SCUMM (Severalnines ClusterControl Unified Monitoring &Management) je řešení založené na agentech s agenty nainstalovanými na uzlech databáze. Poskytuje sadu monitorovacích panelů, které mají jako úložiště dat Prometheus s elastickým dotazovacím jazykem a vícerozměrným datovým modelem. Prometheus sbírá data metrik z exportérů běžících na hostitelích databáze.
Architektura ClusterControl SCUMM byla představena ve verzi 1.7.0 rozšiřující funkce monitorování pro MySQL, Galera Cluster, PostgreSQL a ProxySQL.
Nový ClusterControl 1.7.1 přidává monitorování ve vysokém rozlišení pro systémy MongoDB.
 Seznam řídicího panelu ClusterControl MongoDB
Seznam řídicího panelu ClusterControl MongoDB V tomto článku popíšeme dva hlavní dashboardy pro prostředí MongoDB. MongoDB Server a MongoDB Replicaset.
Panel a seznam metrik
Seznam panelů a jejich metrik:
| Server MongoDB | |
|---|---|
| Název ReplSet Name Doba provozu serveru OpsCounters Připojení WT – Souběžné vstupenky (čtení) WT – Souběžné vstupenky (zápis) WT – Cache Global Lock Asserts |
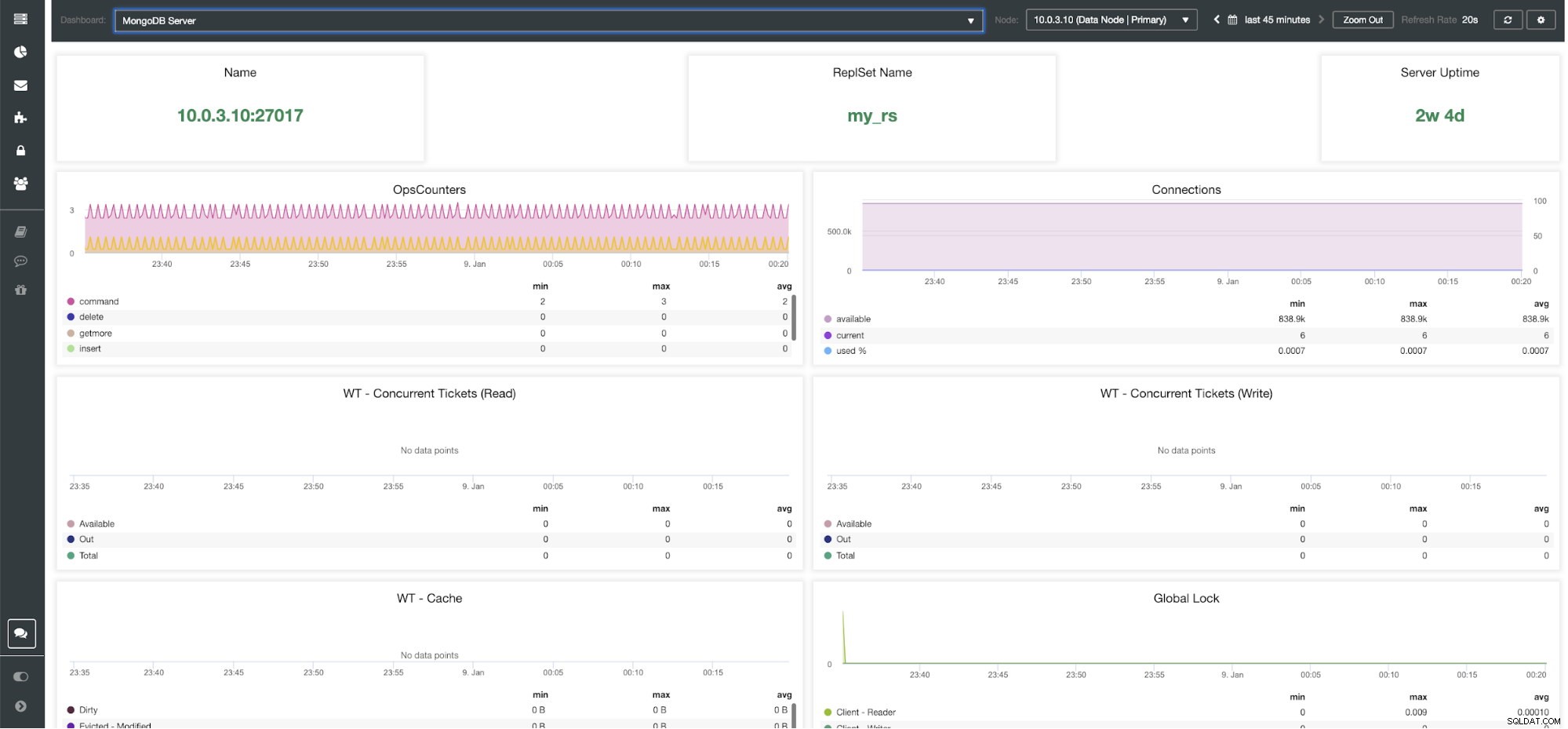 ClusterControl MongoDB Server Dashboard
ClusterControl MongoDB Server Dashboard| MongoDB ReplicaSet | |
|---|---|
| Velikost sady ReplSet Název sady Repl PRIMÁRNÍ Verze serveru Sady replik a členové Okno protokolu na sadu ReplSet Prostor