
Úvod k hromadnému shromažďování PL/SQL
Dobře strukturovaný dotaz, napsaný dnes, by vás mohl v budoucnu zachránit před katastrofickými událostmi. Výkon dotazů je něco, co všichni hledáme, ale jen málokdo to skutečně najde. Učení se malých konceptů vám může pomoci získat zkušenosti, které by mohly vést k lepší dovednosti psaní dotazů. Dnes se na tomto blogu naučíte jeden z těch malých pojmů, kterým je „Hromadný sběr “.
Hromadné shromažďování spočívá především v omezení přepínání kontextu a zlepšení výkonu dotazu. Abychom tedy pochopili, co je hromadné shromažďování, musíme se nejprve naučit, co je přepínání kontextu ?
Co je přepínání kontextu?
Kdykoli napíšete PL/SQL blok nebo řeknete PL/SQL program a spustíte jej, runtime modul PL/SQL jej začne zpracovávat řádek po řádku. Tento stroj sám zpracovává všechny příkazy PL/SQL, ale všechny příkazy SQL, které jste zakódovali do tohoto bloku PL/SQL, předává běhovému modulu SQL. Tyto příkazy SQL pak budou zpracovány samostatně modulem SQL. Jakmile je zpracování dokončeno, SQL engine pak vrátí výsledek zpět do PL/SQL motoru. Tak, aby mohl být vytvořen kombinovaný výsledek. Toto přeskakování ovládání se nazývá přepínání kontextu.
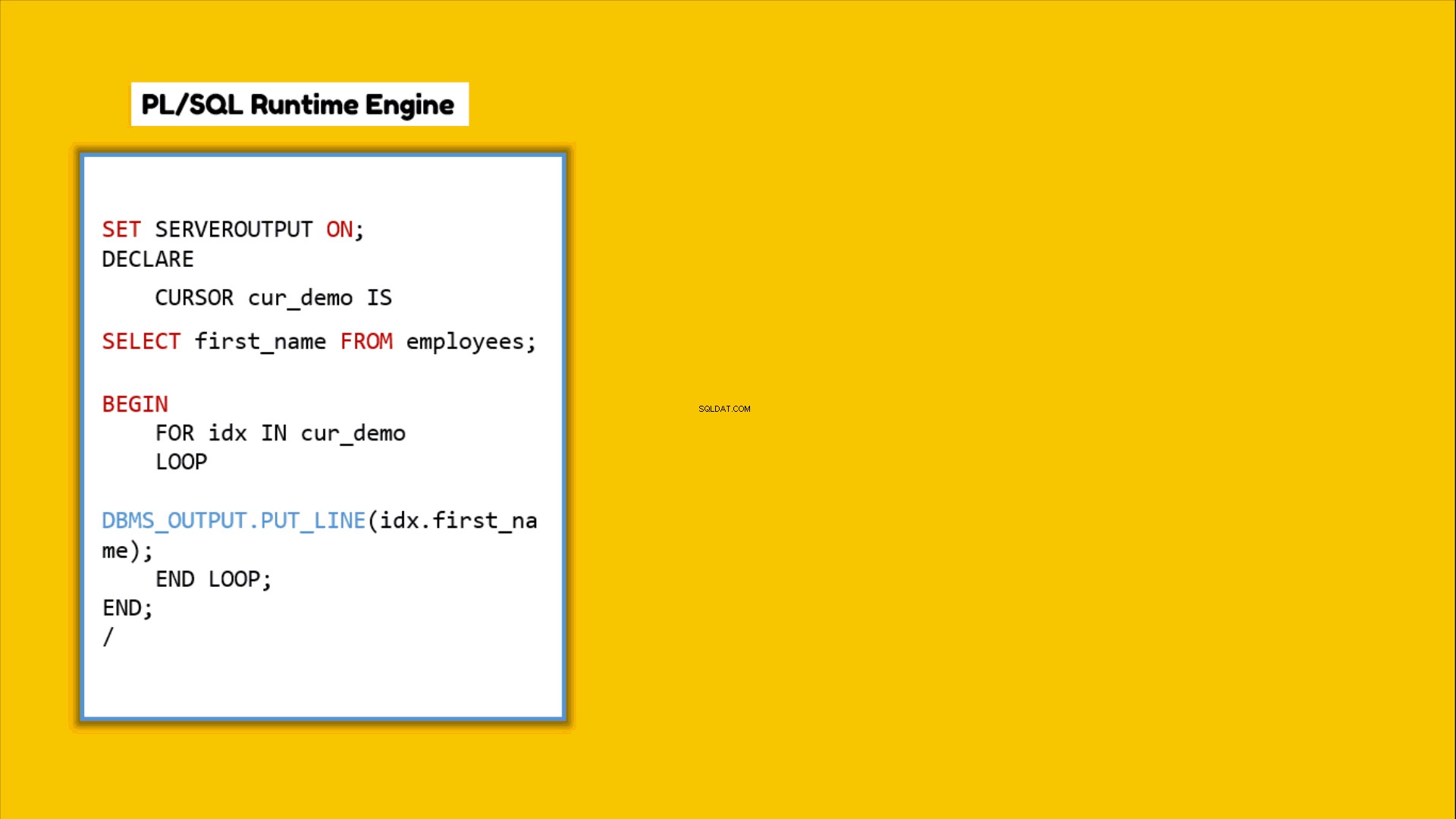
Jak přepínání kontextu ovlivňuje výkon dotazu?
Přepínání kontextu má přímý dopad na výkon dotazu. Čím vyšší je přeskakování ovládacích prvků, tím větší bude režie, která zase sníží výkon. To znamená, že menší přepínání kontextu bude lepší výkon dotazu.
Teď si musíte myslet:"Nemůžeme s tím něco udělat?" Můžeme omezit tyto kontrolní přechody? Existuje nějaký způsob, jak snížit kontextové přepínače? Odpověď na všechny tyto otázky je ano, máme možnost, která nám může pomoci. Tato možnost je klauzule hromadného sběru .
