Vícenásobné JOINY v jednom dotazu
Vícenásobné JOINY jsou normálně spojeny s více sbírkami, ale musíte mít základní znalosti o tom, jak INNER JOIN funguje (viz moje předchozí příspěvky na toto téma). Kromě našich dvou sbírek, které jsme měli dříve; jednotek a studentů, přidejme třetí kolekci a označme ji jako sportovní. Naplňte sportovní kolekci níže uvedenými údaji:
{
"_id" : 1,"tournamentsPlayed" : 6,
"gamesParticipated" : [{"hockey" : "midfielder","football" : "stricker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa", "Rio Brazil"]
}
{
"_id" : 2,"tournamentsPlayed" : 3,
"gamesParticipated" : [{"hockey" : "goalkeeper","football" : "stricker", "handball" : "midfielder"}],
"sportPlaces" : ["Ukraine","India", "Argentina"]
}
{
"_id" : 3,"tournamentsPlayed" : 10,
"gamesParticipated" : [{"hockey" : "stricker","football" : "goalkeeper","tabletennis" : "doublePlayer"}],
"sportPlaces" : ["China","Korea","France"]
}Chtěli bychom například vrátit všechna data pro studenta s hodnotou pole _id rovnou 1. Normálně bychom napsali dotaz k načtení hodnoty pole _id z kolekce studentů a poté vrácenou hodnotu použili k dotazu na údaje v dalších dvou kolekcích. V důsledku toho to nebude nejlepší volba, zejména pokud se jedná o velký soubor dokumentů. Lepším přístupem by bylo použití funkce SQL programu Studio3T. Můžeme se dotazovat na naši MongoDB s normálním konceptem SQL a pak se pokusit vyladit výsledný kód shellu Mongo tak, aby vyhovoval naší specifikaci. Například načteme všechna data s _id rovným 1 ze všech kolekcí:
SELECT *
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Výsledný dokument bude:
{
"students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"grades" : {Maths" : "A","English" : "A","Science" : "A","History" : "B"}
},
"sports" : {
"_id" : NumberInt(1),"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder", "football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa","Rio Brazil"]
}
}Na kartě Kód dotazu bude odpovídající kód MongoDB:
db.getCollection("students").aggregate(
[{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$unwind" : {"path" : "$units","preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id","from" : "sports", "foreignField" : "_id","as" : "sports"}},
{ "$unwind" : {"path" : "$sports", "preserveNullAndEmptyArrays" : false}},
{ "$match" : {"students._id" : NumberLong(1)}}
]
);Při pohledu do vráceného dokumentu osobně nejsem příliš spokojen s datovou strukturou, zejména u vložených dokumentů. Jak můžete vidět, jsou vrácena pole _id a pro jednotky nemusíme potřebovat, aby bylo pole hodnocení vloženo do jednotek.
Chtěli bychom mít pole jednotek s vloženými jednotkami a ne žádná jiná pole. To nás vede k části hrubého ladění. Stejně jako v předchozích příspěvcích zkopírujte kód pomocí poskytnuté ikony kopírování a přejděte do podokna agregace, vložte obsah pomocí ikony vložit.
Za prvé, operátor $match by měl být první fází, takže jej přesuňte na první pozici a získejte něco takového:
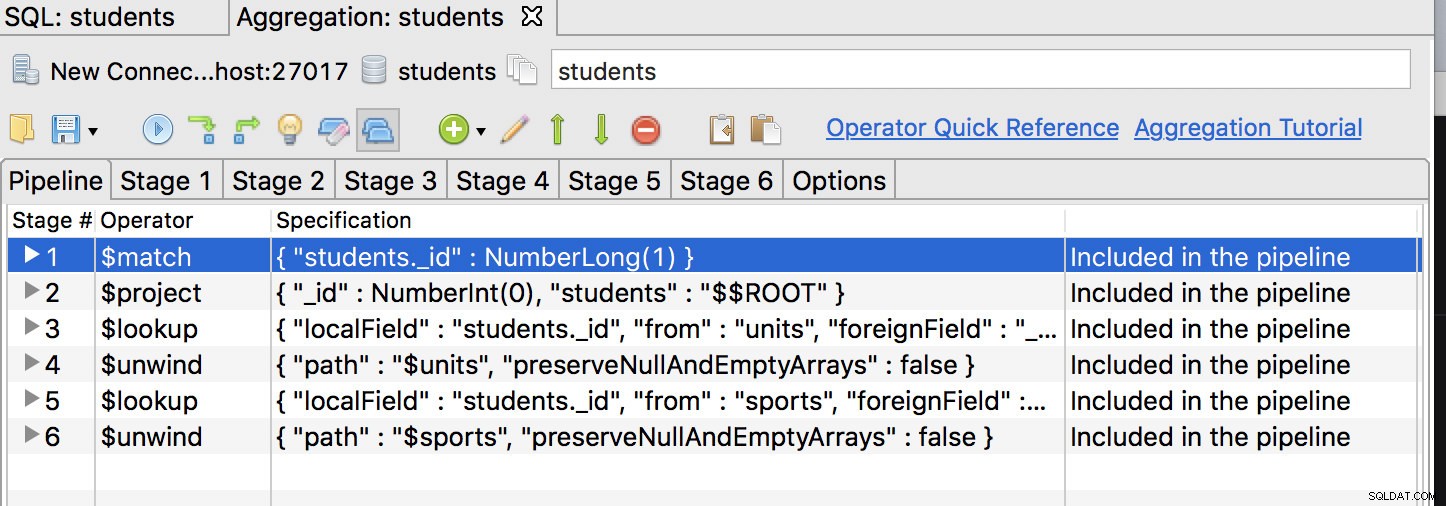
Klepněte na kartu první fáze a upravte dotaz na:
{
"_id" : NumberLong(1)
}Poté musíme dotaz dále upravit, abychom odstranili mnoho fází vkládání našich dat. Za tímto účelem přidáváme nová pole pro zachycení dat pro pole, která chceme odstranit, tj.:
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : { "_id": "$students._id","units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"sports._id" : 0.0}}
]
);Jak můžete vidět, v procesu jemného ladění jsme zavedli nové jednotky polí, které přepíší obsah předchozího agregačního potrubí se známkami jako vloženým polem. Dále jsme vytvořili pole _id, které označuje, že data byla ve vztahu k jakýmkoli dokumentům ve sbírkách se stejnou hodnotou. Poslední fází $projektu je odstranění pole _id ve sportovním dokumentu, abychom mohli mít přehledně prezentovaná data, jak je uvedeno níže.