pro replikaci Celkem PRIMÁRNÍ/SEKUNDÁRNÍ online na sadu ReplSet Otevřené kurzory na sadu ReplSet ReplSet – Časový limit kurzorů na sadu Maximální zpoždění replikace na sadu ReplSet Velikost Oplog OpsCounters Ping Time to Replica Set Members from PRIMARY(s) |
 Řídicí panel ClusterControl MongoDB ReplicaSet
Řídicí panel ClusterControl MongoDB ReplicaSet Databázové systémy silně závisí na prostředcích OS, takže můžete také najít dva další řídicí panely pro Přehled systému a Přehled clusteru vašeho prostředí MongoDB.
| Přehled systému | |
|---|---|
| Doba provozu serveru Jádra CPU Celková RAM Průměrná zátěž Využití CPU Využití RAM Využití místa na disku Využití sítě Disk IOPS Disk IO Util % Propustnost disku |
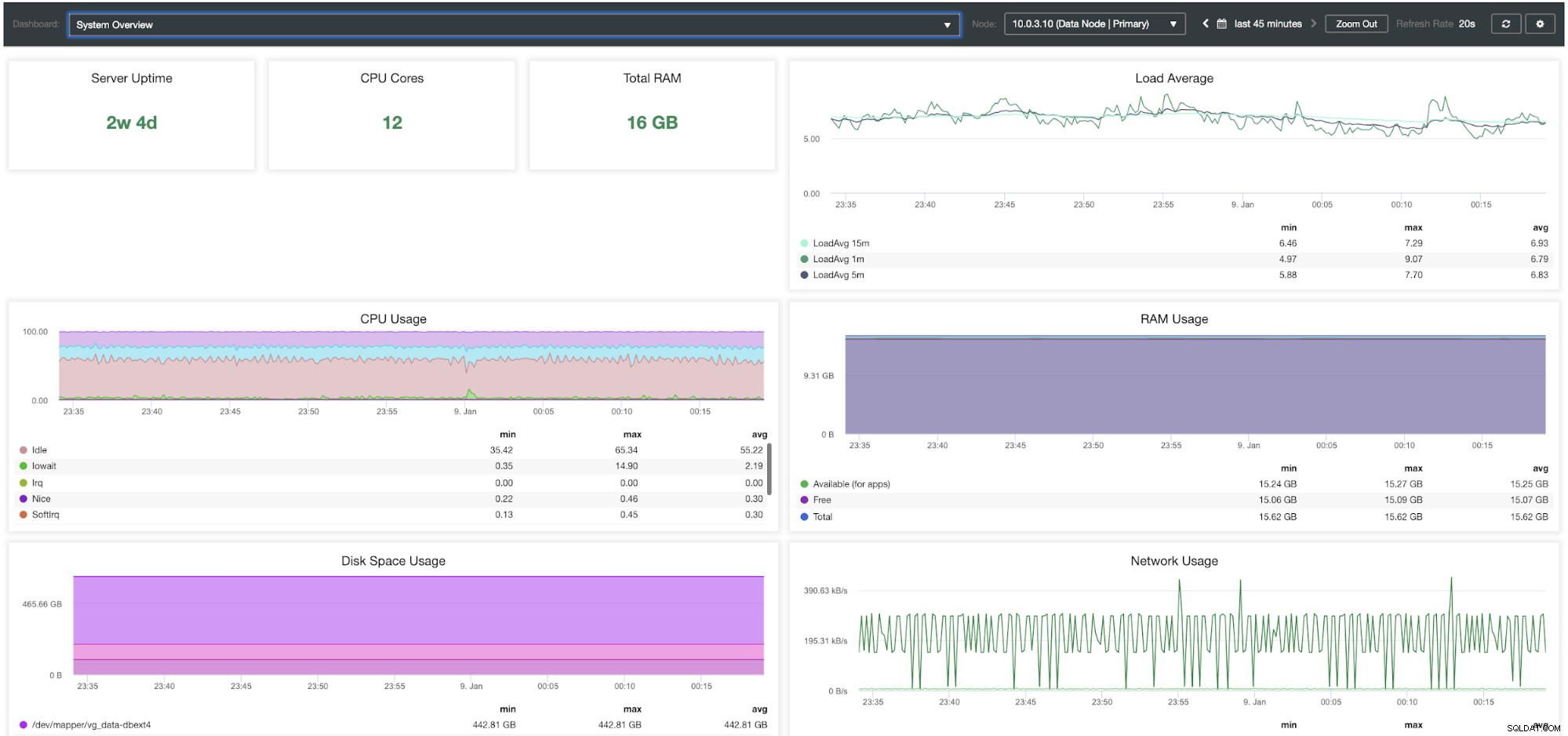 Dashboard Přehled systému ClusterControl
Dashboard Přehled systému ClusterControl| Přehled clusteru | |
|---|---|
| Průměrná zátěž 1 m Průměrná zátěž 5 m Průměrná zátěž 15 m Paměť dostupná pro aplikace Network TX Network RX Disk Read IOPS IOPS zápisu na disk IOPS zápisu na disk + čtení |
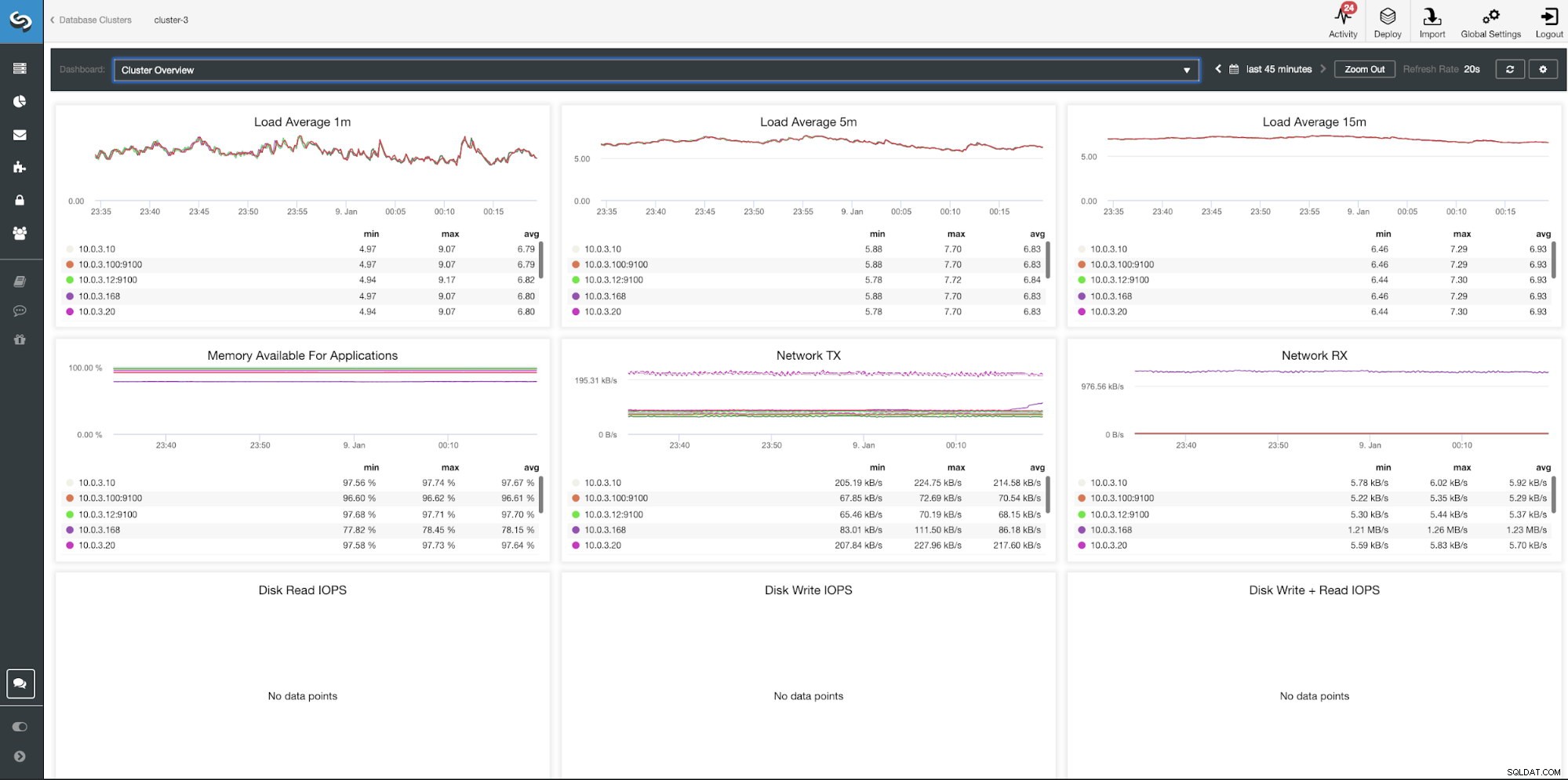 Panel Přehled ClusterControl Cluster
Panel Přehled ClusterControl Cluster Hlavní panel serveru MongoDB
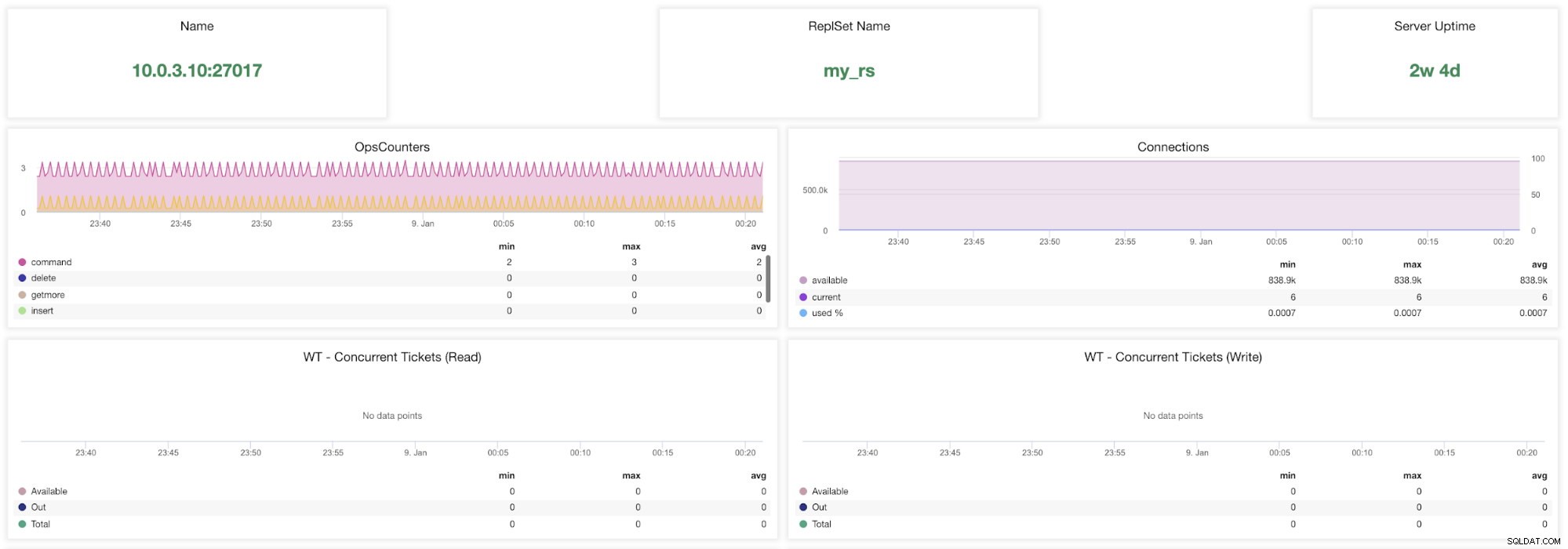 Metriky ClusterControl MongoDB
Metriky ClusterControl MongoDB Jméno - Adresa serveru a port.
