Tento příspěvek na blogu je pokračováním předchozí části 1, kde jsme probrali základy integrace SNMP s ClusterControl.
V tomto příspěvku na blogu se zaměříme na SNMP pasti a upozornění. SNMP depeše jsou nejčastěji používané výstražné zprávy zasílané ze vzdáleného zařízení s podporou SNMP (agenta) do centrálního kolektoru, „správce SNMP“. V případě ClusterControl může být past výstrahou poté, co kritický alarm pro cluster není 0, což znamená, že se děje něco špatného.
Jak je uvedeno v předchozím příspěvku na blogu, pro účely tohoto důkazu konceptu máme dvě definice oznámení o depeších SNMP:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }Oznámení (nebo pasti) jsou kritické AlarmNotification a kritické AlarmNotificationEnded. Obě oznamovací události lze použít k signalizaci naší služby Nagios, ať už má cluster aktivně kritické alarmy nebo ne. V Nagios je pro to termín pasivní kontrola, kdy se Nagios nepokouší určit, zda je hostitel/služba NEDOSTUPNÁ nebo NEDOSTUPNÁ. Nakonfigurujeme také aktivní kontroly, kde jsou kontroly iniciovány kontrolní logikou v démonu Nagios pomocí definice služby, která také monitoruje kritické/varovné alarmy hlášené naším clusterem.
Uvědomte si, že tento blogový příspěvek vyžaduje, aby byl MIB a SNMP agent několikanines správně nakonfigurován, jak je uvedeno v první části této blogové série.
Instalace Nagios Core
Nagios Core je bezplatná verze monitorovací sady Nagios. V první řadě jej musíme nainstalovat a všechny potřebné balíčky, následovat pluginy Nagios, snmptrapd a snmptt. Všimněte si, že pokyny v tomto příspěvku na blogu předpokládají, že všechny uzly běží na CentOS 7.
Nainstalujte potřebné balíčky ke spuštění Nagios:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlVytvořte uživatele nagios a skupinu nagcmd pro umožnění provádění externích příkazů prostřednictvím webového rozhraní, přidejte uživatele nagios a apache jako součást skupiny nagcmd:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheStáhněte si nejnovější verzi Nagios Core odtud, zkompilujte ji a nainstalujte:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeNainstalujte webovou konfiguraci Nagios:
$ make install-webconfVolitelně nainstalujte exfoliační motiv Nagios (nebo můžete zůstat u výchozího motivu):
$ make install-exfoliationVytvořte si uživatelský účet (nagiosadmin) pro přihlášení do webového rozhraní Nagios. Zapamatujte si heslo, které jste tomuto uživateli přiřadili:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminRestartujte webový server Apache, aby se nová nastavení projevila:
$ systemctl restart httpd
$ systemctl enable httpdStáhněte si pluginy Nagios odtud, zkompilujte je a nainstalujte:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installOvěřte výchozí konfigurační soubory Nagios:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosOtevřete prohlížeč a přejděte na https://{IPaddress}/nagios a měli byste vidět vyskakovací okno základního ověření HTTP, kde musíte zadat uživatelské jméno jako nagiosadmin s dříve vytvořeným heslem.
Přidání serveru ClusterControl do Nagios
Vytvořte soubor definice hostitele Nagios pro ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgA přidejte následující řádky:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Některá vysvětlení:
-
V první části definujeme našeho hostitele s názvem hostitele a adresou serveru ClusterControl.
-
Sekce služeb, do kterých vkládáme definice služeb, které mají být sledovány Nagios. První dva v podstatě říkají službě, aby zkontrolovala výstup SNMP pro konkrétní ID objektu. První služba se týká kritického poplachu, proto do příkazu check_snmp přidáme -c0, abychom indikovali, že by se mělo jednat o kritický poplach v Nagios, pokud hodnota překročí 0. Zatímco u varovných poplachů jej označíme upozorněním, pokud hodnota je 1 a vyšší.
-
Poslední definice služby se týká depeší SNMP, které bychom očekávali přicházející ze serveru ClusterControl v případě kritického alarmu raise je vyšší než 0. Tato sekce bude používat definici snmp_trap_template, jak je ukázáno v dalším kroku.