{ "_id" : NumberInt(1),
"students" : {"name" : "James Washington", "age" : 15.0, "grade" : "A", "score" : 10.5},
"units" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"},
"sports" : {
"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder","football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge", "South Africa", "Rio Brazil"]
}
}Můžeme také omezit, která pole mají být vrácena z hlediska SQL. Například můžeme vrátit jméno studenta, jednotky, které tento student dělá, a počet turnajů odehraných pomocí více JOINS pomocí kódu níže:
SELECT students.name, units.grades, sports.tournamentsPlayed
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;To nám nedává nejvhodnější výsledek. Takže jako obvykle jej zkopírujte a vložte do podokna agregace. Pomocí níže uvedeného kódu doladíme, abychom získali odpovídající výsledek.
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : {"units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"name" : "$students.name", "grades" : "$units.grades", "tournamentsPlayed" : "$sports.tournamentsPlayed"}
}}
]
);Tento výsledek agregace z konceptu SQL JOIN nám poskytuje úhlednou a prezentovatelnou datovou strukturu uvedenou níže.
{
"name" : "James Washington",
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"},
"tournamentsPlayed" : NumberInt(6)
}Docela jednoduché, že? Data jsou docela prezentovatelná, jako by byla uložena v jedné kolekci jako jeden dokument.
LEVÉ VNĚJŠÍ PŘIPOJENÍ
LEVÉ VNĚJŠÍ SPOJENÍ se běžně používá k zobrazení dokumentů, které neodpovídají nejčastěji zobrazovanému vztahu. Výsledná sada spojení LEFT OUTER obsahuje všechny řádky z obou kolekcí, které splňují kritéria klauzule WHERE, stejně jako sada výsledků INNER JOIN. Kromě toho všechny dokumenty z levé kolekce, které nemají odpovídající dokumenty v pravé kolekci, budou také zahrnuty do sady výsledků. Pole vybraná z tabulky na pravé straně vrátí hodnoty NULL. Žádné dokumenty v pravé kolekci, které nemají odpovídající kritéria z levé kolekce, však nebudou vráceny.
Podívejte se na tyto dvě kolekce:
studenti
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 4,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Jednotky
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}V kolekci studentů nemáme hodnotu pole _id nastavenou na 3, ale v kolekci jednotek máme. Podobně neexistuje žádná hodnota pole _id 4 in v kolekci jednotek. Pokud použijeme kolekci studentů jako naši levou možnost v přístupu JOIN s dotazem níže:
SELECT *
FROM students
LEFT OUTER JOIN units
ON students._id = units._idS tímto kódem získáme následující výsledek:
{
"students" : {"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5},
"units" : {"_id" : 1,"grades" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"}}
}
{
"students" : {"_id" : 2,"name" : "Clinton Ariango", "age" : 14,"grade" : "B", "score" : 7.5 }
}
{
"students" : {"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5},
"units" : {"_id" : 3,"grades" : {"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}
}Druhý dokument nemá pole jednotek, protože v kolekci jednotek nebyl žádný odpovídající dokument. Pro tento SQL dotaz bude odpovídající Mongo kód
db.getCollection("students").aggregate(
[
{
"$project" : {"_id" : NumberInt(0), "students" : "$$ROOT"}},
{
"$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"}
},
{
"$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : true}
}
]
);Samozřejmě jsme se dozvěděli o jemném ladění, takže můžete pokračovat a restrukturalizovat agregační potrubí tak, aby vyhovovalo konečnému výsledku, který byste chtěli. SQL je velmi mocný nástroj pro správu databází. Je to samo o sobě široké téma, můžete také zkusit použít klauzule IN a GROUP BY, abyste získali odpovídající kód pro MongoDB a viděli, jak to funguje.
Závěr
Zvyknutí si na novou (databázovou) technologii navíc k té, se kterou jste zvyklí pracovat, může zabrat spoustu času. Relační databáze jsou stále běžnější než ty nerelační. Se zavedením MongoDB se však věci změnily a lidé by se jej rádi naučili co nejrychleji, protože s ním souvisí vysoký výkon.
Naučit se MongoDB od nuly může být trochu zdlouhavé, ale můžeme využít znalosti SQL k manipulaci s daty v MongoDB, získat relativní kód MongoDB a doladit jej, abychom získali co nejvhodnější výsledky. Jedním z nástrojů, který je k dispozici pro zlepšení tohoto stavu, je Studio 3T. Nabízí dvě důležité funkce, které usnadňují práci se složitými daty, to jest:funkce dotazů SQL a editor agregace. Dotazy jemného ladění vám nejen zajistí nejlepší výsledek, ale také zlepší výkon z hlediska úspory času.