Začnu druhou otázkou, která je jednodušší. Pomocí dplyr balíček, můžete použít top_n získat n největších řádků pro daný sloupec. Například:
> top_n(p_ash_r_100a, 3, SMPL_CNT) %>% arrange(desc(SMPL_CNT))
# A tibble: 3 × 5
SMPL_TIME SQL_ID MODULE EVENT SMPL_CNT
<dttm> <chr> <chr> <chr> <int>
1 2017-04-11 09:01:00 NO_SQL GoldenGate CPU 7
2 2017-04-11 09:00:00 dgzp3at57cagd GoldenGate db file sequential read 2
3 2017-04-11 09:01:00 37cspa0acgqxp GoldenGate db file sequential read 2
Všimněte si, že při rovnosti bodů na n-tém místě získáte více než n řádků. Tedy top_n(p_ash_r_100, 10, SMPL_CNT) vrátí celou ukázkovou datovou sadu kvůli 17násobné remíze pro 4. místo.
Co se týče první otázky, dokumentace pro geom_area poskytuje vodítko:
To naznačuje, že geom_area očekává, že sloupec mapovaný na x by měl být číselný. Na základě výpisu pro p_ash_r_100 , SMPL_TIME se jeví jako znakový vektor. Pomocí lubridate balíček, můžeme převést SMPL_TIME na datum-čas pomocí dmy_hm :
p_ash_r_100a <- p_ash_r_100 %>%
mutate_at(vars(SMPL_TIME), dmy_hm)
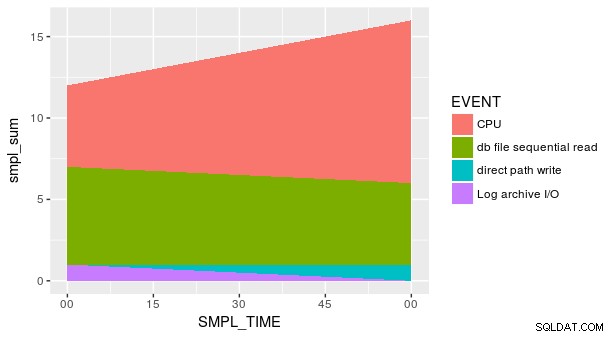
To však nestačí k získání požadovaného grafu, protože existuje více hodnot y pro každou kombinaci x a fill (což je správná estetika pro geom_area , nikoli "col "). Před vykreslením musíme shrnout data:
p_ash_r_100a %>%
group_by(SMPL_TIME, EVENT) %>%
summarise(total = sum(SMPL_CNT)) %>%
ggplot(aes(SMPL_TIME, total, fill = EVENT)) +
geom_area()
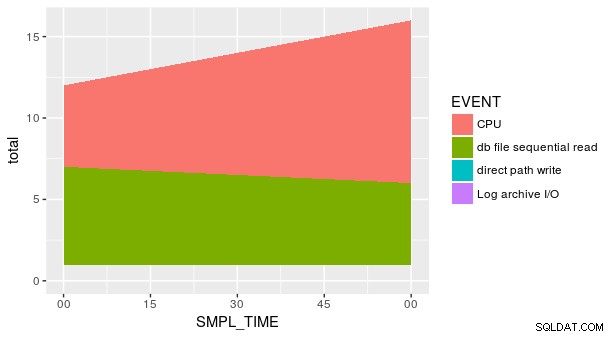
Zápletka však stále není správná. Je to proto, že každá kombinace SMPL_TIME a EVENT není zastoupena v sadě dat. Musíme explicitně sdělit geom_area že y se pro tyto chybějící řádky rovná nule. Jedním ze způsobů je použití praktického fill argument v tidyr::spread .
group_by(p_ash_r_100a, SMPL_TIME, EVENT) %>%
summarise(smpl_sum = sum(SMPL_CNT)) %>%
spread(EVENT, smpl_sum, fill = 0) %>%
gather(EVENT, smpl_sum, CPU, `db file sequential read`,
`direct path write`,
`Log archive I/O`) %>%
ggplot(aes(x = SMPL_TIME, y = smpl_sum, fill = EVENT)) +
geom_area()