Nakonfigurujte šablonu snmp_trap_template přidáním následujících řádků do /usr/local/nagios/etc/objects/templates.cfg:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Zahrňte konfigurační soubor ClusterControl do Nagios přidáním následujícího řádku dovnitř
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgSpusťte předletovou kontrolu konfigurace:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgUjistěte se, že máte na konci výstupu následující řádek:
"Things look okay - No serious problems were detected during the pre-flight check"Restartujte Nagios, aby se změna načetla:
$ systemctl restart nagiosNyní, když se podíváme na stránku Nagios v sekci Služba (levé menu), uvidíme něco takového:
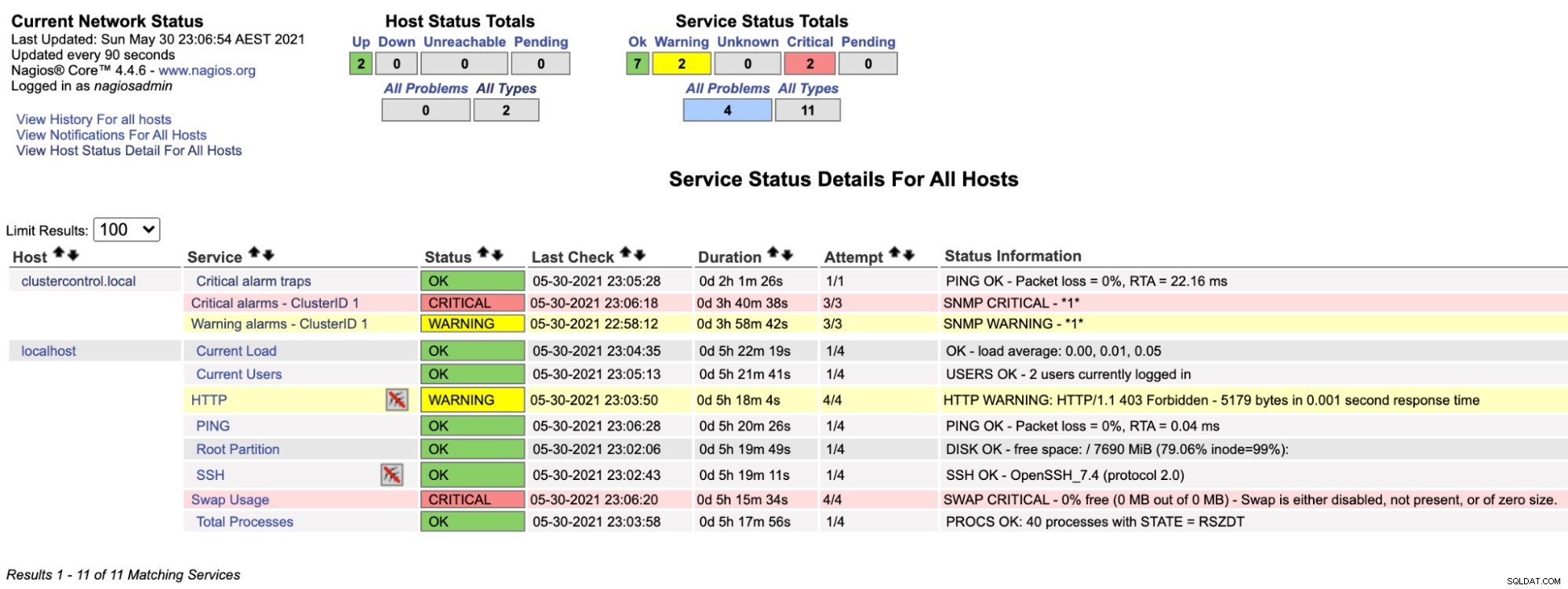
Všimněte si, že řádek "Kritické alarmy - ClusterID 1" zčervená, pokud je kritická hodnota alarmu hlášená ClusterControl větší než 0, zatímco "Výstražné alarmy - ClusterID 1" je žlutý, což znamená, že byl spuštěn varovný alarm. V případě, že se nic zajímavého nestane, uvidíte, že u clustercontrol.local je vše zelené.
Konfigurace Nagios pro příjem pasti
Pasti jsou odesílány vzdálenými zařízeními na server Nagios, nazývá se to pasivní kontrola. V ideálním případě nevíme, kdy bude past odeslána, protože to závisí na tom, zda se vysílající zařízení rozhodne, že past pošle. Například u UPS (záložní baterie), jakmile zařízení ztratí napájení, vyšle past s oznámením "hej, ztratil jsem napájení". Tímto způsobem je Nagios okamžitě informován.
Abychom mohli přijímat depeše SNMP, musíme server Nagios nakonfigurovat pomocí následujících věcí:
-
snmptrapd (démon přijímače depeší SNMP)
-
snmptt (SNMP Trap Translator, démon manipulátoru pastí)
Poté, co snmptrapd přijme past, předá ji snmptt, kde ji nakonfigurujeme tak, aby aktualizovala systém Nagios a poté Nagios odešle výstrahu podle konfigurace skupiny kontaktů.
Nainstalujte úložiště EPEL a poté potřebné balíčky:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogNakonfigurujte démona SNMP trap v /etc/snmp/snmptrapd.conf a nastavte následující řádky:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerVýše uvedené jednoduše znamená, že pasti přijaté démonem snmptrapd budou předány do /usr/sbin/snmptthandler.
