Co je indexování?
Indexování je důležitý pojem ve světě databází. Hlavní výhodou vytváření indexu na libovolné pole je rychlejší přístup k datům. Optimalizuje proces vyhledávání a přístupu k databázi. Abyste tomu porozuměli, zvažte tento příklad.
Když jakýkoli uživatel požádá o konkrétní řádek z databáze, co udělá DB systém? Začne od prvního řádku a zkontroluje, zda je to řádek, který uživatel chce? Pokud ano, vraťte tento řádek, jinak pokračujte v hledání řádku až do konce.
Obecně platí, že když definujete index pro určité pole, systém DB vytvoří uspořádaný seznam hodnot tohoto pole a uloží jej do jiné tabulky. Každý záznam v této tabulce bude ukazovat na odpovídající hodnoty v původní tabulce. Když se tedy uživatel pokusí vyhledat libovolný řádek, nejprve vyhledá hodnotu v indexové tabulce pomocí binárního vyhledávacího algoritmu a vrátí odpovídající hodnotu z původní tabulky. Tento proces zabere méně času, protože místo lineárního vyhledávání používáme binární vyhledávání.
V tomto článku se zaměříme na indexování MongoDB a pochopíme, jak vytvářet a používat indexy v MongoDB.
Jak vytvořit index v kolekci MongoDB?
Chcete-li vytvořit index pomocí prostředí Mongo, můžete použít tuto syntaxi:
db.collection.createIndex( <key and index type specification>, <options> )Příklad:
Chcete-li vytvořit index v poli názvu v kolekci myColl:
db.myColl.createIndex( { name: -1 } )Typy indexů MongoDB
-
Výchozí index _id
Toto je výchozí index, který vytvoří MongoDB, když vytvoříte novou kolekci. Pokud pro toto pole neurčíte žádnou hodnotu, bude _id ve výchozím nastavení pro vaši sbírku primárním klíčem, takže uživatel nemůže vložit dva dokumenty se stejnými hodnotami pole _id. Tento index nelze z pole _id odstranit.
-
Index jednoho pole
Tento typ indexu můžete použít, když chcete vytvořit nový index v jakémkoli jiném poli než pole _id.
Příklad:
db.myColl.createIndex( { name: 1 } )Tím se vytvoří jeden vzestupný index klíče v poli názvu v kolekci myColl
-
Složený index
Můžete také vytvořit index pro více polí pomocí složených indexů. U tohoto indexu záleží na pořadí polí, ve kterých jsou v indexu definovány. Zvažte tento příklad:
db.myColl.createIndex({ name: 1, score: -1 })Tento index nejprve seřadí kolekci podle názvu ve vzestupném pořadí a poté pro každou hodnotu názvu seřadí podle hodnot skóre v sestupném pořadí.
-
Index více klíčů
Tento index lze použít k indexování dat pole. Pokud má nějaké pole v kolekci jako hodnotu pole, můžete použít tento index, který vytvoří samostatné položky indexu pro každý prvek v poli. Pokud je indexovaným polem pole, MongoDB na něm automaticky vytvoří Multikey index.
Zvažte tento příklad:
{ ‘userid’: 1, ‘name’: ‘mongo’, ‘addr’: [ {zip: 12345, ...}, {zip: 34567, ...} ] }Můžete vytvořit víceklíčový index v poli addr zadáním tohoto příkazu v prostředí Mongo.
db.myColl.createIndex({ addr.zip: 1 }) -
Geoprostorový index
Předpokládejme, že jste uložili nějaké souřadnice do kolekce MongoDB. Chcete-li vytvořit index pro pole tohoto typu (která obsahuje geoprostorová data), můžete použít geoprostorový index. MongoDB podporuje dva typy geoprostorových indexů.
