TL;DR:mongoengine tráví věky převáděním všech vrácených polí na diktáty
Abych to otestoval, vytvořil jsem kolekci s dokumentem s DictField s velkým vnořeným dict . Dokument je zhruba v rozsahu 5-10 MB.
Poté můžeme použít timeit.timeit
pro potvrzení rozdílu ve čtení pomocí pymongo a mongoengine.
Poté můžeme použít pycallgraph a GraphViz abych viděl, co mongoenginu trvá tak zatraceně dlouho.
Zde je celý kód:
import datetime
import itertools
import random
import sys
import timeit
from collections import defaultdict
import mongoengine as db
from pycallgraph.output.graphviz import GraphvizOutput
from pycallgraph.pycallgraph import PyCallGraph
db.connect("test-dicts")
class MyModel(db.Document):
date = db.DateTimeField(required=True, default=datetime.date.today)
data_dict_1 = db.DictField(required=False)
MyModel.drop_collection()
data_1 = ['foo', 'bar']
data_2 = ['spam', 'eggs', 'ham']
data_3 = ["subf{}".format(f) for f in range(5)]
m = MyModel()
tree = lambda: defaultdict(tree) # https://stackoverflow.com/a/19189366/3271558
data = tree()
for _d1, _d2, _d3 in itertools.product(data_1, data_2, data_3):
data[_d1][_d2][_d3] = list(random.sample(range(50000), 20000))
m.data_dict_1 = data
m.save()
def pymongo_doc():
return db.connection.get_connection()["test-dicts"]['my_model'].find_one()
def mongoengine_doc():
return MyModel.objects.first()
if __name__ == '__main__':
print("pymongo took {:2.2f}s".format(timeit.timeit(pymongo_doc, number=10)))
print("mongoengine took", timeit.timeit(mongoengine_doc, number=10))
with PyCallGraph(output=GraphvizOutput()):
mongoengine_doc()
A výstup dokazuje, že mongoengine je ve srovnání s pymongo velmi pomalý:
pymongo took 0.87s
mongoengine took 25.81118331072267
Výsledný graf volání docela jasně ukazuje, kde je hrdlo láhve:
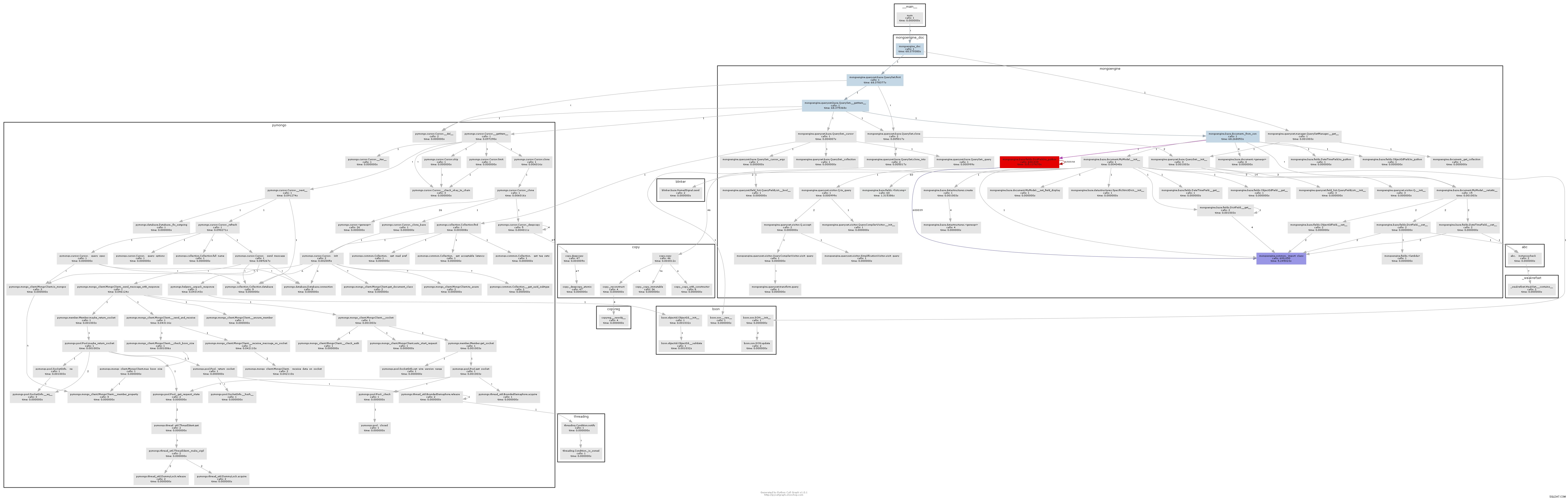
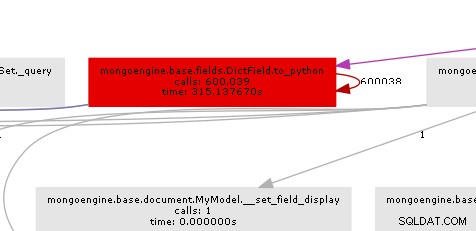
Mongoengine v podstatě zavolá metodu to_python na každém DictField že se vrací z db. to_python je docela pomalý a v našem příkladu je nazýván šíleně mnohokrát.
Mongoengine se používá k elegantnímu mapování struktury vašeho dokumentu na objekty python. Pokud máte velmi velké nestrukturované dokumenty (pro které je mongodb skvělý), pak mongoengine není ve skutečnosti tím pravým nástrojem a měli byste použít pymongo.
Pokud však znáte strukturu, můžete použít EmbeddedDocument pole získat o něco lepší výkon z mongoengine. Spustil jsem podobný, ale ne ekvivalentní test kód v tomto souhrnu
a výstup je:
pymongo with dict took 0.12s
pymongo with embed took 0.12s
mongoengine with dict took 4.3059175412661075
mongoengine with embed took 1.1639373211854682
Takže můžete udělat mongoengine rychlejší, ale pymongo je ještě mnohem rychlejší.
AKTUALIZACE
Dobrou zkratkou k rozhraní pymongo je použití agregačního rámce:
def mongoengine_agg_doc():
return list(MyModel.objects.aggregate({"$limit":1}))[0]