Název sady Repls - Představuje název sady replik, do které server patří.
Doba provozu serveru - Čas od posledního restartu serveru.
Ops Couters - Počet přijatých požadavků za zvolené časové období rozdělený podle typu operace. Tyto počty zahrnují všechny přijaté operace, včetně těch, které nebyly úspěšné.
Připojení - Tento graf ukazuje jednu z nejdůležitějších metrik, které je třeba sledovat - počet spojení přijatých během zvoleného časového období včetně neúspěšných požadavků. Abnormální zatížení provozu může vést k problémům s výkonem. Pokud MongoDB dochází připojení, nemusí být schopen zpracovat příchozí požadavky včas.
WT – souběžné vstupenky (čtení) / WT – souběžné vstupenky (zápis) Tyto dva grafy ukazují tipy pro čtení a zápis, které řídí souběžnost v WiredTiger (WT). Vstupenky WT řídí, kolik operací čtení a zápisu lze na úložišti provést současně. Když dostupné lístky pro čtení a zápis klesnou na nulu, počet souběžně probíhajících operací se rovná nakonfigurovaným hodnotám čtení/zápisu. To znamená, že jakékoli další operace musí před provedením počkat, dokud jedno z běžících vláken nedokončí svou práci na úložišti.
 Metriky ClusterControl MongoDB
Metriky ClusterControl MongoDB WT – mezipaměť (Dirty, Evicted - Modified, Evicted - Unmodified, Max) - Velikost mezipaměti je nejdůležitějším knoflíkem pro WiredTiger. Ve výchozím nastavení MongoDB 3.x rezervuje 50 % (60 % ve 3.2) dostupné paměti pro svou datovou mezipaměť.
Globální zámek (Klient-čtení, klient – zápis, aktuální fronta – čtečka, aktuální fronta – zapisovač) – Špatné vzory návrhu schématu nebo náročné požadavky na čtení a zápis od mnoha klientů mohou způsobit rozsáhlé zamykání. Když k tomu dojde, je potřeba zachovat konzistenci a vyhnout se konfliktům při zápisu.
Aby toho bylo dosaženo, MongoDB používá multigranularity-uzamykání, které umožňuje zamykání operací na různých úrovních, jako je globální, databáze nebo kolekce. .
Potvrzení (msg, regular, rollovers, user) – Tento graf ukazuje počet tvrzení, která jsou vyvolána každou sekundu. Vysoké hodnoty a odchylky od trendů by měly být přezkoumány.
Hlavní panel MongoDB ReplicaSet
Metriky zobrazené na tomto panelu jsou důležité pouze v případě, že používáte sadu replik.
 Metriky ClusterControl MongoDB ReplicaSet
Metriky ClusterControl MongoDB ReplicaSet Velikost sady replik - Počet členů v sadě replik. Standardní nasazení sady replik pro produkční systém je tříčlenná sada replik. Obecně řečeno se doporučuje, aby sada replik měla lichý počet hlasujících členů. Tolerance chyb pro sadu replik je počet členů, kteří se mohou stát nedostupnými, a přesto v sadě ponechat dostatek členů pro zvolení primární volby. Tolerance chyb pro tři členy je jedna, pro pět jsou dva atd.
Název ReplSet - Je to název přiřazený v konfiguračním souboru MongoDB. Název odkazuje na hodnotu /etc/mongod.conf replSet.