-
2D Index:Tento index můžete použít pro data, která jsou uložena jako body na 2D rovině.
db.collection.createIndex( { <location field> : "2d" } ) -
Index 2dsphere:Tento index použijte, když jsou vaše data uložena ve formátu GeoJson nebo v párech souřadnic (zeměpisná délka, zeměpisná šířka)
db.collection.createIndex( { <location field> : "2dsphere" } ) -
-
Textový index
Pro podporu dotazů, které zahrnují hledání nějakého textu v kolekci, můžete použít Text index.
Příklad:
db.myColl.createIndex( { address: "text" } ) -
Hašovaný index
MongoDB podporuje sharding na bázi hash. Hašovaný index počítá hash hodnot indexovaného pole. Hašovaný index podporuje sharding pomocí hašovaných sdílených klíčů. Hašované sdílení používá tento index jako fragmentový klíč k rozdělení dat v rámci vašeho clusteru.
Příklad:
db.myColl.createIndex( { _id: "hashed" } )
-
Jedinečný index
Tato vlastnost zajišťuje, že v indexovaném poli nejsou žádné duplicitní hodnoty. Pokud jsou při vytváření indexu nalezeny nějaké duplikáty, tyto položky se zahodí.
-
Řídký index
Tato vlastnost zajišťuje, že všechny dotazy vyhledávají dokumenty s indexovaným polem. Pokud některý dokument nemá indexované pole, bude vyřazen ze sady výsledků.
-
Index TTL
Tento index se používá k automatickému odstranění dokumentů z kolekce po určitém časovém intervalu (TTL) . To je ideální pro odstraňování dokumentů protokolů událostí nebo uživatelských relací.
Analýza výkonu
Zvažte sbírku studentských skóre. Obsahuje přesně 3000000 dokumentů. V této kolekci jsme nevytvořili žádné indexy. Podívejte se na tento obrázek níže, abyste pochopili schéma.
 Ukázky dokumentů ve sbírce skóre
Ukázky dokumentů ve sbírce skóre Nyní zvažte tento dotaz bez jakýchkoli indexů:
db.scores.find({ student: 585534 }).explain("executionStats")Provedení tohoto dotazu trvá 1155 ms. Zde je výstup. Pro výsledek vyhledejte pole executeTimeMillis.
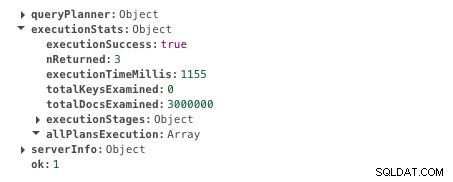 Doba provedení bez indexování
Doba provedení bez indexování Nyní vytvoříme index na studentském poli. Chcete-li vytvořit index, spusťte tento dotaz.
db.scores.createIndex({ student: 1 })Nyní stejný dotaz trvá 0 ms.
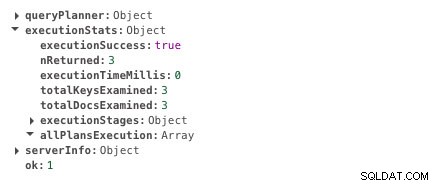 Doba provedení s indexováním
Doba provedení s indexováním Můžete jasně vidět rozdíl v době provádění. Je to téměř okamžité. V tom je síla indexování.
Závěr
Jedno zřejmé řešení je:Vytvářejte indexy. Na základě vašich dotazů můžete ve svých kolekcích definovat různé typy indexů. Pokud nevytvoříte indexy, pak každý dotaz prohledá celé kolekce, což zabere spoustu času, takže vaše aplikace bude velmi pomalá a využívá spoustu zdrojů vašeho serveru. Na druhou stranu nevytvářejte příliš mnoho indexů, protože vytváření zbytečných indexů způsobí další časovou režii pro veškeré vkládání, mazání a aktualizace. Když provádíte kteroukoli z těchto operací na indexovaném poli, musíte stejnou operaci provést také na indexovém stromu, což vyžaduje čas. Indexy jsou uloženy v paměti RAM, takže vytváření irelevantních indexů může zabrat místo v paměti RAM a zpomalit váš server.