Někdy se stane, že máte ke zpracování velmi velký textový nebo CSV soubor, ale nejprve chcete z tohoto velkého souboru vytvořit menší soubory. Protože zpracování nebo otevření takového velkého souboru může trvat příliš dlouho. Níže tedy uvádím příklad rozdělení velkého textového/CSV souboru do více souborů v PL SQL pomocí uložené procedury.
Této proceduře PL SQL stačí předat dva parametry, první je název objektu adresáře databáze, kde jsou umístěny textové soubory, a druhý je název zdrojového souboru (soubor, který chcete rozdělit).
Pokud pro umístění textových souborů neexistuje objekt adresáře Oracle, můžete jej vytvořit, jak je uvedeno níže:
For windows: CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS 'D:\plsql\text_files';
For Linux/Unix (due to difference in path): CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS '/plsql/text_files';
Změňte výše uvedenou cestu podle umístění vašich souborů. Poté vytvořte níže uvedený postup spuštěním jeho skriptu:
CREATE OR REPLACE PROCEDURE split_file (p_db_dir IN VARCHAR2, p_file_name IN VARCHAR2) IS read_file UTL_FILE.file_type; write_file UTL_FILE.file_type; v_string VARCHAR2 (32767); j NUMBER := 1; BEGIN read_file := UTL_FILE.fopen (p_db_dir, p_file_name, 'r'); WHILE j > 0 LOOP write_file := UTL_FILE.fopen (p_db_dir, j || '_' || p_file_name, 'w'); FOR i IN 1 .. 100 LOOP -- example to dividing into 100 rows for each file.. you can increase the number as per your requirement UTL_FILE.get_line (read_file, v_string); UTL_FILE.put_line (write_file, v_string); END LOOP; UTL_FILE.fclose (write_file); j := J + 1; END LOOP; EXCEPTION WHEN OTHERS THEN -- this will handle if reading source file contents finish UTL_FILE.fclose (read_file); UTL_FILE.fclose (write_file); END;
Tento postup rozdělí 100 řádků pro každý soubor, který můžete upravit podle svých potřeb. Nyní proveďte tento postup, jak je ukázáno níže, zadáním názvu objektu adresáře databáze a názvu souboru:
BEGIN
split_file ('CSV_FILE_DIR', 'text_file.csv');
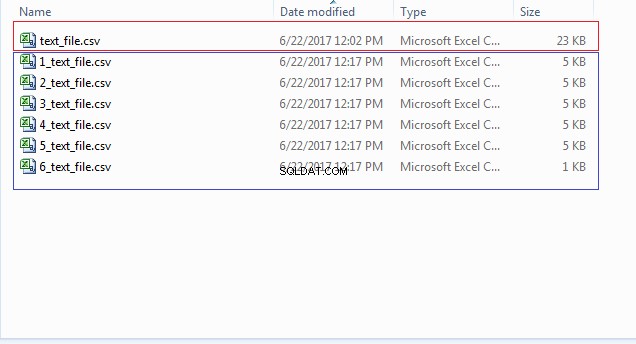
END; Můžete zkontrolovat umístění souboru (CSV_FILE_DIR) pro více souborů začínajících čísly jako 1_text_file.csv, 2_text_file.csv a tak dále, jak je znázorněno na obrázku níže: