Jedním z největších problémů při práci s databázemi a jejich správě je složitost jejich dat a velikosti. Organizace se často zajímají o to, jak se vypořádat s růstem a řídit dopad růstu, protože správa databází selže. Složitost přichází s obavami, které nebyly původně řešeny a nebyly vidět nebo mohly být přehlédnuty, protože aktuálně používaná technologie by měla být schopna zvládnout sama. Správa komplexní a velké databáze musí být podle toho naplánována, zvláště když se očekává, že typ dat, která spravujete nebo s nimi zacházíte, bude masivně růst, ať už očekávaným nebo nepředvídatelným způsobem. Hlavním cílem plánování je vyhnout se nechtěným katastrofám, nebo řekněme vyhýbat se kouření! V tomto blogu se budeme zabývat tím, jak efektivně spravovat velké databáze.
Na velikosti dat záleží
Na velikosti databáze záleží, protože má dopad na výkon a metodologii její správy. To, jak budou data zpracována a uložena, přispěje k tomu, jak bude databáze spravována, což platí jak pro data v tranzitu, tak pro data v klidu. Pro mnoho velkých organizací jsou data zlatem a růst dat by mohl mít drastickou změnu v procesu. Proto je důležité mít předem plány na zpracování rostoucích dat v databázi.
Ve své zkušenosti s prací s databázemi jsem byl svědkem toho, že zákazníci měli problémy s penalizací za výkon a správou extrémního nárůstu dat. Vyvstávají otázky, zda normalizovat tabulky vs. denormalizace tabulek.
Normalizace tabulek
Normalizace tabulek zachovává integritu dat, snižuje redundanci a usnadňuje organizaci dat do efektivnějšího způsobu správy, analýzy a extrahování. Práce s normalizovanými tabulkami přináší efektivitu, zejména při analýze toku dat a získávání dat buď pomocí příkazů SQL, nebo při práci s programovacími jazyky, jako jsou rozhraní C/C++, Java, Go, Ruby, PHP nebo Python s konektory MySQL.
Přestože problémy s normalizovanými tabulkami mají omezení výkonu a mohou zpomalit dotazy kvůli sérii spojení při načítání dat. Zatímco denormalizované tabulky, vše, co musíte vzít v úvahu pro optimalizaci, závisí na indexu nebo primárním klíči pro ukládání dat do vyrovnávací paměti pro rychlejší načítání než při provádění vyhledávání více disků. Denormalizované tabulky nevyžadují žádná spojení, ale obětují integritu dat a velikost databáze má tendenci se zvětšovat a zvětšovat.
Pokud je vaše databáze velká, zvažte použití DDL (Data Definition Language) pro vaši databázovou tabulku v MySQL/MariaDB. Přidání primárního nebo jedinečného klíče pro vaši tabulku vyžaduje opětovné sestavení tabulky. Změna datového typu sloupce také vyžaduje opětovné sestavení tabulky, protože použitelný algoritmus je pouze ALGORITHM=COPY.
Pokud to děláte ve svém produkčním prostředí, může to být náročné. Zdvojnásobte výzvu, pokud je váš stůl obrovský. Představte si milion nebo miliardu čísel řádků. Příkaz ALTER TABLE nemůžete použít přímo na vaši tabulku. To může zablokovat veškerý příchozí provoz, který musí mít přístup k tabulce, ve které aktuálně aplikujete DDL. To však lze zmírnit pomocí pt-online-schema-change nebo skvělého gh-ost. Nicméně vyžaduje monitorování a údržbu při provádění procesu DDL.
Sharding a rozdělení
Díky sdílení a rozdělení pomáhá segregovat nebo segmentovat data podle jejich logické identity. Například segregací na základě data, abecedního pořadí, země, státu nebo primárního klíče na základě daného rozsahu. To pomáhá spravovat velikost vaší databáze. Udržujte velikost databáze až na její hranici, aby ji mohla spravovat vaše organizace a váš tým. V případě potřeby lze snadno škálovat nebo snadno spravovat, zvláště když dojde ke katastrofě.
Když říkáme zvládnutelné, vezměte v úvahu také kapacitní zdroje vašeho serveru a také vašeho inženýrského týmu. Nemůžete pracovat s velkými a velkými daty s několika inženýry. Práce s velkými daty, jako je 1000 databází s velkým množstvím datových sad, vyžaduje obrovskou časovou náročnost. Zručnost a odbornost jsou nutností. Pokud jsou náklady problémem, je to čas, kdy můžete využít služeb třetích stran, které nabízejí spravované služby nebo placené konzultace či podporu pro jakékoli takové inženýrské práce, které mají být zajištěny.
