Chcete se dozvědět vše o Hadoop clusteru?
Hadoop je softwarový rámec pro analýzu a ukládání obrovského množství dat napříč klastry komoditního hardwaru. V tomto článku budeme studovat Hadoop Cluster.
Začněme nejprve úvodem do Clusteru.
Co je to cluster?
Cluster je kolekce uzlů. Uzly nejsou nic jiného než bod spojení/průnik v rámci sítě.
Počítačový cluster je sbírka počítačů připojených k síti, které jsou schopny mezi sebou komunikovat a fungují jako jeden systém.
Co je Hadoop Cluster?
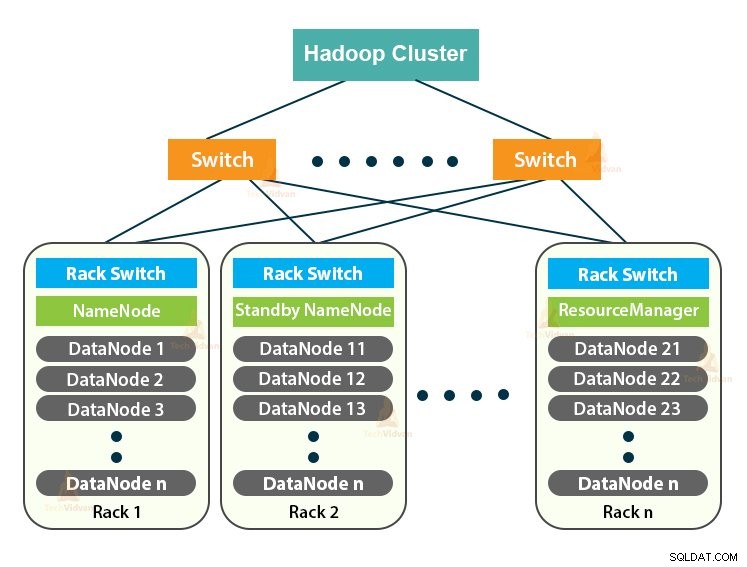
Hadoop Cluster je pouze počítačový cluster používaný ke zpracování velkého množství dat distribuovaným způsobem.
Jedná se o výpočetní cluster navržený pro ukládání a analýzu velkého množství nestrukturovaných nebo strukturovaných dat v distribuovaném výpočetním prostředí.
Clustery Hadoop jsou také známé jako systémy sdíleného nic protože mezi uzly v clusteru není sdíleno nic kromě šířky pásma sítě. Tím se sníží latence zpracování.
Když je tedy potřeba zpracovat dotazy na obrovské množství dat, latence v celém clusteru je minimalizována.
Pojďme nyní studovat architekturu Hadoop Cluster.
Architektura klastru Hadoop
Hadoop Cluster sleduje architekturu master-slave. Skládá se z hlavního uzlu, podřízeného uzlu a klientského uzlu.
1. Master in Hadoop Cluster
Master in the Hadoop Cluster je vysoce výkonný stroj s vysokou konfigurací paměti a CPU. Dva démoni, kterými jsou NameNode a ResourceManager, běží na hlavním uzlu.
a. Funkce NameNode
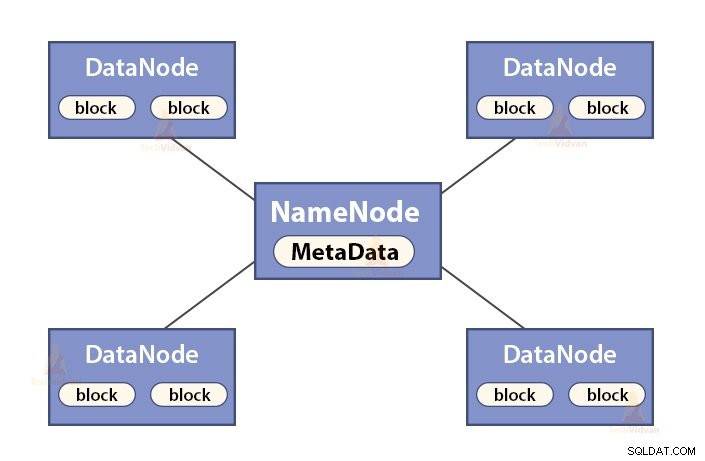
NameNode je hlavní uzel v Hadoop HDFS . NameNode spravuje jmenný prostor souborového systému. Ukládá metadata souborového systému do paměti pro rychlé vyhledávání. Proto by měl být konfigurován na počítačích vyšší třídy.
Funkce NameNode jsou:
- Spravuje jmenný prostor souborového systému
- Ukládá metadata o blocích souboru, umístění bloků, oprávněních atd.
- Provádí operace jmenného prostoru souborového systému, jako je otevírání, zavírání, přejmenování souborů a adresářů atd.
