ClusterControl je naprogramován s řadou algoritmů obnovy, aby automaticky reagoval na různé typy běžných selhání ovlivňujících vaše databázové systémy. Rozumí různým typům databázových topologií a správě procesů souvisejících s databází, aby vám pomohl určit nejlepší způsob obnovení klastru. ClusterControl svým způsobem zlepšuje dostupnost vaší databáze.
Někteří správci topologie pokrývají pouze obnovu clusteru, jako je MHA, Orchestrator a mysqlfailover, ale obnovu uzlu musíte zvládnout sami. ClusterControl podporuje obnovu na úrovni clusteru i uzlu.
Možnosti konfigurace
ClusterControl podporuje dvě součásti obnovy, konkrétně:
- Cluster – pokus o obnovení klastru do provozního stavu
- Uzel – Pokus o obnovení uzlu do provozního stavu
Tyto dvě složky jsou nejdůležitější pro zajištění co nejvyšší dostupnosti služby. Pokud již máte nad ClusterControl správce topologie, můžete zakázat funkci automatického obnovení a nechat jiného správce topologie, aby to za vás spravoval. S ClusterControl máte všechny možnosti.
Funkci automatického obnovení lze povolit a zakázat jednoduchým přepínačem ON/OFF a funguje pro obnovení clusteru nebo uzlu. Zelené ikony znamenají povoleno a červené ikony zakázáno. Následující snímek obrazovky ukazuje, kde jej můžete najít v seznamu databázových clusterů:
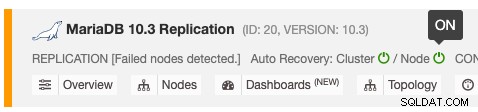
Existují 3 parametry ClusterControl, které lze použít k řízení chování při obnově. Všechny parametry jsou standardně nastaveny na hodnotu true (nastavené s booleovským celým číslem 0 nebo 1):
- enable_autorecovery – Povolí obnovu clusteru a uzlů. Tento parametr je nadmnožinou položek enable_cluster_recovery a enable_node_recovery. Pokud je nastavena na 0, parametry podmnožiny budou vypnuty.
- enable_cluster_recovery – ClusterControl provede obnovu clusteru, pokud je povolena.
- enable_node_recovery – ClusterControl provede obnovu uzlu, pokud je povolena.
Obnova klastru pokrývá pokus o obnovu, aby byla uvedena celá topologie klastru. Například replikace master-slave musí mít v daný okamžik alespoň jednoho živého master, bez ohledu na počet dostupných slave(ů). ClusterControl se pokusí opravit topologii alespoň jednou pro replikační clustery, ale nekonečně pro multi-master replikaci, jako je NDB Cluster a Galera Cluster.
Obnova uzlu pokrývá problém s obnovou uzlu, jako když byl uzel zastaven bez znalosti ClusterControl, např. příkazem zastavení systému z konzoly SSH nebo byl zabit procesem OOM.
Obnova uzlu
ClusterControl je schopen obnovit databázový uzel v případě občasného selhání monitorováním procesu a připojení k databázovým uzlům. Pro tento proces funguje podobně jako systemd, kde zajistí spuštění a spuštění služby MySQL, pokud jste ji úmyslně nezastavili prostřednictvím uživatelského rozhraní ClusterControl.
Pokud se uzel vrátí do režimu online, ClusterControl naváže připojení zpět k uzlu databáze a provede potřebné akce. ClusterControl by pro obnovení uzlu udělal následující:
- Po dobu 30 sekund počká, než systemd/chkconfig/init spustí monitorované služby/procesy
- Pokud jsou monitorované služby/procesy stále mimo provoz, ClusterControl se pokusí spustit databázovou službu automaticky.
- Pokud ClusterControl nedokáže obnovit monitorované služby/procesy, spustí se alarm.
Všimněte si, že pokud uživatel zahájí vypnutí databáze, ClusterControl se nepokusí obnovit konkrétní uzel. Očekává, že jej uživatel spustí zpět prostřednictvím uživatelského rozhraní ClusterControl přechodem na Node -> Node Actions -> Start Node nebo explicitně použije příkaz OS.