Znakové sady a řazení
Znakové sady a řazení ovlivňují ukládání a výkon dat, zejména u dané znakové sady a vybraných řazení. Každá znaková sada a řazení má svůj účel a většinou vyžaduje různé délky. Pokud máte tabulky vyžadující jiné znakové sady a řazení kvůli kódování znaků, data, která mají být uložena a zpracována pro vaši databázi a tabulky, nebo dokonce se sloupci.
To má vliv na efektivní správu databáze. Ovlivňuje vaše úložiště dat a také výkon, jak bylo uvedeno výše. Pokud jste pochopili, jaké druhy znaků má vaše aplikace zpracovávat, poznamenejte si znakovou sadu a řazení, které se mají použít. Sady znaků typu LATIN postačí většinou pro alfanumerický typ znaků, které se mají ukládat a zpracovávat.
Pokud je to nevyhnutelné, sharding a dělení pomáhá alespoň zmírnit a omezit data, aby nedošlo k nafouknutí příliš velkého množství dat na vašem databázovém serveru. Správa velmi velkých dat na jediném databázovém serveru může ovlivnit efektivitu, zejména pro účely zálohování, havárie a obnovy nebo obnovy dat v případě poškození nebo ztráty dat.
Složitost databáze ovlivňuje výkon
Velká a složitá databáze má tendenci mít vliv na snížení výkonu. Komplexní v tomto případě znamená, že obsah vaší databáze tvoří matematické rovnice, souřadnice nebo číselné a finanční záznamy. Nyní tyto záznamy smíchejte s dotazy, které agresivně používají matematické funkce nativní v jeho databázi. Podívejte se na příklad dotazu SQL (kompatibilní s MySQL/MariaDB) níže,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Předpokládejme, že tento dotaz je aplikován na tabulku v rozsahu od milionu řádků. Existuje obrovská možnost, že to může zastavit server a mohlo by to být náročné na zdroje, což by mohlo ohrozit stabilitu vašeho produkčního databázového clusteru. Zapojené sloupce mají tendenci být indexovány, aby se optimalizoval a aby byl tento dotaz výkonný. Přidání indexů do odkazovaných sloupců pro optimální výkon však nezaručuje efektivitu správy vašich velkých databází.
Při řešení složitosti je efektivnější vyhnout se přísnému používání složitých matematických rovnic a agresivnímu používání této vestavěné komplexní výpočetní schopnosti. To lze provozovat a přenášet prostřednictvím složitých výpočtů pomocí backendových programovacích jazyků namísto použití databáze. Pokud máte složité výpočty, tak proč neukládat tyto rovnice do databáze, nenačítat dotazy, uspořádat je do snazšího analyzování nebo ladění v případě potřeby.
Používáte správný databázový stroj?
Datová struktura ovlivňuje výkon databázového serveru na základě kombinace zadaného dotazu a záznamů, které jsou čteny nebo načítány z tabulky. Databázové stroje v rámci MySQL/MariaDB podporují InnoDB a MyISAM, které používají B-stromy, zatímco databázové stroje NDB nebo Memory používají Hash Mapping. Tyto datové struktury mají svůj asymptotický zápis, který vyjadřuje výkon algoritmů používaných těmito datovými strukturami. V informatice je nazýváme notací velkého O, která popisuje výkon nebo složitost algoritmu. Vzhledem k tomu, že InnoDB a MyISAM používají B-Stromy, používá pro vyhledávání O(log n). Zatímco hash tabulky nebo hash mapy používají O(n). Oba sdílejí průměrný a nejhorší případ pro jeho výkon s jeho notací.
Nyní zpět ke konkrétnímu stroji, vzhledem k datové struktuře stroje, dotaz, který má být aplikován na základě cílových dat, která mají být načtena, samozřejmě ovlivňuje výkon vašeho databázového serveru. Hashovací tabulky nedokážou získat rozsah, zatímco B-Stromy jsou velmi efektivní pro provádění těchto typů vyhledávání a také si poradí s velkým množstvím dat.
Pomocí správného nástroje pro data, která ukládáte, musíte určit, jaký typ dotazu použijete pro tato konkrétní data, která ukládáte. Jaký typ logiky mají tato data formulovat, když se transformují na obchodní logiku.
Zacházení s 1000 nebo tisíci databázemi, používání správného nástroje v kombinaci vašich dotazů a dat, která chcete načíst a uložit, bude poskytovat dobrý výkon. Vzhledem k tomu, že jste předem určili a analyzovali své požadavky pro jeho účel pro správné databázové prostředí.
Správné nástroje pro správu velkých databází
Je velmi těžké a obtížné spravovat velmi rozsáhlou databázi bez pevné platformy, na kterou se můžete spolehnout. I s dobrými a zkušenými databázovými inženýry je technicky databázový server, který používáte, náchylný k lidské chybě. Jedna chyba jakékoli změny vašich konfiguračních parametrů a proměnných může mít za následek drastickou změnu, která způsobí snížení výkonu serveru.