- Udržuje a spravuje DataNode.
b. Funkce Správce zdrojů
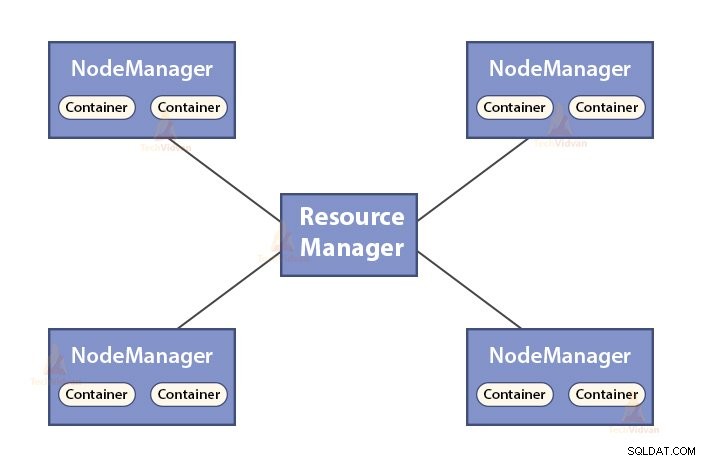
- ResourceManager je hlavní démon YARN.
- ResourceManager určuje zdroje mezi všemi aplikacemi v systému.
- Sleduje živé a mrtvé uzly v clusteru.
2. Otroci v klastru Hadoop
Slave v Hadoop Clusteru jsou levným komoditním hardwarem. Dva démoni, kterými jsou DataNodes a YARN NodeManagers, běží na podřízených uzlech.
a. Funkce DataNodes
- DataNodes uchovává skutečná obchodní data. Ukládá bloky souboru.
- Provádí vytváření, mazání a replikaci bloků na základě pokynů z NameNode.
- DataNode je zodpovědný za obsluhu operací čtení/zápisu klientů.
b. Funkce NodeManager
- NodeManager je slave démon YARN.
- Zodpovídá za kontejnery, sleduje jejich využití zdrojů (jako je CPU, disk, paměť, síť) a hlásí to správci zdrojů.
- NodeManager také kontroluje stav uzlu, na kterém běží.
3. Klientský uzel v Hadoop Cluster
Klientské uzly v Hadoopu nejsou ani hlavní, ani podřízené uzly. Mají na sobě nainstalovaný Hadoop se všemi nastaveními clusteru.
Funkce klientských uzlů
- Klientské uzly načítají data do Hadoop Clusteru.
- Odešle úlohy MapReduce popisující, jak by měla být tato data zpracována.
- Po dokončení zpracování načtěte výsledky úlohy.
Můžeme škálovat Hadoop Cluster přidáním dalších uzlů. Díky tomu je Hadoop lineárně škálovatelný . S každým přidáním uzlu získáme odpovídající zvýšení propustnosti. Pokud máme ‚n‘ uzlů, pak přidání 1 uzlu poskytuje (1/n) další výpočetní výkon.
Jednouzlový hadoopový cluster versus víceuzlový hadoopový cluster
1. Hadoop cluster s jedním uzlem
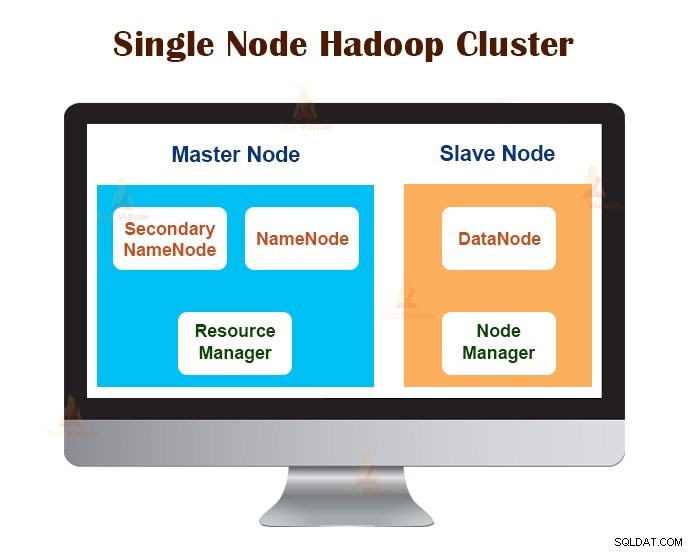
Cluster Hadoop s jedním uzlem je nasazen na jednom počítači. Všichni démoni jako NameNode, DataNode, ResourceManager, NodeManager běží na stejném počítači/hostiteli.
V nastavení clusteru s jedním uzlem vše běží na jedné instanci JVM. Uživatel Hadoop nemusel provádět žádná konfigurační nastavení kromě nastavení proměnné JAVA_HOME.