Obnova zahrnuje všechny služby související s databází, jako je ProxySQL, HAProxy, MaxScale, Keepalived, exportéry Prometheus a garbd. Zvláštní pozornost je věnována exportérům Prometheus, kde ClusterControl používá program nazvaný „daemon“ k démonizaci procesu exportu. ClusterControl se pokusí připojit k naslouchacímu portu exportéra za účelem kontroly stavu a ověření. Proto se doporučuje otevřít exportní porty ze serveru ClusterControl a Prometheus, abyste se ujistili, že během obnovy nedojde k falešnému poplachu.
Obnova clusteru
ClusterControl rozumí topologii databáze a při provádění obnovy se řídí osvědčenými postupy. U databázového clusteru, který je dodáván s integrovanou odolností proti chybám, jako je Galera Cluster, NDB Cluster a MongoDB Replicaset, bude proces převzetí služeb při selhání automaticky proveden databázovým serverem prostřednictvím výpočtu kvora, prezenčního signálu a přepínání rolí (pokud existuje). ClusterControl monitoruje proces a provádí nezbytné úpravy vizualizace, jako je zohlednění změn v zobrazení Topologie a úprava komponenty monitorování a správy pro novou roli, např. nový primární uzel v sadě replik.
U databázových technologií, které nemají vestavěnou odolnost proti chybám s automatickým obnovením, jako je replikace MySQL/MariaDB a replikace streamování dat PostgreSQL/TimescaleDB, provede ClusterControl postupy obnovy podle osvědčených postupů poskytovaných prodejce databáze. Pokud se obnovení nezdaří, je nutný zásah uživatele a samozřejmě o tom dostanete upozornění.
Ve smíšené/hybridní topologii, například asynchronní slave, který je připojen ke clusteru Galera nebo NDB Cluster, bude uzel obnoven pomocí ClusterControl, pokud je povoleno obnovení clusteru.
Obnova clusteru se nevztahuje na samostatný server MySQL. Pro tento typ clusteru se však v uživatelském rozhraní ClusterControl doporučuje zapnout obnovu uzlu i clusteru.
Replikace MySQL/MariaDB
ClusterControl podporuje obnovu následujícího nastavení replikace MySQL/MariaDB:
- Master-slave s MySQL GTID
- Master-slave s MariaDB GTID
- Master-slave s bez GTID (MySQL i MariaDB)
- Master-master s MySQL GTID
- Master-master s MariaDB GTID
- Asynchronní slave připojený ke clusteru Galera
ClusterControl bude při obnově clusteru respektovat následující parametry:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- černá listina_failover_replication
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
Další podrobnosti o každém z parametrů naleznete na stránce dokumentace.
ClusterControl se bude při sledování a správě replikace master-slave řídit následujícími pravidly:
- Všechny uzly budou spuštěny s read_only=ON a super_read_only=ON (bez ohledu na jejich roli).
- V daném okamžiku může pracovat pouze jeden hlavní server (read_only=OFF).
- Při mapování topologie se spolehněte na proměnnou MySQL report_host.
- Pokud existují dva nebo více uzlů, které mají současně hodnotu read_only=OFF, ClusterControl automaticky nastaví read_only=ON na obou masterech, aby je ochránil před náhodným zápisem. K výběru skutečného masteru je nutný zásah uživatele deaktivací pouze pro čtení. Přejděte na Nodes -> Node Actions -> Disable Readonly.
V případě, že aktivní hlavní server přestane fungovat, ClusterControl se pokusí provést převzetí služeb při selhání hlavního serveru v následujícím pořadí:
- Po 3 sekundách nedosažitelnosti masteru spustí ClusterControl alarm.
- Zkontrolujte dostupnost slave zařízení, alespoň jeden z slave musí být dosažitelný pomocí ClusterControl.
- Vyberte otroka jako kandidáta na mistra.
- ClusterControl vypočítá pravděpodobnost chybných transakcí, pokud je povoleno GTID.
- Pokud nebude zjištěna žádná chybná transakce, vybraný bude povýšen na nového hlavního serveru.
- Vytvořte a udělte uživatele replikace pro použití otroky.
- Změnit pána pro všechny otroky, kteří ukazovali ze starého pána na nově povýšeného pána.
- Spustit slave a povolit pouze pro čtení.
- Vyprázdnit protokoly na všech uzlech.
- Pokud povýšení slave selže, ClusterControl zruší úlohu obnovy. K opětovnému spuštění úlohy obnovy je nutný zásah uživatele nebo restartování služby cmon.