Provedení zálohy do databáze na velmi velké databázi může být občas náročné. Existují případy, kdy zálohování může selhat z nějakých podivných důvodů. Dotazy, které by mohly zastavit server, na kterém běží záloha, obvykle způsobí selhání. V opačném případě musíte prozkoumat příčinu.
Použití automatizace, jako je Chef, Puppet, Ansible, Terraform nebo SaltStack, může být použito jako váš IaC k poskytování rychlejších úkolů. Při používání dalších nástrojů třetích stran, které vám pomohou při sledování a poskytování vysoce kvalitních obrázků grafů. Výstražné a výstražné systémy jsou také velmi důležité, aby vás upozornily na problémy, které mohou nastat od varování až po úroveň kritického stavu. Zde je ClusterControl v této situaci velmi užitečný.
ClusterControl nabízí snadnou správu velkého počtu databází nebo dokonce i sdílených typů prostředí. Byl tisíckrát testován a instalován a byl spuštěn ve výrobě poskytující alarmy a upozornění správcům databází, inženýrům nebo DevOps provozujícím databázové prostředí. Od fáze nebo vývoje, QA až po produkční prostředí.
ClusterControl může také provádět zálohování a obnovení. I u velkých databází může být efektivní a snadno se spravuje, protože uživatelské rozhraní poskytuje plánování a má také možnosti nahrát jej do cloudu (AWS, Google Cloud a Azure).
K dispozici je také ověření zálohy a spousta možností, jako je šifrování a komprese. Podívejte se například na snímek obrazovky níže (vytvoření zálohy pro MySQL pomocí Xtrabackup):
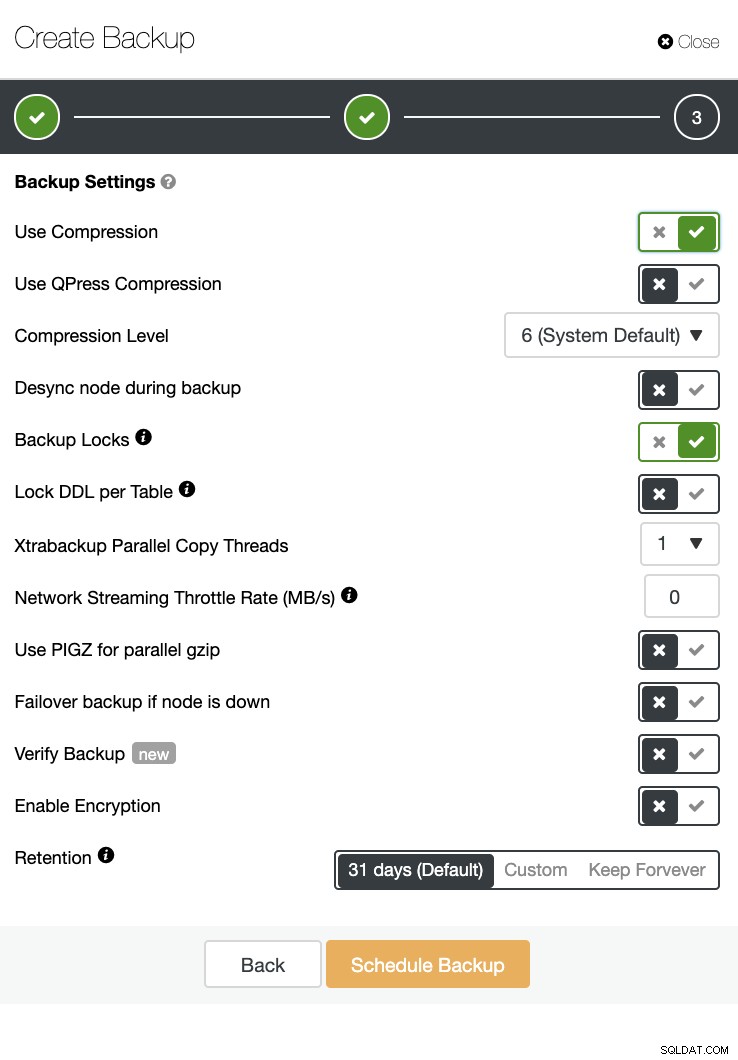
Závěr
Správu velkých databází, jako je tisíc nebo více, lze efektivně provádět, ale musí být stanovena a připravena předem. Použití správných nástrojů, jako je automatizace nebo dokonce předplatné spravovaných služeb, výrazně pomáhá. I když to vyžaduje náklady, obrat ve službách a rozpočet, který je třeba vynaložit na získání kvalifikovaných inženýrů, lze snížit, pokud jsou k dispozici správné nástroje.