Co je to doložka o hromadném sběru?
Klauzule hromadného sběru komprimuje více přepínačů do jediného kontextového přepínače a zvyšuje efektivitu a výkon programu PL/SQL.
Klauzule hromadného shromažďování omezuje přeskakování vícenásobného ovládání tím, že shromažďuje všechna volání příkazů SQL z programu PL/SQL a odesílá je do SQL Engine jediným pohybem a naopak.
Kde můžeme použít doložku hromadného sběru?
Klauzuli hromadného sběru lze použít s klauzulemi SELECT-INTO, FETCH-INTO a RETURN-INTO.
Pomocí příkazu Bulk Collect můžeme VYBRAT, INSERT, AKTUALIZOVAT nebo VYMAZAT velké soubory dat z databázových objektů, jako jsou tabulky nebo pohledy.
Co je to hromadné zpracování dat?
Proces načítání dávek dat z PL/SQL runtime modulu do SQL motoru a naopak se nazývá hromadné zpracování dat.
Kolik máme výpisů o hromadném zpracování dat?
Máme jednu doložku o hromadném zpracování dat což je Bulk Collect a jeden výpis o hromadném zpracování dat což je FORALL v databázi Oracle.
Slyšel jsem, že klauzule hromadného shromažďování používá implicitní i explicitní kurzory?
Ano, slyšeli jste dobře. Klauzuli Bulk collect můžeme použít buď uvnitř příkazu SQL, nebo s příkazem FETCH. Když používáme klauzuli hromadného sběru s příkazem SQL, tj. SELECT INTO, používá implicitní kurzor. Zatímco pokud použijeme klauzuli hromadného sběru s příkazem FETCH, používá explicitní kurzor.
Toto byl rychlý úvod do první klauzule o hromadném zpracování dat PL/SQL, což je BULK COLLECT. O druhém prohlášení o hromadném zpracování dat se dozvíme, jakmile skončíme s prvním. Mezitím se nezapomeňte přihlásit k odběru našeho kanálu YouTube, protože v příštím tutoriálu se naučíme, jak můžeme zlepšit efektivitu příkazu SQL pomocí klauzule Bulk Collect.
Děkuji a přeji hezký den!