- Až bude stará předloha znovu dostupná, bude spuštěna pouze pro čtení a nebude součástí replikace. Je vyžadován zásah uživatele.
Současně budou spuštěny následující alarmy:
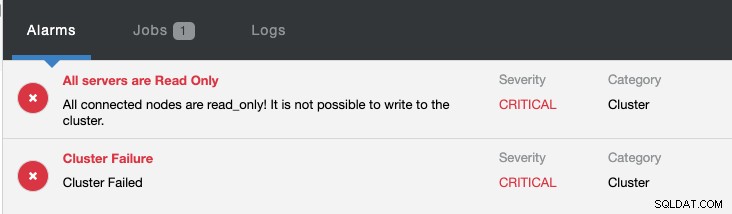
Podívejte se na Úvod do funkce Failover pro replikaci MySQL – blog 101 a automatické převzetí služeb při selhání replikace MySQL – novinka v ClusterControl 1.4, kde najdete další informace o tom, jak nakonfigurovat a spravovat převzetí služeb při selhání replikace MySQL pomocí ClusterControl.
PostgreSQL/TimescaleDB Streaming Replication
ClusterControl podporuje obnovu následujícího nastavení replikace PostgreSQL:
- PostgreSQL Streaming Replication
- TimescaleDB Streaming Replication
ClusterControl bude při obnově clusteru respektovat následující parametry:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- černá listina_failover_replication
Další podrobnosti o každém z parametrů naleznete na stránce dokumentace.
ClusterControl se bude řídit následujícími pravidly pro správu a monitorování nastavení streamovací replikace PostgreSQL:
- wal_level je nastavena na "replica" (nebo "hot_standby" v závislosti na verzi PostgreSQL).
- Proměnný archive_mode je na hlavním serveru nastaven na ON.
- Nastavte soubor recovery.conf na podřízené uzly, čímž se uzel přepne do pohotovostního režimu s povoleným pouze pro čtení.
V případě, že dojde k výpadku aktivního hlavního serveru, ClusterControl se pokusí provést obnovu clusteru v následujícím pořadí:
- Po 10 sekundách nedosažitelnosti masteru spustí ClusterControl alarm.
- Po 10 sekundách plynulé čekací doby zahájí ClusterControl hlavní úlohu převzetí služeb při selhání.
- Vzorkujte replayLocation a acceptLocation na všech dostupných uzlech, abyste určili nejpokročilejší uzel.
- Povýšit nejpokročilejší uzel jako nový hlavní uzel.
- Zastavte otroky.
- Ověřte stav synchronizace pomocí pg_rewind.
- Restartování otroků s novým masterem.
- Pokud povýšení slave selže, ClusterControl zruší úlohu obnovy. K opětovnému spuštění úlohy obnovy je nutný zásah uživatele nebo restartování služby cmon.
- Když bude starý master znovu dostupný, bude nucen se vypnout a nebude součástí replikace. Je vyžadován zásah uživatele. Viz níže.
Když se starý hlavní server vrátí do režimu online, pokud je spuštěna služba PostgreSQL, ClusterControl vynutí vypnutí služby PostgreSQL. To má chránit server před náhodnými zápisy, protože by byl spuštěn bez souboru obnovy (recovery.conf), což znamená, že by bylo možné zapisovat. Měli byste očekávat, že se v postgresql-{day}.log objeví následující řádky:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downPostgreSQL byl spuštěn poté, co byl server opět online kolem 05:06:10, ale ClusterControl provedl rychlé vypnutí 17 sekund poté, kolem 05:06:27. Pokud je to něco, co byste nechtěli, můžete pro tento cluster dočasně zakázat obnovu uzlů.
Podívejte se na Automatické přepnutí při selhání replikace Postgres a přepnutí při selhání pro PostgreSQL Replication 101, kde získáte další informace o tom, jak nakonfigurovat a spravovat přepnutí při selhání replikace PostgreSQL pomocí ClusterControl.
Závěr
Automatická obnova ClusterControl rozumí topologii databázového clusteru a je schopna obnovit nefunkční nebo degradovaný cluster do plně funkčního clusteru, což výrazně zlepší dostupnost databázových služeb. Vyzkoušejte ClusterControl nyní a dosáhněte svých devítek v SLA a dostupnosti databáze. Neznáte své devítky? Podívejte se na tuto skvělou devítkovou kalkulačku.