Přidejte soubor SEVERALNINES-CLUSTERCONTROL-MIB.txt do /usr/share/snmp/mibs vytvořením /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtVytvořte /etc/snmp/snmp.conf (všimněte si bez „d“) a přidejte tam náš vlastní MIB:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBSpusťte službu snmptrapd:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdDále musíme nakonfigurovat následující konfigurační řádky uvnitř /etc/snmp/snmptt.ini:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDVšimněte si, že jsme povolili modul net_snmp_perl a přidali další konfigurační cestu, /etc/snmp/snmptt-cc.conf do snmptt.ini. Zde musíme definovat události ClusterControl snmptt, aby mohly být předány do Nagios. Vytvořte nový soubor v /etc/snmp/snmptt-cc.conf a přidejte následující řádky:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCNěkterá vysvětlení:
-
Máme definovány dvě pasti – kritické AlarmNotification a kritické AlarmNotificationEnded.
-
Kritické upozornění na alarm jednoduše vyvolá kritické upozornění a předá ho službě „Critical alarm traps“ definované v Nagios. $aA znamená vrátit IP adresu agenta trapu. Hodnota 2 je hodnota výsledku kontroly, která je v tomto případě kritická (0=OK, 1=VAROVÁNÍ, 2=KRITICKÉ, 3=NEZNÁMÉ).
-
Kritický AlarmNotificationEnded jednoduše vyvolá výstrahu OK a předá ji službě „Critical alarm traps“, aby zrušil předchozí past poté, co se vše vrátí do normálu. $aA znamená vrátit IP adresu agenta trapu. Hodnota 0 je výsledná hodnota kontroly, což je v tomto případě v pořádku. Další podrobnosti o substitucích řetězců rozpoznávaných snmptt naleznete v tomto článku v části "FORMÁT".
-
Můžete použít snmpttconvertmib ke generování souboru obsluhy události snmptt pro konkrétní MIB.
Všimněte si, že ve výchozím nastavení není cesta k obslužným rutinám událostí poskytována jádrem Nagios. Proto musíme zkopírovat tento adresář eventhandlers ze zdroje Nagios do adresáře contrib, jak je znázorněno níže:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersMusíme také přiřadit skupinu snmptt jako součást skupiny nagcmd, aby mohla spustit nagios.cmd uvnitř skriptu submit_check_result:
$ usermod -a -G nagcmd snmpttSpusťte službu snmptt:
$ systemctl start snmptt
$ systemctl enable snmpttSprávce SNMP (server Nagios) je nyní připraven přijímat a zpracovávat naše příchozí depeše SNMP.
Odeslání depeše ze serveru ClusterControl
Předpokládejme, že chcete odeslat SNMP trap správci SNMP, 192.168.10.11 (server Nagios), protože celkový počet kritických alarmů dosáhl 2 pro cluster ID 1, spustíte následující příkaz na server ClusterControl (na straně klienta), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Nebo ve formátu OID (doporučeno):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Kde, .1.3.6.1.4.1.57397.1.1.3.1 se rovná události trapu kritického AlarmNotification a následující OID představují celkový počet aktuálních kritických alarmů a ID clusteru, v tomto pořadí .
Na serveru Nagios byste si měli všimnout, že služba trap zčervenala:
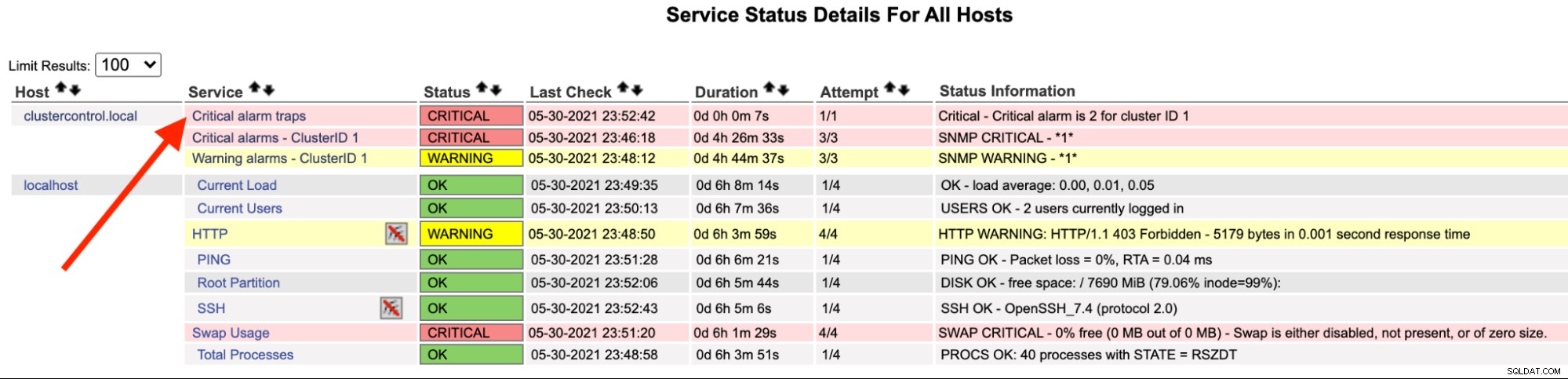
Můžete to také vidět v /var/log/messages na následujícím řádku:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1Po vyřešení alarmu můžeme pro odeslání normální pasti provést následující příkaz:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Kde, .1.3.6.1.4.1.57397.1.1.3.2 se rovná události kritický AlarmNotificationEnded a následující OID představují celkový počet aktuálních kritických alarmů (v tomto případě by měla být 0 ) a ID clusteru.
