatečné zatížení.
Všimněte si, že Galera Cluster je citlivý na síť díky své prakticky synchronní povaze. Čím dále jsou uzly Galera v daném clusteru, tím vyšší je latence a její schopnost zápisu distribuovat a certifikovat sady zápisu. Také pokud připojení není stabilní, může snadno dojít k rozdělení clusteru, což by mohlo spustit synchronizaci clusteru na spojovacích uzlech. V některých případech to může způsobit nestabilitu klastru. To vyžaduje trochu ladění parametrů Galera, jak je ukázáno v tomto blogovém příspěvku, Nasazení hybridního prostředí infrastruktury pro Percona XtraDB Cluster.
Poslední myšlenky
Galera Cluster je skvělá technologie, kterou lze nasadit různými způsoby – jeden cluster natažený na více místech, více clusterů udržovaných v synchronizaci prostřednictvím asynchronní replikace, směs synchronní a asynchronní replikace a tak dále. Skutečné řešení bude diktováno faktory, jako je latence WAN, případná versus silná konzistence dat a rozpočet.