PRIMÁRNÍ - Primární uzel přijímá všechny operace zápisu a zaznamenává všechny ostatní změny své datové sady do svého provozního protokolu. Hodnota je k identifikaci IP a portu vašeho primárního uzlu v clusteru sady replik MongoDB.
Verze serveru - Identifikujte verzi serveru. ClusterControl verze 1.7.1 podporuje MongoDB verze 3.2/3.4/3.6/4.0.
Sady replik a členové (min, max, avg) – Tento graf vám může pomoci identifikovat aktivní členy v průběhu časového období. Můžete sledovat minimální, maximální a průměrné počty primárních a sekundárních uzlů a jak se tato čísla měnila v průběhu času. Jakákoli odchylka může ovlivnit odolnost proti chybám a dostupnost clusteru.
Okno Oplog na sadu ReplSet - Replikační okno je základní metrikou, kterou je třeba sledovat. Oplog MongoDB je jediná kolekce, jejíž (přednastavená) velikost byla omezena. Lze to popsat jako rozdíl mezi prvním a posledním časovým razítkem v oplog.rs. Je to doba, po kterou může být sekundární prvek offline, než je k synchronizaci instance potřeba počáteční synchronizace. Tyto metriky vás informují o tom, kolik času vám zbývá do vyřazení naší další transakce z oplogu.
 Metriky ClusterControl MongoDB ReplicaSet
Metriky ClusterControl MongoDB ReplicaSet Replication Headroom - Tento graf představuje rozdíl mezi oknem primárního protokolu a zpožděním replikace sekundárních uzlů. Oplog MongoDB má omezenou velikost a pokud uzel příliš zaostává, nebude schopen jej dohnat. Pokud k tomu dojde, dojde k úplné synchronizaci a toto je nákladná operace, které je třeba se vždy vyhnout.
Celkem PRIMÁRNÍ/SEKUNDÁRNÍ online na sadu ReplSet - Celkový počet uzlů clusteru za časové období.
Otevřít kurzory na sadu ReplSet (připnuto, časový limit, celkem) - Požadavek na čtení přichází s kurzorem, který je ukazatelem na datovou sadu výsledku. Zůstane otevřená na serveru a bude tedy spotřebovávat paměť, pokud nebude ukončena výchozím nastavením MongoDB. Měli byste identifikovat neaktivní kurzory a odříznout je, abyste ušetřili paměť.
ReplSet - Časový limit kurzorů na SetsMax Prodleva replikace na sadu ReplSet - Prodleva replikace je velmi důležité sledovat, pokud zmenšujete čtení přidáváním dalších sekundárních položek. MongoDB použije tyto sekundární položky pouze v případě, že nebudou příliš zaostávat. Pokud má sekundární replikace zpoždění, riskujete, že budou obsluhována zastaralá data, která již byla přepsána na primární.
Velikost OplogSize - Některé úlohy mohou vyžadovat větší velikost oplogu. Aktualizace více dokumentů najednou, odstranění se rovnají stejnému množství dat jako vložení nebo významnému počtu aktualizací na místě.
OpsConters - Tento graf ukazuje počet provedení dotazů.
Čas pingu na replikaci nastavit člena z primárního - To vám umožní zjistit členy sady replik, které jsou mimo provoz nebo nedostupné z primárního uzlu.
Závěrečné poznámky
Nová funkce řídicího panelu ClusterControl 1.7.1 MongoDB je k dispozici v Community Edition zdarma. Databázové operační týmy z toho mohou profitovat pomocí grafů s vysokým rozlišením, zvláště když provádějí své každodenní rutiny jako analýzy hlavních příčin a plánování kapacity.
Nasazení nových monitorovacích agentů je otázkou jednoho kliknutí. ClusterControl instaluje agenty Prometheus, konfiguruje metriky a udržuje přístup ke konfiguraci exportérů Prometheus prostřednictvím svého GUI, takže můžete lépe spravovat konfiguraci parametrů, jako jsou příznaky kolektoru pro exportéry (Prometheus).
Přiměřeným sledováním počtu požadavků na čtení a zápis můžete zabránit přetížení zdrojů, rychle najít původ potenciálního přetížení a vědět, kdy je třeba škálovat.