Na serveru Nagios byste si měli všimnout, že služba trap je opět zelená:
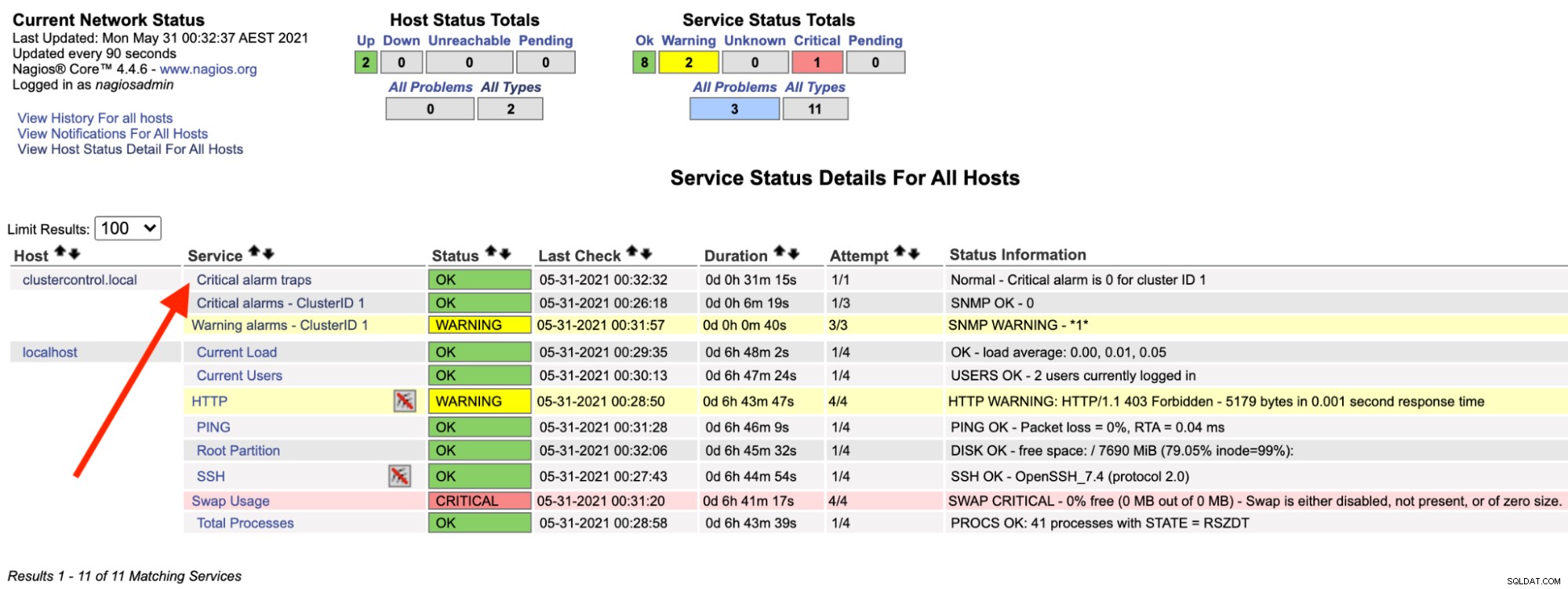
Výše uvedené lze automatizovat pomocí jednoduchého bash skriptu:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
doneChcete-li spustit skript na pozadí, jednoduše proveďte:
$ bash alarmtrapper.bash &V tuto chvíli bychom měli být schopni vidět službu Nagios „Kritické poplachové pasti“ v akci, pokud automaticky dojde k selhání v našem clusteru.
Poslední myšlenky
V této sérii blogů jsme ukázali, jak lze ClusterControl nakonfigurovat pro monitorování, generování/zpracování pastí a upozorňování pomocí protokolu SNMP. To také znamená začátek naší cesty k začlenění SNMP do našich budoucích verzí. Zůstaňte naladěni, protože přineseme další aktualizace této skvělé funkce.