Výchozí faktor replikace pro cluster Hadoop s jedním uzlem je vždy 1.
2. Multi-Node Hadoop Cluster
Multi-Node Hadoop Cluster je nasazen na více počítačích. Všichni démoni ve víceuzlovém clusteru Hadoop jsou spuštěni a běží na různých počítačích/hostitelích.
Víceuzlový cluster Hadoop se řídí architekturou master-slave. Démoni Namenode a ResourceManager běží na hlavních uzlech, což jsou počítače vyšší třídy.
Démoni DataNodes a NodeManagers běží na podřízených uzlech (pracovní uzly), což je levný komoditní hardware.
Ve víceuzlovém clusteru Hadoop mohou být podřízené stroje přítomny v libovolném umístění bez ohledu na umístění fyzického umístění hlavního serveru.
Komunikační protokoly používané v Hadoop Cluster
Komunikační protokoly HDFS jsou navrstveny na vrcholu protokolu TCP/IP. Klient naváže spojení s NameNode prostřednictvím konfigurovatelného portu TCP na počítači NameNode.
Hadoop Cluster naváže připojení ke klientovi prostřednictvím ClientProtocol. Navíc DataNode komunikuje s NameNode pomocí DataNode Protocol.
Abstrakce vzdáleného volání procedur (RPC) obaluje klientský protokol a protokol DataNode. Podle návrhu NameNode neiniciuje žádné RPC. Odpovídá pouze na požadavky RPC vydané klienty nebo DataNodes.
Osvědčené postupy pro vytváření clusteru Hadoop
Výkon Hadoop Clusteru závisí na různých faktorech založených na dobře dimenzovaných hardwarových zdrojích, které využívají CPU, paměť, šířku pásma sítě, pevný disk a další dobře nakonfigurované softwarové vrstvy.
Vybudování Hadoop Clusteru je netriviální práce. Vyžaduje to zvážení různých faktorů, jako je výběr správného hardwaru, dimenzování Hadoop Clusterů a konfigurace Hadoop Clusteru.
Podívejme se nyní na každý z nich podrobně.
1. Výběr správného hardwaru pro Hadoop Cluster
Mnoho organizací se při nastavování infrastruktury Hadoop nachází v nesnázích, protože si neuvědomují, jaký druh strojů je třeba zakoupit pro nastavení optimalizovaného prostředí Hadoop a jaké ideální konfigurace musí použít.
Pro výběr správného hardwaru pro Hadoop Cluster je třeba vzít v úvahu následující body:
- Objem dat, který bude cluster zpracovávat.
- Typ zátěže, se kterou se bude cluster vypořádat (vázáno na CPU, vázáno na I/O).
- Metodika ukládání dat, jako jsou datové kontejnery, použité techniky komprese dat, pokud existují.
- Zásady uchovávání dat, to znamená, jak dlouho chceme data uchovávat, než je vyprázdníme.
2. Určení velikosti klastru Hadoop
Pro určení velikosti Hadoop Clusteru by měl být klíčovým faktorem objem dat, který uživatelé Hadoop zpracují na Hadoop Clusteru.
Znalost objemu dat, která mají být zpracována, pomáhá při rozhodování o tom, kolik uzlů bude zapotřebí pro efektivní zpracování dat a kapacitu paměti požadovanou pro každý uzel. Měla by existovat rovnováha mezi výkonem a cenou schváleného hardwaru.
3. Konfigurace Hadoop Cluster
Najít ideální konfiguraci pro Hadoop Cluster není snadný úkol. Rámec Hadoop musí být přizpůsoben clusteru, na kterém běží, a také úloze.
Nejlepší způsob, jak rozhodnout o ideální konfiguraci pro Hadoop Cluster, je spouštět úlohy Hadoop s dostupnou výchozí konfigurací, abyste získali základní linii. Poté můžeme analyzovat soubory protokolu historie úloh, abychom zjistili, zda došlo k nějakému slabému zdroji nebo zda doba potřebná ke spuštění úloh není delší, než se očekávalo.
Pokud ano, změňte konfiguraci. Opakování stejného procesu může vyladit konfiguraci Hadoop Cluster, která nejlépe vyhovuje obchodním požadavkům.
Výkon Hadoop Clusteru značně závisí na prostředcích přidělených démonům. Pro malý až střední datový kontext Hadoop rezervuje jedno CPU jádro na každém DataNode, zatímco pro dlouhé datové sady alokuje 2 CPU jádra na každý DataNode pro HDFS a MapReduce démony.
Správa clusteru Hadoop
Při nasazení Hadoop Clusteru do produkce je zřejmé, že by se měl škálovat podél všech dimenzí, kterými jsou objem, rozmanitost a rychlost.
Různé funkce, které by měl mít, aby byl připraven k výrobě, jsou – nepřetržitá dostupnost, robustnost, ovladatelnost a výkon. Správa klastrů Hadoop je hlavním aspektem iniciativy pro velká data.
Nejlepší nástroj pro správu Hadoop Clusteru by měl mít následující vlastnosti:-
- Musí zajistit vysokou dostupnost 24 hodin denně 7 dní v týdnu, poskytování zdrojů, rozmanité zabezpečení, správu pracovní zátěže, monitorování stavu a optimalizaci výkonu. Také musí poskytovat plánování úloh, správu zásad, zálohování a obnovu přes jeden nebo více uzlů.
- Implementujte redundantní HDFS NameNode s vysokou dostupností s vyrovnáváním zátěže, pohotovostními režimy, resynchronizací a automatickým přepnutím při selhání.
- Vynucení ovládacích prvků založených na zásadách, které zabraňují jakékoli aplikaci získat nepřiměřený podíl zdrojů na již namaxovaném clusteru Hadoop.
- Provádění regresního testování pro správu nasazení jakýchkoli softwarových vrstev přes clustery Hadoop. Je to proto, aby se zajistilo, že žádné úlohy nebo data nespadnou nebo nenarazí na překážky v každodenním provozu.
Výhody Hadoop Cluster
Různé výhody, které Hadoop Cluster poskytuje, jsou:
1. Škálovatelné
Hadoop clustery jsou škálovatelné. Do Hadoop Clusteru můžeme přidat libovolný počet uzlů bez jakýchkoli prostojů a bez dalšího úsilí. S každým přidáním uzlu získáme odpovídající zvýšení propustnosti.
2. Robustnost
Hadoop Cluster je nejlépe známý pro své spolehlivé úložiště. Dokáže spolehlivě ukládat data i v případech, jako je selhání DataNode, selhání NameNode a síťový oddíl. DataNode pravidelně vysílá signál srdečního tepu do NameNode.
V síťovém oddílu se sada DataNodes odpojí od NameNode, díky čemuž NameNode nepřijímá žádný prezenční signál z těchto DataNode. NameNode pak považuje tyto DataNode za mrtvé a nepředává jim žádný I/O požadavek.
Také replikační faktor bloků uložených v těchto DataNodes klesne pod jejich specifikovanou hodnotu. V důsledku toho NameNode zahájí replikaci těchto bloků a zotaví se po selhání.
3. Cluster Rebalancing
Architektura Hadoop HDFS automaticky provádí opětovné vyvážení clusteru. Pokud volné místo v DataNode klesne pod prahovou úroveň, architektura HDFS automaticky přesune některá data do jiného DataNode, kde je dostatek místa.
4. Cenově efektivní
Nastavení Hadoop Clusteru je nákladově efektivní, protože obsahuje levný komoditní hardware. Každá organizace může snadno nastavit výkonný Hadoop Cluster, aniž by utrácela mnoho za drahý serverový hardware.
Také Hadoop Clusters s topologií distribuovaného úložiště překonávají omezení tradičního systému. Omezené úložiště lze rozšířit pouhým přidáním dalších levných úložných jednotek do systému.
5. Flexibilní
Hadoop Clusters jsou vysoce flexibilní, protože mohou zpracovávat data jakéhokoli typu, strukturovaná, polostrukturovaná nebo nestrukturovaná, a jakékoli velikosti od gigabajtů po petabajty.
6. Rychlé zpracování
V Hadoop Clusteru lze data zpracovávat paralelně v distribuovaném prostředí. To Hadoopu poskytuje možnosti rychlého zpracování dat. Hadoop Clusters dokážou zpracovat terabajty nebo petabajty dat během zlomku sekund.
7. Integrita dat
Pro kontrolu jakéhokoli poškození datových bloků kvůli chybnému softwaru, chybám v úložném zařízení atd. Hadoop Cluster implementuje kontrolní součet na každý blok souboru. Pokud zjistí, že je některý blok poškozený, hledá jej v jiném DataNode, který obsahuje repliku stejného bloku. Hadoop Cluster tedy zachovává integritu dat.
Shrnutí
Po přečtení tohoto článku můžeme říci, že Hadoop Cluster je speciální výpočetní cluster určený pro analýzu a ukládání velkých dat. Hadoop Cluster se řídí architekturou master-slave.
Hlavní uzel je počítačový stroj vyšší třídy a podřízené uzly jsou stroje s normální konfigurací CPU a paměti. Viděli jsme také, že Hadoop Cluster lze nastavit na jednom počítači nazývaném jednouzlový Hadoop Cluster nebo na více strojích nazývaných víceuzlový Hadoop Cluster.
V tomto článku jsme se také zabývali osvědčenými postupy, které je třeba dodržovat při vytváření clusteru Hadoop. Viděli jsme také mnoho výhod Hadoop Clusteru, včetně škálovatelnosti, flexibility, nákladové efektivity atd.